Recognition: unknown
Analyzing Chain of Thought (CoT) Approaches in Control Flow Code Deobfuscation Tasks
Pith reviewed 2026-05-10 11:21 UTC · model grok-4.3
The pith
Chain-of-thought prompting improves large language models' recovery of control flow and semantics in obfuscated C code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that Chain-of-Thought prompting, which directs the model through explicit reasoning steps for code analysis, produces higher-quality deobfuscated output than zero-shot prompting. Across the tested models and obfuscation types, this yields clearer control-flow graphs and outputs that match the original program on test inputs more closely. GPT5 records the strongest results, with roughly 16 percent better control-flow graph reconstruction and 20.5 percent better semantic preservation than simple prompting. Results also vary with the original program's control-flow complexity and the specific obfuscator used.
What carries the argument
Chain-of-Thought (CoT) prompting, which supplies the model with explicit, task-specific reasoning steps before producing the deobfuscated code.
If this is right
- CoT prompting reduces reliance on manual inspection for recovering readable control flow from flattened or predicate-protected code.
- Model performance scales with both the degree of obfuscation and the intrinsic complexity of the original control-flow graph.
- The approach supplies more faithful graph reconstructions and behavior-preserving code than direct prompting alone.
- CoT can serve as an assistive layer that shortens the time needed for reverse engineering while improving code explainability.
Where Pith is reading between the lines
- The same prompting pattern could be tried on other obfuscation families such as data obfuscation or virtualization-based protection.
- Hybrid pipelines that feed CoT output into existing static-analysis tools might further raise reconstruction accuracy.
- Testing on additional languages and larger, real malware samples would show how far the observed gains extend.
Load-bearing premise
That matching program outputs on a fixed set of test inputs is enough to confirm the deobfuscated code still carries the original semantics.
What would settle it
An obfuscated program where the CoT output matches the original on every test input yet produces different behavior on an untested input, or a real-world control-flow-obfuscated binary outside the chosen C benchmark set on which CoT fails to recover the original graph structure.
Figures





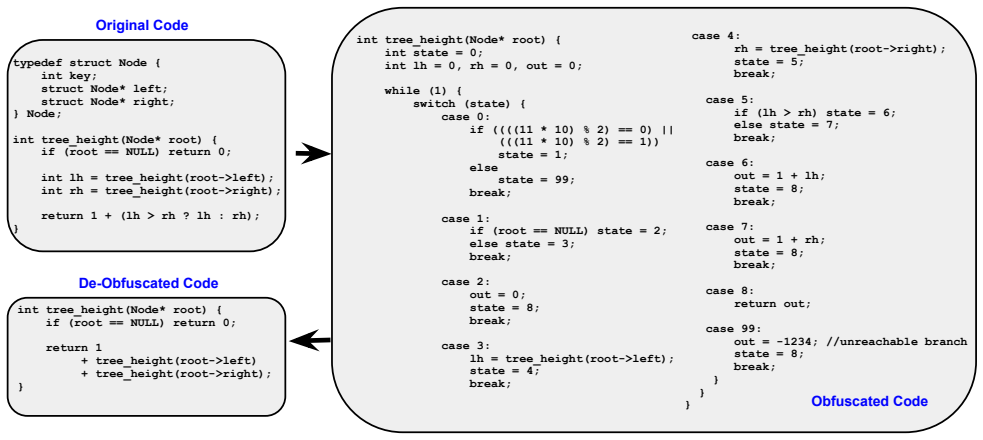
read the original abstract
Code deobfuscation is the task of recovering a readable version of a program while preserving its original behavior. In practice, this often requires days or even months of manual work with complex and expensive analysis tools. In this paper, we explore an alternative approach based on Chain-of-Thought (CoT) prompting, where a large language model is guided through explicit, step-by-step reasoning tailored for code analysis. We focus on control flow obfuscation, including Control Flow Flattening (CFF), Opaque Predicates, and their combination, and we measure both structural recovery of the control flow graph and preservation of program semantics. We evaluate five state-of-the-art large language models and show that CoT prompting significantly improves deobfuscation quality compared with simple prompting. We validate our approach on a diverse set of standard C benchmarks and report results using both structural metrics for control flow graphs and semantic metrics based on output similarity. Among the tested models and by applying CoT, GPT5 achieves the strongest overall performance, with an average gain of about 16% in control-flow graph reconstruction and about 20.5% in semantic preservation across our benchmarks compared to zero-shot prompting. Our results also show that model performance depends not only on the obfuscation level and the chosen obfuscator but also on the intrinsic complexity of the original control flow graph. Collectively, these findings suggest that CoT-guided large language models can serve as effective assistants for code deobfuscation, providing improved code explainability, more faithful control flow graph reconstruction, and better preservation of program behavior while potentially reducing the manual effort needed for reverse engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Chain-of-Thought (CoT) prompting substantially improves large language model performance on control-flow deobfuscation tasks (Control Flow Flattening, Opaque Predicates, and combinations) relative to zero-shot prompting. It evaluates five state-of-the-art LLMs on standard C benchmarks, reports that GPT5 with CoT yields average gains of ~16% in control-flow graph reconstruction and ~20.5% in semantic preservation (measured by output similarity), and notes that results vary with obfuscation level and original CFG complexity.
