Recognition: unknown
CodeMMR: Bridging Natural Language, Code, and Image for Unified Retrieval
Pith reviewed 2026-05-10 08:45 UTC · model grok-4.3
The pith
CodeMMR aligns natural language, code, and images in one embedding space for improved multimodal code retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
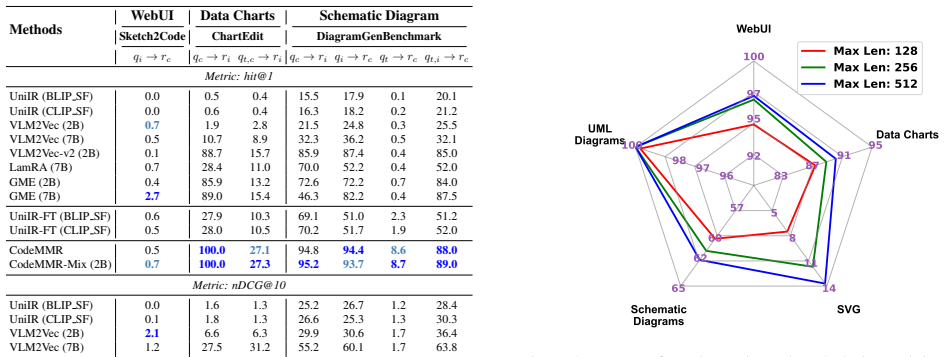
The paper introduces CodeMMR as a model that jointly embeds natural language, code, and images into a shared semantic space using instruction-based multimodal alignment, enabling strong performance across different modalities and languages on the new MMCoIR benchmark while also boosting RAG-based code generation.
What carries the argument
Instruction-based multimodal alignment, which uses targeted instructions to map inputs from different modalities into a common vector representation for similarity-based retrieval.
If this is right
- Multimodal queries, such as a text description paired with an image, can retrieve relevant code more accurately.
- Integration into RAG systems leads to higher fidelity code outputs with better visual grounding.
- Retrieval performance holds across eight programming languages and various libraries without custom models.
- Code search expands beyond text to include visual domains like SVGs, schematics, and UML diagrams.
Where Pith is reading between the lines
- Development environments might adopt unified search that accepts screenshots or sketches as input for finding code.
- The shared space could support transfer to new tasks like debugging with visual outputs.
- Scaling this alignment to larger models may further close the gap between retrieval and generation in AI coding.
Load-bearing premise
That instruction-based multimodal alignment can effectively create a shared semantic space without losing critical modality-specific details or introducing alignment artifacts that undermine retrieval accuracy.
What would settle it
If CodeMMR shows no advantage over existing baselines on the MMCoIR benchmark when tested with image or code queries, the benefit of the unified embedding approach would be called into question.
Figures









read the original abstract
Code search, framed as information retrieval (IR), underpins modern software engineering and increasingly powers retrieval-augmented generation (RAG), improving code discovery, reuse, and the reliability of LLM-based coding. Yet existing code IR models remain largely text-centric and often overlook the visual and structural aspects inherent in programming artifacts such as web interfaces, data visualizations, SVGs, schematic diagrams, and UML. To bridge this gap, we introduce MMCoIR, the first comprehensive benchmark for evaluating multimodal code IR across five visual domains, eight programming languages, eleven libraries, and show the challenge of the task through extensive evaluation. Therefore, we then propose CodeMMR, a unified retrieval model that jointly embeds natural language, code, and images into a shared semantic space through instruction-based multimodal alignment. CodeMMR achieves strong generalization across modalities and languages, outperforming competitive baselines (e.g., UniIR, GME, VLM2Vec) by an average of 10 points on nDCG@10. Moreover, integrating CodeMMR into RAG enhances code generation fidelity and visual grounding on unseen code generation tasks, underscoring the potential of multimodal retrieval as a core enabler for next-generation intelligent programming systems. Datasets are available at HuggingFace.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal data from code, text, and images can be aligned into a shared semantic space via instruction tuning without substantial information loss.
