Recognition: unknown
Exploring Data-Free LoRA Transferability for Video Diffusion Models
Pith reviewed 2026-05-09 17:09 UTC · model grok-4.3
The pith
Spectral clashes in shared subspaces break LoRA transfer to distilled video models, but a data-free fix restores it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
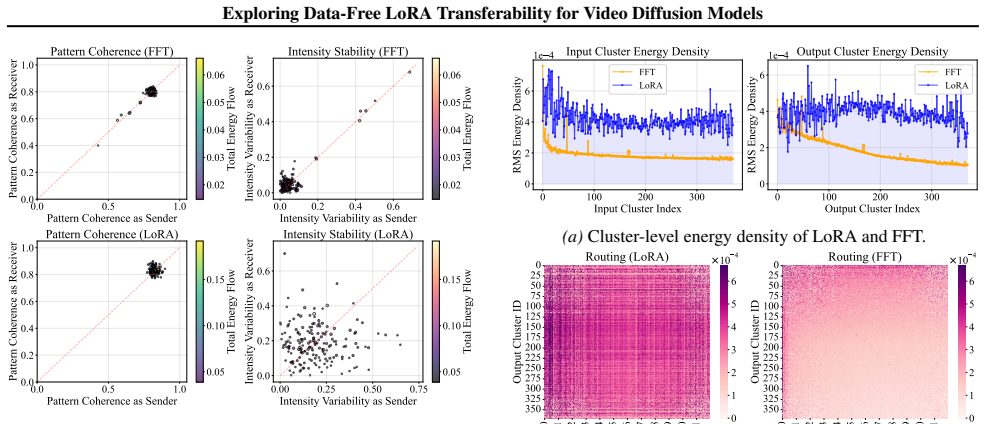
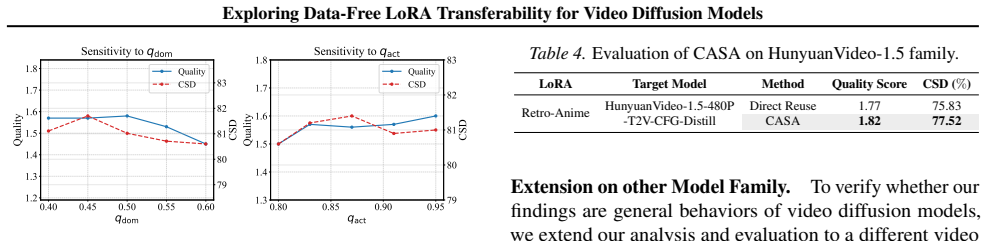
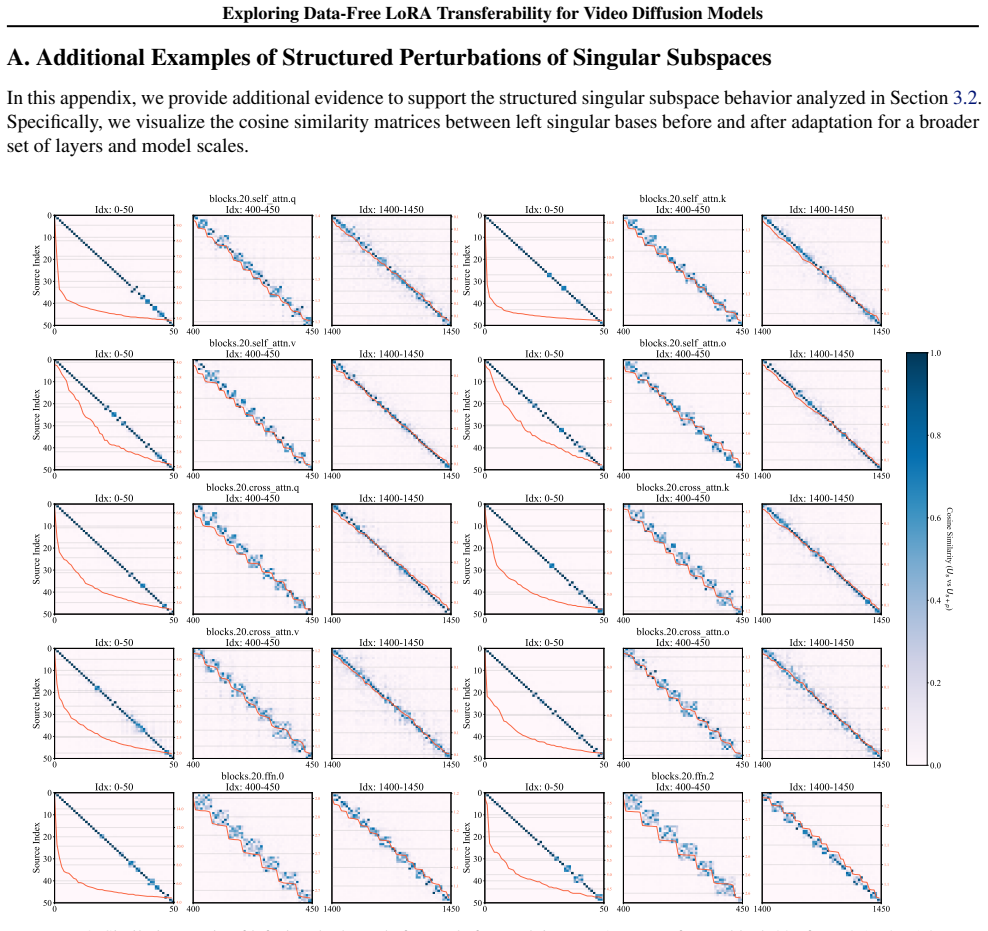
