Recognition: unknown
Efficient Video Diffusion Models: Advancements and Challenges
Pith reviewed 2026-05-10 08:25 UTC · model grok-4.3
The pith
A survey that groups efficient video diffusion methods into four paradigms—step distillation, efficient attention, model compression, and cache/trajectory optimization—and outlines open challenges for practical use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
To the best of our knowledge, our work is the first comprehensive survey on efficient video diffusion models, offering researchers and engineers a structured overview of the field and its emerging research directions.
Load-bearing premise
That the proposed four-class categorization (step distillation, efficient attention, model compression, cache/trajectory optimization) comprehensively and unbiasedly covers all relevant methods without significant omissions or overlaps.
Figures






read the original abstract
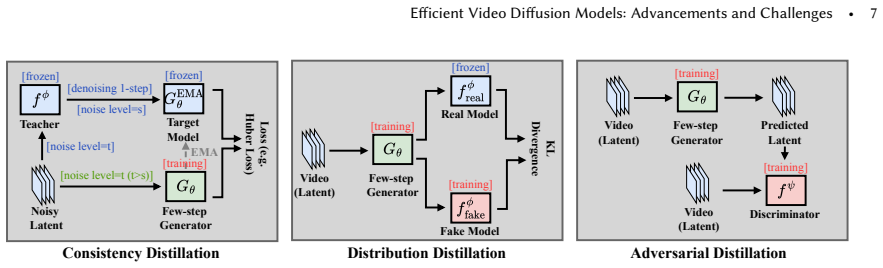
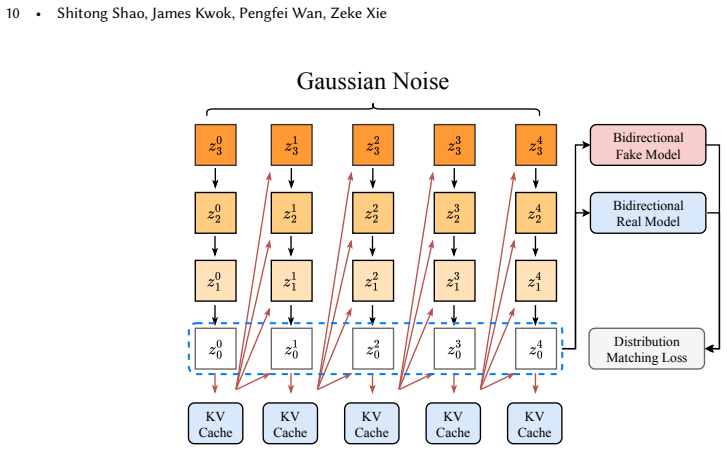
Video diffusion models have rapidly become the dominant paradigm for high-fidelity generative video synthesis, but their practical deployment remains constrained by severe inference costs. Compared with image generation, video synthesis compounds computation across spatial-temporal token growth and iterative denoising, making attention and memory traffic major bottlenecks in real-world settings. This survey provides a systematic and deployment-oriented review of efficient video diffusion models. We propose a unified categorization that organizes existing methods into four classes of main paradigms, including step distillation, efficient attention, model compression, and cache/trajectory optimization. Building on this categorization, we respectively analyze algorithmic trends of these four paradigms and examine how different design choices target two core objectives: reducing the number of function evaluations and minimizing per-step overhead. Finally, we discuss open challenges and future directions, including quality preservation under composite acceleration, hardware-software co-design, robust real-time long-horizon generation, and open infrastructure for standardized evaluation. To the best of our knowledge, our work is the first comprehensive survey on efficient video diffusion models, offering researchers and engineers a structured overview of the field and its emerging research directions.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: survey paper with no derivations or self-referential claims
full rationale
This is a survey paper that organizes existing literature on efficient video diffusion models into four proposed categories (step distillation, efficient attention, model compression, cache/trajectory optimization). It contains no original equations, derivations, fitted parameters, predictions, or mathematical results. The central claim is that the work is the first comprehensive survey, which is a statement of scope and novelty rather than a derived quantity. No self-citations are load-bearing for any result, and the categorization is an organizational framework applied to external methods, not a reduction to the paper's own inputs. The paper is self-contained as a review and scores 0 on circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Exploring Data-Free LoRA Transferability for Video Diffusion Models
CASA uses spectral density to arbitrate between preserving the target model's manifold and restoring LoRA alignment, mitigating style degradation and structural collapse in distilled video diffusion models.
Reference graph
Works this paper leans on
-
[4]
Ganesh Bikshandi, Tri Dao, Pradeep Ramani, Jay Shah, Vijay Thakkar, and Ying Zhang. 2024. FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision. InAdvances in Neural Information Processing Systems 37. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 68658–68685. https://doi.org/10.52202/079017-2193
-
[16]
Siyan Chen, Yanfei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Xuyan Chi, Jian Cong, Qinpeng Cui, Qide Dong, Junliang Fan, et al
-
[17]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model. arXiv:2512.13507 https://arxiv.org/abs/2512.13507
- [28]
-
[29]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations. OpenReview.net. https://openreview.net...
