Recognition: unknown
Complexity Guarantees for Zeroth-order Methods via Exponentially-shifted Gaussian Smoothing: Mitigating Dimension-dependence and Incorporating Decision-dependence
Pith reviewed 2026-05-10 10:17 UTC · model grok-4.3
The pith
Exponentially-shifted Gaussian smoothing reduces dimension dependence in zeroth-order stochastic optimization from quadratic to linear.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the exponentially-shifted Gaussian smoothing estimator yields gradient estimates whose moments depend linearly on dimension, enabling zeroth-order methods whose iteration complexities improve by a factor of n over prior Gaussian-smoothing schemes, with this property preserved under extensions to decision-dependent stochastic optimization where densities are either closed-form or obey moment bounds.
What carries the argument
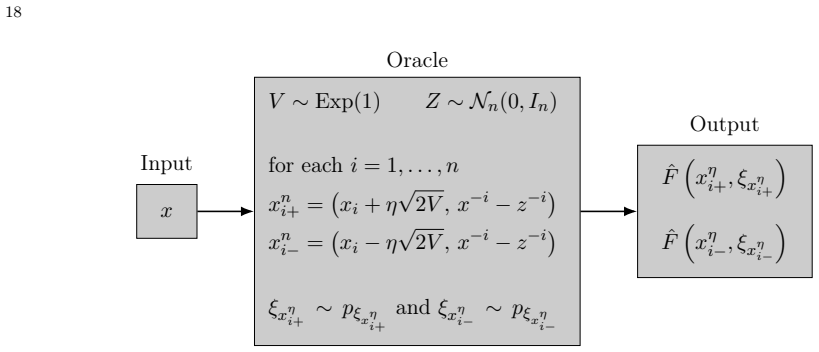
The exponentially-shifted Gaussian smoothing (esGs) estimator, which applies an exponential shift to standard Gaussian smoothing to obtain moment bounds with only linear dimension dependence.
Load-bearing premise
The objective must have bounded moments after smoothing, and any decision-dependent densities must satisfy corresponding moment bounds.
What would settle it
Numerical tests on high-dimensional instances showing that the gradient estimator's moments scale quadratically with dimension or that iteration counts fail to improve by a factor of n.
Figures

read the original abstract
In this paper, we consider two distinct challenges in the resolution of nonsmooth stochastic optimization. Of these, the first pertains to the pronounced dependence of dimension in Gaussian smoothing-enabled zeroth-order schemes, impeding applications to large-scale settings. Second, no unified analysis {exists} for smoothing-enabled stochastic zeroth-order methods, allowing for capturing standard and decision-dependent stochastic optimization. To contend with the first challenge, we introduce a new exponentially-shifted Gaussian smoothing {\bf esGs} estimator whose moment bounds enjoy a linear dependence on dimension (rather than a quadratic dependence as in standard Gaussian smoothing estimators). Second, we show that such an estimator can be extended in two distinct ways to address decision-dependent regimes where the underlying densities are either available in closed form or not. Notably, the resulting gradient estimators continue to display a linear dependence in dimension. We then develop an {\bf esGs}-enabled stochastic zeroth-order method applicable to nonsmooth strongly convex, convex, and {non-}convex regimes. Importantly, our guarantees provide improved dimension-dependence in iteration complexities (by a factor of problem dimension $n$) while maintaing similar oracle complexities. In addition, we also provide novel high probability guarantees and almost sure sublinear rate guarantees in convex settings, while a new subsequential almost sure convergence guarantee is provided in nonconvex regimes. Preliminary numerics support our theoretical findings show that the proposed schemes display improved computational times and more refined empirical accuracies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an exponentially-shifted Gaussian smoothing (esGs) estimator for zeroth-order stochastic optimization of nonsmooth objectives. The central claim is that the esGs estimator achieves second-moment bounds with only linear dependence on dimension n (versus quadratic for standard Gaussian smoothing), which yields iteration complexities improved by a factor of n while preserving comparable oracle complexity. The estimator is extended in two ways to decision-dependent regimes (closed-form densities or moment-bounded densities), with the linear dimension property preserved. The resulting stochastic zeroth-order algorithm is analyzed for nonsmooth strongly convex, convex, and nonconvex problems, delivering high-probability bounds, almost-sure sublinear rates in the convex case, and subsequential almost-sure convergence in the nonconvex case.