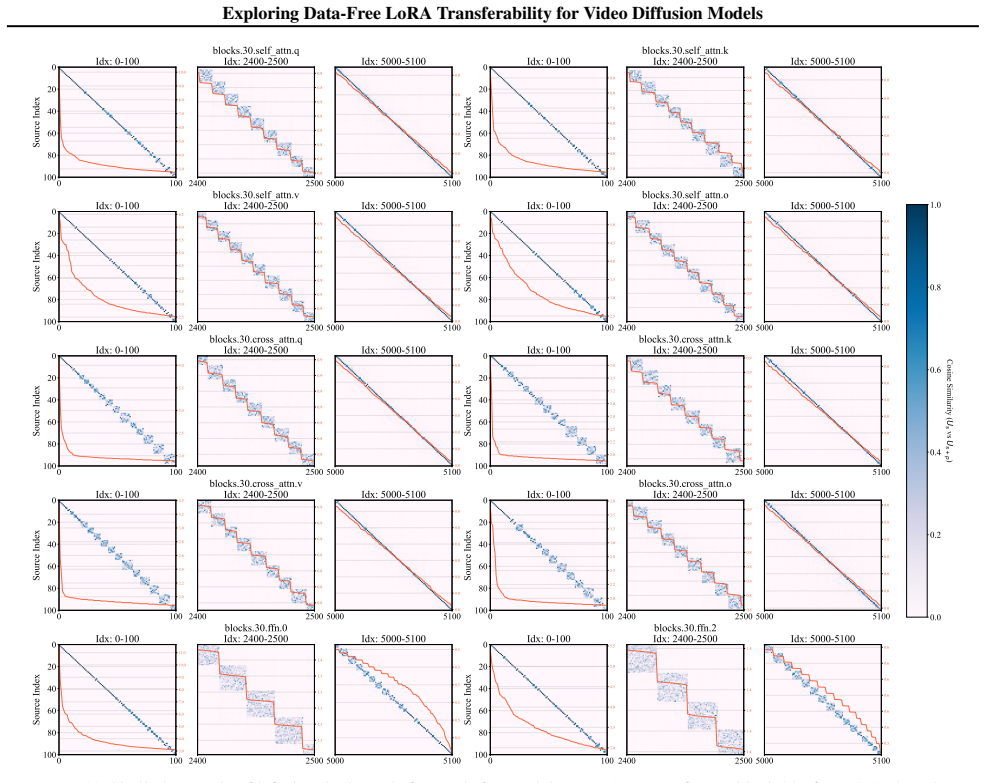
Incompatibility arises because both the original and distilled models respect spectral rigidity yet build conflicting routing pathways over the same singular subspaces, producing constructive overload or destructive cancellation. Cluster-Aware Spectral Arbitration resolves the clash by measuring spectral density and dynamically choosing whether to safeguard the target manifold or restore LoRA alignment.
