Recognition: no theorem link
Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents
Pith reviewed 2026-05-12 04:10 UTC · model grok-4.3
The pith
On-policy data evolution from agent rollouts boosts multimodal deep search performance from 24.9% to 39% on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A visual-native agent harness with an image bank reference protocol makes intermediate visual evidence reusable across tool calls, and On-policy Data Evolution (ODE) generates training data directly from the current policy's rollouts so that each round's data focuses on the precise gaps the model has not yet closed.
What carries the argument
On-policy Data Evolution (ODE), the closed-loop process that creates both supervised fine-tuning and reinforcement learning data from the target agent's own rollouts to match its evolving capability gaps.
If this is right
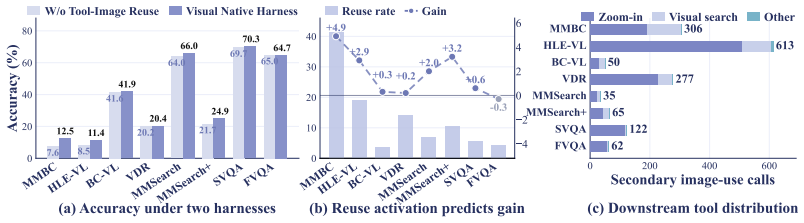
- Image bank reuse proves especially effective on complex tasks that need iterative visual refinement.
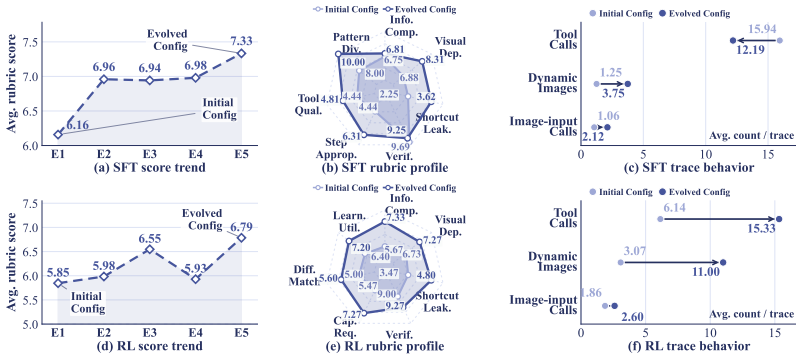
- Rollout-feedback evolution produces more grounded SFT traces and better policy-matched RL tasks than static synthesis.
- The approach delivers average score gains on all eight multimodal deep search benchmarks, including surpassing a larger closed model at the 8B scale.
- The same framework supports the full training lifecycle from supervised fine-tuning to policy optimization.
Where Pith is reading between the lines
- The method reduces dependence on static, human-curated datasets by generating data matched to the current policy.
- Image-bank reuse may improve performance in any agent workflow that chains multiple visual tools.
- Multiple rounds of ODE could lead to continued gains if the loop is run beyond the reported experiments.
Load-bearing premise
Rollouts from the current policy accurately reveal the exact capability gaps that need filling without creating self-reinforcing errors or training instability.
What would settle it
Running the same training procedure with ODE replaced by static data curation and measuring whether average scores on the eight benchmarks stay flat or drop instead of rising.
Figures








read the original abstract
Multimodal deep search requires an agent to solve open-world problems by chaining search, tool use, and visual reasoning over evolving textual and visual context. Two bottlenecks limit current systems. First, existing tool-use harnesses treat images returned by search, browsing, or transformation as transient outputs, so intermediate visual evidence cannot be re-consumed by later tools. Second, training data is usually built by fixed curation recipes that cannot track the target agent's evolving capability. To address these challenges, we first introduce a visual-native agent harness centered on an image bank reference protocol, which registers every tool-returned image as an addressable reference and makes intermediate visual evidence reusable by later tools. On top of this harness, On-policy Data Evolution (ODE) runs a closed-loop data generator that refines itself across rounds from rollouts of the policy being trained. This per-round refinement makes each round's data target what the current policy still needs to learn. The same framework supports both diverse supervised fine-tuning data and policy-aware reinforcement learning data curation, covering the full training lifecycle of the target agent. Across 8 multimodal deep search benchmarks, ODE improves the Qwen3-VL-8B agent from 24.9% to 39.0% on average, surpassing Gemini-2.5 Pro in standard agent-workflow setting (37.9%). At 30B, ODE raises the average score from 30.6% to 41.5%. Further analyses validate the effectiveness of image-bank reuse, especially on complex tasks requiring iterative visual refinement, while rollout-feedback evolution yields more grounded SFT traces and better policy-matched RL tasks than static synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a visual-native agent harness centered on an image bank reference protocol that registers tool-returned images as reusable references. It introduces On-policy Data Evolution (ODE), a closed-loop data generator that produces SFT and RL training data from rollouts of the policy being trained, with each round targeting remaining capability gaps. The authors report that ODE raises Qwen3-VL-8B performance from 24.9% to 39.0% average across 8 multimodal deep search benchmarks (surpassing Gemini-2.5 Pro at 37.9%) and improves the 30B variant from 30.6% to 41.5%, with further analyses on image-bank reuse and rollout-feedback benefits.
