Recognition: unknown
Ragged Paged Attention: A High-Performance and Flexible LLM Inference Kernel for TPU
Pith reviewed 2026-05-10 08:22 UTC · model grok-4.3
The pith
RPA kernel for TPUs achieves 86% MBU in decode and 73% MFU in prefill on Llama 3 8B via tiling for ragged memory, fused pipelines, and specialized compilation for prefill/decode workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
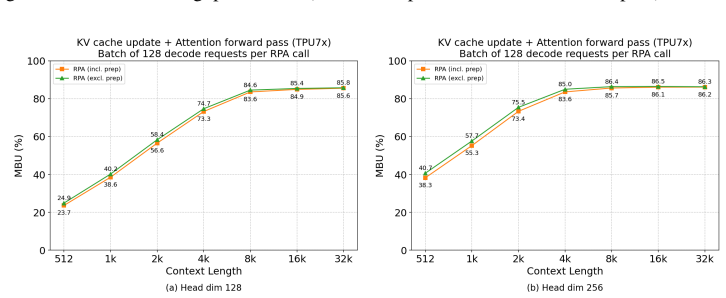
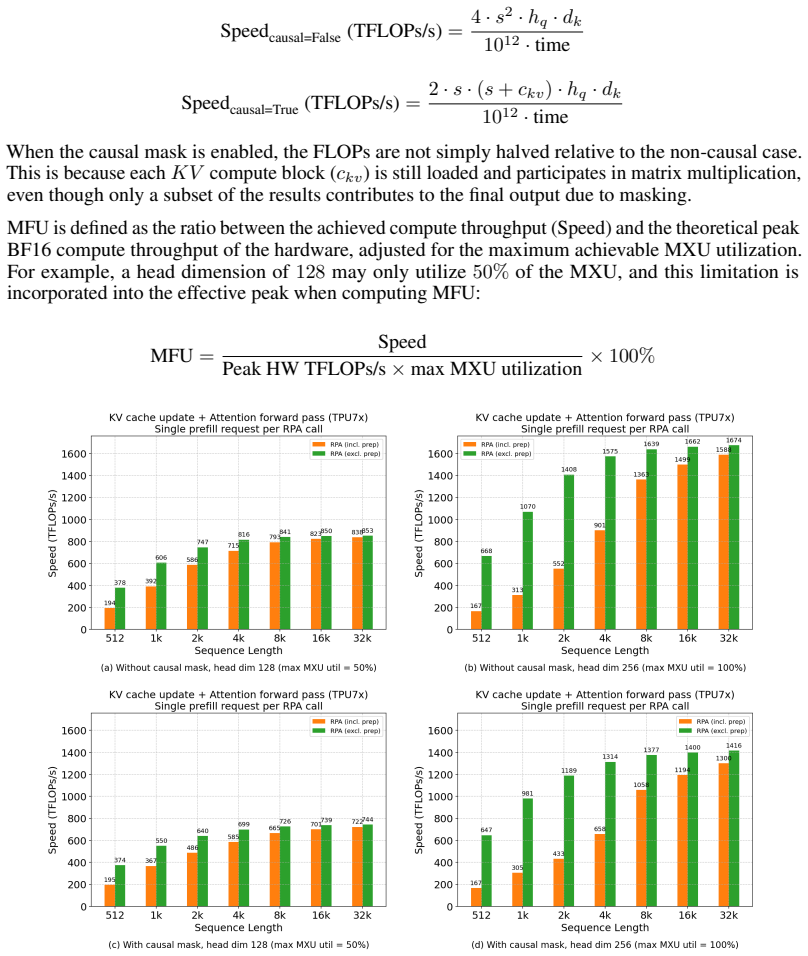
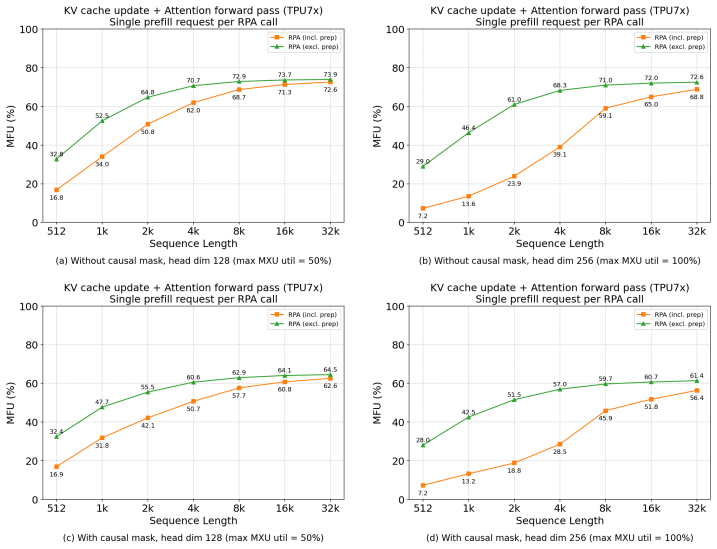
RPA achieves up to 86% memory bandwidth utilization (MBU) in decode and 73% model FLOPs utilization (MFU) in prefill on Llama 3 8B on TPU7x, integrated as primary TPU backend in vLLM and SGLang.
