Recognition: unknown
SSMamba: A Self-Supervised Hybrid State Space Model for Pathological Image Classification
Pith reviewed 2026-05-10 09:28 UTC · model grok-4.3
The pith
SSMamba, a hybrid state space model with self-supervised pretraining on target data, outperforms prior foundation models on pathological ROI and WSI classification tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SSMamba integrates Mamba Masked Image Modeling to reduce cross-magnification domain shift, a Directional Multi-scale module to improve local-global relationship modeling, and a Local Perception Residual module to increase fine-grained sensitivity, allowing effective self-supervised feature learning on target pathological datasets that leads to superior classification performance on both ROI and whole-slide image tasks.
What carries the argument
The SSMamba hybrid architecture that combines state space modeling with vision transformers through the MAMIM, DMS, and LPR modules for domain-adaptive fine-grained feature extraction.
If this is right
- Self-supervised pretraining directly on target ROI datasets reduces the need for massive external data collections in pathology analysis.
- The model architecture supports effective classification at both the region-of-interest level and the aggregated whole-slide image level.
- Mamba integration provides an alternative to pure transformer backbones that improves local feature capture while managing computational demands.
- Enhanced focus on fine-grained cues improves the capture of diagnostic morphological patterns in clinical pathology images.
Where Pith is reading between the lines
- The same hybrid components could be tested on other medical imaging tasks that involve scale variation, such as radiology or cytology slides.
- State space models paired with attention mechanisms might offer efficiency gains in broader vision tasks where transformers face local modeling limits.
- The two-stage target-domain pretraining strategy may apply to any setting where domain shift arises from acquisition parameters rather than content.
Load-bearing premise
The three added components of Mamba masked modeling, directional multi-scale processing, and local residual perception are sufficient to fix the main shortcomings of transformer models when dealing with magnification changes and subtle details in pathology images.
What would settle it
A new pathological dataset with large unaddressed magnification differences or very subtle diagnostic cues on which SSMamba shows no performance gain over the compared prior methods would indicate the components do not deliver the claimed benefits.
