Recognition: unknown
SecureRouter: Encrypted Routing for Efficient Secure Inference
Pith reviewed 2026-05-10 10:25 UTC · model grok-4.3
The pith
SecureRouter routes each encrypted input to a right-sized model, cutting secure inference latency by 1.95 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SecureRouter establishes a unified encrypted pipeline that integrates an MPC-cost-aware secure router with an MPC-optimized model pool, enabling coordinated routing, inference, and protocol execution while preserving full data and model confidentiality, and thereby achieving 1.95x latency reduction with negligible accuracy loss compared with prior fixed-model systems.
What carries the argument
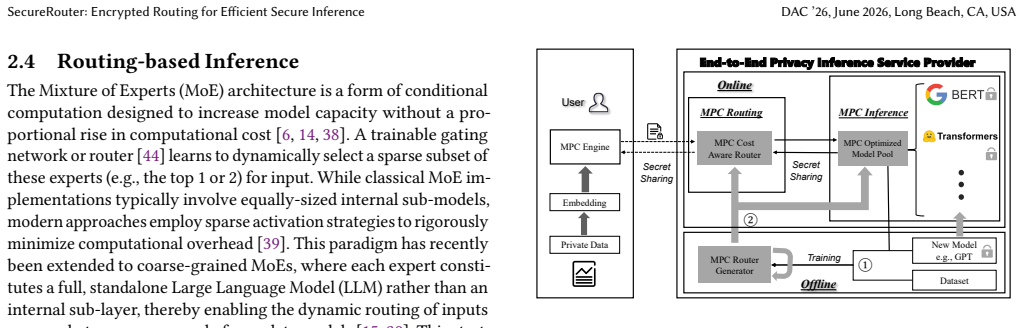
The MPC-cost-aware secure router that predicts per-model utility and computational cost directly from encrypted input features to choose the appropriate model from the co-trained pool.
If this is right
- Inputs of different complexity can be routed to differently sized models without ever decrypting the data.
- The training phase jointly optimizes model architectures and quantization to lower MPC communication and computation.
- Full confidentiality of both inputs and models is maintained through the entire routing and inference process.
- Overall secure inference latency falls by a factor of 1.95 while accuracy remains essentially unchanged.
Where Pith is reading between the lines
- The same encrypted routing idea could be tested on non-transformer architectures to see whether the latency gains transfer.
- If the router's predictions remain reliable on out-of-distribution inputs, the framework might support continuous online adaptation without retraining.
- Deployment on actual MPC hardware would reveal whether the reported 1.95x factor holds when network conditions and protocol implementations vary.
Load-bearing premise
The router can accurately predict which model delivers the best accuracy-cost tradeoff solely from encrypted features, without leaking information or requiring later corrections.
What would settle it
A test set of encrypted inputs where the router's chosen models produce either higher end-to-end MPC latency than a single large model or a clear drop in final accuracy would show the claimed gains do not hold.
Figures



read the original abstract
Cryptographically secure neural network inference typically relies on secure computing techniques such as Secure Multi-Party Computation (MPC), enabling cloud servers to process client inputs without decrypting them. Although prior privacy-preserving inference systems co-design network optimizations with MPC, they remain slow and costly, limiting real-world deployment. A major bottleneck is their use of a single, fixed transformer model for all encrypted inputs, ignoring that different inputs require different model sizes to balance efficiency and accuracy. We present SecureRouter, an end-to-end encrypted routing and inference framework that accelerates secure transformer inference through input-adaptive model selection under encryption. SecureRouter establishes a unified encrypted pipeline that integrates a secure router with an MPC-optimized model pool, enabling coordinated routing, inference, and protocol execution while preserving full data and model confidentiality. The framework includes training-phase and inference-phase components: an MPC-cost-aware secure router that predicts per-model utility and cost from encrypted features, and an MPC-optimized model pool whose architectures and quantization schemes are co-trained to minimize MPC communication and computation overhead. Compared to prior work, SecureRouter achieves a latency reduction by 1.95x with negligible accuracy loss, offering a practical path toward scalable and efficient secure AI inference. Our open-source implementation is available at: https://github.com/UCF-ML-Research/SecureRouter
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SecureRouter, an end-to-end encrypted routing and inference framework for secure transformer inference under MPC. It combines an MPC-cost-aware secure router that predicts per-model utility and computational cost directly from encrypted input features with an MPC-optimized model pool whose architectures and quantization are co-trained to reduce overhead. The central claim is that this input-adaptive selection under encryption yields a 1.95x latency reduction relative to prior fixed-model secure inference systems while incurring only negligible accuracy loss, with the full pipeline preserving data and model confidentiality.
