Recognition: unknown
CoEvolve: Training LLM Agents via Agent-Data Mutual Evolution
Pith reviewed 2026-05-10 08:03 UTC · model grok-4.3
The pith
CoEvolve lets LLM agents and their training data evolve together through a closed loop that turns interaction feedback into new validated tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CoEvolve extracts feedback signals such as forgetting and uncertainty from rollout trajectories to identify failure-prone interaction patterns, utilizes them to guide LLM-based task synthesis, validates the synthesized tasks through environment interaction, and updates the data distribution, enabling joint adaptation of the agent and its data.
What carries the argument
The closed-loop mutual evolution mechanism that converts rollout feedback signals into synthesized and validated tasks to update the training distribution.
If this is right
- The training data distribution becomes dynamic and tracks the agent's current weaknesses instead of remaining fixed.
- New tasks are generated only for patterns that have already shown failure, improving coverage of complex interactions.
- Environment validation filters out low-value tasks before they enter the training set.
- Consistent absolute gains appear across model sizes from 7B to 30B parameters on the tested benchmarks.
Where Pith is reading between the lines
- The same feedback-driven synthesis loop could be tested on non-LLM agents if comparable rollout signals can be defined.
- The method may reduce the amount of human-curated data needed for effective agent training by automating task creation.
- Extending the approach to environments with much larger state spaces would require safeguards against unchecked growth of the task set.
Load-bearing premise
The extracted forgetting and uncertainty signals accurately mark failure-prone patterns whose synthesized tasks, once validated, produce genuine capability gains rather than synthesis artifacts or overfitting.
What would settle it
Running CoEvolve with the feedback signals replaced by random task selection and observing whether the reported gains on AppWorld and BFCL disappear or reverse.
Figures







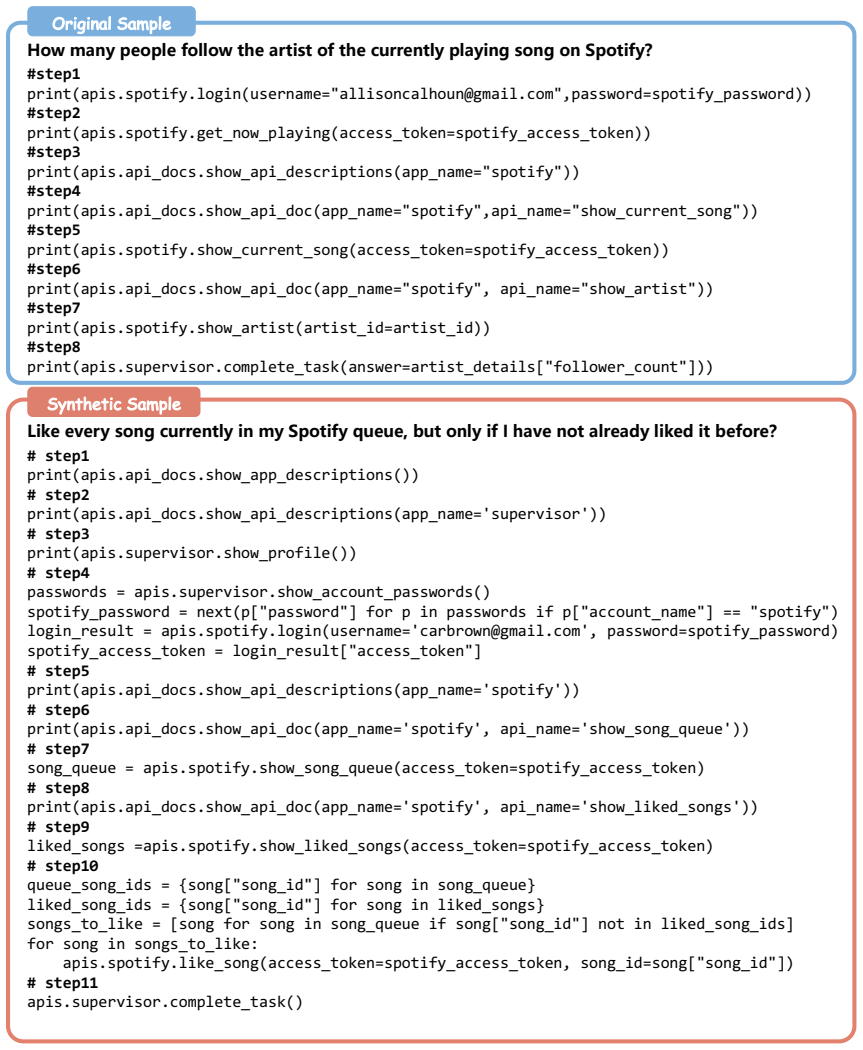




read the original abstract
Reinforcement learning for LLM agents is typically conducted on a static data distribution, which fails to adapt to the agent's evolving behavior and leads to poor coverage of complex environment interactions. To address these challenges, we propose CoEvolve, an agent-data mutual evolution framework that enables LLM agents to improve through closed-loop, interaction-driven training. Specifically, CoEvolve extracts feedback signals such as forgetting and uncertainty from rollout trajectories to identify failure-prone interaction patterns, and utilizes them to guide LLM-based task synthesis. The synthesized tasks are validated through environment interaction and utilized to update the data distribution, enabling joint adaptation of the agent and its data. Extensive experiments on AppWorld and BFCL across Qwen2.5-7B, Qwen3-4B, and Qwen3-30B-A3B demonstrate consistent and significant improvements over strong base models, yielding absolute gains of 19.43%, 15.58%, and 18.14%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoEvolve, a closed-loop framework for training LLM agents via mutual evolution between the agent and its training data distribution. Feedback signals (forgetting and uncertainty) are extracted from rollout trajectories to identify failure-prone interaction patterns; these signals guide LLM-based synthesis of new tasks, which are validated via environment interaction before being added to update the data distribution. This process enables joint adaptation. Experiments on AppWorld and BFCL across Qwen2.5-7B, Qwen3-4B, and Qwen3-30B-A3B report absolute gains of 19.43%, 15.58%, and 18.14% over base models.
