Recognition: unknown
Hierarchical Active Inference using Successor Representations
Pith reviewed 2026-05-10 09:39 UTC · model grok-4.3
The pith
Lower-level successor representations and active inference planning bootstrap higher-level abstract states and actions that enable efficient planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
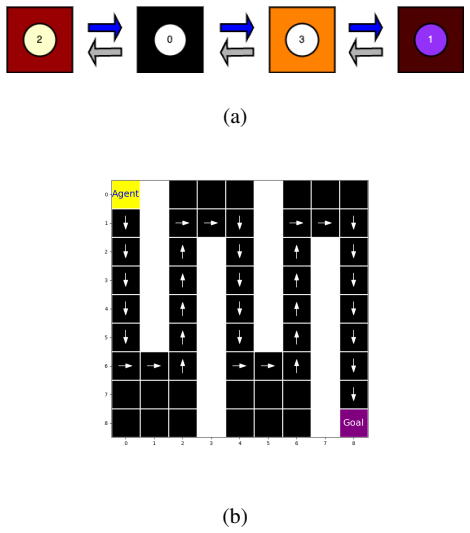
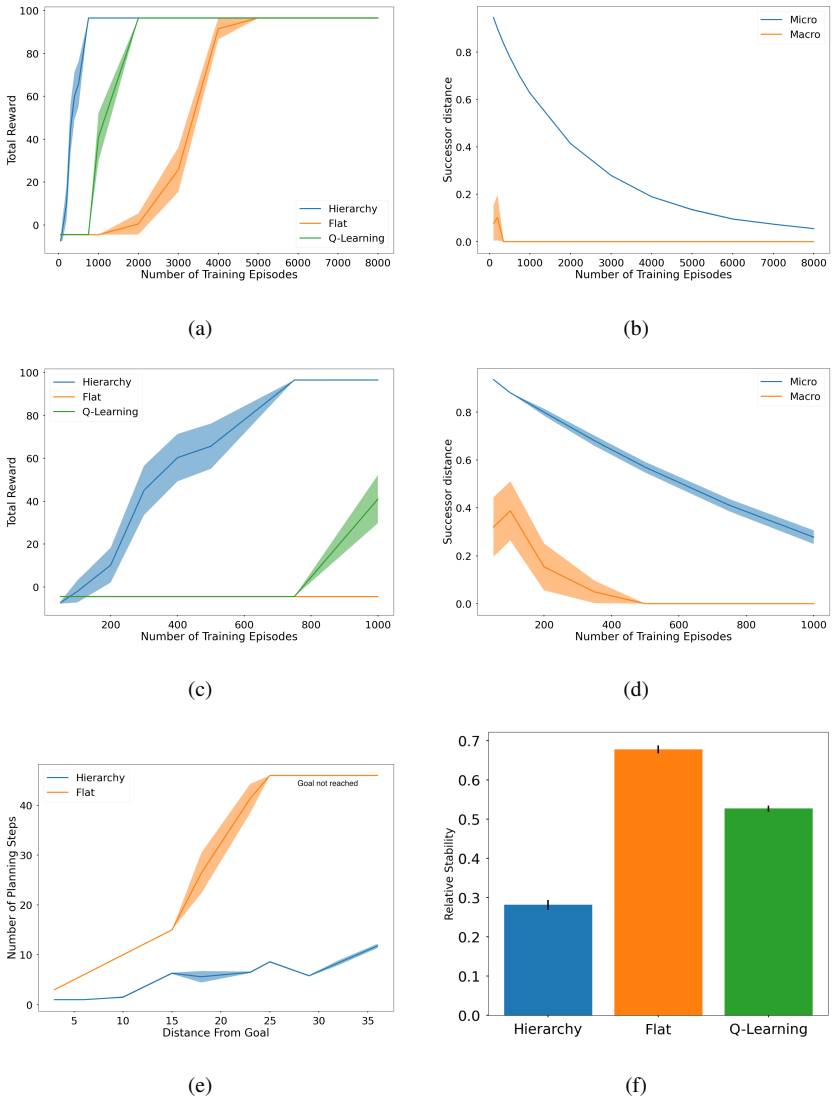
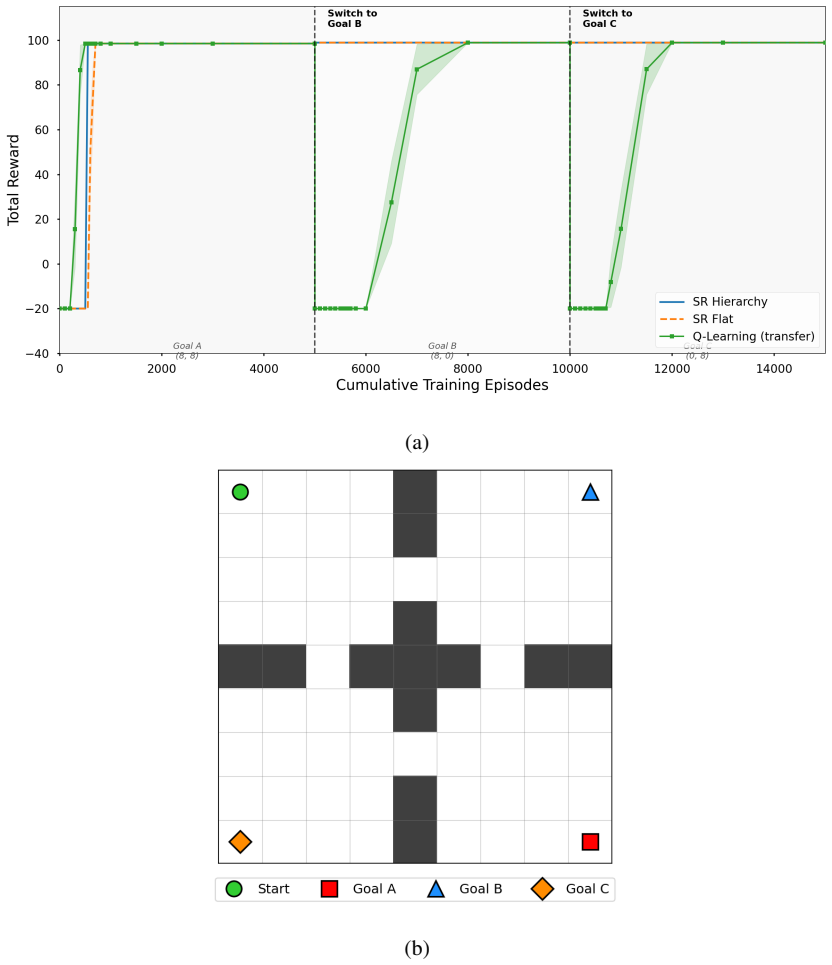
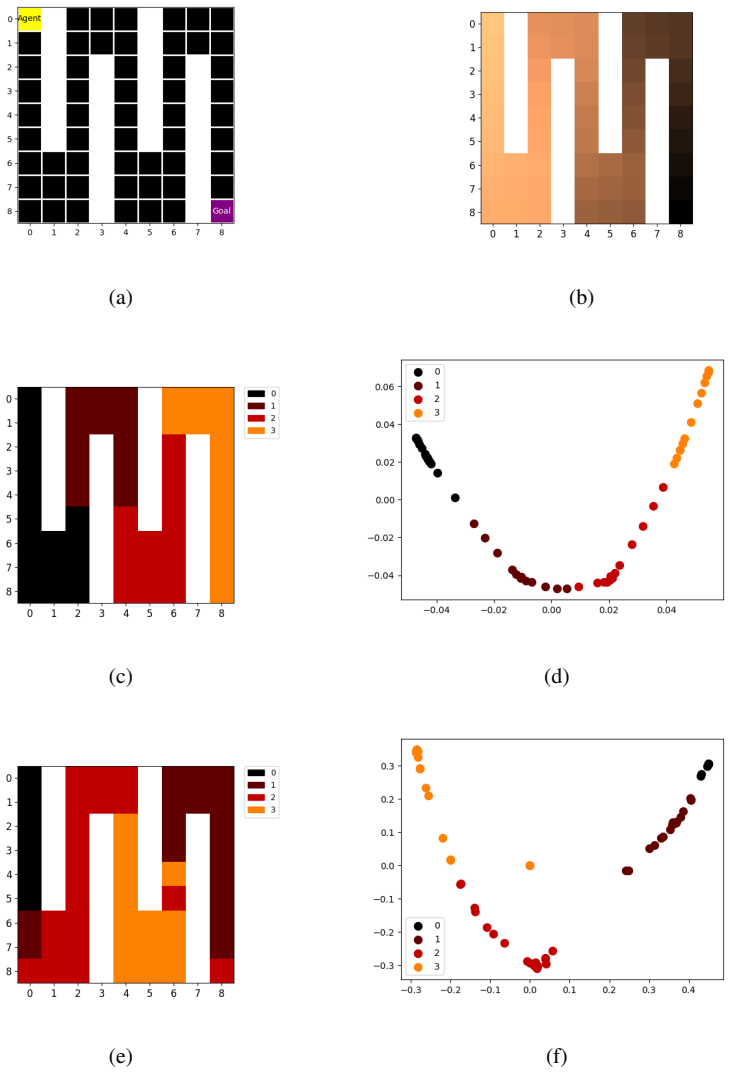