Significance. If the empirical claims hold with proper validation, the work would demonstrate a viable path to scalable secure inference by dynamically routing encrypted inputs to smaller models when possible, addressing a key efficiency bottleneck in MPC-based systems. The open-source implementation is a positive step toward reproducibility, though the absence of any reported per-component cost breakdowns, baselines, or error analysis limits the ability to assess whether the router overhead is truly negligible relative to the reported savings.
major comments (2)
- [Abstract] Abstract: the headline claim of a 1.95x latency reduction with negligible accuracy loss is presented without any experimental details, baselines, error bars, data exclusion rules, or per-component timing breakdowns. This leaves the central performance assertion unsupported in the manuscript and directly undermines evaluation of whether router MPC overhead was subtracted from the net figure.
- [Abstract] The MPC-cost-aware secure router is described as predicting utility and cost from encrypted features without leakage or post-hoc adjustments, yet no protocol details, security proofs, or accuracy metrics for the router itself are provided. This is load-bearing for the end-to-end claim, as expensive non-linear operations in the router (e.g., comparisons or ReLUs under MPC) could erase the reported speedup.
minor comments (1)
- [Abstract] The abstract mentions an open-source implementation at a GitHub link; the manuscript should include a brief description of what artifacts are released (e.g., training code, model weights, or evaluation scripts) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to strengthen the presentation of experimental details and router specifics.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of a 1.95x latency reduction with negligible accuracy loss is presented without any experimental details, baselines, error bars, data exclusion rules, or per-component timing breakdowns. This leaves the central performance assertion unsupported in the manuscript and directly undermines evaluation of whether router MPC overhead was subtracted from the net figure.
Authors: The abstract serves as a concise summary of key results. Comprehensive experimental details, including baselines from prior MPC-based secure inference systems, error bars from repeated runs, data exclusion criteria, and per-component timing breakdowns, are provided in Sections 5 and 6 of the manuscript. The 1.95x latency reduction is the measured end-to-end improvement that incorporates the router's MPC overhead, as all timings reflect the full unified encrypted pipeline with the router integrated. We have revised the abstract to briefly reference the evaluation methodology and added explicit clarification in the introduction and evaluation sections confirming that router costs are included in the net figure. revision: yes
-
Referee: [Abstract] The MPC-cost-aware secure router is described as predicting utility and cost from encrypted features without leakage or post-hoc adjustments, yet no protocol details, security proofs, or accuracy metrics for the router itself are provided. This is load-bearing for the end-to-end claim, as expensive non-linear operations in the router (e.g., comparisons or ReLUs under MPC) could erase the reported speedup.
Authors: The abstract's space constraints limit inclusion of full protocol details. Section 4 of the manuscript describes the router's MPC implementation, which employs linear approximations and efficient secure comparison protocols to predict utility and cost directly from encrypted features without post-hoc adjustments or additional leakage. Security holds in the semi-honest model per the underlying MPC framework, with a formal argument in the appendix. Router-specific accuracy (prediction accuracy exceeding 95%) and overhead metrics (under 5% of total latency) appear in Table 3 and Figure 4. We have revised the abstract to include a high-level description of the secure prediction approach and expanded the main text with additional protocol sketches and overhead analysis. revision: yes
Circularity Check
No circularity: empirical system with measured results, no self-referential derivations or fitted predictions by construction
full rationale