2020
-
[43]
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. 2025. Mean flows for one-step generative modeling. arXiv:2505.13447 https://arxiv.org/abs/2505.13447
work page internal anchor Pith review arXiv 2025
-
[49]
Junxian Guo, Haotian Tang, Shang Yang, Zhekai Zhang, Zhijian Liu, and Song Han. 2024. Block Sparse Attention. https://github.com/mit- han-lab/Block-Sparse-Attention
2024
-
[50]
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al . 2026. LTX-2: Efficient Joint Audio-Visual Foundation Model. arXiv:2601.03233 https: //arxiv.org/abs/2601.03233
work page Pith review arXiv 2026
-
[51]
Hao-AI-Lab. 2025. FastVideo. https://github.com/hao-ai-lab/FastVideo/tree/main
2025
-
[57]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. 2024. VBench: Comprehensive Benchmark Suite for Video Generative Models. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR...
-
[58]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. 2026. VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models.IEEE Transactions on Pattern Analysis and Machine I...
- [59]
- [60]
- [61]
-
[63]
Kim, Y ., Jang, J., and Shin, S
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S. Ryoo, and Tian Xie. 2024. Adaptive Caching for Faster Video Generation with Diffusion Transformers. arXiv:2411.02397 https://arxiv.org/abs/2411.02397
-
[64]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A Style-Based Generator Architecture for Generative Adversarial Networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 4396–4405. https://doi.org/10.1109/cvpr.2019.00453
- [65]
-
[66]
Jisoo Kim, Wooseok Seo, Junwan Kim, Seungho Park, Sooyeon Park, and Youngjae Yu. 2025. Vip: Iterative online preference distillation for efficient video diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 17235–17245. , Vol. 1, No. 1, Article . Publication date: April 2026. 30•Shitong Shao, James Kwok, Pengfei Wan,...
2025
-
[67]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al . 2024. HunyuanVideo: A Systematic Framework For Large Video Generative Models. arXiv:2412.03603 https://arxiv.org/abs/2412.03603
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [68]
-
[69]
Black Forest Labs. 2024. FLUX. https://blackforestlabs.ai/
2024
- [70]
- [71]
-
[72]
Xingyang Li, Muyang Li, Tianle Cai, Haocheng Xi, Shuo Yang, Yujun Lin, Lvmin Zhang, Songlin Yang, Jinbo Hu, Kelly Peng, Maneesh Agrawala, Ion Stoica, Kurt Keutzer, and Song Han. 2025. Radial Attention: 𝑂(𝑛log𝑛) Sparse Attention with Energy Decay for Long Video Generation. arXiv:2506.19852 https://arxiv.org/abs/2506.19852
- [73]
- [74]
- [75]
- [76]
- [77]
-
[78]
Akide Liu, Zeyu Zhang, Zhexin Li, Xuehai Bai, Yizeng Han, Jiasheng Tang, Yuanjie Xing, Jichao Wu, Mingyang Yang, Weihua Chen, Jiahao He, Yuanyu He, Fan Wang, Gholamreza Haffari, and Bohan Zhuang. 2025. FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion. arXiv:2506.04648 https://arxiv.org/abs/2506.04648
-
[79]
Kwok, Sumi Helal, and Zeke Xie
Buhua Liu, Shitong Shao, Bao Li, Lichen Bai, Zhiqiang Xu, Haoyi Xiong, James T. Kwok, Sumi Helal, and Zeke Xie. 2026. Alignment of Diffusion Models: Fundamentals, Challenges, and Future.Comput. Surveys58, 9 (March 2026), 1–37. https://doi.org/10.1145/3796982
- [80]
- [81]
- [82]
- [83]
- [84]
- [85]
- [86]
- [87]
-
[88]
Tianqi Liu, Zihao Huang, Zhaoxi Chen, Guangcong Wang, Shoukang Hu, Liao Shen, Huiqiang Sun, Zhiguo Cao, Wei Li, and Ziwei Liu
-
[89]
arXiv:2503.20785 https://arxiv.org/abs/2503.20785
Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency. arXiv:2503.20785 https://arxiv.org/abs/2503.20785
-
[90]
Xingchao Liu, Chengyue Gong, and Qiang Liu. 2022. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv:2209.03003 https://arxiv.org/abs/2209.03003
work page internal anchor Pith review arXiv 2022
-
[91]
Xinyan Liu, Huihong Shi, Yang Xu, and Zhongfeng Wang. 2026. TaQ-DiT: Time-aware Quantization for Diffusion Transformers.IEEE Transactions on Circuits and Systems for Video Technology(2026), 1–1. https://doi.org/10.1109/tcsvt.2026.3652275
-
[92]
Yong Liu, Jinshan Pan, Yinchuan Li, Qingji Dong, Chao Zhu, Yu Guo, and Fei Wang. 2025. UltraVSR: Achieving Ultra-Realistic Video Super-Resolution with Efficient One-Step Diffusion Space. InProceedings of the 33rd ACM International Conference on Multimedia. ACM, 7785–7794. https://doi.org/10.1145/3746027.3755117 , Vol. 1, No. 1, Article . Publication date:...