Figures




read the original abstract
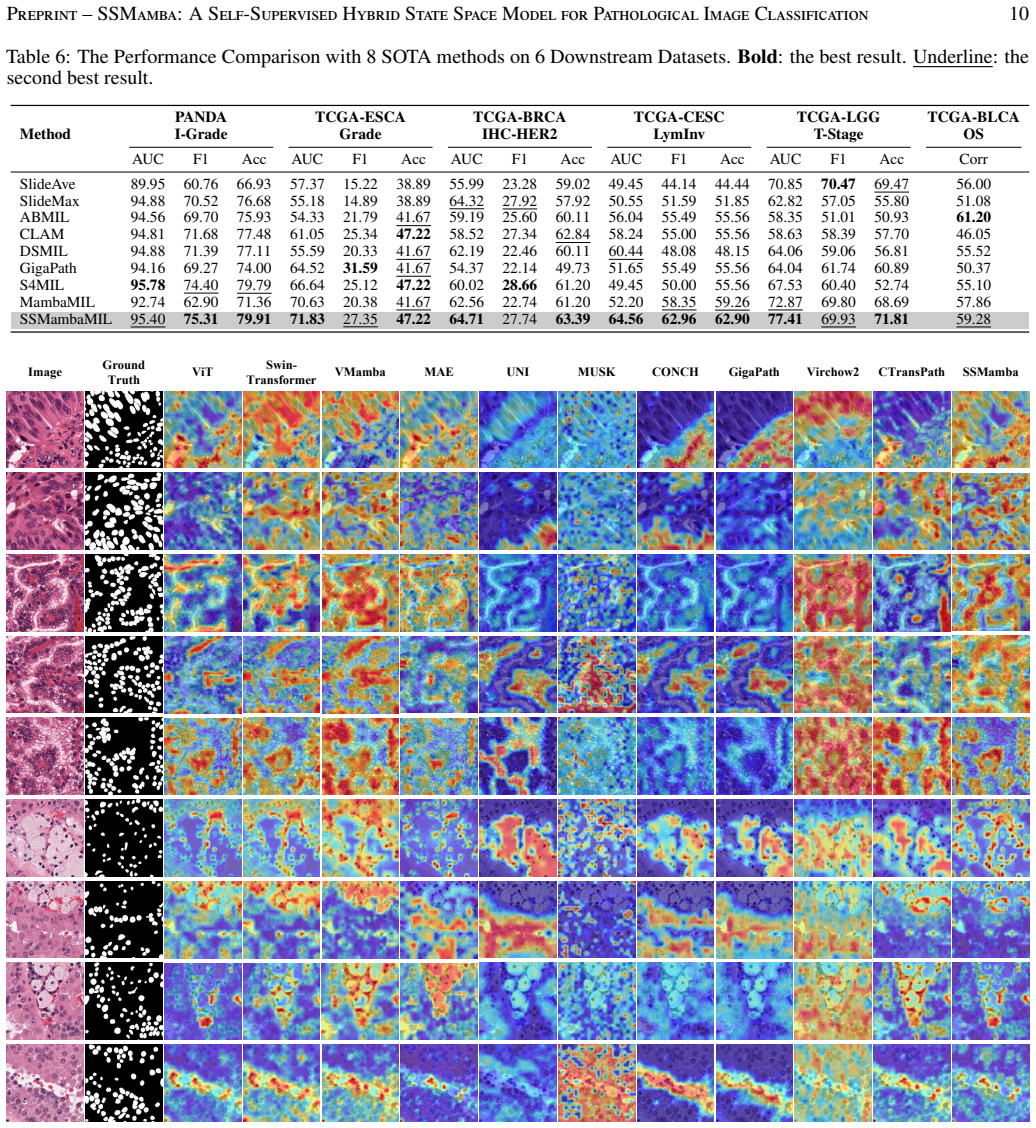
Pathological diagnosis is highly reliant on image analysis, where Regions of Interest (ROIs) serve as the primary basis for diagnostic evidence, while whole-slide image (WSI)-level tasks primarily capture aggregated patterns. To extract these critical morphological features, ROI-level Foundation Models (FMs) based on Vision Transformers (ViTs) and large-scale self-supervised learning (SSL) have been widely adopted. However, three core limitations remain in their application to ROI analysis: (1) cross-magnification domain shift, as fixed-scale pretraining hinders adaptation to diverse clinical settings; (2) inadequate local-global relationship modeling, wherein the ViT backbone of FMs suffers from high computational overhead and imprecise local characterization; (3) insufficient fine-grained sensitivity, as traditional self-attention mechanisms tend to overlook subtle diagnostic cues. To address these challenges, we propose SSMamba, a hybrid SSL framework that enables effective fine-grained feature learning without relying on large external datasets. This framework incorporates three domain-adaptive components: Mamba Masked Image Modeling (MAMIM) for mitigating domain shift, a Directional Multi-scale (DMS) module for balanced local-global modeling, and a Local Perception Residual (LPR) module for enhanced fine-grained sensitivity. Employing a two-stage pipeline, SSL pretraining on target ROI datasets followed by supervised fine-tuning (SFT), SSMamba outperforms 11 state-of-the-art (SOTA) pathological FMs on 10 public ROI datasets and surpasses 8 SOTA methods on 6 public WSI datasets. These results validate the superiority of task-specific architectural designs for pathological image analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SSMamba, a self-supervised hybrid state space model for pathological image classification. It introduces three domain-adaptive components—Mamba Masked Image Modeling (MAMIM) to mitigate cross-magnification domain shift, Directional Multi-scale (DMS) module for balanced local-global modeling, and Local Perception Residual (LPR) module for enhanced fine-grained sensitivity—within a two-stage pipeline of SSL pretraining directly on target ROI datasets followed by supervised fine-tuning (SFT). The central empirical claim is that SSMamba outperforms 11 SOTA pathological foundation models on 10 public ROI datasets and surpasses 8 SOTA methods on 6 public WSI datasets.