Reference graph
Works this paper leans on
-
[1]
Unified modeling language code genera- tion from diagram images using multimodal large language models.Machine Learning with Applications, page 100660,
Averi Bates, Ryan Vavricka, Shane Carleton, Ruosi Shao, and Chongle Pan. Unified modeling language code genera- tion from diagram images using multimodal large language models.Machine Learning with Applications, page 100660,
-
[2]
Tikzero: Zero-shot text-guided graphics program synthesis
Jonas Belouadi, Eddy Ilg, Margret Keuper, Hideki Tanaka, Masao Utiyama, Raj Dabre, Steffen Eger, and Simone Ponzetto. Tikzero: Zero-shot text-guided graphics program synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17793–17806, 2025. 4
2025
-
[3]
Revela: Dense retriever learning via language modeling.arXiv preprint arXiv:2506.16552, 2025
Fengyu Cai, Tong Chen, Xinran Zhao, Sihao Chen, Hong- ming Zhang, Sherry Tongshuang Wu, Iryna Gurevych, and Heinz Koeppl. Revela: Dense retriever learning via language modeling.arXiv preprint arXiv:2506.16552, 2025. 3
-
[4]
Xuanming Cui, Jianpeng Cheng, Hong-you Chen, Satya Narayan Shukla, Abhijeet Awasthi, Xichen Pan, Chaitanya Ahuja, Shlok Kumar Mishra, Qi Guo, Ser-Nam Lim, et al. Think then embed: Generative context improves multimodal embedding.arXiv preprint arXiv:2510.05014,
-
[5]
Introducing visual studio code
Alessandro Del Sole. Introducing visual studio code. InVi- sual Studio Code Distilled: Evolved Code Editing for Win- dows, macOS, and Linux, pages 1–17. Springer, 2023. 1
2023
-
[6]
Coquir: A comprehen- sive benchmark for code quality-aware information retrieval
Jiahui Geng, Fengyu Cai, Shaobo Cui, Qing Li, Liang- wei Chen, Chenyang Lyu, Haonan Li, Derui Zhu, Walter Pretschner, Heinz Koeppl, et al. Coquir: A comprehen- sive benchmark for code quality-aware information retrieval. arXiv preprint arXiv:2506.11066, 2025. 1, 3
-
[7]
Webcode2m: A real-world dataset for code generation from webpage designs
Yi Gui, Zhen Li, Yao Wan, Yemin Shi, Hongyu Zhang, Bo- hua Chen, Yi Su, Dongping Chen, Siyuan Wu, Xing Zhou, et al. Webcode2m: A real-world dataset for code generation from webpage designs. InProceedings of the ACM on Web Conference 2025, pages 1834–1845, 2025. 1, 7
2025
-
[8]
CoSQA: 20,000+ web queries for code search and question answer- ing
Junjie Huang, Duyu Tang, Linjun Shou, Ming Gong, Ke Xu, Daxin Jiang, Ming Zhou, and Nan Duan. CoSQA: 20,000+ web queries for code search and question answer- ing. InProceedings of the 59th Annual Meeting of the As- sociation for Computational Linguistics and the 11th Inter- national Joint Conference on Natural Language Processing (Volume 1: Long Papers), ...