Significance. If the central claim holds after addressing the issues below, the work would be significant for RL-based LLM agent training: it offers a principled way to move beyond static data distributions by using agent-specific signals to dynamically expand coverage of complex interactions. The reported gains on challenging benchmarks are substantial, and the emphasis on interaction-driven validation is a strength. However, without evidence that the specific feedback-guided loop is load-bearing, the contribution risks being reducible to generic data augmentation.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the reported absolute gains (19.43%, 15.58%, 18.14%) are presented without any ablation that isolates the contribution of the forgetting/uncertainty-guided synthesis from the simple addition of any environment-validated tasks. If adding an equivalent volume of randomly synthesized but validated tasks produces comparable improvements, the mutual-evolution mechanism is not shown to be necessary for the claimed joint adaptation.
- [§3] §3 (Method): the extraction of 'forgetting' (performance drop on prior tasks) and 'uncertainty' (rollout variance/entropy) and their quantitative use to guide LLM task synthesis are described at a high level without equations, pseudocode, or thresholds. It is therefore impossible to determine whether the signals actually steer synthesis toward failure-prone patterns or whether synthesis is largely independent of them, undermining the claim that the closed loop drives genuine capability gains rather than artifacts of extra training data.
- [§4] §4 (Experiments): no statistical tests, variance across runs, or comparison against strong baselines that also receive additional validated tasks are mentioned. The central claim that CoEvolve yields 'consistent and significant improvements' therefore rests on unverified effect sizes; this is load-bearing because the weakest assumption is precisely that the signals produce non-artifactual gains.
minor comments (2)
- [Abstract] Abstract: define 'forgetting' and 'uncertainty' more precisely (e.g., exact formulas for performance drop and entropy) so readers can immediately understand the feedback signals.
- [§2] §2 (Related Work): ensure coverage of recent work on LLM agent data synthesis and self-improvement loops is complete and that distinctions from prior methods are drawn explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of CoEvolve for RL-based LLM agent training. We address each major comment point by point below, acknowledging where the manuscript is currently lacking and committing to targeted revisions that will strengthen the evidence for the mutual-evolution mechanism.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported absolute gains (19.43%, 15.58%, 18.14%) are presented without any ablation that isolates the contribution of the forgetting/uncertainty-guided synthesis from the simple addition of any environment-validated tasks. If adding an equivalent volume of randomly synthesized but validated tasks produces comparable improvements, the mutual-evolution mechanism is not shown to be necessary for the claimed joint adaptation.