Significance. If the results hold under controlled conditions, the work would be significant for showing that task-specific hybrid architectures combining state-space models with targeted modules can deliver superior performance on pathology images without relying on large-scale external pretraining corpora. This could shift emphasis toward efficient, domain-adapted designs over scaling general ViT-based FMs, particularly for handling magnification variability and subtle morphological cues.
major comments (2)
- [Experiments] Experiments section (results tables comparing to 11 SOTA pathological FMs): the evaluation protocol applies two-stage SSL pretraining on the target ROI datasets only to SSMamba, while the baselines appear to be used in their originally published form (supervised fine-tuning from large-scale pretraining). This leaves open the possibility that reported gains derive from the in-domain pretraining advantage rather than the MAMIM + DMS + LPR components, directly undermining the claim that these modules address cross-magnification shift, local-global imbalance, and fine-grained sensitivity.
- [§3] §3 (Method, DMS and LPR modules): the paper provides no ablation studies isolating the contribution of each proposed component (MAMIM, DMS, LPR) versus a plain Mamba backbone or standard ViT, nor any quantitative analysis of how DMS achieves balanced local-global modeling beyond qualitative description. Without these, it is difficult to attribute performance gains specifically to the architectural innovations.
minor comments (2)
- [Abstract] Abstract: the claim of outperforming SOTA models is stated without any numerical metrics, confidence intervals, or statistical test results, which reduces informativeness for readers.
- [Figures and §3.1] Notation and figures: the directional multi-scale module diagram and equations for MAMIM masking strategy would benefit from clearer labeling of input/output dimensions and hyper-parameters to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Experiments] Experiments section (results tables comparing to 11 SOTA pathological FMs): the evaluation protocol applies two-stage SSL pretraining on the target ROI datasets only to SSMamba, while the baselines appear to be used in their originally published form (supervised fine-tuning from large-scale pretraining). This leaves open the possibility that reported gains derive from the in-domain pretraining advantage rather than the MAMIM + DMS + LPR components, directly undermining the claim that these modules address cross-magnification shift, local-global imbalance, and fine-grained sensitivity.
Authors: We acknowledge the referee's concern regarding the fairness of the comparison. The two-stage SSL pretraining on target datasets is an integral component of the SSMamba framework, specifically designed to mitigate cross-magnification domain shift without requiring large-scale external pretraining data, which is a key advantage over existing pathological foundation models. The baselines are evaluated in their standard published configurations, as is common when comparing to foundation models. Our empirical results demonstrate that this domain-adapted approach yields superior performance on the target tasks. To address this point, we will revise the Experiments section to more explicitly describe the evaluation protocol and provide additional discussion on how the performance gains stem from the synergy of the MAMIM, DMS, and LPR components within the in-domain pretraining pipeline. We believe this clarifies that the gains are not solely from pretraining but from the proposed hybrid architecture tailored for pathology. revision: partial
-
Referee: [§3] §3 (Method, DMS and LPR modules): the paper provides no ablation studies isolating the contribution of each proposed component (MAMIM, DMS, LPR) versus a plain Mamba backbone or standard ViT, nor any quantitative analysis of how DMS achieves balanced local-global modeling beyond qualitative description. Without these, it is difficult to attribute performance gains specifically to the architectural innovations.