What carries the argument
Cluster-Aware Spectral Arbitration (CASA), which inspects spectral densities within shared functional clusters and arbitrates between manifold protection and LoRA realignment.
If this is right
- Existing LoRAs become usable on step-distilled and causally-distilled video models without retraining or video samples.
- Generation artifacts drop and both motion consistency and visual style are recovered while keeping the speed gains of distillation.
- The approach operates entirely in weight space, so it can be applied at inference time to any compatible pair of base models.
Where Pith is reading between the lines
- Similar spectral diagnostics could be tested on other compression methods such as quantization or pruning to check whether the same subspace conflicts appear.
- Pre-computed spectral profiles for popular base models might allow instant compatibility checks before any LoRA is applied.
- The method raises the possibility that adapter libraries could be maintained across families of video generators without per-model fine-tuning.
Load-bearing premise
Spectral interference inside shared functional clusters is the main reason LoRAs fail on distilled models, and that density-based arbitration can fix the mismatch without data or retraining.
What would settle it
Apply CASA to a new distilled model and LoRA pair whose direct transfer already shows clear style loss; if spectral density maps reveal no interference clusters yet artifacts remain, or if CASA produces no measurable recovery, the account is falsified.
Figures










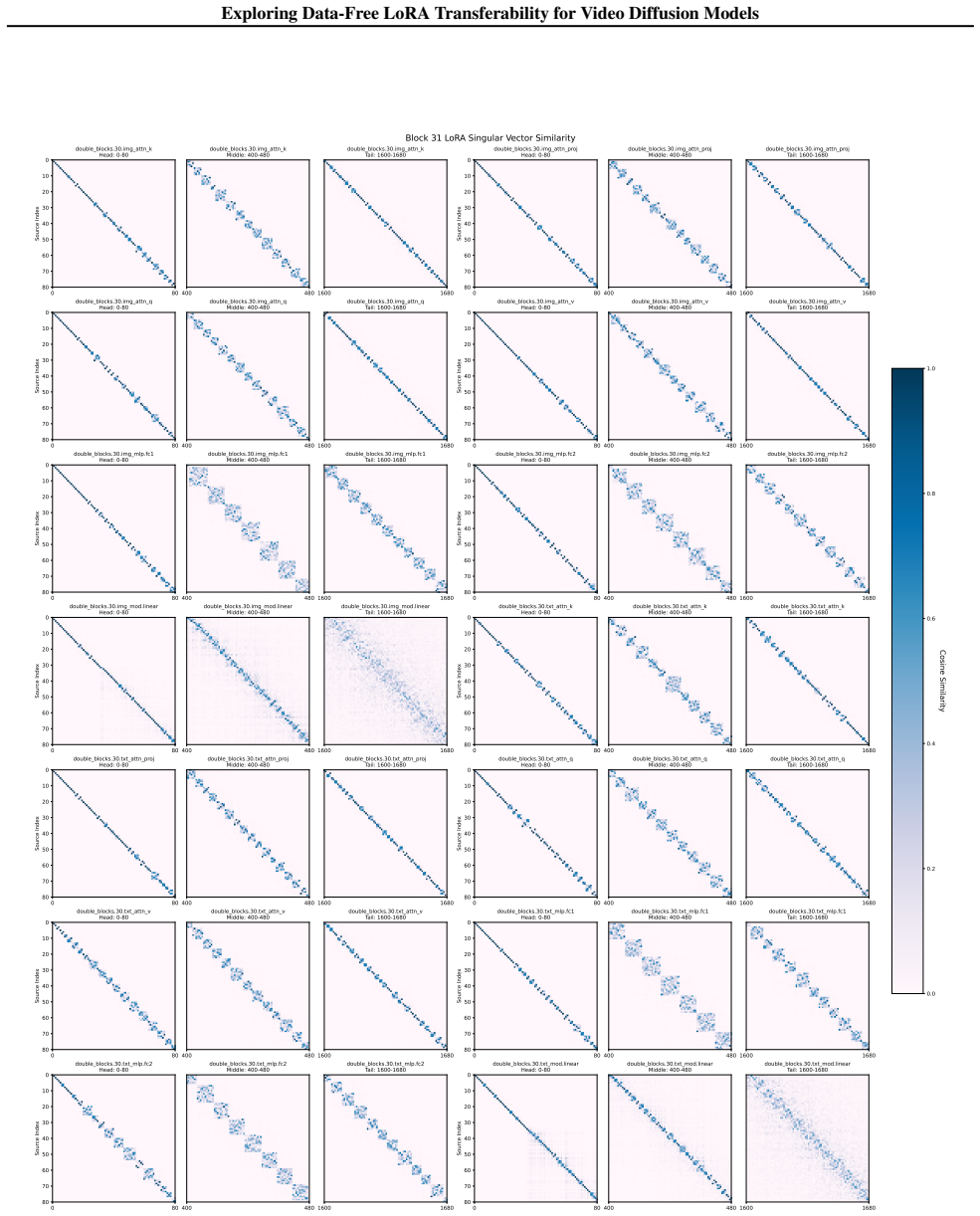

read the original abstract
Video diffusion models leveraging step distillation or causal distillation have achieved remarkable performance. However, adapting existing LoRAs to these variants remains a critical challenge due to weight space mismatches. We observe that direct application leads to style degradation and structural collapse, yet the underlying mechanisms remain poorly understood. To fill this gap, we delve into the weight space and identify that the incompatibility stems from spectral interference within shared functional clusters defined over singular subspaces. Specifically, our analysis reveals that while both paradigms respect spectral rigidity, they establish conflicting routing pathways that clash through constructive overload or destructive cancellation. To address this issue, we propose Cluster-Aware Spectral Arbitration (CASA), a data-free framework that dynamically arbitrates between safeguarding the target's manifold