Recognition: unknown
Accuracy Is Speed: Towards Long-Context-Aware Routing for Distributed LLM Serving
Pith reviewed 2026-05-10 08:11 UTC · model grok-4.3
The pith
Under long-context serving, LLM accuracy becomes a speed metric because retries on incorrect answers accumulate user-visible delay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
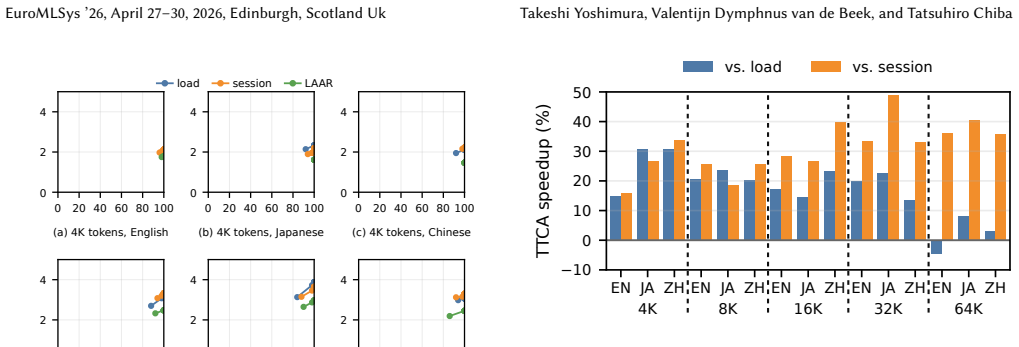
Accuracy becomes speed through retry dynamics in long-context distributed LLM serving. The central metric is Time-to-Correct-Answer (TTCA), defined as the wall-clock time to the first correct response. Prompt length and language amplify accuracy variance and thus inflate TTCA. Lightweight Accuracy-Aware Routing (LAAR) is shown to reduce TTCA by capability-based assignment of requests. Accuracy should therefore be a first-class objective in such serving systems.
What carries the argument
Time-to-Correct-Answer (TTCA) metric that tracks wall-clock time to first correct answer, carried by retry dynamics in the serving system, and the Lightweight Accuracy-Aware Routing (LAAR) that uses accuracy capabilities for request routing.
Load-bearing premise
That the serving system will retry requests upon receiving incorrect responses, and that accuracy differences across prompts and models are significant enough to affect overall timing in a measurable way.
What would settle it
If experiments show no reduction in TTCA when applying accuracy-aware routing, or if accuracy variance does not correlate with increased time to correct answers in long-context workloads.
Figures



read the original abstract
Distributed LLM serving systems optimize per-request latency and throughput. However, under long-context workloads, inference accuracy becomes more variable. When incorrect responses trigger retries, accuracy directly translates into cumulative user-visible delay that is not captured by single-shot latency metrics. In this work, we argue that under long-context serving, \textbf{accuracy becomes speed} through retry dynamics. We introduce \textit{Time-to-Correct-Answer (TTCA)}, a metric that measures the wall-clock time required to obtain the first correct response. Our measurement study shows that prompt characteristics such as length and language amplify accuracy variance, which inflates TTCA. We demonstrate \textit{Lightweight Accuracy-Aware Routing (LAAR)}, a capability-based routing design that reduces TTCA. Our results suggest that in long-context distributed serving, accuracy should be treated as a first-class systems objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under long-context distributed LLM serving, accuracy directly affects speed via retry dynamics on incorrect responses. It introduces the Time-to-Correct-Answer (TTCA) metric as wall-clock time to the first correct response, presents a measurement study showing that prompt length and language amplify accuracy variance and inflate TTCA, and demonstrates a Lightweight Accuracy-Aware Routing (LAAR) design that reduces TTCA, arguing that accuracy should be a first-class systems objective.
Significance. If the retry assumption holds in practice and the measurements are robust, the work could shift distributed serving designs toward accuracy-aware routing and metrics like TTCA, extending beyond traditional latency/throughput optimization. The LAAR proposal offers a concrete capability-based routing approach; the empirical focus on prompt characteristics provides falsifiable observations about variance in long-context workloads.
major comments (3)
- [Abstract] Abstract and §1: The central claim that 'accuracy becomes speed' through retry dynamics is load-bearing on the premise that incorrect responses are detected and trigger retries. The manuscript does not detail any correctness oracle, verifier, or ground-truth mechanism for open-ended long-context queries, which is required for TTCA to translate to user-visible delay in standard continuous-batching systems.
- [Measurement study] Measurement study: The claim that prompt length and language 'amplify accuracy variance, which inflates TTCA' lacks reported sample sizes, error bars, statistical significance tests, or explicit baselines (e.g., short-context controls), making it impossible to assess whether the observed effects are large enough to support treating accuracy as a first-class objective.