Significance. If the empirical gains are shown to stem from the on-policy mechanism rather than confounding factors, the work would offer a practical advance in multimodal agent training by replacing static data curation with adaptive, policy-aware data evolution and by solving the transient-image problem in tool-use harnesses. The scale of the reported lifts (roughly 14-point gains at both model sizes) would be notable for the field if reproducible and attributable to ODE.
major comments (2)
- [Abstract] Abstract: The headline performance numbers (24.9%→39.0% at 8B; 30.6%→41.5% at 30B) are stated without any accompanying experimental details on the number of ODE rounds, per-round data volumes, baseline agents, statistical tests, or ablation studies isolating ODE from the image-bank harness or from simple data scaling.
- [Abstract] Abstract: The claim that 'rollout-feedback evolution yields more grounded SFT traces and better policy-matched RL tasks than static synthesis' is not supported by any quantitative checks on data diversity, error-type distribution shift, or divergence from static baselines; this is load-bearing for the central assertion that on-policy rollouts precisely fill capability gaps without self-reinforcing biases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the abstract would benefit from additional context on the experimental setup and have revised it accordingly to include key details on ODE rounds, data volumes, and references to ablations. We also strengthen the presentation of quantitative support for the rollout-feedback claims. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance numbers (24.9%→39.0% at 8B; 30.6%→41.5% at 30B) are stated without any accompanying experimental details on the number of ODE rounds, per-round data volumes, baseline agents, statistical tests, or ablation studies isolating ODE from the image-bank harness or from simple data scaling.
Authors: We agree that the abstract is concise and omits these specifics. The full manuscript details the setup in Section 4: ODE was performed over 3 rounds for the 8B model and 2 rounds for the 30B model, generating approximately 45k SFT and 9k RL examples per round on average. Baselines include the unmodified Qwen3-VL, the image-bank harness alone, and static data synthesis at equivalent scale. Ablation studies (Table 4) isolate ODE's contribution from the harness and from naive data scaling, while statistical significance is evaluated via bootstrap resampling (p < 0.01 reported). We have revised the abstract to note the number of ODE rounds and to direct readers to the ablations and statistical results in the main text. revision: yes
-
Referee: [Abstract] Abstract: The claim that 'rollout-feedback evolution yields more grounded SFT traces and better policy-matched RL tasks than static synthesis' is not supported by any quantitative checks on data diversity, error-type distribution shift, or divergence from static baselines; this is load-bearing for the central assertion that on-policy rollouts precisely fill capability gaps without self-reinforcing biases.
Authors: The manuscript presents supporting analyses in Section 5.3 and Appendix C that quantify these aspects. Data diversity is measured via embedding variance and unique error-type coverage, showing an 18% increase for ODE SFT traces relative to static synthesis. Error-type distribution shifts are reported in Table 5, with ODE covering 32% more underrepresented failure modes. Divergence from static baselines is assessed via Jensen-Shannon distance on task distributions (0.14 for SFT, 0.11 for RL), confirming better policy alignment. These checks indicate that on-policy data targets remaining gaps without measurable self-reinforcement, as out-of-distribution performance also improves across rounds. To make the quantitative nature of the evidence more prominent, we have added an explicit summary paragraph and cross-references in the abstract. revision: partial
Circularity Check
No circularity; empirical benchmark gains from on-policy data generation
full rationale
The paper's core contribution is an empirical method (ODE) that generates training data via closed-loop rollouts from the target policy and reports average score lifts on 8 multimodal benchmarks (24.9%→39.0% at 8B; 30.6%→41.5% at 30B). No equations, fitted parameters, or first-principles derivations are presented that reduce to their own inputs by construction. The description of the image-bank harness and per-round refinement is procedural rather than tautological; the reported improvements are measured against external benchmarks and baselines, not derived from self-referential definitions or self-citations. This is a standard empirical ML paper whose validity rests on experimental outcomes, not on any load-bearing self-referential step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of reinforcement learning and supervised fine-tuning hold for the agent training loop.