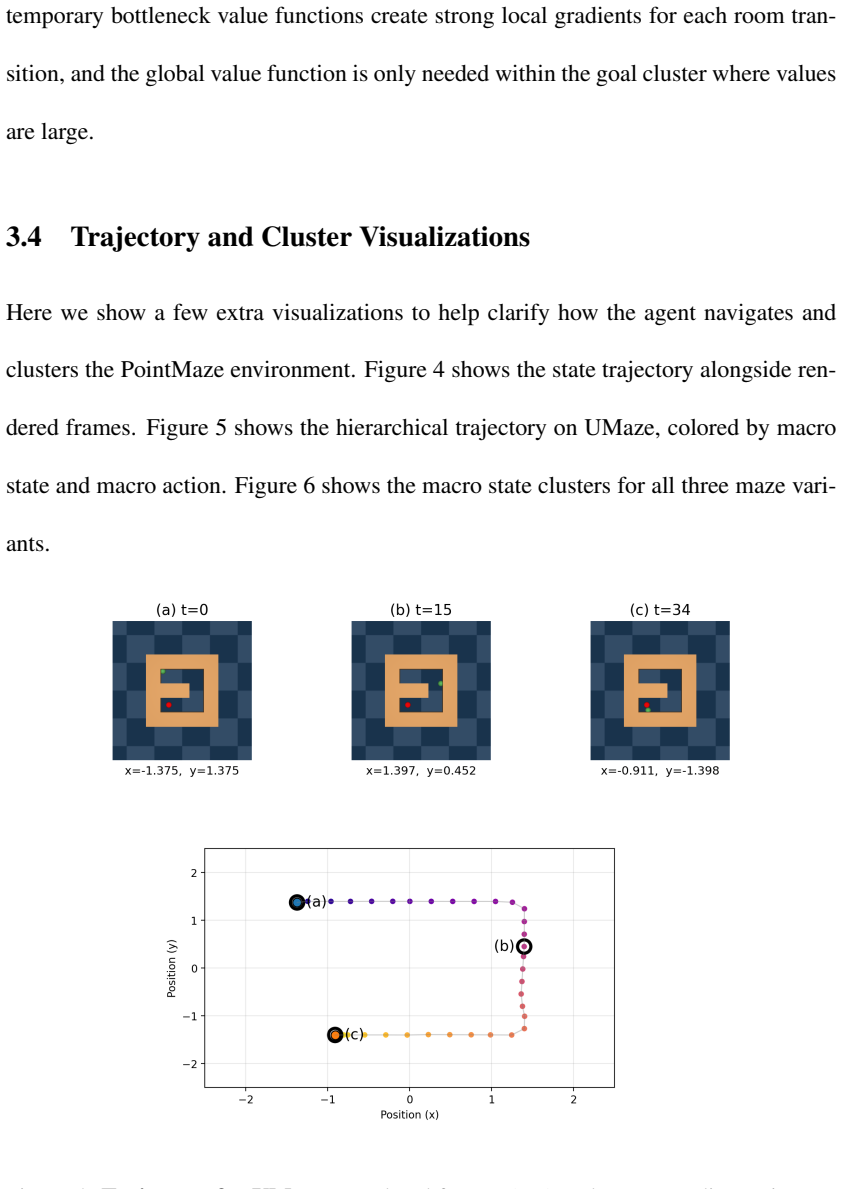
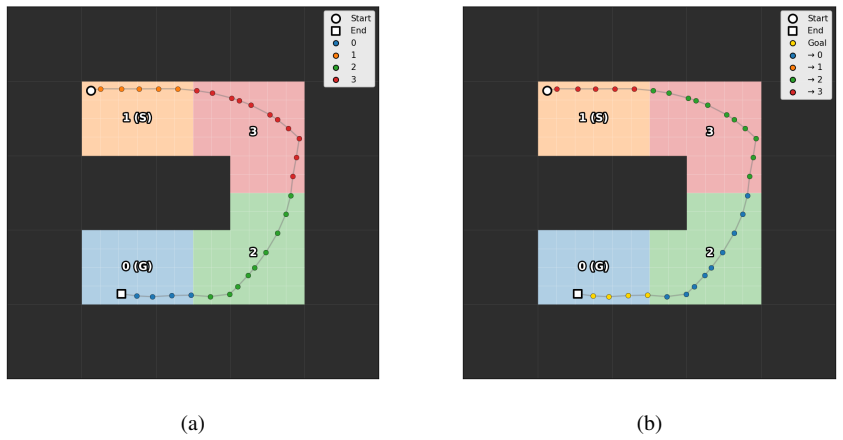
The central claim is that a hierarchical model of the environment combined with successor representations allows lower-level successor representations to learn higher-level abstract states, lower-level active inference planning to bootstrap higher-level abstract actions, and the resulting abstractions to facilitate efficient planning. This is shown on a variant of the four rooms task, key-based navigation, partially