Recognition: unknown
HyperGVL: Benchmarking and Improving Large Vision-Language Models in Hypergraph Understanding and Reasoning
Pith reviewed 2026-05-10 08:54 UTC · model grok-4.3
The pith
HyperGVL is the first benchmark to test how well vision-language models understand and reason over hypergraphs, with a router that improves them by picking better representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HyperGVL establishes the first standardized evaluation of LVLMs on hypergraph understanding and reasoning by supplying 84,000 vision-language QA examples that span 12 tasks, multiscale synthetic hypergraphs, and real citation and protein networks; it further shows that performance varies sharply with the choice of textual or visual encoding and introduces the generalizable router WiseHyGR that learns adaptive representations to raise model accuracy on the same tasks.
What carries the argument
The HyperGVL benchmark (12 tasks plus 12 text and image encodings) together with the WiseHyGR router that selects representations adaptively for each input.
If this is right
- Current LVLMs handle simple element counting but drop sharply on NP-hard hypergraph problems.
- Switching between text and image encodings can change accuracy by large margins on the same hypergraph.
- An adaptive router that picks representations per example lifts performance without retraining the base model.
- Real citation and protein networks now have a repeatable test suite for multimodal AI.
- Future LVLM training can target the specific failure modes revealed by the 12-task suite.
Where Pith is reading between the lines
- If WiseHyGR-style routing generalizes, it could be applied to other complex structures such as simplicial complexes or temporal graphs.
- Improved hypergraph reasoning would let LVLMs assist directly in analyzing biological interaction networks or community detection in social data.
- The benchmark supplies a ready-made training signal for next-generation models that need to handle higher-order relations beyond ordinary graphs.
- Systematic comparison across 12 encodings suggests that no single representation is universally best, pointing to a need for dynamic multimodal encoders.
Load-bearing premise
That the chosen 12 tasks and the mix of synthetic plus real-world hypergraphs, shown through 12 specific text and image formats, give a fair and complete picture of what hypergraph understanding actually requires from an LVLM.
What would settle it
A new LVLM that scores near the top on every HyperGVL task even when forced to use a single fixed representation instead of the router, or a version of WiseHyGR that fails to raise accuracy on a held-out set of real protein hypergraphs.
Figures




read the original abstract
Large Vision-Language Models (LVLMs) consistently require new arenas to guide their expanding boundaries, yet their capabilities with hypergraphs remain unexplored. In the real world, hypergraphs have significant practical applications in areas such as life sciences and social communities. Recent advancements in LVLMs have shown promise in understanding complex topologies, yet there remains a lack of a benchmark to delineate the capabilities of LVLMs with hypergraphs, leaving the boundaries of their abilities unclear. To fill this gap, in this paper, we introduce $\texttt{HyperGVL}$, the first benchmark to evaluate the proficiency of LVLMs in hypergraph understanding and reasoning. $\texttt{HyperGVL}$ provides a comprehensive assessment of 12 advanced LVLMs across 84,000 vision-language question-answering (QA) samples spanning 12 tasks, ranging from basic component counting to complex NP-hard problem reasoning. The involved hypergraphs contain multiscale synthetic structures and real-world citation and protein networks. Moreover, we examine the effects of 12 textual and visual hypergraph representations and introduce a generalizable router $\texttt{WiseHyGR}$ that improves LVLMs in hypergraph via learning adaptive representations. We believe that this work is a step forward in connecting hypergraphs with LVLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyperGVL, the first benchmark for evaluating large vision-language models (LVLMs) on hypergraph understanding and reasoning. It comprises 84,000 vision-language QA samples spanning 12 tasks (from basic component counting to NP-hard reasoning) over multiscale synthetic hypergraphs and real-world citation/protein networks. The work evaluates 12 advanced LVLMs, analyzes the impact of 12 textual and visual hypergraph representations, and proposes the WiseHyGR router that learns to select adaptive representations to improve LVLM performance on these tasks.
Significance. If the benchmark tasks genuinely require comprehension of higher-order hypergraph structure rather than permitting non-structural shortcuts, HyperGVL would constitute a valuable new evaluation resource for an underexplored capability with applications in life sciences and social networks. The scale (84k samples), breadth (12 tasks and 12 representations), and the constructive addition of a generalizable router that demonstrably improves performance are positive features. The paper ships a large-scale empirical benchmark and an adaptive routing mechanism; these are concrete contributions that can be built upon.
major comments (2)
- [§3, §4] §3 (Benchmark Construction) and §4 (Task Definitions): The manuscript does not describe explicit controls, ablations, or human validation studies to confirm that the 12 tasks cannot be solved via visual shortcuts (e.g., node counting via image segmentation) or textual heuristics (e.g., degree-based pattern matching on citation text) without engaging hyperedge incidence structure. This is load-bearing for the central claim that HyperGVL measures hypergraph proficiency.