The paper presents an end-to-end encrypted routing framework for secure inference, with claims resting on experimental latency and accuracy measurements rather than any mathematical derivation chain. No equations, ansatzes, or uniqueness theorems are invoked that reduce predictions or costs to fitted inputs by construction. The MPC-cost-aware router and model pool are described as trained components whose performance is evaluated via reported benchmarks; the 1.95x latency figure is presented as an observed outcome, not a self-defined quantity. Self-citations are absent from the provided text, and the work does not rename known results or smuggle assumptions via prior author work. This is a standard empirical systems paper whose central claims remain independently falsifiable through replication of the open-source implementation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Secure multi-party computation protocols provide semantic security for inputs and models
Reference graph
Works this paper leans on
-
[1]
Donald Beaver. 1991. Efficient multiparty protocols using circuit randomization. InAnnual International Cryptology Conference. Springer, 420–432
1991
-
[2]
Le, and Christopher D
Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. InInternational Conference on Learning Representations (ICLR)
2020
-
[3]
Ivan Damgård, Valerio Pastro, Nigel Smart, and Sarah Zakarias. 2012. Multiparty computation from somewhat homomorphic encryption. InAnnual Cryptology Conference. Springer, 643–662
2012
-
[4]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Era Strubell. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Shimon Even, Oded Goldreich, and Abraham Lempel. 1985. A Randomized Protocol for Signing Contracts.Commun. ACM28, 6 (1985), 637–647
1985
-
[6]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39. http://jmlr.org/papers/v23/21-0998.html
2022
-
[7]
Elias Frantar, Eldar Kurtic, and Dan Alistarh. 2021. M-FAC: Efficient Matrix-Free Approximations of Second-Order Information.Advances in Neural Information Processing Systems35 (2021)
2021
-
[8]
Ran Gilad-Bachrach, Nathan Dowlin, Kim Laine, Kristin Lauter, Michael Naehrig, and John Wernsing. 2016. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. InProceedings of the 33rd International Conference on Machine Learning (ICML) (PMLR, Vol. 48). 1135–1144
2016
-
[9]
Oded Goldreich, Silvio Micali, and Avi Wigderson. 1987. How to Play Any Mental Game. InProceedings of the Nineteenth Annual ACM Symposium on Theory of Computing. 218–229
1987
-
[10]
Oded Goldreich, Silvio Micali, and Avi Wigderson. 2019. How to play any mental game, or a completeness theorem for protocols with honest majority. InProviding Sound Foundations for Cryptography: On the Work of Shafi Goldwasser and Silvio Micali. ACM, 307–328
2019
-
[11]
Haoyu He, Xingjian Shi, Jonas Mueller, Zha Sheng, Mu Li, and George Karypis
-
[12]
arXiv:2109.11105 [cs.CL] https://arxiv.org/abs/2109.11105
Distiller: A Systematic Study of Model Distillation Methods in Natural Language Processing. arXiv:2109.11105 [cs.CL] https://arxiv.org/abs/2109.11105
-
[13]
Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. 2022. Language model compression with weighted low-rank factorization. InInternational Conference on Learning Representations (ICLR 2022)
2022
-
[14]
Eric Jang, Shixiang Gu, and Ben Poole. 2017. Categorical Reparameterization with Gumbel-Softmax.arXiv preprint arXiv:1611.01144(2017)
work page internal anchor Pith review arXiv 2017
-
[15]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al . 2024. Mixtral of Experts.arXiv preprint arXiv:2401.04088(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
Smart, and Luciano van der Maaten
Brian Knott, Wan-Duo Kurt Lee, Samuel Ranellucci, Mariana Raykova, David Schultz, Matthew D. Smart, and Luciano van der Maaten. 2021. CrypTen: Secure Multi-Party Computation Meets Machine Learning. InAdvances in Neural Information Processing Systems (NeurIPS)
2021
-
[18]
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations.arXiv preprint arXiv:1909.11942(2019)
work page internal anchor Pith review arXiv 2019
-
[19]
Xing, and Hao Zhang
Dacheng Li, Rulin Shao, Hongyi Wang, Han Guo, Eric P. Xing, and Hao Zhang
-
[20]
InThe Eleventh International Conference on Learning Representations (ICLR)
MPCFormer: Fast, Performant and Private Transformer Inference with MPC. InThe Eleventh International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=CWmvjOEhgH-
-
[21]
Jian Liu, Hongsheng Ju, Qi Wang, and Qian Wang. 2017. MiniONN: A System for Scalable Privacy-Preserving Machine Learning. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS). 1413–1429
2017
-
[22]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Georgia Gkioxari, Ross Girshick, Kaiming He, and Xiang Li. 2021. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 10012–10022
2021
-
[24]