Significance. If the evaluation protocol and semantic metric are shown to be reliable, the work would provide useful empirical evidence that structured prompting can assist automated deobfuscation and reduce manual reverse-engineering effort. The observation that LLM success depends on both obfuscation technique and intrinsic program complexity offers a practical insight for tool builders in software security and program analysis.
major comments (2)
- Abstract: the central quantitative claims (~16% CFG reconstruction gain and ~20.5% semantic preservation gain for GPT5) are stated without any description of the experimental protocol, number or identity of benchmarks, number of runs, statistical tests, or error bars, preventing assessment of whether the reported improvements are robust or reproducible.
- Abstract: semantic preservation is defined solely via 'output similarity' on test inputs, yet no information is supplied on test-suite coverage, equivalence tolerance, handling of side effects, memory layout, or non-determinism. This proxy is load-bearing for the claim of improved deobfuscation quality, especially under CFF and opaque predicates where unexercised paths may diverge.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's clarity and the need for more experimental context. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the central quantitative claims (~16% CFG reconstruction gain and ~20.5% semantic preservation gain for GPT5) are stated without any description of the experimental protocol, number or identity of benchmarks, number of runs, statistical tests, or error bars, preventing assessment of whether the reported improvements are robust or reproducible.
Authors: We agree that the abstract would benefit from additional context on the evaluation setup to support assessment of the claims. In the revised version, we will expand the abstract to note that the results are based on a diverse set of standard C benchmarks, five state-of-the-art LLMs, and averages across multiple runs per configuration, with full details on the protocol, benchmark identities, and any statistical measures provided in the experimental section of the paper. This revision will be made while respecting abstract length limits. revision: yes
-
Referee: Abstract: semantic preservation is defined solely via 'output similarity' on test inputs, yet no information is supplied on test-suite coverage, equivalence tolerance, handling of side effects, memory layout, or non-determinism. This proxy is load-bearing for the claim of improved deobfuscation quality, especially under CFF and opaque predicates where unexercised paths may diverge.
Authors: We acknowledge that the abstract's description of the semantic metric is high-level. The full manuscript provides details on the test inputs, coverage considerations, and handling of program behavior in the evaluation methodology section. We will revise the abstract to clarify that semantic preservation is assessed via output equivalence on test suites targeting the original program's observable behavior, including notes on equivalence tolerance and non-determinism where relevant. This addresses the concern without altering the core metric, which we maintain is suitable for verifying deobfuscation quality on exercised paths. revision: partial
Circularity Check
No circularity: purely empirical comparison of prompting strategies
full rationale
The paper reports experimental results from evaluating five LLMs on control-flow deobfuscation benchmarks using CoT versus zero-shot prompting. It measures CFG reconstruction accuracy and semantic preservation via output similarity on standard C programs. No equations, derivations, fitted parameters, uniqueness theorems, or self-citations are used to derive the central claims. All quantitative gains (e.g., 16% CFG, 20.5% semantic) are direct empirical observations from the described test suite. The work is self-contained against external benchmarks and contains no load-bearing steps that reduce to prior fitted quantities or self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Protecting software through obfuscation: Can it keep pace with progress in code analysis?