- [§5.2] §5.2 (WiseHyGR Training and Evaluation): The router's training procedure, dataset split, and evaluation lack reported error bars, statistical significance tests, or ablation against fixed-representation baselines. Without these, it is difficult to assess whether the reported improvements are robust or merely reflect variance in the 12 LVLMs.
minor comments (3)
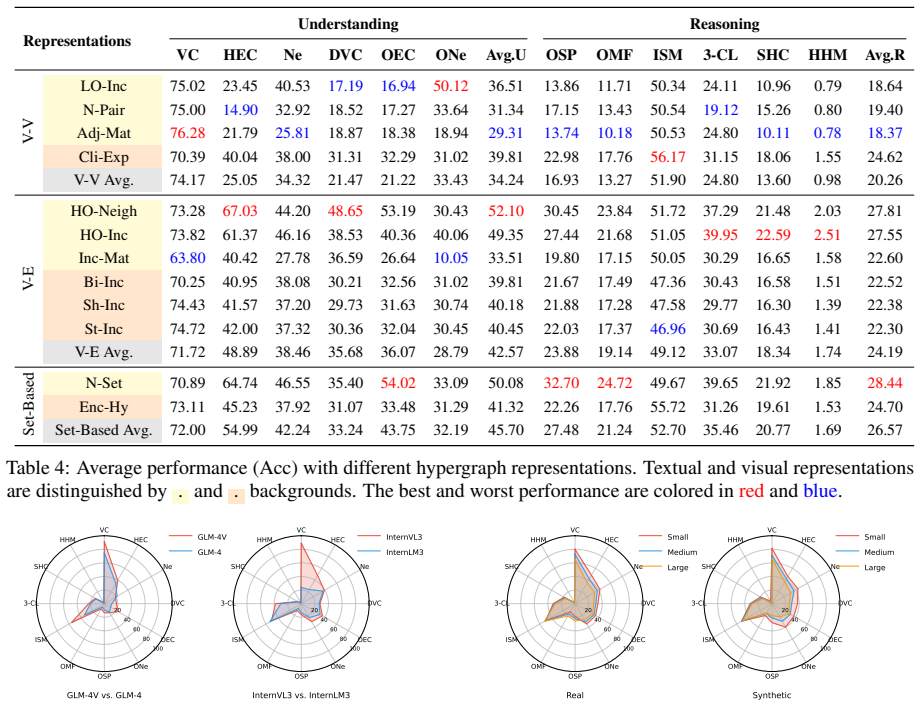
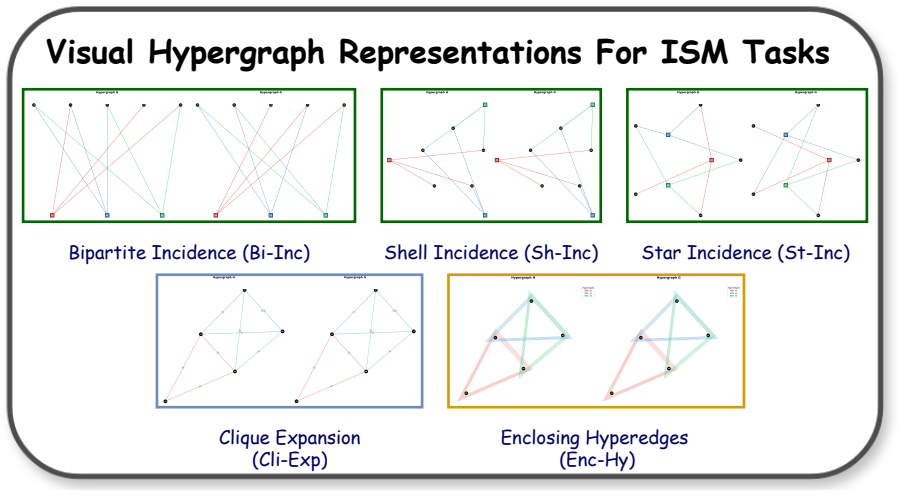
- [Table 1, Figure 3] Table 1 and Figure 3: Axis labels and legend entries use inconsistent notation for hypergraph representations (e.g., 'Incidence Matrix' vs. 'IM'); standardize terminology across text, tables, and figures.