invented entities (2)
-
Image bank reference protocol
no independent evidence
-
On-policy Data Evolution (ODE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
URLhttps://arxiv.org/abs/2402.14740. Anthropic. Claude 3.7 Sonnet System Card. Technical report, Anthropic, February 2025a. URL https://www-cdn.anthropic.com/9ff93dfa8f445c932415d335c88852ef47f1201e. pdf. Anthropic. System Card: Claude Opus 4 & Claude Sonnet
work page internal anchor Pith review arXiv
-
[2]
Technical report, Anthropic, May 2025b. URL https://www-cdn.anthropic.com/ 6d8a8055020700718b0c49369f60816ba2a7c285.pdf. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
doi: 10.1038/ s41586-025-09962-4. URLhttps://arxiv.org/abs/2501.14249. Mingyang Chen, Haoze Sun, Tianpeng Li, Fan Yang, Hao Liang, Keer Lu, Bin Cui, Wentao Zhang, Zenan Zhou, and Weipeng Chen. Facilitating multi-turn function calling for llms via compositional instruction tuning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://arxiv.org/abs/2410.12952. Shuang Chen, Kaituo Feng, Hangting Chen, Wenxuan Huang, Dasen Dai, Quanxin Shou, Yunlong Lin, Xiangyu Yue, Shenghua Gao, and Tianyu Pang. Opensearch-vl: An open recipe for frontier multimodal search agents,
-
[5]
URLhttps://arxiv.org/abs/2605.05185. Xianfu Cheng, Wei Zhang, Shiwei Zhang, Jian Yang, Xiangyuan Guan, Xianjie Wu, Xiang Li, Ge Zhang, Jiaheng Liu, Yuying Mai, Yutao Zeng, Zhoufutu Wen, Ke Jin, Baorui Wang, Weixiao Zhou, Yunhong Lu, Tongliang Li, Wenhao Huang, and Zhoujun Li. Simplevqa: Multimodal factuality evaluation for multimodal large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, and Gemini Team
URL https://arxiv.org/ abs/2502.13059. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, and Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,
-
[7]
URLhttps://arxiv.org/abs/2507.06261. Xinyu Geng, Peng Xia, Zhen Zhang, Xinyu Wang, Qiuchen Wang, Ruixue Ding, Chenxi Wang, Jialong Wu, Kuan Li, Yida Zhao, Huifeng Yin, Yong Jiang, Pengjun Xie, Fei Huang, Huaxiu Yao, Yi R. Fung, and Jingren Zhou. Webwatcher: Breaking new frontiers of vision-language deep research agent. InThe Fourteenth International Confe...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URLhttps://arxiv.org/abs/2601.22060. Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Guanglu Song, Peng Gao, Yu Liu, Chunyuan Li, and Hongsheng Li. MMSearch: Benchmarking the potential of large models as multi-modal search engines.arXiv preprint arXiv:2409.12959,
-
[9]
URLhttps://arxiv.org/abs/2409.12959. Shilong Li, Xingyuan Bu, Wenjie Wang, Jiaheng Liu, Jun Dong, Haoyang He, Hao Lu, Haozhe Zhang, Chenchen Jing, Zhen Li, Chuanhao Li, Jiayi Tian, Chenchen Zhang, Tianhao Peng, Yancheng He, Jihao Gu, Yuanxing Zhang, Jian Yang, Ge Zhang, Wenhao Huang, Wangchunshu Zhou, Zhaoxiang Zhang, Ruizhe Ding, and Shilei Wen. Mm-brows...
-
[10]
URLhttps://arxiv.org/abs/2508.13186. Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong Wang, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Xinzhi Wang, Yong Liu, Yasheng Wang, Duyu Tang, Dandan Tu, Lifeng Shang, Xin Jiang, Ruiming Tang, Defu Lian, Qun Liu, and Enhong C...