Authors: We agree that ablation studies are essential for rigorously validating the contributions of each module. In the revised manuscript, we will add a dedicated ablation study subsection in the Experiments section. This will include: (1) comparisons of SSMamba with and without MAMIM, DMS, and LPR, as well as against a plain Mamba backbone and a standard ViT; (2) quantitative analysis for the DMS module, such as performance metrics on local vs. global feature extraction tasks or visualization-based quantitative measures (e.g., IoU on attention regions). These additions will help attribute the performance improvements specifically to the proposed components. revision: yes
Circularity Check
No circularity: empirical architecture proposal with external benchmarks
full rationale
The paper proposes a hybrid model (SSMamba) with three components (MAMIM, DMS, LPR) and reports empirical results on public ROI and WSI datasets. No equations, derivations, or first-principles predictions are described in the provided text. Claims of outperformance are framed as experimental outcomes from a two-stage SSL+SFT pipeline, not as quantities that reduce by construction to fitted parameters or self-referential definitions. The evaluation uses external public datasets and comparisons to other methods, satisfying the rule that self-contained results against external benchmarks receive score 0-2. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in a way that collapses the central claim. The skeptic concern about baseline pretraining fairness is a methodological question, not a circularity reduction per the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep neural network models for computational histopathology: A survey.Medical image analysis, 67:101813, 2021
Chetan L Srinidhi, Ozan Ciga, and Anne L Martel. Deep neural network models for computational histopathology: A survey.Medical image analysis, 67:101813, 2021
2021
-
[2]
Image analysis and machine learning in digital pathology: Challenges and opportunities.Medical image analysis, 33:170–175, 2016
Anant Madabhushi and George Lee. Image analysis and machine learning in digital pathology: Challenges and opportunities.Medical image analysis, 33:170–175, 2016
2016
-
[3]
Deep learning.nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.nature, 521(7553):436–444, 2015
2015
-
[4]
Big self-supervised models advance medical image classifi- cation
Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, et al. Big self-supervised models advance medical image classifi- cation. InProceedings of the IEEE/CVF international conference on computer vision, pages 3478–3488, 2021
2021
-
[5]
Contrastive learning of medical visual representations from paired images and text
Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive learning of medical visual representations from paired images and text. InMachine Learning for Healthcare Conference, pages 2–25. PMLR, 2022. Preprint– SSMamba: A Self-SupervisedHybridStateSpaceModel forPathologicalImageClassification15
2022
-
[6]
Mapping medical image-text to a joint space via masked modeling.Medical Image Analysis, 91:103018, 2024
Zhihong Chen, Yuhao Du, Jinpeng Hu, Yang Liu, Guanbin Li, Xiang Wan, and Tsung-Hui Chang. Mapping medical image-text to a joint space via masked modeling.Medical Image Analysis, 91:103018, 2024
2024
-
[7]
Self-supervised visual fea- ture learning with deep neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(11):4037–4058, 2020
Longlong Jing and Yingli Tian. Self-supervised visual fea- ture learning with deep neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(11):4037–4058, 2020
2020
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[9]
Mcua: Multi-level context and uncertainty aware dynamic deep ensemble for breast cancer histology image classification
Zakaria Senousy, Mohammed M Abdelsamea, Mo- hamed Medhat Gaber, Moloud Abdar, U Rajendra Acharya, Abbas Khosravi, and Saeid Nahavandi. Mcua: Multi-level context and uncertainty aware dynamic deep ensemble for breast cancer histology image classification. IEEE Transactions on Biomedical Engineering, 69(2):818– 829, 2021
2021
-
[10]
Distill- ing foundation models for robust and efficient models in digital pathology
Alexandre Filiot, Nicolas Dop, Oussama Tchita, Auriane Riou, Rémy Dubois, Thomas Peeters, Daria Valter, Marin Scalbert, Charlie Saillard, Geneviève Robin, et al. Distill- ing foundation models for robust and efficient models in digital pathology. InInternational Conference on Medi- cal Image Computing and Computer-Assisted Intervention, pages 162–172. Spr...