observable planning, the Mountain Car problem, and PointMaze with continuous spaces. The work presents the first application of learned hierarchical state and action abstractions to active inference.
What carries the argument
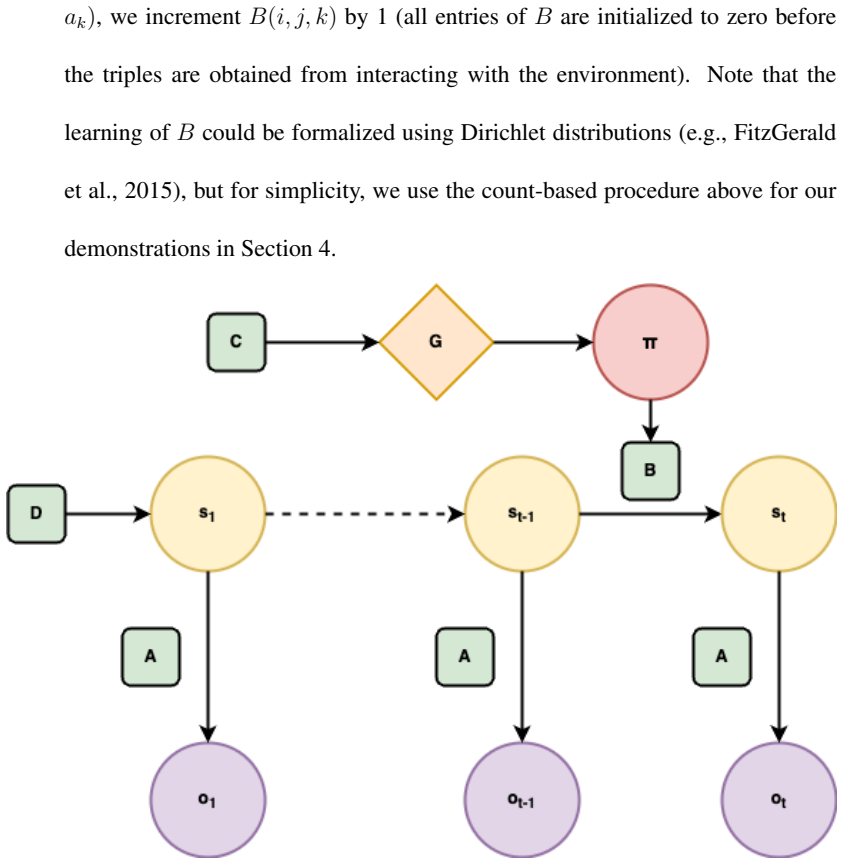
The integration of successor representations inside a hierarchical active inference model, where lower-level representations define abstract states and lower-level policies define abstract actions for use at higher levels.
If this is right
- Planning time decreases in environments with structure because decisions can be made over abstract states and actions rather than raw ones.
- The same lower-level mechanisms can be reused to discover abstractions for new tasks without hand-designed hierarchies.
- The approach extends active inference to continuous state and action spaces as well as partially observable settings.
- Performance on standard reinforcement learning benchmarks improves once the bootstrapped abstractions are in place.