Load-bearing premise
The fine-grained tiling, custom pipeline, and distribution-aware compilation will deliver similar high utilization across other models, sequence lengths, and TPU variants without major retuning or performance cliffs.
Figures













read the original abstract
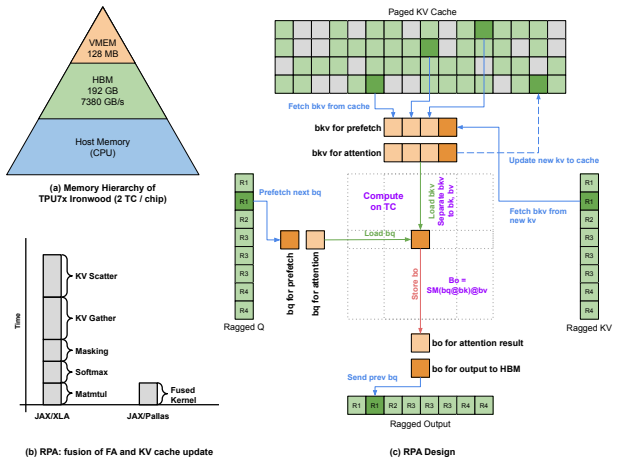
Large Language Model (LLM) deployment is increasingly shifting to cost-efficient accelerators like Google's Tensor Processing Units (TPUs), prioritizing both performance and total cost of ownership (TCO). However, existing LLM inference kernels and serving systems remain largely GPU-centric, and there is no well-established approach for efficiently mapping LLM workloads onto TPU architectures--particularly under the dynamic and ragged execution patterns common in modern serving. In this paper, we present Ragged Paged Attention (RPA), a high-performance and flexible attention kernel for TPUs, implemented using Pallas and Mosaic. RPA addresses these challenges through three key techniques: (1) fine-grained tiling to enable efficient dynamic slicing over ragged memory, (2) a custom software pipeline that fuses KV cache updates with attention computation, and (3) a distribution-aware compilation strategy that generates specialized kernels for decode, prefill, and mixed workloads. Evaluated on Llama 3 8B on TPU7x, RPA achieves up to 86% memory bandwidth utilization (MBU) in decode and 73% model FLOPs utilization (MFU) in prefill. Integrated as the primary TPU backend in vLLM and SGLang, RPA provides a production-grade foundation for efficient TPU inference and offers practical insights into kernel design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ragged Paged Attention (RPA), a TPU inference kernel for LLMs implemented in Pallas and Mosaic. It proposes three techniques—fine-grained tiling for dynamic ragged memory slicing, a custom software pipeline fusing KV cache updates with attention computation, and distribution-aware compilation that specializes kernels for decode, prefill, and mixed workloads—to address the lack of efficient TPU mappings for dynamic serving patterns. On Llama 3 8B evaluated on TPU7x, RPA reports peak utilizations of 86% memory bandwidth utilization (MBU) in decode and 73% model FLOPs utilization (MFU) in prefill; the kernel is integrated as the primary TPU backend in vLLM and SGLang.
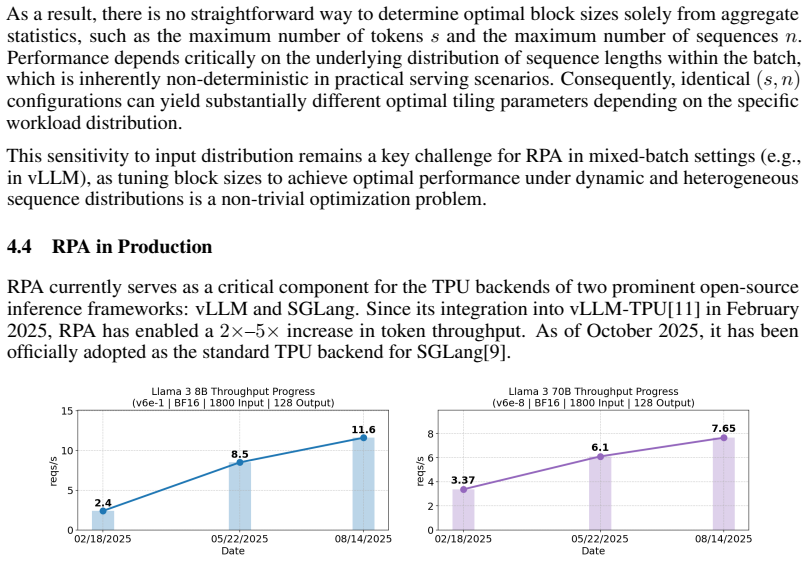
Significance. If the reported utilization numbers are reproducible on representative workloads and the techniques prove robust across models and TPU variants, the work supplies a production-grade TPU attention kernel that fills a clear gap in GPU-centric serving stacks. The open integration into vLLM and SGLang and the emphasis on practical kernel-design lessons would make the contribution immediately usable by the community.