2025
-
[11]
An image is worth 16x16 words: Trans- formers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, and Sylvain Gelly. An image is worth 16x16 words: Trans- formers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[12]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
2021
-
[13]
Pathasst: A generative foundation ai assistant to- wards artificial general intelligence of pathology
Yuxuan Sun, Chenglu Zhu, Sunyi Zheng, Kai Zhang, Lin Sun, Zhongyi Shui, Yunlong Zhang, Honglin Li, and Lin Yang. Pathasst: A generative foundation ai assistant to- wards artificial general intelligence of pathology. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5034–5042, 2024
2024
-
[14]
Transfusion: Understanding transfer learning for medical imaging.Advances in neural information processing systems, 32, 2019
Maithra Raghu, Chiyuan Zhang, Jon Kleinberg, and Samy Bengio. Transfusion: Understanding transfer learning for medical imaging.Advances in neural information processing systems, 32, 2019
2019
-
[15]
Domain adaptive detec- tion framework for multi-center bone tumor detection on radiographs.Computerized Medical Imaging and Graph- ics, 123, 2025
Bing Li, Danyang Xu, Hongxin Lin, Ruodai Wu, Songx- iong Wu, Jingjing Shao, Jinxiang Zhang, Haiyang Dai, Dan Wei, and Bingsheng Huang. Domain adaptive detec- tion framework for multi-center bone tumor detection on radiographs.Computerized Medical Imaging and Graph- ics, 123, 2025
2025
-
[16]
Unsupervised domain adaptation based on feature and edge alignment for femur x-ray im- age segmentation.Computerized medical imaging and graphics, page 116, 2024
Xiaoming Jiang, Yongxin Yang, Tong Su, Kai Xiao, Li Dan Lu, Wei Wang, Changsong Guo, Lizhi Shao, Mingjing Wang, and Dong Jiang. Unsupervised domain adaptation based on feature and edge alignment for femur x-ray im- age segmentation.Computerized medical imaging and graphics, page 116, 2024
2024
-
[17]
Weakly supervised multiple instance learning histopathological tumor segmentation
Marvin Lerousseau, Maria Vakalopoulou, Marion Classe, Julien Adam, Enzo Battistella, Alexandre Carré, Théo Estienne, Théophraste Henry, Eric Deutsch, and Nikos Paragios. Weakly supervised multiple instance learning histopathological tumor segmentation. InMedical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference,...
2020
-
[18]
Scorenet: Learning non- uniform attention and augmentation for transformer-based histopathological image classification
Thomas Stegmüller, Behzad Bozorgtabar, Antoine Spahr, and Jean-Philippe Thiran. Scorenet: Learning non- uniform attention and augmentation for transformer-based histopathological image classification. InProceedings of the IEEE/CVF winter Conference on applications of com- puter vision, pages 6170–6179, 2023
2023
-
[19]
Combining recur- rent, convolutional, and continuous-time models with lin- ear state space layers.Advances in neural information processing systems, 34:572–585, 2021
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. Combining recur- rent, convolutional, and continuous-time models with lin- ear state space layers.Advances in neural information processing systems, 34:572–585, 2021
2021
-
[20]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page Pith review arXiv 2023
-
[21]
Mambaout: Do we really need mamba for vision? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4484– 4496, 2025
Weihao Yu and Xinchao Wang. Mambaout: Do we really need mamba for vision? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4484– 4496, 2025
2025
-
[22]
On transla- tion invariance in cnns: Convolutional layers can exploit absolute spatial location
Osman Semih Kayhan and Jan C van Gemert. On transla- tion invariance in cnns: Convolutional layers can exploit absolute spatial location. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14274–14285, 2020
2020
-
[23]
Transformer-based unsupervised contrastive learning for histopathological image classification.Medical image anal- ysis, 81:102559, 2022
Xiyue Wang, Sen Yang, Jun Zhang, Minghui Wang, Jing Zhang, Wei Yang, Junzhou Huang, and Xiao Han. Transformer-based unsupervised contrastive learning for histopathological image classification.Medical image anal- ysis, 81:102559, 2022
2022
-
[24]
Towards a general-purpose foundation model for computational pathology.Nature Medicine, 2024
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Bowen Chen, Andrew Zhang, Daniel Shao, Andrew H Song, Muhammad Shaban, et al. Towards a general-purpose foundation model for computational pathology.Nature Medicine, 2024
2024
-
[25]
Eric Zimmermann, Eugene V orontsov, Julian Viret, Adam Casson, Michal Zelechowski, George Shaikovski, Neil Tenenholtz, James Hall, David Klimstra, Razik Yousfi, et al. Virchow2: Scaling self-supervised mixed magnification models in pathology.arXiv preprint arXiv:2408.00738, 2024
-
[26]
A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, CliffWong, Ze- lalem Gero, Javier González, Yu Gu, et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
2024
-
[27]
Lei Zhou, Huidong Liu, Joseph Bae, Junjun He, Dimitris Samaras, and Prateek Prasanna. Self pre-training with Preprint– SSMamba: A Self-SupervisedHybridStateSpaceModel forPathologicalImageClassification16 masked autoencoders for medical image classification and segmentation. In2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), pages 1–6. ...