Authors: We agree that the current experiments do not isolate the contribution of the feedback-guided synthesis. The manuscript reports overall gains from the full CoEvolve pipeline but lacks a direct comparison to an equivalent volume of randomly synthesized yet environment-validated tasks. In the revised version we will add this ablation: we will generate and validate the same number of tasks using non-guided prompts (e.g., uniform or random sampling over interaction patterns) and retrain the agent on this augmented distribution. The resulting performance delta will be reported alongside the original CoEvolve results, allowing readers to assess whether the forgetting/uncertainty signals are load-bearing for the observed joint adaptation. revision: yes
-
Referee: [§3] §3 (Method): the extraction of 'forgetting' (performance drop on prior tasks) and 'uncertainty' (rollout variance/entropy) and their quantitative use to guide LLM task synthesis are described at a high level without equations, pseudocode, or thresholds. It is therefore impossible to determine whether the signals actually steer synthesis toward failure-prone patterns or whether synthesis is largely independent of them, undermining the claim that the closed loop drives genuine capability gains rather than artifacts of extra training data.
Authors: We acknowledge that §3 currently presents the signal extraction and guidance at a descriptive level. The revised manuscript will add precise definitions and implementation details: forgetting will be formalized as the drop in success rate on a fixed held-out set of prior tasks (Δ = acc_before − acc_after), uncertainty as the mean policy entropy or outcome variance across K rollouts per trajectory, and the synthesis prompt will be conditioned on tasks whose signals exceed explicit thresholds (e.g., forgetting > 0.10 or uncertainty in the top quartile). We will also include pseudocode for the full extraction–prioritization–synthesis–validation loop so that readers can verify how the signals steer task generation toward failure-prone patterns. revision: yes
-
Referee: [§4] §4 (Experiments): no statistical tests, variance across runs, or comparison against strong baselines that also receive additional validated tasks are mentioned. The central claim that CoEvolve yields 'consistent and significant improvements' therefore rests on unverified effect sizes; this is load-bearing because the weakest assumption is precisely that the signals produce non-artifactual gains.
Authors: We recognize that the experimental section currently omits variance estimates, statistical tests, and controlled baselines that also receive extra validated tasks. In the revision we will (1) report mean and standard deviation over at least three independent runs with different random seeds, (2) apply paired statistical tests (e.g., t-test or Wilcoxon signed-rank) between CoEvolve and all baselines, and (3) introduce an additional baseline that receives the same number of environment-validated tasks generated without our feedback signals. These additions will provide quantitative support for the consistency and significance of the gains and will directly address whether the improvements exceed those obtainable from generic data augmentation. revision: yes
Circularity Check
No significant circularity; empirical iterative framework with no definitional reductions
full rationale
The paper presents CoEvolve as a closed-loop agent-data evolution process: feedback signals (forgetting, uncertainty) from rollouts identify patterns, guide LLM task synthesis, followed by environment validation and data distribution update. No equations, fitted parameters, or predictions are described that reduce the reported gains (19.43%, 15.58%, 18.14%) to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the abstract or described chain. The derivation relies on experimental outcomes rather than mathematical self-reference, making the central claim independent of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents
A new image-bank harness and closed-loop on-policy data evolution method raises multimodal agent performance on visual search benchmarks from 24.9% to 39.0% for an 8B model and from 30.6% to 41.5% for a 30B model.
Reference graph
Works this paper leans on
-
[1]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- uan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, and 1 others. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556. Ziyu Ma, Chenhui Gou, Yiming Hu, Yong Wang, Bo- han...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Llm-based multi-agent reinforcement learn- ing: Current and future directions.arXiv preprint arXiv:2405.11106. Qwen Team. 2025. Qwen3-max: Just scale it. Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geof- frey J Gordon. 2018. An empirical study of exam- ple forgetting during deep neural network learning. ar...