major comments (3)
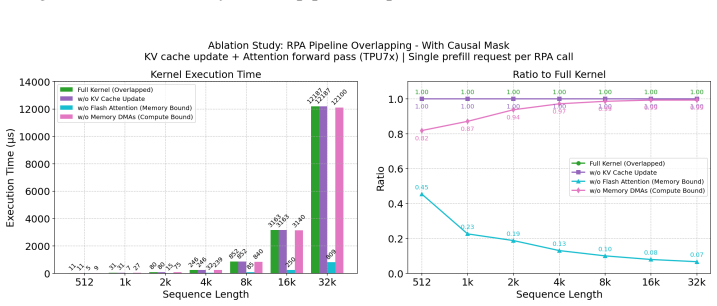
- [Abstract / Evaluation] Abstract and evaluation section: The headline claims of 86% MBU (decode) and 73% MFU (prefill) on Llama 3 8B / TPU7x are given without any description of the batch-size, sequence-length, or raggedness distribution that produced those peaks. Because the central thesis is that the three techniques deliver high utilization under realistic ragged serving conditions, the absence of workload characterization prevents readers from judging whether the numbers are representative or the result of favorable inputs.
- [Evaluation] Evaluation section: No baseline numbers are reported for a straightforward Pallas/Mosaic port of paged attention that omits the custom pipeline and distribution-aware specialization. Without this comparison it is impossible to quantify how much of the reported utilization is attributable to the proposed techniques versus simply running on TPU hardware.
- [Results] Results / §5: The manuscript provides no sensitivity curves or ablation data showing how MBU/MFU vary with sequence length, batch size, or degree of raggedness, nor any measurements on other models or TPU generations. This omission directly undermines the claim that RPA is both high-performance and flexible.
minor comments (1)
- [Abstract] The abstract states that RPA “provides practical insights into kernel design,” yet the provided text does not enumerate those insights; a short dedicated subsection or bullet list would help readers extract the design lessons.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption TPU architecture supports efficient dynamic slicing and software pipelining via Pallas/Mosaic primitives
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Fedus, Niklas Muennighoff, Stefan Bolze, Shibo Sun, Jia Siddhartha, et al. GQA: Training generalized multi-query transformer models from multi-head checkpoints.arXiv preprint arXiv:2305.13245, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
Pallas: A JAX extension for writing low-level, high-performance cus- tom kernels
The JAX Authors. Pallas: A JAX extension for writing low-level, high-performance cus- tom kernels. https://docs.jax.dev/en/latest/pallas/index.html, 2023. Accessed: 2026-04-01
2023
-
[3]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024
2024
-
[4]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[5]
Abhimanyu Dubey, Akhil Jauhri, Abhinav Pandey, Ashish Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Atli Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles (SOSP), 2023
2023
-
[7]
FlashAttention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024. 20
2024
-
[8]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review arXiv 1911
-
[9]
Integrating ragged paged attention v3 into SGLang
SGLang Team. Integrating ragged paged attention v3 into SGLang. https://lmsys.org/ blog/2025-10-29-sglang-jax/#integrating-ragged-paged-attention-v3 , 2025. Accessed: 2026-04-03
2025
-
[10]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), pages 5998–6008, 2017
2017
-
[11]
vLLM TPU support
vLLM Team. vLLM TPU support. https://blog.vllm.ai/2025/10/16/vllm-tpu.html,
2025
-
[12]
Accessed: 2026-04-03
2026
-
[13]
Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao. FlashAttention-4: Algorithm and kernel pipelining co-design for asymmetric hardware scaling. arXiv preprint arXiv:2603.05451, 2026
-
[14]
Gonzalez, Clark W
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark W. Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. A Full Benchmarking Results Table 4: RPA P...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.