Significance. If the linear-in-n second-moment bound for the esGs estimator is rigorously established under the paper's stated assumptions, the work would meaningfully reduce the dimension dependence that currently limits zeroth-order methods in large-scale settings. The unified treatment of standard and decision-dependent stochastic optimization, together with the additional high-probability and almost-sure convergence results, would constitute a solid theoretical contribution to the field.
major comments (1)
- [Section defining the esGs estimator and its moment bounds (likely §3)] The load-bearing step is the claim that the esGs estimator satisfies E[||G_esGs||^2] = O(n) rather than O(n^2). The manuscript must supply the explicit moment calculation (presumably in the section defining the estimator and its properties) that shows how the exponential shift cancels the quadratic terms arising from the product of the smoothing kernel and the random direction. If this derivation relies on unstated restrictions on the objective or the decision-dependent measure beyond the “standard conditions” and “bounded moments after smoothing” mentioned in the abstract, the factor-n improvement in iteration complexity does not follow.
minor comments (1)
- [Abstract] Abstract: “maintaing” should be “maintaining”; the phrase “non- convex” contains an extraneous hyphen and brace that should be cleaned up for readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive overall assessment of the contribution. We address the single major comment below and will revise the manuscript to improve clarity on the requested derivation.
read point-by-point responses
-
Referee: [Section defining the esGs estimator and its moment bounds (likely §3)] The load-bearing step is the claim that the esGs estimator satisfies E[||G_esGs||^2] = O(n) rather than O(n^2). The manuscript must supply the explicit moment calculation (presumably in the section defining the estimator and its properties) that shows how the exponential shift cancels the quadratic terms arising from the product of the smoothing kernel and the random direction. If this derivation relies on unstated restrictions on the objective or the decision-dependent measure beyond the “standard conditions” and “bounded moments after smoothing” mentioned in the abstract, the factor-n improvement in iteration complexity does not follow.
Authors: We agree that the second-moment bound is the central technical step and that its derivation should be fully explicit. The manuscript already contains the moment calculation in Section 3 (immediately following the definition of the esGs estimator), where we expand E[||G_esGs||^2] using the product of the exponentially-shifted kernel and the random direction, then apply the shift parameter choice to cancel the quadratic-in-n terms that appear in the standard Gaussian case. The resulting bound is O(n) under precisely the conditions stated in the paper: Lipschitz continuity of the objective (or its smoothed version) and bounded second moments of the stochastic oracle after smoothing. No additional restrictions on the decision-dependent measure are used beyond those already listed in the abstract and Section 2. If the current presentation is not sufficiently detailed for the referee, we will expand the derivation with an extra lemma and all intermediate steps in the revised version. revision: yes
Circularity Check
No circularity detected; derivation relies on new estimator definition and derived bounds
full rationale
The paper introduces the esGs estimator as a novel construction and asserts that its second-moment bound scales linearly in dimension under standard nonsmoothness plus bounded-moment assumptions after smoothing. This bound is then used to obtain the claimed iteration-complexity improvement. No equation reduces to a prior fitted quantity renamed as a prediction, no uniqueness theorem is imported from the authors' own prior work, and no ansatz is smuggled via self-citation. The central claims therefore rest on the explicit construction and moment analysis of the new estimator rather than on any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective satisfies standard bounded-moment conditions after smoothing that enable the linear dimension bound.
- domain assumption Decision-dependent densities satisfy moment conditions whether or not they are available in closed form.