S. Schrittwieser, S. Katzenbeisser, J. Kinder, G. Merzdovnik, and E. Weippl, “Protecting software through obfuscation: Can it keep pace with progress in code analysis?”Acm computing surveys (csur), vol. 49, no. 1, pp. 1–37, 2016
2016
-
[2]
Obfuscation of executable code to improve resistance to static disassembly,
C. Linn and S. Debray, “Obfuscation of executable code to improve resistance to static disassembly,” inProceedings of the 10th ACM conference on Computer and communications security, 2003, pp. 290–299
2003
-
[3]
D. Manuel, N. T. Islam, J. Khoury, A. Nunez, E. Bou-Harb, and P. Najafirad, “Enhancing reverse engineering: Investigating and benchmarking large language models for vulnerability analysis in decompiled binaries,”arXiv preprint arXiv:2411.04981, 2024
-
[4]
Can llms obfuscate code? a systematic analysis of large language models into assembly code obfuscation,
S. Mohseni, S. Mohammadi, D. Tilwani, Y . Saxena, G. K. Ndawula, S. Vema, E. Raff, and M. Gaur, “Can llms obfuscate code? a systematic analysis of large language models into assembly code obfuscation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 23, 2025, pp. 24 893–24 901
2025
-
[5]
Taxonomy of static code analysis tools,
J. Novak, A. Krajncet al., “Taxonomy of static code analysis tools,” inThe 33rd international convention MIPRO. IEEE, 2010, pp. 418–422
2010
-
[6]
Code obfuscation literature survey,
A. Balakrishnan and C. Schulze, “Code obfuscation literature survey,”CS701 Construction of compilers, vol. 19, no. 31, p. 10, 2005
2005
-
[7]
Layered obfuscation: a taxonomy of software obfuscation techniques for layered security,
H. Xu, Y . Zhou, J. Ming, and M. Lyu, “Layered obfuscation: a taxonomy of software obfuscation techniques for layered security,” Cybersecurity, vol. 3, pp. 1–18, 2020
2020
-
[8]
Predicting the re- silience of obfuscated code against symbolic execution attacks via machine learning,
S. Banescu, C. Collberg, and A. Pretschner, “Predicting the re- silience of obfuscated code against symbolic execution attacks via machine learning,” inProceedings of the 26th USENIX Security Symposium (USENIX Security ’17), Vancouver, BC, Canada, 2017, pp. 661–678
2017
-
[9]
Symbolic execution for software testing: Three decades later,
C. Cadar and K. Sen, “Symbolic execution for software testing: Three decades later,”Communications of the ACM, vol. 56, no. 2, pp. 82–90, 2013
2013
-
[10]
A survey of symbolic execution techniques,
R. Baldoni, E. Coppa, D. C. D’Elia, C. Demetrescu, and I. Finoc- chi, “A survey of symbolic execution techniques,”ACM Computing Surveys, vol. 51, no. 3, pp. 1–39, 2018
2018
-
[11]
Manufacturing resilient bi-opaque predicates against symbolic execution,
H. Xu, Y . Zhou, Y . Kang, F. Tu, and M. R. Lyu, “Manufacturing resilient bi-opaque predicates against symbolic execution,” in2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Luxembourg, 2018, pp. 666–677
2018
-
[12]
Dobf: A deobfuscation pre-training objective for programming languages,
M.-A. Lachaux, B. Roziere, M. Szafraniec, and G. Lample, “Dobf: A deobfuscation pre-training objective for programming languages,”Advances in Neural Information Processing Systems, vol. 34, pp. 14 967–14 979, 2021
2021
-
[13]
G. Fan, X. Xie, X. Zheng, Y . Liang, and P. Di, “Static code analysis in the ai era: An in-depth exploration of the concept, function, and potential of intelligent code analysis agents,”arXiv preprint arXiv:2310.08837, 2023
-
[14]
A survey on machine learning techniques for source code analysis,
T. Sharma, M. Kechagia, S. Georgiou, R. Tiwari, I. Vats, H. Moazen, and F. Sarro, “A survey on machine learning techniques for source code analysis,”arXiv preprint arXiv:2110.09610, 2021
-
[15]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information pro- cessing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[16]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
P. Sahoo, A. K. Singh, S. Saha, V . Jain, S. Mondal, and A. Chadha, “A systematic survey of prompt engineering in large language models: Techniques and applications,”arXiv preprint arXiv:2402.07927, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493, 2022