- [§2] §2 (Related Work): The discussion of prior graph and hypergraph benchmarks omits recent multimodal graph QA datasets; add citations to ensure completeness.
- [Appendix A] Appendix A (Data Generation): The multiscale synthetic hypergraph generation parameters (e.g., hyperedge size distribution) are only summarized; provide the exact sampling procedure or code link for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects for strengthening the validity of the benchmark and the router evaluation. We address each major comment point-by-point below and commit to revisions that directly incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§3, §4] §3 (Benchmark Construction) and §4 (Task Definitions): The manuscript does not describe explicit controls, ablations, or human validation studies to confirm that the 12 tasks cannot be solved via visual shortcuts (e.g., node counting via image segmentation) or textual heuristics (e.g., degree-based pattern matching on citation text) without engaging hyperedge incidence structure. This is load-bearing for the central claim that HyperGVL measures hypergraph proficiency.
Authors: We agree that explicit validation against non-structural shortcuts is essential to substantiate the claim that HyperGVL evaluates hypergraph understanding. The task suite in §4 was constructed so that higher-order tasks (e.g., hyperedge membership queries, NP-hard problems such as hypergraph coloring or matching) inherently depend on incidence relations that cannot be reduced to simple node/edge counts or visual segmentation; basic counting tasks were included as controls but are not the sole focus. Nevertheless, the current manuscript does not report the requested ablations or human studies. In the revised version we will add: (i) controlled ablations that randomize or remove hyperedge incidence information while preserving node/edge visuals and text, (ii) comparisons against non-structural baselines (e.g., image-segmentation-only and text-heuristic-only solvers), and (iii) a human validation study on a stratified subset of tasks. These results will be presented in expanded sections §3 and §4. revision: yes
-
Referee: [§5.2] §5.2 (WiseHyGR Training and Evaluation): The router's training procedure, dataset split, and evaluation lack reported error bars, statistical significance tests, or ablation against fixed-representation baselines. Without these, it is difficult to assess whether the reported improvements are robust or merely reflect variance in the 12 LVLMs.
Authors: We acknowledge that the current presentation of WiseHyGR results in §5.2 is insufficiently rigorous. While the router is trained on a held-out split of the HyperGVL training set and selects among the 12 representations, the manuscript reports only mean performance gains without variance estimates or formal comparisons. In the revision we will: (1) report standard deviations across multiple random seeds and training runs, (2) include paired statistical significance tests (e.g., Wilcoxon signed-rank or t-tests) against each fixed-representation baseline, and (3) add an explicit ablation table comparing WiseHyGR to every one of the 12 fixed representations individually. The training procedure, dataset splits, and hyperparameter choices will be described in full detail with these metrics. revision: yes
Circularity Check
Benchmark and router proposal exhibits no derivation-chain circularity
full rationale
The paper introduces an external benchmark (HyperGVL) with 12 tasks on synthetic and real-world hypergraphs plus a router (WiseHyGR) for adaptive representations. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described claims. The evaluation of 12 external LVLMs on 84k QA samples is independent of the benchmark construction itself, and the router's learning is a standard downstream application rather than a tautological reduction. This matches the default expectation for benchmark papers whose central contribution is data and tooling rather than closed-form derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption QA samples on synthetic and real-world hypergraphs can serve as a valid proxy for hypergraph understanding and reasoning capabilities in LVLMs
invented entities (1)
-
WiseHyGR router
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Gita: Graph to visual and textual integration for vision-language graph reasoning.Advances in Neural Information Processing Systems, 37:44–72. Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, and 1 oth- ers. 2024. Deepseek-vl2: Mixture-of-experts vision- language models for advanced...
work page internal anchor Pith review arXiv 2024
-
[2]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Hypergcn: A new method for training graph convolutional networks on hypergraphs.Advances in neural information processing systems, 32. Zhilin Yang, William Cohen, and Ruslan Salakhudi- nov. 2016a. Revisiting semi-supervised learning with graph embeddings. InInternational conference on machine learning, pages 40–48. PMLR. Zhilin Yang, William Cohen, and Ru...
work page internal anchor Pith review arXiv 2024
-
[3]
Ans:”. Hyperedge Counting (HEC) Q:How many hyperedges are in the hyper- graphG? List the answer after “Ans:
evaluate the problem-solving capabilities of LVLMs in graph theory problems. Vision- Graph assumes that visual graphs are naturally equipped, while GVLQA generates visual graphs from scratch. Both benchmarks include numerous synthetic visual graphs and complex graph theory problems. Ai et al. (2024) introduces a multimodal instruction-following benchmark ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.