and restoring LoRA alignment based on spectral density. Extensive experiments demonstrate that CASA effectively mitigates artifacts and revives LoRA functionality. Our code is available at https://github.com/Noahwangyuchen/CASA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates challenges in transferring LoRAs to step- or causally-distilled video diffusion models, attributing incompatibility to spectral interference within shared functional clusters over singular subspaces that creates conflicting routing pathways (constructive overload or destructive cancellation). It proposes Cluster-Aware Spectral Arbitration (CASA), a data-free framework that dynamically arbitrates between safeguarding the target manifold and restoring LoRA alignment using spectral density, claiming that extensive experiments show CASA mitigates artifacts and revives LoRA functionality. Code is released at a GitHub link.
Significance. If the causal attribution and CASA mechanism are substantiated, the work would provide a practical data-free approach to adapting existing LoRAs to distilled video diffusion variants, addressing a real deployment barrier in generative video modeling without retraining or data access. The emphasis on weight-space spectral analysis offers a potentially generalizable lens, though the current lack of quantitative validation limits assessment of its contribution relative to existing LoRA adaptation techniques.
major comments (2)
- [Abstract] Abstract: The central claim that 'extensive experiments demonstrate that CASA effectively mitigates artifacts and revives LoRA functionality' is unsupported by any quantitative results, baselines, ablation studies, error bars, or statistical analysis, leaving the effectiveness of spectral-density arbitration unverified and the soundness of the contribution difficult to evaluate.
- [Abstract] Abstract: The diagnosis that incompatibility 'stems from spectral interference within shared functional clusters defined over singular subspaces' and produces 'conflicting routing pathways' is asserted without equations, derivations, or controlled isolation experiments that demonstrate this mechanism dominates over alternatives such as temporal-layer mismatches or global scale differences; this makes the data-free restoration claim rest on an untested causal attribution.
minor comments (1)
- [Abstract] The abstract references code availability but provides no details on experimental protocols, model variants tested, or reproducibility steps that would allow independent verification of the claimed results.