2021
-
[9]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Al- lamanis, and Marc Brockschmidt. Codesearchnet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436, 2019. 1, 3
work page internal anchor Pith review arXiv 1909
-
[10]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[11]
VLM2vec: Training vision- language models for massive multimodal embedding tasks
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. VLM2vec: Training vision- language models for massive multimodal embedding tasks. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2, 5, 7
2025
-
[12]
XCodeEval: An execution-based large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval
Mohammad Abdullah Matin Khan, M Saiful Bari, Xuan Long Do, Weishi Wang, Md Rizwan Parvez, and Shafiq Joty. XCodeEval: An execution-based large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
2024
-
[13]
Jovana Kondic, Pengyuan Li, Dhiraj Joshi, Zexue He, Shafiq Abedin, Jennifer Sun, Ben Wiesel, Eli Schwartz, Ahmed Nassar, Bo Wu, et al. Chartgen: Scaling chart understanding via code-guided synthetic chart generation.arXiv preprint arXiv:2507.19492, 2025. 1, 4
-
[14]
Unlocking the conversion of web screenshots into HTML code with the websight dataset
Hugo Laurenc ¸on, L´eo Tronchon, and Victor Sanh. Unlock- ing the conversion of web screenshots into html code with the websight dataset.arXiv preprint arXiv:2403.09029, 2024. 4
-
[15]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 2
2022
-
[16]
Sketch2Code: Eval- uating vision-language models for interactive web design prototyping
Ryan Li, Yanzhe Zhang, and Diyi Yang. Sketch2Code: Eval- uating vision-language models for interactive web design prototyping. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Vol- ume 1: Long Papers), pages 3921–3955, Albuquerque, New Mexico, 2025....
2025
-
[17]
CoIR: A comprehensive benchmark for code information retrieval models
Xiangyang Li, Kuicai Dong, Yi Quan Lee, Wei Xia, Hao Zhang, Xinyi Dai, Yasheng Wang, and Ruiming Tang. CoIR: A comprehensive benchmark for code information retrieval models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22074–22091, Vienna, Austria, 2025. Asso- ciation for Computat...
2025
-
[18]
MM-EMBED: UNIVERSAL MULTIMODAL RETRIEV AL WITH MUL- TIMODAL LLMS
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. MM-EMBED: UNIVERSAL MULTIMODAL RETRIEV AL WITH MUL- TIMODAL LLMS. InThe Thirteenth International Confer- ence on Learning Representations, 2025. 2
2025
-
[19]
CodeXEmbed: A generalist embedding model family for multilingual and multi-task code retrieval
Ye Liu, Rui Meng, Shafiq Joty, silvio savarese, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. CodeXEmbed: A generalist embedding model family for multilingual and multi-task code retrieval. InSecond Conference on Language Modeling, 2025. 3, 7
2025
-
[20]
Lamra: Large multimodal model as your advanced retrieval assistant
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4015–4025, 2025. 1, 2, 5
2025
-
[21]
arXiv preprint arXiv:2507.04590 , year=
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, et al. Vlm2vec-v2: Advancing multimodal em- bedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590, 2025. 2, 5, 7
-
[22]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 2
2021
-
[24]
Rodriguez, Abhay Puri, Shubham Agarwal, Issam H
Juan A. Rodriguez, Abhay Puri, Shubham Agarwal, Issam H. Laradji, Pau Rodriguez, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Starvector: Gener- ating scalable vector graphics code from images and text. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 16175–16186,
-
[25]
Retrieval on source code: a neural code search
Saksham Sachdev, Hongyu Li, Sifei Luan, Seohyun Kim, Koushik Sen, and Satish Chandra. Retrieval on source code: a neural code search. InProceedings of the 2nd ACM SIG- PLAN international workshop on machine learning and pro- gramming languages, pages 31–41, 2018. 1
2018
-
[26]
EvoR: Evolving re- trieval for code generation
Hongjin Su, Shuyang Jiang, Yuhang Lai, Haoyuan Wu, Boao Shi, Che Liu, Qian Liu, and Tao Yu. EvoR: Evolving re- trieval for code generation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 2538– 2554, Miami, Florida, USA, 2024. Association for Compu- tational Linguistics. 1
2024
-
[27]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Xu, Yiqing Xie, Graham Neubig, and Daniel Fried