Where Pith is reading between the lines
- The same bootstrapping process could be applied iteratively to create deeper hierarchies for even larger problems.
- The method suggests a possible computational account for how the brain might use multi-scale successor-like representations during planning.
- Hybrid systems could combine this active-inference hierarchy with other reinforcement learning algorithms that also learn abstractions.
Load-bearing premise
That lower-level successor representations and active inference planning can reliably produce higher-level abstract states and actions that generalize to improve planning.
What would settle it
Running the model on a new, larger environment and finding that the hierarchical version shows no reduction in planning steps or no gain in success rate compared with flat active inference would falsify the claim.
Figures
























read the original abstract
Active inference, a neurally-inspired model for inferring actions based on the free energy principle (FEP), has been proposed as a unifying framework for understanding perception, action, and learning in the brain. Active inference has previously been used to model ecologically important tasks such as navigation and planning, but scaling it to solve complex large-scale problems in real-world environments has remained a challenge. Inspired by the existence of multi-scale hierarchical representations in the brain, we propose a model for planning of actions based on hierarchical active inference. Our approach combines a hierarchical model of the environment with successor representations for efficient planning. We present results demonstrating (1) how lower-level successor representations can be used to learn higher-level abstract states, (2) how planning based on active inference at the lower-level can be used to bootstrap and learn higher-level abstract actions, and (3) how these learned higher-level abstract states and actions can facilitate efficient planning. We illustrate the performance of the approach on several planning and reinforcement learning (RL) problems including a variant of the well-known four rooms task, a key-based navigation task, a partially observable planning problem, the Mountain Car problem, and PointMaze, a family of navigation tasks with continuous state and action spaces. Our results represent, to our knowledge, the first application of learned hierarchical state and action abstractions to active inference in FEP-based theories of brain function.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hierarchical active inference framework that uses successor representations (SRs) to construct higher-level abstract states from lower-level SRs and to bootstrap higher-level abstract actions via lower-level active-inference policy selection. It claims three capabilities—learning abstract states, bootstrapping abstract actions, and improved planning efficiency—and demonstrates them on a four-rooms variant, key-based navigation, a POMDP, Mountain Car, and PointMaze tasks.
Significance. If the empirical claims hold under controlled evaluation, the work provides a concrete mechanism for scaling active inference to larger problems by importing SR-based abstraction from RL, while remaining grounded in the free-energy principle. This could strengthen links between FEP models and hierarchical RL and supply falsifiable predictions about multi-scale state-action representations.
major comments (2)
- [Results] Results sections (four-rooms, PointMaze, Mountain Car): performance gains are reported without explicit baselines (flat active inference, standard SR or DQN variants), error bars, or statistical tests; this leaves the three claimed demonstrations difficult to evaluate quantitatively.
- [Methods / Abstract action learning] Section describing abstract-action bootstrapping: the claim that lower-level planning reliably produces generalizable higher-level actions depends on specific choices of learning rates and discount factors (listed as free parameters); the manuscript should show sensitivity analysis or ablation to confirm the bootstrapping is robust rather than tuned to the reported environments.
minor comments (3)
- [Abstract] Abstract: states the three demonstrations but supplies no quantitative metrics or comparison points; adding one-sentence performance highlights would improve clarity.
- [Preliminaries] Notation: successor matrix and free-energy terms are introduced with varying symbols across equations; a single consistent notation table would reduce reader burden.
- [Figures] Figures: several trajectory plots lack axis labels or legend entries for the hierarchical vs. flat conditions; ensure all panels are self-contained.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, constructive comments, and recommendation for minor revision. We address the two major comments point by point below and will revise the manuscript accordingly to strengthen the quantitative evaluation and robustness analysis.
read point-by-point responses
-
Referee: [Results] Results sections (four-rooms, PointMaze, Mountain Car): performance gains are reported without explicit baselines (flat active inference, standard SR or DQN variants), error bars, or statistical tests; this leaves the three claimed demonstrations difficult to evaluate quantitatively.