Simulated Author's Rebuttal
We thank the referee for the careful review and insightful comments on our work. We address each major comment point by point below, clarifying aspects of the manuscript and outlining revisions to improve clarity and substantiation of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'extensive experiments demonstrate that CASA effectively mitigates artifacts and revives LoRA functionality' is unsupported by any quantitative results, baselines, ablation studies, error bars, or statistical analysis, leaving the effectiveness of spectral-density arbitration unverified and the soundness of the contribution difficult to evaluate.
Authors: We appreciate the referee pointing out the need for stronger support in the abstract. The full manuscript contains quantitative evaluations in the Experiments section, including baseline comparisons, ablation studies on spectral density thresholds, and visual assessments. To address the concern directly, we will revise the abstract to include specific quantitative metrics (e.g., improvements in perceptual quality scores and statistical significance from user studies) that substantiate the effectiveness of CASA. This change will be incorporated in the revised version. revision: yes
-
Referee: [Abstract] Abstract: The diagnosis that incompatibility 'stems from spectral interference within shared functional clusters defined over singular subspaces' and produces 'conflicting routing pathways' is asserted without equations, derivations, or controlled isolation experiments that demonstrate this mechanism dominates over alternatives such as temporal-layer mismatches or global scale differences; this makes the data-free restoration claim rest on an untested causal attribution.
Authors: We acknowledge that the abstract states the diagnosis concisely. Section 3 of the manuscript presents a weight-space spectral analysis identifying shared functional clusters and the resulting interference. However, to strengthen the causal claim as noted, we will add explicit equations and derivations for the constructive overload and destructive cancellation effects, plus controlled ablation experiments isolating spectral interference from factors such as temporal mismatches. These additions will be included in the revised manuscript to better substantiate the mechanism. revision: yes
Circularity Check
No circularity detected; derivation is observational and self-contained
full rationale
The provided abstract and manuscript description contain no equations, derivations, or self-citations that reduce any claimed result to its inputs by construction. The incompatibility analysis is presented as an empirical observation of spectral interference in singular subspaces, and CASA is introduced as a new data-free arbitration framework based on spectral density. No fitted parameters are renamed as predictions, no uniqueness theorems are imported from prior self-work, and no ansatz is smuggled via citation. The central claims rest on direct weight-space inspection and experimental validation rather than tautological redefinition or load-bearing self-reference. This is consistent with standard non-circular empirical framework papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion model weights exhibit spectral rigidity across distillation paradigms
- domain assumption Singular subspaces define shared functional clusters in the weight space
invented entities (1)
-
Cluster-Aware Spectral Arbitration (CASA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Somepalli, Gowthami and Gupta, Anubhav and Gupta, Kamal and Palta, Shramay and Goldblum, Micah and Geiping, Jonas and Shrivastava, Abhinav and Goldstein, Tom , title =. 2024 , isbn =. doi:10.1007/978-3-031-72848-8_9 , booktitle =
-
[2]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Ding, Zihan and Jin, Chi and Liu, Difan and Zheng, Haitian and Singh, Krishna Kumar and Zhang, Qiang and Kang, Yan and Lin, Zhe and Liu, Yuchen , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[3]
2025 , eprint=
Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation , author=. 2025 , eprint=
2025
-
[4]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2023 , eprint=
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets , author=. 2023 , eprint=
2023
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Hunyuanvideo: A systematic framework for large video generative models , author=. arXiv preprint arXiv:2412.03603 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Video generation models as world simulators , author=
-
[8]