invented entities (1)
-
exponentially-shifted Gaussian smoothing (esGs) estimator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A theoretical and empirical comparison of gradient approximations in derivative-free optimization.Founda- tions of Computational Mathematics, 22(2):507–560, 2022
Albert S Berahas, Liyuan Cao, Krzysztof Choromanski, and Katya Scheinberg. A theoretical and empirical comparison of gradient approximations in derivative-free optimization.Founda- tions of Computational Mathematics, 22(2):507–560, 2022
2022
-
[2]
Léon Bottou, Frank E. Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning.SIAM Review, 60(2):223–311, 2018. doi: 10.1137/16M1080173. URL https://doi.org/10.1137/16M1080173
-
[3]
Boucheron, G
S. Boucheron, G. Lugosi, and P. Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. OUP Oxford, 2013. ISBN 9780199535255. URLhttps://books.google.com/ books?id=koNqWRluhP0C
2013
-
[4]
Yatong Chen, Wei Tang, Chien-Ju Ho, and Yang Liu. Performative prediction with bandit feedback: Learning through reparameterization.arXiv preprint arXiv:2305.01094, 2024
-
[5]
F. H. Clarke, Yu. S. Ledyaev, R. J. Stern, and P. R. Wolenski.Nonsmooth analysis and control theory, volume 178 ofGraduate Texts in Mathematics. Springer-Verlag, New York, 1998. ISBN 0-387-98336-8
1998
-
[6]
Complexity guarantees for an implicit smoothing-enabled method for stochastic mpecs.Mathematical Programming, 198(2):1153– 1225, 2023
Shisheng Cui, Uday V Shanbhag, and Farzad Yousefian. Complexity guarantees for an implicit smoothing-enabled method for stochastic mpecs.Mathematical Programming, 198(2):1153– 1225, 2023
2023
-
[7]
Stochastic approximation with decision- dependent distributions: asymptotic normality and optimality.Journal of Machine Learning Research, 25(90):1–49, 2024
Joshua Cutler, Mateo Diaz, and Dmitriy Drusvyatskiy. Stochastic approximation with decision- dependent distributions: asymptotic normality and optimality.Journal of Machine Learning Research, 25(90):1–49, 2024
2024
-
[8]
Stochastic optimization with decision-dependent distri- butions.Mathematics of Operations Research, 48(2):954–998, 2023
Dmitriy Drusvyatskiy and Lin Xiao. Stochastic optimization with decision-dependent distri- butions.Mathematics of Operations Research, 48(2):954–998, 2023. 42
2023
-
[9]
The minimization of semicontinuous functions: mollifier subgradients.Siam journal on control and optimization, 33(1):149–167, 1995
Yuri M Ermoliev, Vladimir I Norkin, and Roger JB Wets. The minimization of semicontinuous functions: mollifier subgradients.Siam journal on control and optimization, 33(1):149–167, 1995
1995
-
[10]
Concentration bounds for stochastic approximations
Noufel Frikha and Stéphane Menozzi. Concentration bounds for stochastic approximations. Electronic Communications in Probability, 17:1–15, 2012. doi: 10.1214/ECP.v17-1952
-
[11]
Michael C. Fu. Chapter 19 gradient estimation. In Shane G. Henderson and Barry L. Nelson, editors,Simulation, volume 13 ofHandbooks in Operations Research and Management Science, pages 575–616. Elsevier, 2006
2006
-
[12]
Some elementary inequalities relating to the gamma and incomplete gamma function.J
Walter Gautschi. Some elementary inequalities relating to the gamma and incomplete gamma function.J. Math. Phys, 38(1):77–81, 1959
1959
-
[13]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM journal on optimization, 23(4):2341–2368, 2013
Saeed Ghadimi and Guanghui Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM journal on optimization, 23(4):2341–2368, 2013
2013
-
[14]
Likelilood ratio gradient estimation: an overview
Peter W Glynn. Likelilood ratio gradient estimation: an overview. InProceedings of the 19th conference on Winter simulation, pages 366–375, 1987
1987
-
[15]
Likelihood ratio derviative estimators for stochastic systems
Peter W Glynn. Likelihood ratio derviative estimators for stochastic systems. InProceedings of the 21st conference on Winter simulation, pages 374–380, 1989
1989
-
[16]