2023
-
[28]
A vision– language foundation model for precision oncology.Nature, 638(8051):769–778, 2025
Jinxi Xiang, Xiyue Wang, Xiaoming Zhang, Yinghua Xi, Feyisope Eweje, Yijiang Chen, Yuchen Li, Colin Bergstrom, Matthew Gopaulchan, Ted Kim, et al. A vision– language foundation model for precision oncology.Nature, 638(8051):769–778, 2025
2025
-
[29]
Lu, Bowen Chen, Andrew Zhang, Drew F
Ming Y . Lu, Bowen Chen, Andrew Zhang, Drew F. K. Williamson, Richard J. Chen, Tong Ding, Long Phi Le, Yung-Sung Chuang, and Faisal Mahmood. Visual lan- guage pretrained multiple instance zero-shot transfer for histopathology images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19764–19775, June 2023
2023
-
[30]
Vmamba: Visual state space model.Advances in neu- ral information processing systems, 37:103031–103063, 2024
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neu- ral information processing systems, 37:103031–103063, 2024
2024
-
[31]
Wensheng Wang, Zewen Jin, Xueli Liu, and Xinrong Chen. Nama-mamba: Foundation model for generalizable nasal disease detection using masked autoencoder with mamba on endoscopic images.Computerized Medical Imaging and Graphics, 122:102524, 2025
2025
-
[32]
Zhiqing Zhang, Tianyong Liu, Guojia Fan, Na Li, Bin Li, Yao Pu, Qianjin Feng, and Shoujun Zhou. Spine- mamba: Enhancing 3d spinal segmentation in clinical imaging through residual visual mamba layers and shape priors.Computerized Medical Imaging and Graphics, 123: 102531, 2025
2025
-
[33]
Cmt: Convolutional neural networks meet vision transformers
Jianyuan Guo, Kai Han, Han Wu, Yehui Tang, Xinghao Chen, Yunhe Wang, and Chang Xu. Cmt: Convolutional neural networks meet vision transformers. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12175–12185, 2022
2022
-
[34]
Andrew A. Borkowski, Marilyn M. Bui, L. Brannon Thomas, Catherine P. Wilson, Lauren A. DeLand, and Stephen M. Mastorides. Lung and colon cancer histopatho- logical image dataset (lc25000), 2019. URL https: //arxiv.org/abs/1912.12142
-
[35]
Predicting survival from colorectal cancer histology slides using deep learning: A retrospec- tive multicenter study.PLoS medicine, 16(1):e1002730, 2019
Jakob Nikolas Kather, Johannes Krisam, Pornpimol Charoentong, Tom Luedde, Esther Herpel, Cleo-Aron Weis, Timo Gaiser, Alexander Marx, Nektarios A Val- ous, Dyke Ferber, et al. Predicting survival from colorectal cancer histology slides using deep learning: A retrospec- tive multicenter study.PLoS medicine, 16(1):e1002730, 2019
2019
-
[36]
A dataset of microscopic peripheral blood cell images for development of automatic recognition systems.Data in brief, 30(article 105474), 2020
Andrea Acevedo, Anna Merino González, Edwin San- tiago Alférez Baquero, Ángel Molina Borrás, Laura Boldú Nebot, and José Rodellar Benedé. A dataset of microscopic peripheral blood cell images for development of automatic recognition systems.Data in brief, 30(article 105474), 2020
2020
-
[37]
Instance-based vision transformer for subtyping of papil- lary renal cell carcinoma in histopathological image
Zeyu Gao, Bangyang Hong, Xianli Zhang, Yang Li, Chang Jia, Jialun Wu, Chunbao Wang, Deyu Meng, and Chen Li. Instance-based vision transformer for subtyping of papil- lary renal cell carcinoma in histopathological image. In International conference on medical image computing and computer-assisted intervention, pages 299–308. Springer, 2021