FastVideo: A Unified Framework for Accelerated Video Generation , author =
-
[9]
Forty-second International Conference on Machine Learning , year=
Diffusion Adversarial Post-Training for One-Step Video Generation , author=. Forty-second International Conference on Machine Learning , year=
-
[10]
Forty-second International Conference on Machine Learning , year=
Sparse Video-Gen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity , author=. Forty-second International Conference on Machine Learning , year=
-
[11]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[12]
Kaifeng Gao and Jiaxin Shi and Hanwang Zhang and Chunping Wang and Jun Xiao and Long Chen , booktitle=. Ca2-
-
[13]
Long-context autoregressive video modeling with next-frame prediction , author=. arXiv preprint arXiv:2503.19325 , year=
-
[14]
and Durand, Fredo and Shechtman, Eli and Huang, Xun , title =
Yin, Tianwei and Zhang, Qiang and Zhang, Richard and Freeman, William T. and Durand, Fredo and Shechtman, Eli and Huang, Xun , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[15]
arXiv preprint arXiv:2505.13389 , year=
Vsa: Faster video diffusion with trainable sparse attention , author=. arXiv preprint arXiv:2505.13389 , year=
-
[16]
Shih-Yang Liu and Chien-Yi Wang and Hongxu Yin and Pavlo Molchanov and Yu-Chiang Frank Wang and Kwang-Ting Cheng and Min-Hung Chen , booktitle=. Do
-
[17]
Chenghao Fan and Zhenyi Lu and Sichen Liu and Chengfeng Gu and Xiaoye Qu and Wei Wei and Yu Cheng , booktitle=. Make Lo
-
[18]
Fanxu Meng and Zhaohui Wang and Muhan Zhang , booktitle=. Pi
-
[19]
2025 , eprint=
Weight Spectra Induced Efficient Model Adaptation , author=. 2025 , eprint=
2025
-
[20]
Reece S Shuttleworth and Jacob Andreas and Antonio Torralba and Pratyusha Sharma , booktitle=. Lo
-
[21]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
X-adapter: Adding universal compatibility of plugins for upgraded diffusion model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
Trans-LoRA: towards data-free Transferable Parameter Efficient Finetuning , volume =
Wang, Runqian and Ghosh, Soumya and Cox, David and Antognini, Diego and Oliva, Aude and Feris, Rogerio and Karlinsky, Leonid , booktitle =. Trans-LoRA: towards data-free Transferable Parameter Efficient Finetuning , volume =. doi:10.52202/079017-1957 , editor =
-
[24]
Farzad Farhadzadeh and Debasmit Das and Shubhankar Borse and Fatih Porikli , booktitle=. Lo
-
[25]
Forty-second International Conference on Machine Learning , year=
Zero-Shot Adaptation of Parameter-Efficient Fine-Tuning in Diffusion Models , author=. Forty-second International Conference on Machine Learning , year=
-
[26]
2025 , eprint=
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time , author=. 2025 , eprint=
2025
-
[27]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and Wang, Yaohui and Chen, Xinyuan and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle=
-
[28]
2025 , eprint=
LongLive: Real-time Interactive Long Video Generation , author=. 2025 , eprint=
2025
-
[29]
Krea Realtime 14B: Real-time Video Generation , author=
-
[30]
The Thirteenth International Conference on Learning Representations , year=
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
VACE: All-in-One Video Creation and Editing , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[33]
Chandler Davis and W. M. Kahan , journal =. The Rotation of Eigenvectors by a Perturbation. III , volume =
-
[34]
Tim Dettmers and Artidoro Pagnoni and Ari Holtzman and Luke Zettlemoyer , booktitle=
-
[35]
The Eleventh International Conference on Learning Representations , year=
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. The Eleventh International Conference on Learning Representations , year=
-
[36]
Dawid Jan Kopiczko and Tijmen Blankevoort and Yuki M Asano , booktitle=. Ve
-
[37]
2024 , eprint=
See Further for Parameter Efficient Fine-tuning by Standing on the Shoulders of Decomposition , author=. 2024 , eprint=
2024
-
[38]
The Thirteenth International Conference on Learning Representations , year=
Unleashing the Power of Task-Specific Directions in Parameter Efficient Fine-tuning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[39]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Improving Video Generation with Human Feedback , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[40]
2025 , eprint=
HunyuanVideo 1.5 Technical Report , author=. 2025 , eprint=
2025
-
[41]
Efficient Video Diffusion Models: Advancements and Challenges
Efficient Video Diffusion Models: Advancements and Challenges , author =. arXiv preprint arXiv:2604.15911 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.