- [93]
-
[94]
Beijia Lu, Ziyi Chen, Jing Xiao, and Jun-Yan Zhu. 2025. Input-Aware Sparse Attention for Real-Time Co-Speech Video Generation. In Proceedings of the SIGGRAPH Asia 2025 Conference Papers. ACM, 1–11. https://doi.org/10.1145/3757377.3763831
- [95]
-
[96]
Yunhong Lu, Yanhong Zeng, Haobo Li, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jiapeng Zhu, Hengyuan Cao, Zhipeng Zhang, Xing Zhu, et al . 2025. Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation. arXiv:2512.04678 https://arxiv.org/abs/2512.04678
- [97]
-
[98]
Zhengyao Lv, Chenyang Si, Tianlin Pan, Zhaoxi Chen, Kwan-Yee K. Wong, Yu Qiao, and Ziwei Liu. 2025. Dual-Expert Consistency Model for Efficient and High-Quality Video Generation. arXiv:2506.03123 https://arxiv.org/abs/2506.03123
- [99]
-
[100]
Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xiaoniu Song, Xing Chen, Yu Zhou, Deshan Sun, Deyu Zhou, Jian Zhou, Kaijun Tan, Kang An, Mei Chen, Wei Ji, Qiling Wu, Wen Sun, Xin Han, Yanan Wei, Zheng Ge, Aojie Li, Bin Wang, Bizhu Huang, Bo Wang, Brian Li, Changxing Miao, Chen Xu, Chenfei Wu, Chenguang...
-
[101]
Xin Ma, Yaohui Wang, Genyun Jia, Xinyuan Chen, Tien-Tsin Wong, and Cunjian Chen. 2026. Consistent and Controllable Image Animation with Motion Linear Diffusion Transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence(2026), 1–16. https://doi.org/10.1109/tpami.2026.3664227
- [102]
-
[103]
2025.Krea Realtime 14B: Real-time Video Generation
Erwann Millon. 2025.Krea Realtime 14B: Real-time Video Generation. https://github.com/krea-ai/realtime-video
2025
-
[104]
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. 2024. OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation. arXiv:2407.02371 https://arxiv.org/abs/2407.02371
work page internal anchor Pith review arXiv 2024
-
[105]
Open-Sora-Plan. 2024. Mixkit. https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.1.0
2024
-
[106]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Transformers. In2023 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 4172–4182. https://doi.org/10.1109/iccv51070.2023.00387
- [107]
- [108]
- [109]
- [110]
- [111]
-
[112]
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. 2024. Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation. InSIGGRAPH Asia 2024 Conference Papers. ACM, 1–11. https: //doi.org/10.1145/3680528.3687625
-
[113]
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. 2024. Adversarial Diffusion Distillation. InComputer Vision – ECCV 2024. Springer Nature Switzerland, 87–103. https://doi.org/10.1007/978-3-031-73016-0_6 , Vol. 1, No. 1, Article . Publication date: April 2026. 32•Shitong Shao, James Kwok, Pengfei Wan, Zeke Xie
- [114]
- [115]
- [116]
-
[117]
Xuan Shen, Chenxia Han, Yufa Zhou, Yanyue Xie, Yifan Gong, Quanyi Wang, Yiwei Wang, Yanzhi Wang, Pu Zhao, and Jiuxiang Gu
-
[118]
DraftAttention: Fast Video Diffusion via Low-Resolution Attention Guidance. arXiv:2505.14708 https://arxiv.org/abs/2505.14708
-
[119]
Kuai Shou. 2024. Kling 2.6. https://app.klingai.com/global/release-notes/c605hp1tzd?type=dialog
2024
-
[120]
Gaurav Shrivastava and Abhinav Shrivastava. 2024. Video Prediction by Modeling Videos as Continuous Multi-Dimensional Processes. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 7236–7245. https://doi.org/10.1109/cvpr52733. 2024.00691
-
[121]
SkyTimelapse. 2021. SkyTimelapse. youtube.com/channel/UCtLemFmUPZYItte3PpG7f2Q/videos?reload=9
2021
-
[122]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. 2023. Consistency Models. InInternational Conference on Machine Learning. PMLR, 32211–32252
2023
-
[123]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2023. Score-Based Generative Modeling through Stochastic Differential Equations. InInternational Conference on Learning Representations. OpenReview.net. https: //openreview.net/forum?id=PxTIG12RRHS
2023
-
[124]
K Soomro. 2012. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv:1212.0402 https://arxiv.org/abs/1212.0402
work page internal anchor Pith review arXiv 2012
-
[125]
Stability.ai. 2024. Introducing Stable Diffusion 3.5. https://stability.ai/news/introducing-stable-diffusion-3-5
2024
-
[126]
Wenzhang Sun, Qirui Hou, Donglin Di, Jiahui Yang, Yongjia Ma, and Jianxun Cui. 2025. UniCP: A Unified Caching and Pruning Framework for Efficient Video Generation. InProceedings of the 7th ACM International Conference on Multimedia in Asia. ACM, 1–7. https://doi.org/10.1145/3743093.3770981
- [127]
- [128]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.