A. A. Goldstein. Optimization of Lipschitz continuous functions.Math. Programming, 13(1): 14–22, 1977. ISSN 0025-5610. doi: 10.1007/BF01584320. URLhttps://doi.org/10.1007/ BF01584320
-
[17]
Zhiyu He, Saverio Bolognani, Florian Dörfler, and Michael Muehlebach. Decision-dependent stochastic optimization: The role of distribution dynamics.arXiv preprint arXiv:2503.07324, 2025
-
[18]
Stochastic approach for price optimization problems with decision-dependent uncertainty.European Journal of Operational Research, 322:541–553, 2025
Yuya Hikima and Akiko Takeda. Stochastic approach for price optimization problems with decision-dependent uncertainty.European Journal of Operational Research, 322:541–553, 2025
2025
-
[19]
Zeroth-order methods for nonconvex stochastic problems with decision-dependent distributions
Yuya Hikima and Akiko Takeda. Zeroth-order methods for nonconvex stochastic problems with decision-dependent distributions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17195–17203, 2025
2025
-
[20]
How to learn when data reacts to your model: performative gradient descent
Zachary Izzo, Lexing Ying, and James Zou. How to learn when data reacts to your model: performative gradient descent. InInternational Conference on Machine Learning, pages 4641–
-
[21]
Afrooz Jalilzadeh, Uday Shanbhag, Jose Blanchet, and Peter W. Glynn. Smoothed variable sample-size accelerated proximal methods for nonsmooth stochastic convex programs.Stoch. Syst., 12(4):373–410, 2022. ISSN 1946-5238. doi: 10.1287/stsy.2022.0095. URLhttps://doi. org/10.1287/stsy.2022.0095
-
[22]
Using importance samping in estimating weak derivative.arXiv preprint arXiv:2209.13184, 2022
Cheng Jie and Michael C Fu. Using importance samping in estimating weak derivative.arXiv preprint arXiv:2209.13184, 2022
-
[23]
Anatoli Juditsky and Arkadii S Nemirovski. Large deviations of vector-valued martingales in 2-smooth normed spaces.arXiv preprint arXiv:0809.0813, 2008
-
[24]
Lakshmanan and D
H. Lakshmanan and D. Farias. Decentralized recourse allocation in dynamic networks of agents. SIAM Journal on Optimization, 19(2):911–940, 2008
2008
-
[25]
Stochastic optimization schemes for performative prediction with nonconvex loss.Advances in Neural Information Processing Systems, 37:8673–8697, 2024
Qiang Li and Hoi-To Wai. Stochastic optimization schemes for performative prediction with nonconvex loss.Advances in Neural Information Processing Systems, 37:8673–8697, 2024
2024
-
[26]
Haitong Liu, Qiang Li, and Hoi-To Wai. Two-timescale derivative free optimization for perfor- mative prediction with markovian data.arXiv preprint arXiv:2310.05792, 2023
-
[27]
Zeroth-order gradient and quasi- newton methods for nonsmooth nonconvex stochastic optimization.SIAM Journal on Opti- mization, 36(2):564–596, 2026
Luke Marrinan, Uday V Shanbhag, and Farzad Yousefian. Zeroth-order gradient and quasi- newton methods for nonsmooth nonconvex stochastic optimization.SIAM Journal on Opti- mization, 36(2):564–596, 2026
2026
-
[28]
Stochastic opti- mization for performative prediction.Advances in Neural Information Processing Systems, 33: 4929–4939, 2020
Celestine Mendler-Dünner, Juan Perdomo, Tijana Zrnic, and Moritz Hardt. Stochastic opti- mization for performative prediction.Advances in Neural Information Processing Systems, 33: 4929–4939, 2020. 43
2020
-
[30]
Outside the echo chamber: Optimizing the performative risk
John P Miller, Juan C Perdomo, and Tijana Zrnic. Outside the echo chamber: Optimizing the performative risk. InInternational Conference on Machine Learning, pages 7710–7720. PMLR, 2021
2021
-
[31]
Nemirovski and D
A. Nemirovski and D. Yudin.Problem Complexity and Method Efficiency in Optimization. Wiley -Intersci. Ser. Discrete Math 15 John Wiley New York, 1983
1983
-
[32]
Random gradient-free minimization of convex functions
Yurii Nesterov and Vladimir Spokoiny. Random gradient-free minimization of convex functions. Foundations of Computational Mathematics, 17(2):527–566, 2017
2017
-
[33]
Performative prediction
Juan Perdomo, Tijana Zrnic, Celestine Mendler-Dünner, and Moritz Hardt. Performative prediction. InInternational Conference on Machine Learning, pages 7599–7609. PMLR, 2020