2021
-
[38]
Paip 2019: Liver cancer segmentation chal- lenge.Medical image analysis, 67:101854, 2021
Yoo Jung Kim, Hyungjoon Jang, Kyoungbun Lee, Seongkeun Park, Sung-Gyu Min, Choyeon Hong, Jeong Hwan Park, Kanggeun Lee, Jisoo Kim, Wonjae Hong, et al. Paip 2019: Liver cancer segmentation chal- lenge.Medical image analysis, 67:101854, 2021
2019
-
[39]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.Jama, 318(22):2199–2210, 2017
Babak Ehteshami Bejnordi, Mitko Veta, Paul Johannes Van Diest, Bram Van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen AWM Van Der Laak, Meyke Hermsen, Quirine F Manson, Maschenka Balkenhol, et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.Jama, 318(22):2199–2210, 2017
2017
-
[40]
Plissiti, P
Marina E. Plissiti, P. Dimitrakopoulos, G. Sfikas, Christophoros Nikou, O. Krikoni, and A. Charchanti. Sipakmed: A new dataset for feature and image based classification of normal and pathological cervical cells in pap smear images. In2018 25th IEEE International Con- ference on Image Processing (ICIP), pages 3144–3148,
-
[41]
doi: 10.1109/ICIP.2018.8451588
-
[42]
A petri dish for histopathology image analysis
Jerry Wei, Arief Suriawinata, Bing Ren, Xiaoying Liu, Mikhail Lisovsky, Louis Vaickus, Charles Brown, Michael Baker, Naofumi Tomita, Lorenzo Torresani, et al. A petri dish for histopathology image analysis. InInternational Conference on Artificial Intelligence in Medicine, pages 11–24. Springer, 2021
2021
-
[43]
Tcgabiolinks: an r/bioconductor package for integrative analysis of tcga data.Nucleic acids research, 44(8):e71–e71, 2016
Antonio Colaprico, Tiago C Silva, Catharina Olsen, Lu- ciano Garofano, Claudia Cava, Davide Garolini, Thais S Sabedot, Tathiane M Malta, Stefano M Pagnotta, Isabella Castiglioni, et al. Tcgabiolinks: an r/bioconductor package for integrative analysis of tcga data.Nucleic acids research, 44(8):e71–e71, 2016
2016
-
[44]
Osteosarcoma.Nature reviews Dis- ease primers, 8(1):77, 2022
Hannah C Beird, Stefan S Bielack, Adrienne M Flanagan, Jonathan Gill, Dominique Heymann, Katherine A Janeway, J Andrew Livingston, Ryan D Roberts, Sandra J Strauss, and Richard Gorlick. Osteosarcoma.Nature reviews Dis- ease primers, 8(1):77, 2022
2022
-
[45]
Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature medicine, 28(1):154–163, 2022
Wouter Bulten, Kimmo Kartasalo, Po-Hsuan Cameron Chen, Peter Ström, Hans Pinckaers, Kunal Nagpal, Yuan- nan Cai, David F Steiner, Hester Van Boven, Robert Vink, et al. Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature medicine, 28(1):154–163, 2022
2022
-
[46]
Unpuzzle: A unified framework for pathol- ogy image analysis.arXiv preprint arXiv:2503.03152, 2025
Dankai Liao, Sicheng Chen, Nuwa Xi, Qiaochu Xue, Jieyu Li, Lingxuan Hou, Zeyu Liu, Chang Han Low, Yufeng Wu, Yiling Liu, et al. Unpuzzle: A unified framework for pathol- ogy image analysis.arXiv preprint arXiv:2503.03152, 2025
-
[47]
An enhanced vision trans- former with wavelet position embedding for histopatholog- ical image classification.Pattern Recognition, 140:109532, 2023