Z. Zhang, A. Zhang, M. Li, and A. Smola, “Automatic chain of thought prompting in large language models,”arXiv preprint arXiv:2210.03493, 2022
-
[18]
Towards bet- ter chain-of-thought prompting strategies: A survey,
Z. Yu, L. He, Z. Wu, X. Dai, and J. Chen, “Towards better chain-of-thought prompting strategies: A survey,”arXiv preprint arXiv:2310.04959, 2023
-
[19]
Obfuscator- llvm–software protection for the masses,
P. Junod, J. Rinaldini, J. Wehrli, and J. Michielin, “Obfuscator- llvm–software protection for the masses,” in2015 ieee/acm 1st international workshop on software protection. IEEE, 2015, pp. 3–9
2015
-
[20]
Deobfuscation: Reverse engineering obfuscated code,
S. K. Udupa, S. K. Debray, and M. Madou, “Deobfuscation: Reverse engineering obfuscated code,” in12th Working Conference on Reverse Engineering (WCRE’05). IEEE, 2005, pp. 10–pp
2005
-
[21]
Impact of code deobfuscation and feature interaction in android malware detection,
Y .-C. Chen, H.-Y . Chen, T. Takahashi, B. Sun, and T.-N. Lin, “Impact of code deobfuscation and feature interaction in android malware detection,”IEEE Access, vol. 9, pp. 123 208–123 219, 2021
2021
-
[22]
Camouflage in malware: from encryption to metamorphism,
B. B. Rad, M. Masrom, and S. Ibrahim, “Camouflage in malware: from encryption to metamorphism,”International Journal of Com- puter Science and Network Security, vol. 12, no. 8, pp. 74–83, 2012
2012
-
[23]
From static to ai-driven detection: A comprehensive review of obfuscated malware techniques,
S. Chandran, S. R. Syam, S. Sankaran, T. Pandey, and K. Achuthan, “From static to ai-driven detection: A comprehensive review of obfuscated malware techniques,”IEEE Access, 2025
2025
-
[24]
Use of cryptography in malware ob- fuscation,
H. J. Asghar, B. Z. H. Zhao, M. Ikram, G. Nguyen, D. Kaafar, S. Lamont, and D. Coscia, “Use of cryptography in malware ob- fuscation,”Journal of Computer Virology and Hacking Techniques, vol. 20, no. 1, pp. 135–152, 2024
2024
-
[25]
Control flow ob- fuscation for android applications,
V . Balachandran, D. J. Tan, V . L. Thinget al., “Control flow ob- fuscation for android applications,”Computers & Security, vol. 61, pp. 72–93, 2016
2016
-
[26]
A framework to quantify the quality of source code obfuscation,
H. Jin, J. Lee, S. Yang, K. Kim, and D. H. Lee, “A framework to quantify the quality of source code obfuscation,”Applied Sciences, vol. 14, no. 12, p. 5056, 2024
2024
-
[27]
Lightweight dispatcher constructions for control flow flattening,
B. Johansson, P. Lantz, and M. Liljenstam, “Lightweight dispatcher constructions for control flow flattening,” inProceedings of the 7th Software Security, Protection, and Reverse Engineering/Software Security and Protection Workshop, 2017, pp. 1–12
2017
-
[28]
A generic approach to automatic deobfuscation of executable code,
B. Yadegari, B. Johannesmeyer, B. Whitely, and S. Debray, “A generic approach to automatic deobfuscation of executable code,” inProceedings of the IEEE Symposium on Security and Privacy (S&P). IEEE, 2015, pp. 674–691
2015
-
[29]
Statistical deobfuscation of android applications,
B. Bichsel, V . Raychev, P. Tsankov, and M. Vechev, “Statistical deobfuscation of android applications,” inProceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2016, pp. 343–355
2016
-
[30]
Obfuscating C++ programs via control flow flattening,
G. L ´aszl´o and ´A. Kiss, “Obfuscating C++ programs via control flow flattening,”Annales Universitatis Scientiarum Budapestinensis de Rolando E ¨otv¨os Nominatae, Sectio Computatorica, vol. 30, pp. 3–19, 2009
2009
-
[31]
Neural network-based graph embedding for cross-platform binary code similarity detection,
X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural network-based graph embedding for cross-platform binary code similarity detection,” inProceedings of the ACM SIGSAC Confer- ence on Computer and Communications Security (CCS). ACM, 2017, pp. 363–376
2017
-
[32]
Toxic code snippets on stack overflow,
C. Ragkhitwetsagul, J. Krinke, M. Paixao, G. Bianco, and R. Oliveto, “Toxic code snippets on stack overflow,”IEEE Transac- tions on Software Engineering, vol. 48, no. 3, pp. 733–750, 2022