-
[11]
AgentInstruct: Toward generative teaching with agentic flows.arXiv preprint arXiv:2407.03502,
URLhttps://arxiv.org/abs/2407.03502. Kartik Narayan, Yang Xu, Tian Cao, Kavya Nerella, Vishal M. Patel, Navid Shiee, Peter Grasch, Chao Jia, Yinfei Yang, and Zhe Gan. Deepmmsearch-r1: Empowering multimodal llms in multimodal web search,
- [12]
-
[13]
URLhttps://arxiv.org/abs/2504.03601. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models,
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URLhttps://arxiv.org/abs/2402.03300. Aaditya Singh, Adam Fry, Adam Perelman, and OpenAI Team. Openai gpt-5 system card,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URLhttps://arxiv.org/abs/2601.03267. Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https: //arxiv.org/abs/2602.23166. Shuo Tang, Xianghe Pang, Zexi Liu, Bohan Tang, Rui Ye, Tian Jin, Xiaowen Dong, Yanfeng Wang, and Siheng Chen. Synthesizing post-training data for llms through multi-agent simulation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23306–23335,
-
[17]
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
URLhttps://arxiv.org/abs/2510.24701. Peng Wang, Qi Wu, Chunhua Shen, Anton van den Hengel, and Anthony Dick. Fvqa: Fact-based visual question answering,
-
[18]
Jinming Wu, Zihao Deng, Wei Li, Yiding Liu, Bo You, Bo Li, Zejun Ma, and Ziwei Liu
URLhttps://arxiv.org/abs/1606.05433. Jinming Wu, Zihao Deng, Wei Li, Yiding Liu, Bo You, Bo Li, Zejun Ma, and Ziwei Liu. Mmsearch-r1: Incentivizing lmms to search,
-
[19]
Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
URLhttps://arxiv.org/abs/2506.20670. Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal LLMs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
-
[20]
URL https://arxiv.org/abs/ 2604.15840. Yu Zeng, Wenxuan Huang, Zhen Fang, Shuang Chen, Yufan Shen, Yishuo Cai, Xiaoman Wang, Zhenfei Yin, Lin Chen, Zehui Chen, Shiting Huang, Yiming Zhao, Xu Tang, Yao Hu, Philip Torr, Wanli Ouyang, and Shaosheng Cao. Vision-deepresearch benchmark: Rethinking visual and textual search for multimodal large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URL https://arxiv.org/abs/ 2602.02185. Kangning Zhang, Wenxiang Jiao, Kounianhua Du, Yuan Lu, Weiwen Liu, Weinan Zhang, and Yong Yu. Looptool: Closing the data-training loop for robust llm tool calls,
-
[22]
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su
URL https: //arxiv.org/abs/2511.09148. Zhixin Zhang, Yiyuan Zhang, Xiaohan Ding, and Xiangyu Yue. Vision search assistant: Empower vision-language models as multimodal search engines.arXiv preprint arXiv:2410.21220,
-
[23]
SGLang: Efficient Execution of Structured Language Model Programs
URL https://arxiv.org/ abs/2312.07104. Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chunhua Shen, and Xing Yu. DeepEyes: Incentivizing “thinking with images” via reinforcement learning.arXiv preprint arXiv:2505.14362,
work page internal anchor Pith review arXiv
-
[24]
13 Appendix A Implementation Details of On-policy Data Evolution 15 A.1 Round ConfigurationC t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.2 Mode-Specific Trace Rubrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.3 Stage 1: Seed Proposal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
work page 1945
-
[25]
(2) The shift from colonial dependencies and trust territories to the NSGT framework. (3) UN institutional oversight of decolonization, from the Trusteeship Council to the C-24 Special Committee. (4) Territory-specific case documentation (Western Sahara).Edge structure.Node 1 (1945 baseline map) provides the territorial-status framework that later UN maps...
work page 1945
-
[26]
Node 6 (Western Sahara)supportsNode 5 through territory-specific cartographic detail.Reasoning enrichment.A consistency check between (a) the count of Trust Territories visible on the 1948 map and (b) the canonical roster of 11 originals attaches a derived quantity “10/11≈90.9% ” to the edge connecting Node 2 and Node 3, with provenance to the Trusteeship...
work page 1948
-
[27]
If the candidate merely mentions the reference phrase inside a negated statement, failure trace, or quoted query, mark no. 23 Calibration examples: - Correct: reference=’A set of edges without common vertices.’ candidate=’matching’ - Correct: reference=’Thought experiments.’ candidate=’used to explore philosophical questions about perception and reality’ ...
work page 2025
-
[28]
is a multimodal browsing benchmark de- signed to test whether agents can retrieve and reason over web evidence that may appear in images or videos rather than text alone. Its questions are hand-crafted to require multi-hop multimodal browsing, and each item includes fine-grained reasoning requirements for checking multimodal dependency. We evaluate on the...
work page 2026
-
[29]
is a fact-based visual question answering benchmark where answering requires external factual knowledge in addition to image understanding. Each question is associated with supporting facts, making it useful for evaluating knowledge-grounded visual reasoning. We randomly sample 300 examples for evaluation. Following prior evaluation practice where applica...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.