Recognition: unknown
Privacy-Preserving LLMs Routing
Pith reviewed 2026-05-10 08:31 UTC · model grok-4.3
The pith
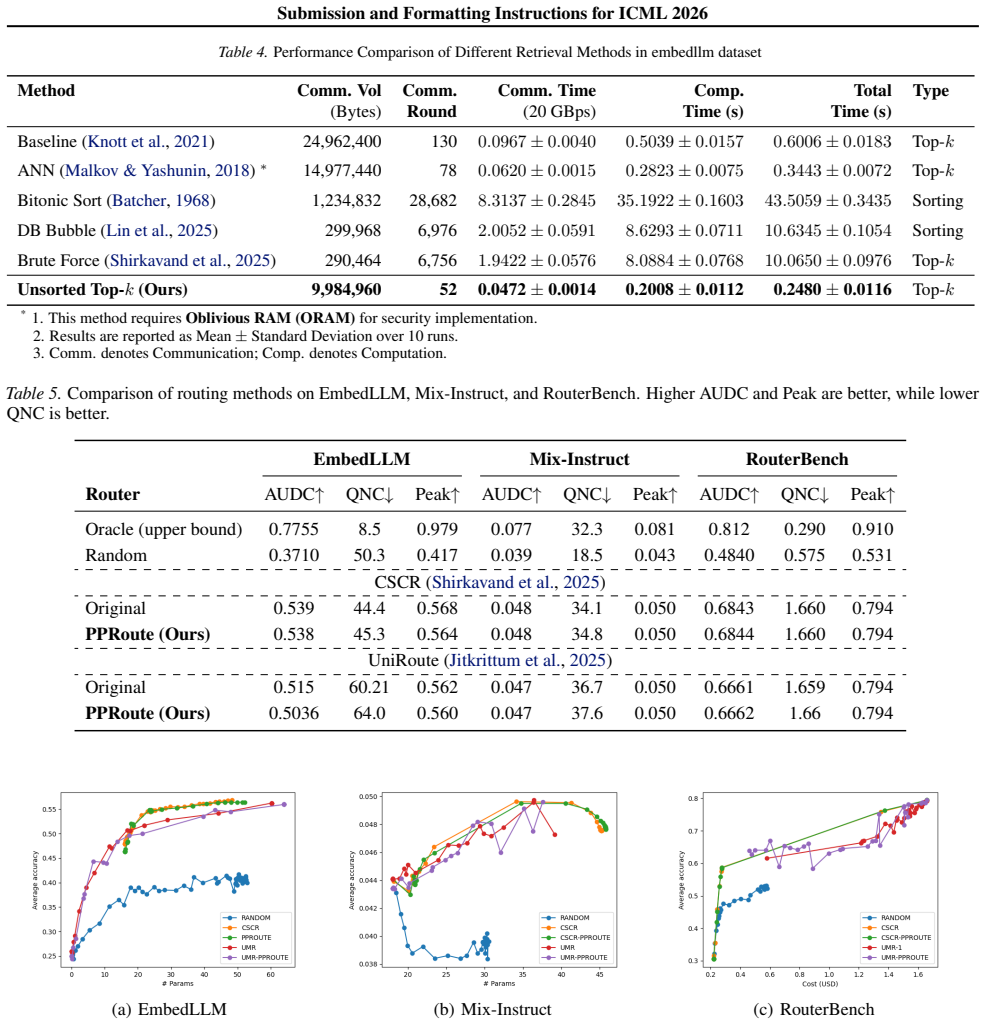
PPRoute achieves plaintext-level LLM routing quality with MPC-based privacy and a 20x speedup over naive encrypted implementations via MPC-friendly encoders, multi-step training, and O(1) communication Top-k search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across different datasets, PPRoute achieves the performance of plaintext counterparts, while achieving approximately a 20× speedup over naïve MPC implementations.
Load-bearing premise
The multi-step training algorithm and MPC-friendly operations preserve routing quality without introducing privacy leaks or accuracy drops that would make the system unusable in real deployments.