2020
-
[34]
Polyak.Introduction to Optimization
Boris T. Polyak.Introduction to Optimization. Optimization Software, New York, 1987
1987
-
[35]
Zeroth-order methods for nondifferen- tiable, nonconvex, and hierarchical federated optimization.Advances in Neural Information Processing Systems, 36, 2023
Yuyang Qiu, Uday Shanbhag, and Farzad Yousefian. Zeroth-order methods for nondifferen- tiable, nonconvex, and hierarchical federated optimization.Advances in Neural Information Processing Systems, 36, 2023
2023
-
[36]
Decision-dependent risk minimization in geometrically decaying dynamic environments
Mitas Ray, Lillian J Ratliff, Dmitriy Drusvyatskiy, and Maryam Fazel. Decision-dependent risk minimization in geometrically decaying dynamic environments. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8081–8088, 2022
2022
-
[37]
The Annals of Mathe- matical Statistics22(1), 79–86 (1951) https://doi.org/10.1214/aoms/1177729694
Herbert Robbins and Sutton Monro. A Stochastic Approximation Method.The Annals of Mathematical Statistics, 22(3):400 – 407, 1951. doi: 10.1214/aoms/1177729586. URLhttps: //doi.org/10.1214/aoms/1177729586
-
[38]
A convergence theorem for non negative almost su- permartingales and some applications
Herbert Robbins and David Siegmund. A convergence theorem for non negative almost su- permartingales and some applications. InOptimizing methods in statistics, pages 233–257. Elsevier, 1971
1971
-
[39]
Zeroth-order randomized block methods for con- strained minimization of expectation-valued lipschitz continuous functions
Uday V Shanbhag and Farzad Yousefian. Zeroth-order randomized block methods for con- strained minimization of expectation-valued lipschitz continuous functions. In2021 Seventh Indian Control Conference (ICC), pages 7–12. IEEE, 2021
2021
-
[40]
Shapiro, D
A. Shapiro, D. Dentcheva, and A. Ruszczyński.Lectures on Stochastic Programming: Modeling and Theory, volume 16. SIAM, 2014
2014
-
[41]
Multivariate stochastic approximation using a simultaneous perturbation gra- dient approximation.IEEE transactions on automatic control, 37(3):332–341, 1992
James C Spall. Multivariate stochastic approximation using a simultaneous perturbation gra- dient approximation.IEEE transactions on automatic control, 37(3):332–341, 1992
1992
-
[42]
V. A. Steklov. Sur les expressions asymptotiques decertaines fonctions définies par les équations différentielles du second ordre et leers applications au problème du dévelopement d’une fonction arbitraire en séries procédant suivant les diverses fonctions.Comm. Charkov Math. Soc., 2(10): 97–199, 1907
1907
-
[43]
Jean-Philippe Vial. Strong and weak convexity of sets and functions.Mathematics of Opera- tions Research, 8(2):231–259, 1983. ISSN 0364765X, 15265471. URLhttp://www.jstor.org/ stable/3689591
-
[44]
Improving dimension depen- dence in complexity guarantees for zeroth-order methods via exponentially-shifted gaussian smoothing
Mingrui Wang, Prakash Chakraborty, and Uday V Shanbhag. Improving dimension depen- dence in complexity guarantees for zeroth-order methods via exponentially-shifted gaussian smoothing. In2024 Winter Simulation Conference (WSC), pages 3193–3204. IEEE, 2024
2024
-
[45]
Zifan Wang, Changxin Liu, Thomas Parisini, Michael M Zavlanos, and Karl H Johansson. Con- strained optimization with decision-dependent distributions.arXiv preprint arXiv:2310.02384, 2023
-
[46]
MIT press Cambridge, MA, 2006
Christopher KI Williams and Carl Edward Rasmussen.Gaussian processes for machine learn- ing, volume 2. MIT press Cambridge, MA, 2006
2006
-
[47]
Yousefian, A
F. Yousefian, A. Nedić, and U. V. Shanbhag. On stochastic gradient and subgradient methods with adaptive steplength sequences.Automatica, 48(1):56–67, 2012. 44 (M. W ang) Harold and Inge Marcus Department of Industrial and Manuf acturing Engineering, The Pennsyl v ania State University, University Park, PA 16802 United States, Email address:mvw5822@psu.ed...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.