- [LAAR] LAAR demonstration: The routing design is presented as reducing TTCA, but the manuscript provides no overhead measurements for accuracy estimation or routing decisions, nor ablation showing that the reduction is due to accuracy awareness rather than other factors such as load balancing.
minor comments (2)
- [Abstract] The abstract states 'our results suggest' without quantifying the TTCA reduction achieved by LAAR or the number of workloads evaluated.
- [Introduction] Notation for TTCA should be defined with an explicit formula (e.g., TTCA = latency_1 + latency_2 + ... until correct) rather than only descriptively.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which have helped us improve the clarity and rigor of the paper. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract and §1: The central claim that 'accuracy becomes speed' through retry dynamics is load-bearing on the premise that incorrect responses are detected and trigger retries. The manuscript does not detail any correctness oracle, verifier, or ground-truth mechanism for open-ended long-context queries, which is required for TTCA to translate to user-visible delay in standard continuous-batching systems.
Authors: We agree that the applicability of TTCA depends on the presence of a mechanism to identify incorrect responses. The paper focuses on long-context workloads where such mechanisms are increasingly common, for instance in retrieval-augmented generation with fact-checking or in agentic systems with tool use for verification. In the revised manuscript, we will add a dedicated paragraph in Section 1 discussing practical correctness detection approaches and explicitly state the assumption under which TTCA measures user-visible delay. This clarification strengthens the presentation without altering the experimental results. revision: yes
-
Referee: [Measurement study] Measurement study: The claim that prompt length and language 'amplify accuracy variance, which inflates TTCA' lacks reported sample sizes, error bars, statistical significance tests, or explicit baselines (e.g., short-context controls), making it impossible to assess whether the observed effects are large enough to support treating accuracy as a first-class objective.
Authors: The referee correctly identifies a gap in the reporting of the measurement study. While the study included multiple runs, we did not sufficiently document the statistical details. In the revision, we will report the sample sizes used for each configuration, include error bars on all relevant figures, perform and report statistical significance tests (e.g., t-tests or ANOVA), and add explicit short-context control experiments to quantify the amplification effect. These additions will allow readers to better evaluate the magnitude of the observed variance. revision: yes
-
Referee: [LAAR] LAAR demonstration: The routing design is presented as reducing TTCA, but the manuscript provides no overhead measurements for accuracy estimation or routing decisions, nor ablation showing that the reduction is due to accuracy awareness rather than other factors such as load balancing.
Authors: We appreciate this point on the LAAR evaluation. The current results show TTCA reduction, but to isolate the effect, we will add overhead measurements for the accuracy estimation component and the routing decision latency. Furthermore, we will include an ablation study that compares LAAR against a load-balancing-only baseline (without accuracy awareness) under the same workload. This will demonstrate that the TTCA improvements stem from the accuracy-aware decisions. These changes will be incorporated in the revised version. revision: yes
Circularity Check
No circularity: empirical measurement and routing proposal are self-contained
full rationale
The paper introduces TTCA as a new metric for wall-clock time to first correct response under assumed retry dynamics, then reports direct measurements showing that prompt length and language increase accuracy variance (and thus TTCA). It proposes LAAR as a capability-based router to reduce TTCA. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the text. The derivation chain consists of empirical observation followed by system design, with no step reducing by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Incorrect responses trigger retries that add to user-visible delay
- domain assumption Prompt length and language amplify accuracy variance
invented entities (2)
-
Time-to-Correct-Answer (TTCA)
no independent evidence
-
Lightweight Accuracy-Aware Routing (LAAR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Am- mar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jian- min Bao, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Qin Cai, Vishrav Chaudhary, Dong Chen, Dongdong Chen, Weizhu Chen, Yen-Chun Chen, Yi-Ling Chen, Hao Cheng, Parul Chopra, Xiyang Dai, ...
work page internal anchor Pith review arXiv 2024
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. arXiv:2308.14508 [cs.CL] https://arxiv.org/abs/2308.14508
work page internal anchor Pith review arXiv 2024
-
[3]
Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masa- nari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, and Naoaki Okazaki. 2024. Continual Pre-Training for Cross- Lingual LLM Adaptation: Enhancing Japanese Language Capabilities. arXiv:2404.17790 [cs.CL]https://arxiv.org/abs/2404.17790
- [4]
-
[5]
Amey Hengle, Prasoon Bajpai, Soham Dan, and Tanmoy Chakraborty
-
[6]
arXiv:2408.10151 [cs.CL]https://arxiv.org/abs/2408.10151
Multilingual Needle in a Haystack: Investigating Long- Context Behavior of Multilingual Large Language Models. arXiv:2408.10151 [cs.CL]https://arxiv.org/abs/2408.10151
-
[7]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. RULER: What’s the Real Context Size of Your Long-Context Language Models? arXiv:2404.06654 [cs.CL]https://arxiv.org/abs/2404.06654
work page internal anchor Pith review arXiv 2024
-
[8]
IBM Granite Team. 2024. Granite 3.0 language models
2024
-
[9]
Kunal Jain, Anjaly Parayil, Ankur Mallick, Esha Choukse, Xiaot- ing Qin, Jue Zhang, Íñigo Goiri, Rujia Wang, Chetan Bansal, Vic- tor Rühle, Anoop Kulkarni, Steve Kofsky, and Saravan Rajmohan
-
[10]
Performance Aware LLM Load Balancer for Mixed Workloads. InProceedings of the 5th Workshop on Machine Learning and Sys- tems(World Trade Center, Rotterdam, Netherlands)(EuroMLSys ’25). Association for Computing Machinery, New York, NY, USA, 19–30. doi:10.1145/3721146.3721947
-
[11]
Bowen Jin, Jinsung Yoon, Jiawei Han, and Sercan O. Arik. 2024. Long- Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG. arXiv:2410.05983 [cs.CL]https://arxiv.org/abs/2410.05983 EuroMLSys ’26, April 27–30, 2026, Edinburgh, Scotland Uk Takeshi Yoshimura, Valentijn Dymphnus van de Beek, and Tatsuhiro Chiba
-
[12]
Kubernetes SIG Network. 2026. Gateway API Inference Exten- sion.https://github.com/kubernetes-sigs/gateway-api-inference- extensionGitHub repository. Accessed: 2026-04-10
2026
-
[13]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New Yor...