Zora Zhiruo Wang, Akari Asai, Xinyan Velocity Yu, Frank F. Xu, Yiqing Xie, Graham Neubig, and Daniel Fried. CodeRAG-bench: Can retrieval augment code generation? InFindings of the Association for Computational Linguis- tics: NAACL 2025, pages 3199–3214, Albuquerque, New Mexico, 2025. Association for Computational Linguistics. 3
2025
-
[29]
Uniir: Train- ing and benchmarking universal multimodal information re- trievers
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. Uniir: Train- ing and benchmarking universal multimodal information re- trievers. InEuropean Conference on Computer Vision, pages 387–404. Springer, 2024. 2, 5
2024
-
[30]
From words to structured visuals: A benchmark and framework for text-to-diagram generation and editing
Jingxuan Wei, Cheng Tan, Qi Chen, Gaowei Wu, Siyuan Li, Zhangyang Gao, Linzhuang Sun, Bihui Yu, and Ruifeng Guo. From words to structured visuals: A benchmark and framework for text-to-diagram generation and editing. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 13315–13325, 2025. 3, 4
2025
-
[31]
Chartmimic: Evaluating LMM’s cross-modal reason- ing capability via chart-to-code generation
Cheng Yang, Chufan Shi, Yaxin Liu, Bo Shui, Junjie Wang, Mohan Jing, Linran XU, Xinyu Zhu, Siheng Li, Yuxiang Zhang, Gongye Liu, Xiaomei Nie, Deng Cai, and Yujiu Yang. Chartmimic: Evaluating LMM’s cross-modal reason- ing capability via chart-to-code generation. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 1, 7, 8
2025
-
[32]
OmniSVG: A unified scalable vector graph- ics generation model
Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Fukun Yin, Jiaxu Zhang, Liao Wang, Gang YU, Xingjun Ma, and Yu-Gang Jiang. OmniSVG: A unified scalable vector graph- ics generation model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 4
2025
-
[33]
Xing, Xiaodan Liang, and Zhiqiang Shen
Sukmin Yun, Haokun Lin, Rusiru Thushara, Moham- mad Qazim Bhat, Yongxin Wang, Zutao Jiang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, Haonan Li, Preslav Nakov, Timothy Baldwin, Zhengzhong Liu, Eric P. Xing, Xiaodan Liang, and Zhiqiang Shen. Web2code: A large-scale webpage-to-code dataset and evaluation frame- work for multimodal LLMs. InThe Thirty...
2024
-
[34]
Web2code: A large- scale webpage-to-code dataset and evaluation framework for multimodal llms.Advances in neural information processing systems, 37:112134–112157, 2024
Sukmin Yun, Rusiru Thushara, Mohammad Bhat, Yongxin Wang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, Haonan Li, Preslav Nakov, et al. Web2code: A large- scale webpage-to-code dataset and evaluation framework for multimodal llms.Advances in neural information processing systems, 37:112134–112157, 2024. 1
2024
-
[35]
RepoCoder: Repository-level code completion through iter- ative retrieval and generation
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. RepoCoder: Repository-level code completion through iter- ative retrieval and generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing, pages 2471–2484, Singapore, 2023. Association for Computational...
2023
-
[36]
Magiclens: self- supervised image retrieval with open-ended instructions
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. Magiclens: self- supervised image retrieval with open-ended instructions. In Proceedings of the 41st International Conference on Ma- chine Learning. JMLR.org, 2024. 2
2024
-
[37]
Syntax-aware retrieval augmented code generation
Xiangyu Zhang, Yu Zhou, Guang Yang, and Taolue Chen. Syntax-aware retrieval augmented code generation. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1291–1302, Singapore, 2023. Associa- tion for Computational Linguistics. 1
2023
- [38]
-
[39]
ChartE- dit: How far are MLLMs from automating chart analysis? evaluating MLLMs’ capability via chart editing
Xuanle Zhao, Xuexin Liu, Yang Haoyue, Xianzhen Luo, Fanhu Zeng, Jianling Li, Qi Shi, and Chi Chen. ChartE- dit: How far are MLLMs from automating chart analysis? evaluating MLLMs’ capability via chart editing. InFind- ings of the Association for Computational Linguistics: ACL 2025, pages 3616–3630, Vienna, Austria, 2025. Association for Computational Ling...
2025
-
[40]
Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, and Maosong Sun. ChartCoder: Advancing multimodal large language model for chart-to-code genera- tion. InProceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Pa- pers), pages 7333–7348, Vienna, Austria, 2025. Association for Computatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.