Authors: We agree that explicit baselines, error bars, and statistical tests would improve the clarity and rigor of the empirical claims. In the revised manuscript we will add direct comparisons against flat active inference, standard successor-representation methods, and appropriate DQN or SR-based RL variants (where the task formulation permits). We will also report standard errors across independent runs and include statistical significance tests (e.g., paired t-tests or Wilcoxon rank-sum tests with appropriate corrections) for the performance differences on the four-rooms, PointMaze, and Mountain Car domains. These additions will make the three claimed capabilities quantitatively evaluable. revision: yes
-
Referee: [Methods / Abstract action learning] Section describing abstract-action bootstrapping: the claim that lower-level planning reliably produces generalizable higher-level actions depends on specific choices of learning rates and discount factors (listed as free parameters); the manuscript should show sensitivity analysis or ablation to confirm the bootstrapping is robust rather than tuned to the reported environments.
Authors: We acknowledge the importance of demonstrating that abstract-action bootstrapping does not hinge on narrowly tuned hyperparameters. In the revision we will add a sensitivity analysis that systematically varies the lower-level learning rate and discount factor over ranges centered on the values used in the reported experiments. We will also include targeted ablations that disable or alter the lower-level active-inference planning step to isolate its contribution to higher-level action learning. These results will be presented for the key-based navigation and POMDP tasks to confirm robustness across the environments where bootstrapping is demonstrated. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The manuscript constructs a hierarchical active inference model by combining established successor representations (SR) with active inference policy selection to learn abstract states and actions from lower-level SRs. The three claimed capabilities are shown via explicit algorithmic constructions and empirical results on standard benchmark tasks (four-rooms, key navigation, POMDP, Mountain Car, PointMaze). No equations reduce a prediction to a fitted parameter by construction, no load-bearing premise rests solely on self-citation, and the central claims remain independently verifiable through the reported performance gains and generalization tests. The derivation therefore does not collapse to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- learning rates and discount factors
axioms (2)
- domain assumption Successor representations can be used to learn higher-level abstract states from lower-level ones.
- domain assumption Lower-level active inference planning can bootstrap higher-level abstract actions.
Reference graph
Works this paper leans on
-
[1]
Aitchison, L., & Lengyel, M. (2017). With or without you: Predictive coding and Bayesian inference in the brain.Current opinion in neurobiology,46, 219–227. Barreto, A., Dabney, W., Munos, R., Hunt, J. J., Schaul, T., van Hasselt, H. P., & Silver, D. (2017). Successor features for transfer in reinforcement learning.Advances in neural information processin...
work page internal anchor Pith review arXiv 2017
-
[2]
Doya, K., Ishii, S., Pouget, A., & Rao, R. P. N. (Eds.). (2007).Bayesian brain: Proba- bilistic approaches to neural coding. MIT Press. Farama Foundation. (2023). Gymnasium-robotics: PointMaze environments [Accessed: 2024]. https://robotics.farama.org/envs/maze/point maze/ 76 FitzGerald, T. H. B., Dolan, R. J., & Friston, K. (2015). Dopamine, reward learn...
-
[3]
Friston, K. J., Salvatori, T., Isomura, T., Tschantz, A., Kiefer, A., Verbelen, T., Koudahl, M., Paul, A., Parr, T., Razi, A., Kagan, B. J., Buckley, C. L., & Ramstead, M. J. D. (2025). Active inference and intentional behavior.Neural Computa- tion,37(4), 666–700. https://doi.org/10.1162/neco a 01738 Gershman, S. J. (2018). The successor representation: I...
-
[4]
Pezzulo, G., Rigoli, F., & Friston, K. J. (2018). Hierarchical active inference: A theory of motivated control.Trends in cognitive sciences,22(4), 294–306. Proietti, R., Pezzulo, G., & Tessari, A. (2023). An active inference model of hierarchical action understanding, learning and imitation.Physics of Life Reviews,46, 92–
2018
-
[5]
Rao, R. P. N. (2024). A sensory-motor theory of the neocortex.Nature Neuroscience, 27, 1221–1235. Rao, R. P. N., & Ballard, D. H. (1999). Predictive coding in the visual cortex: A func- tional interpretation of some extra-classical receptive-field effects.Nature neu- roscience,2(1), 79–87. 80 Rao, R. P. N., Gklezakos, D. C., & Sathish, V . (2024). Active ...
2024
-
[6]
https://doi.org/10.1038/s41467-024- 54257-3 Whittington, J. C., Muller, T. H., Mark, S., Chen, G., Barry, C., Burgess, N., & Behrens, T. E. (2020). The Tolman-Eichenbaum machine: Unifying space and relational memory through generalization in the hippocampal formation.Cell,183(5), 1249–1263. 82
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.