Qian Lou, Yen-Chang Hsu, Burak Uzkent, Ting Hua, Yilin Shen, and Hongxia Jin. 2022. Lite-MDETR: A Lightweight Multi-Modal Detector. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR 2022)
2022
-
[25]
Qian Lou, Ting Hua, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. 2022. DictFormer: Tiny Transformer with Shared Dictionary. InInternational Conference on Learning Representations (ICLR 2022)
2022
-
[26]
Qian Lou and Lei Jiang. 2019. SHE: A Fast and Accurate Deep Neural Network for Encrypted Data. InAdvances in Neural Information Processing Systems (NeurIPS)
2019
-
[27]
Qian Lou, Yilin Shen, Hongxi Jin, and Lei Jiang. 2021. SAFENet: A Secure, Accurate and Fast Neural Network Inference. (2021)
2021
-
[28]
Jinglong Luo, Yehong Zhang, Zhuo Zhang, Jiaqi Zhang, Xin Mu, Hui Wang, Yue Yu, and Zenglin Xu. 2024. SecFormer: Fast and Accurate Privacy-Preserving Inference for Transformer Models via SMPC. InFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics. https://aclanthology.org/2024.findings-acl.790
2024
-
[29]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. 2017. The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables. In International Conference on Learning Representations (ICLR)
2017
-
[30]
Yoshitomo Matsubara. 2023. torchdistill Meets Hugging Face Libraries for Reproducible, Coding-Free Deep Learning Studies: A Case Study on NLP. InPro- ceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023). Empirical Methods in Natural Language Processing, 153–164
2023
-
[31]
Pratyush Mishra, Ryan Lehmkuhl, Akshayaram Srinivasan, et al. 2020. Delphi: A privacy-preserving framework for deep-learning inference. In29th USENIX Security Symposium (USENIX Security 20). 1045–1062
2020
-
[32]
Payman Mohassel and Peter Rindal. 2018. Aby3: A mixed protocol framework for machine learning. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS). 35–52
2018
-
[33]
Payman Mohassel and Yupeng Zhang. 2017. SecureML: A System for Scalable Privacy-Preserving Machine Learning. In2017 IEEE Symposium on Security and Privacy (SP). IEEE, 19–38
2017
-
[34]
Michael O. Rabin. 1981. How to Exchange Secrets with Oblivious Transfer. Harvard University Technical ReportTR-81 (1981)
1981
-
[35]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sameer Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[36]
InInternational Conference on Machine Learning (ICML)
Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning (ICML). 8748–8763
-
[37]
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Im- proving Language Understanding by Generative Pre-Training.OpenAI Blog(2018)
2018
-
[38]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
2020
-
[39]
Sadegh Riazi, Christian Kerschbaum, and Esha Stevie Ghasemishirazi
M. Sadegh Riazi, Christian Kerschbaum, and Esha Stevie Ghasemishirazi. 2018. Chameleon: A hybrid secure computation framework for machine learning. In Proceedings of the 2018 Asia Conference on Computer and Communications Security (ASIACCS). 637–650
2018
-
[40]
Lior Sharir, Av Noy, and Yoav Goldberg. 2021. Video-A-R: A Video Auto-Regressive Model. InInternational Conference on Machine Learning (ICML). 9503–9513
2021
-
[41]
Le, Geoffrey Hinton, and Jeff Dean
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. InInternational Conference on Learning Representations (ICLR)
2017
- [42]
-
[43]
Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Exploring the Limits of Knowledge Distillation for BERT.arXiv preprint arXiv:1910.01108 (2019)
work page internal anchor Pith review arXiv 2019
-
[44]
Sameer Wagh, Divya Gupta, and Nishanth Chandran. 2019. Securenn: 3-party secure computation for neural network training.Proceedings on Privacy Enhancing Technologies2019, 3 (2019), 26–49
2019
-
[45]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2WELCOME. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. InInternational Conference on Learning Representations (ICLR)
-
[46]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, et al. 2019. HuggingFace’s Transformers: State-of-the-art Natural Language Processing.arXiv preprint arXiv:1910.03771(2019)
work page internal anchor Pith review arXiv 2019
- [47]
- [48]
- [49]
-
[50]
Yancheng Zhang, Mengxin Zheng, Yuzhang Shang, Xun Chen, and Qian Lou. 2024. Heprune: Fast private training of deep neural networks with encrypted data prun- ing.Advances in Neural Information Processing Systems37 (2024), 51063–51084. 7 DAC ’26, June 2026, Long Beach, CA, USA Yukuan Zhang, Mengxin Zheng, and Qian Lou A Expert Pool Scalability We investigat...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.