-
[14]
Ruiqi Lai, Siyu Cao, Leqi Li, Luo Mai, and Dmitrii Ustiugov. 2025. Manage the Workloads not the Cluster: Designing a Control Plane for Large-Scale AI Clusters. InProceedings of the 5th Workshop on Machine Learning and Systems(World Trade Center, Rotterdam, Netherlands) (EuroMLSys ’25). Association for Computing Machinery, New York, NY, USA, 246–253. doi:1...
-
[15]
arXiv preprint arXiv:2412.10319 , year =
Yucheng Li, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Surin Ahn, Chengruidong Zhang, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, and Lili Qiu. 2025. SCBench: A KV Cache-Centric Analysis of Long-Context Methods. arXiv:2412.10319 [cs.CL]https: //arxiv.org/abs/2412.10319
-
[16]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172 [cs.CL] https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
llm-d Project. 2026. llm-d Inference Scheduler.https://github.com/llm- d/llm-d-inference-schedulerGitHub repository. Accessed: 2026-04-10
2026
-
[18]
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, Pan Zhang, Liang- ming Pan, Yu-Gang Jiang, Jiaqi Wang, Yixin Cao, and Aixin Sun. 2024. MMLONGBENCH-DOC: benchmarking long-context document un- derstanding with visualizations. InProceedings of the 38th International Conference on Neural Informa...
2024
-
[19]
Moonmoon Mohanty, Gautham Bolar, Preetam Patil, UmaMaheswari Devi, Felix George, Pratibha Moogi, and Parimal Parag. 2025. De- ferred prefill for throughput maximization in LLM inference. In Proceedings of the 5th Workshop on Machine Learning and Systems (World Trade Center, Rotterdam, Netherlands)(EuroMLSys ’25). As- sociation for Computing Machinery, New...
- [20]
-
[21]
Pol G. Recasens, Ferran Agullo, Yue Zhu, Chen Wang, Eun Kyung Lee, Olivier Tardieu, Jordi Torres, and Josep Ll. Berral. 2025. Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Infer- ence . In2025 IEEE 18th International Conference on Cloud Computing (CLOUD). IEEE Computer Society, Los Alamitos, CA, USA, 277–287. doi:10.1109/CLOUD67622.2025.00036
- [22]
- [23]
-
[24]
Jackson, Zhifei Li, Jiarong Xing, Scott Shenker, and Ion Stoica
Tian Xia, Ziming Mao, Jamison Kerney, Ethan J. Jackson, Zhifei Li, Jiarong Xing, Scott Shenker, and Ion Stoica. 2025. SkyWalker: A Locality-Aware Cross-Region Load Balancer for LLM Inference. arXiv:2505.24095 [cs.DC]https://arxiv.org/abs/2505.24095
-
[25]
Haoyuan Xu, Chang Li, Xinyan Ma, Xianhao Ou, Zihan Zhang, Tao He, Xiangyu Liu, Zixiang Wang, Jiafeng Liang, Zheng Chu, Runxuan Liu, Rongchuan Mu, Dandan Tu, Ming Liu, and Bing Qin. 2026. The Evolution of Tool Use in LLM Agents: From Single-Tool Call to Multi- Tool Orchestration. arXiv:2603.22862 [cs.SE]https://arxiv.org/abs/ 2603.22862
-
[26]
Amy Yang, Jingyi Yang, Aya Ibrahim, Xinfeng Xie, Bangsheng Tang, Grigory Sizov, Jeremy Reizenstein, Jongsoo Park, and Jianyu Huang
-
[27]
Context parallelism for scalable million-token inference.arXiv preprint arXiv:2411.01783,
Context Parallelism for Scalable Million-Token Inference. arXiv:2411.01783 [cs.DC]https://arxiv.org/abs/2411.01783
- [28]
- [29]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.