2022
-
[33]
Assessing llms in malicious code deobfuscation of real-world malware campaigns,
C. Patsakis, F. Casino, and N. Lykousas, “Assessing llms in malicious code deobfuscation of real-world malware campaigns,” Expert systems with applications, vol. 256, p. 124912, 2024
2024
-
[34]
Exploring the potential of llms for code deobfuscation,
D. Beste, G. Menguy, H. Hajipour, M. Fritz, A. E. Cin `a, S. Bardin, T. Holz, T. Eisenhofer, and L. Sch ¨onherr, “Exploring the potential of llms for code deobfuscation,” inInternational Conference on Detection of Intrusions and Malware, and Vulnerability Assess- ment. Springer, 2025, pp. 267–286
2025
-
[35]
Can llms recover program semantics? a systematic evaluation with symbolic execution,
R. Feng and S. Saha, “Can llms recover program semantics? a systematic evaluation with symbolic execution,”arXiv preprint arXiv:2511.19130, 2025
-
[36]
Malicious source code detection using a translation model,
C. Tsfaty and M. Fire, “Malicious source code detection using a translation model,”Patterns, vol. 4, no. 7, 2023
2023
-
[37]
Deobfuscation, unpacking, and decoding of obfuscated malicious javascript for machine learning models detection performance improvement,
S. Ndichu, S. Kim, and S. Ozawa, “Deobfuscation, unpacking, and decoding of obfuscated malicious javascript for machine learning models detection performance improvement,”CAAI Transactions on Intelligence Technology, vol. 5, no. 3, pp. 184–192, 2020
2020
-
[38]
A survey of the recent trends in deep learning based malware detection,
U.-e.-H. Tayyab, F. B. Khan, M. H. Durad, A. Khan, and Y . S. Lee, “A survey of the recent trends in deep learning based malware detection,”Journal of Cybersecurity and Privacy, vol. 2, no. 4, pp. 800–829, 2022
2022
-
[39]
Dfsgraph: Data flow semantic model for intermediate representation programs based on graph network,
K. Tang, Z. Shan, C. Zhang, L. Xu, M. Qiao, and F. Liu, “Dfsgraph: Data flow semantic model for intermediate representation programs based on graph network,”Electronics, vol. 11, no. 19, p. 3230, 2022
2022
-
[40]
Deep graph learning for circuit deobfuscation,
Z. Chen, L. Zhang, G. Kolhe, H. M. Kamali, S. Rafatirad, S. M. Pudukotai Dinakarrao, H. Homayoun, C.-T. Lu, and L. Zhao, “Deep graph learning for circuit deobfuscation,”Frontiers in big Data, vol. 4, p. 608286, 2021
2021
-
[41]
A neural network-based cognitive obfuscation toward enhanced logic locking,
R. Hassan, G. Kolhe, S. Rafatirad, H. Homayoun, and S. M. P. Dinakarrao, “A neural network-based cognitive obfuscation toward enhanced logic locking,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 11, pp. 4587–4599, 2021
2021
-
[42]
Towards machine- learning-based oracle-guided analog circuit deobfuscation,
D. Jain, G. Zhao, R. Datta, and K. Shamsi, “Towards machine- learning-based oracle-guided analog circuit deobfuscation,” in2024 IEEE International Test Conference (ITC). IEEE, 2024, pp. 323– 332
2024
-
[43]
Graph matching networks for learning the similarity of graph structured objects,
Y . Li, C. Gu, T. Dullien, O. Vinyals, and P. Kohli, “Graph matching networks for learning the similarity of graph structured objects,” inInternational conference on machine learning. PMLR, 2019, pp. 3835–3845
2019
-
[44]
Graph clustering using k-neighbourhood attribute structural similarity,
M. P. Boobalan, D. Lopez, and X. Z. Gao, “Graph clustering using k-neighbourhood attribute structural similarity,”Applied soft computing, vol. 47, pp. 216–223, 2016
2016
-
[45]
A method to evaluate cfg compari- son algorithms,
P. P. Chan and C. Collberg, “A method to evaluate cfg compari- son algorithms,” in2014 14th international conference on quality software. IEEE, 2014, pp. 95–104
2014
-
[46]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[47]
Enhanced bilingual evaluation understudy,
K. Maraseket al., “Enhanced bilingual evaluation understudy,” arXiv preprint arXiv:1509.09088, 2015
-
[48]
A call for clarity in reporting BLEU scores.arXiv preprint arXiv:1804.08771,
M. Post, “A call for clarity in reporting bleu scores,”arXiv preprint arXiv:1804.08771, 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.