Meidan Ding, Aiping Qu, Haiqin Zhong, Zhihui Lai, Shuomin Xiao, and Penghui He. An enhanced vision trans- former with wavelet position embedding for histopatholog- ical image classification.Pattern Recognition, 140:109532, 2023
2023
-
[48]
Hongbin Cai, Xiaobing Feng, Ruomeng Yin, Youcai Zhao, Lingchuan Guo, Xiangshan Fan, and Jun Liao. Mist: mul- tiple instance learning network based on swin transformer Preprint– SSMamba: A Self-SupervisedHybridStateSpaceModel forPathologicalImageClassification17 for whole slide image classification of colorectal adenomas. The Journal of pathology, 259(2):1...
2023
-
[49]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Pi- otr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[50]
2dmamba: Efficient state space model for im- age representation with applications on giga-pixel whole slide image classification
Jingwei Zhang, Anh Tien Nguyen, Xi Han, Vincent Quoc- Huy Trinh, Hong Qin, Dimitris Samaras, and Mahdi S Hosseini. 2dmamba: Efficient state space model for im- age representation with applications on giga-pixel whole slide image classification. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 3583–3592, 2025
2025
-
[51]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. InIn- ternational conference on machine learning, pages 2127–
-
[52]
Data-efficient and weakly supervised computational pathol- ogy on whole-slide images.Nature biomedical engineer- ing, 5(6):555–570, 2021
Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, Richard J Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathol- ogy on whole-slide images.Nature biomedical engineer- ing, 5(6):555–570, 2021
2021
-
[53]
Dual-stream multiple instance learning network for whole slide image classifica- tion with self-supervised contrastive learning
Bin Li, Yin Li, and Kevin W Eliceiri. Dual-stream multiple instance learning network for whole slide image classifica- tion with self-supervised contrastive learning. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2021
2021
-
[54]
Structured state space models for multiple instance learning in digital pathology
Leo Fillioux, Joseph Boyd, Maria Vakalopoulou, Paul- Henry Cournède, and Stergios Christodoulidis. Structured state space models for multiple instance learning in digital pathology. InInternational Conference on Medical Im- age Computing and Computer-Assisted Intervention, pages 594–604. Springer, 2023
2023
-
[55]
Mambamil: En- hancing long sequence modeling with sequence reordering in computational pathology
Shu Yang, Yihui Wang, and Hao Chen. Mambamil: En- hancing long sequence modeling with sequence reordering in computational pathology. InInternational conference on medical image computing and computer-assisted inter- vention, pages 296–306. Springer, 2024
2024
-
[56]
cross-organ consistency in sample quantity, cross-organ difference in morphology
Korsuk Sirinukunwattana, Josien PW Pluim, Hao Chen, Xiaojuan Qi, Pheng-Ann Heng, Yun Bo Guo, Li Yang Wang, Bogdan J Matuszewski, Elia Bruni, Urko Sanchez, et al. Gland segmentation in colon histology images: The glas challenge contest.Medical image analysis, 35:489– 502, 2017. 8 Appendix 8.1 Dataset Details The LaC datasetis characterized by a multi-organ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.