Figures



read the original abstract
Large language model (LLM) routing has emerged as a critical strategy to balance model performance and cost-efficiency by dynamically selecting services from various model providers. However, LLM routing adds an intermediate layer between users and LLMs, creating new privacy risks to user data. These privacy risks have not been systematically studied. Although cryptographic techniques such as Secure Multi-Party Computation (MPC) enable privacy-preserving computation, their protocol design and implementation remain under-explored, and na\"ive implementations typically incur prohibitive computational overhead. To address this, we propose a privacy-preserving LLM routing framework (PPRoute). PPRoute includes multiple strategies to speed up encoder inference and nearest neighbor search under the MPC and maintain the quality of LLM routing. First, PPRoute uses MPC-friendly operations to boost the encoder inference. Second, PPRoute uses a multiple-step model training algorithm to maintain routing quality despite the constraints of the encrypted domain. Third, PPRoute proposes an unsorted Top-k algorithm with $O(1)$ communication complexity for secure sorting in model search, significantly reducing communication latency. Across different datasets, PPRoute achieves the performance of plaintext counterparts, while achieving approximately a 20$\times$ speedup over na\"ive MPC implementations.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical system (PPRoute) built from MPC-friendly encoder operations, a multi-step training procedure, and an unsorted Top-k search with claimed O(1) communication. All central performance claims are presented as measured outcomes on datasets rather than as predictions derived from fitted parameters or self-referential equations. No derivation chain reduces a result to its own inputs by construction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automix: Automatically mixing language models
Aggarwal, P., Madaan, A., Anand, A., Potharaju, S. P., Mishra, S., Zhou, P., Gupta, A., Rajagopal, D., Kappa- ganthu, K., Yang, Y ., et al. Automix: Automatically mix- ing language models.arXiv preprint arXiv:2310.12963,
-
[2]
Batcher, K. E. Sorting networks and their applications. In Proceedings of the April 30–May 2, 1968, spring joint computer conference, pp. 307–314,
1968
-
[3]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Chen, L., Zaharia, M., and Zou, J. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176,
work page internal anchor Pith review arXiv
-
[4]
Hybrid llm: Cost-efficient and quality- aware query routing.arXiv preprint arXiv:2404.14618, 2024
Ding, D., Mallick, A., Wang, C., Sim, R., Mukherjee, S., Ruhle, V ., Lakshmanan, L. V ., and Awadallah, A. H. Hy- brid llm: Cost-efficient and quality-aware query routing. arXiv preprint arXiv:2404.14618,
-
[5]
arXiv preprint arXiv:2410.03834 , year=
Feng, T., Shen, Y ., and You, J. Graphrouter: A graph-based router for llm selections.arXiv preprint arXiv:2410.03834,
-
[6]
Hu, Q. J., Bieker, J., Li, X., Jiang, N., Keigwin, B., Ran- ganath, G., Keutzer, K., and Upadhyay, S. K. Router- bench: A benchmark for multi-llm routing system.arXiv preprint arXiv:2403.12031,
-
[7]
arXiv preprint arXiv:2510.19506 , year=
Huang, C., Shi, T., Zhu, Y ., Chen, R., and Quan, X. Looka- head routing for large language models.arXiv preprint arXiv:2510.19506,
- [8]
-
[9]
Universal Model Routing for Efficient LLM Inference.arXiv preprint arXiv:2502.08773, 2025
Jitkrittum, W., Narasimhan, H., Rawat, A. S., Juneja, J., Wang, C., Wang, Z., Go, A., Lee, C.-Y ., Shenoy, P., Pani- grahy, R., et al. Universal model routing for efficient llm inference.arXiv preprint arXiv:2502.08773,
-
[10]
Lu, K., Yuan, H., Lin, R., Lin, J., Yuan, Z., Zhou, C., and Zhou, J
URL https: //openreview.net/forum?id=1VqxIgyQlp. Lu, K., Yuan, H., Lin, R., Lin, J., Yuan, Z., Zhou, C., and Zhou, J. Routing to the expert: Efficient reward-guided ensemble of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: ...
2024
-
[11]
SecFormer: Fast and accurate privacy-preserving inference for transformer models via SMPC
9 Submission and Formatting Instructions for ICML 2026 Luo, J., Zhang, Y ., Zhang, Z., Zhang, J., Mu, X., Wang, H., Yu, Y ., and Xu, Z. SecFormer: Fast and accurate privacy-preserving inference for transformer models via SMPC. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Findings of the Association for Computational Linguistics: ACL 2024, pp. 13333...
2026
-
[12]
Rethinking tabular data understanding with large language models
Association for Computational Linguistics. doi: 10.18653/v1/2024. findings-acl.790. URL https://aclanthology. org/2024.findings-acl.790/. Malkov, Y . A. and Yashunin, D. A. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(4):824– 836,
-
[13]
doi: 10.1109/TPAMI.2018.2889473. Mohassel, P. and Zhang, Y . Secureml: A system for scalable privacy-preserving machine learning. In2017 IEEE sym- posium on security and privacy (SP), pp. 19–38. IEEE,
-
[14]
Cost- aware contrastive routing for llms.arXiv preprint arXiv:2508.12491,
Shirkavand, R., Gao, S., Yu, P., and Huang, H. Cost- aware contrastive routing for llms.arXiv preprint arXiv:2508.12491,
-
[15]
Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789, 2023
Shnitzer, T., Ou, A., Silva, M., Soule, K., Sun, Y ., Solomon, J., Thompson, N., and Yurochkin, M. Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789,
-
[16]
D., Jin, H., Yao, Y ., Zhang, J., Zhang, T., Avestimehr, S., and He, C
Stripelis, D., Xu, Z., Hu, Z., Shah, A. D., Jin, H., Yao, Y ., Zhang, J., Zhang, T., Avestimehr, S., and He, C. Ten- soropera router: A multi-model router for efficient llm inference. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: In- dustry Track, pp. 452–462,
2024
-
[17]
Tsiourvas, A., Sun, W., and Perakis, G. Causal llm routing: End-to-end regret minimization from observational data. arXiv preprint arXiv:2505.16037,
-
[18]
When to reason: Semantic router for vllm
Wang, C., Liu, X., Liu, Y ., Zhu, Y ., Mo, X., Jiang, J., and Chen, H. When to reason: Semantic router for vllm. arXiv preprint arXiv:2510.08731,
-
[19]
arXiv preprint arXiv:2310.03094 , year=
Yue, M., Zhao, J., Zhang, M., Du, L., and Yao, Z. Large language model cascades with mixture of thoughts rep- resentations for cost-efficient reasoning.arXiv preprint arXiv:2310.03094,
-
[20]
Zeng, W., Dong, Y ., Zhou, J., Ma, J., Tan, J., Wang, R., and Li, M. Mpcache: Mpc-friendly kv cache eviction for efficient private large language model inference.arXiv preprint arXiv:2501.06807,
-
[21]
Zhuang, R., Wu, T., Wen, Z., Li, A., Jiao, J., and Ramchan- dran, K. Embedllm: Learning compact representations of large language models.arXiv preprint arXiv:2410.02223,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.