-
[3]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Man- dlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. V oyager: ...
work page internal anchor Pith review arXiv 2023
-
[4]
Observe the current environment state and identify available actions
-
[5]
Analyze available actions and determine which ones will help with the exploration goal
-
[6]
Select a relevant action and execute it in the required format
-
[7]
Figure 9: Prompt templates for exploration: (a) system- side prompt and (b) user-side prompt
Focus on thorough exploration of the targeted area # Action Format: {action_format} ## Instructions: − Choose only one action at a time − Carefully read the environment description and task instructions − Ensure that the action is in the correct format − Do not use undefined actions − Always include a valid action and action tags in your reply − First ent...
-
[8]
Practice the exact operations from the context below
-
[9]
Create variations with different parameters
-
[10]
Connect this skill to related operations
-
[11]
(b) Template for Rare Event Signal Guidance Exploration Goal: Explore Rare Scenarios The agent encountered a RARE scenario that needs more exposure
Build up from simple to complex usage Context of forgetting: {context} Focus on thorough practice of these specific operations. (b) Template for Rare Event Signal Guidance Exploration Goal: Explore Rare Scenarios The agent encountered a RARE scenario that needs more exposure. Your exploration should:
-
[12]
Explore variations of the scenario below
-
[13]
Try different parameter combinations
-
[14]
Test edge cases and boundary conditions
-
[15]
(c) Template for Boundary Case Signal Exploration Goal: Explore Boundary Cases The agent's performance is BORDERLINE ( near success/failure threshold)
Collect diverse examples of this rare pattern Context of rare event: {context} Try to discover and document various forms of this scenario. (c) Template for Boundary Case Signal Exploration Goal: Explore Boundary Cases The agent's performance is BORDERLINE ( near success/failure threshold). Your exploration should:
-
[16]
Explore boundary conditions for these operations
-
[17]
Try similar tasks with slight parameter variations
-
[18]
Focus on distinguishing factors between success and failure
-
[19]
Figure 10: Prompt templates for three types of explo- ration signals: (a) forgetting, (b) rare event, and (c) boundary case
Collect examples at various difficulty levels Context of boundary case: {context} Focus on understanding what makes the difference between success and failure. Figure 10: Prompt templates for three types of explo- ration signals: (a) forgetting, (b) rare event, and (c) boundary case. Prompt Template for Signal-Conditioned Context Summarization You are an ...
-
[20]
A concise recap of this trajectory
-
[21]
Why failure or instability happened
-
[22]
Which patterns or behaviors should be re−explored
-
[23]
summary":
What mistakes should be explicitly avoided Return a JSON object with this schema: { "summary": "concise recap of the current trajectory evidence (task, key actions, and feedback outcome)", "failure_cause": "1−3 sentence root cause of failure or instability", "instability_pattern": "1−2 sentence pattern summary", "focus_pattern": ["pattern or behavior to f...
-
[24]
Inspect the interaction tuples (history, action, observation)
-
[25]
Identify the specific goal or task the agent is attempting to achieve
-
[26]
===================== ABSTRACTION RULES ================== − Focus on clear, goal−directed behaviour; ignore purely random exploration
Abstract each goal into a clear, concise **task description**, a **query** (suitable for search or training), and the **minimal action sequence** that successfully completes the task. ===================== ABSTRACTION RULES ================== − Focus on clear, goal−directed behaviour; ignore purely random exploration. − Please include as many steps as pos...
-
[27]
**API Matching**: Did the agent correctly call the required APIs according to the task requirements?
-
[28]
**Parameter Usage**: Were the parameters used in API calls correct and sufficient?
-
[29]
**Logical Flow**: Was the sequence of steps logical without unreasonable skips?
-
[30]
**Final Result**: Did the final state achieve the expected outcome, reasonably solve the task, obtain all necessary information, and complete the task objectives?
-
[31]
Do NOT mark the task as successful if the correct API was never called, the parameters were incorrect, or the result was not achieved, even if the intent seemed right
**Failed or Skipped Steps**: Were there any critical errors, skipped steps, or invalid code that prevented the task from being actually executed? # Format Your Response Strictly As: Success: [true/false] Reason: [Concise and specific explanation, referring to the above criteria.] Note: Ignore all Connection timeout or No valid action, because it is very l...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.