Recognition: unknown
Hierarchical Codec Diffusion for Video-to-Speech Generation
Pith reviewed 2026-05-10 08:08 UTC · model grok-4.3
The pith
A diffusion transformer generates speech from silent video by aligning visual cues to different levels of a speech codec hierarchy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HiCoDiT generates discrete speech tokens level by level from video input. Lower-level blocks condition on lip-synchronized motion and facial identity to capture speaker-aware semantics, while higher-level blocks use facial expression to modulate prosodic dynamics. A dual-scale adaptive instance layer normalization captures global vocal style through channel-wise normalization and local prosody dynamics through temporal-wise normalization. This hierarchical conditioning produces stronger audio-visual alignment than prior methods.
What carries the argument
The Hierarchical Codec Diffusion Transformer (HiCoDiT) with level-specific blocks and dual-scale adaptive instance layer normalization, which matches coarse visual cues to lower RVQ tokens and fine visual cues to higher RVQ tokens.
If this is right
- Stronger direct matching of visual motion to speech content and prosody at the exact token granularity where each property lives.
- Generation of speech without any audio signal at inference time while still preserving speaker identity and rhythmic detail.
- Demonstration that discrete codec tokens support more precise property alignment than continuous waveform or spectrogram methods.
- Improved handling of facial expression effects on speech timing and intonation through dedicated high-level blocks.
Where Pith is reading between the lines
- The same level-wise conditioning pattern could be tested on video-to-music or video-to-sound-effect tasks where audio also has coarse identity and fine timing layers.
- If the RVQ separation is stable, future work could try learning which visual features route to which level rather than fixing the assignment by hand.
- Performance on videos with rapid expression changes or multiple speakers would test how well the assumed semantic split survives outside controlled talking-head data.
Load-bearing premise
That lower levels of the RVQ codec naturally encode coarse speaker semantics while higher levels encode fine prosody, so visual signals can be applied separately at each level without audio input.
What would settle it
An ablation that removes level-specific conditioning and applies the same visual features to every token level, then measures whether objective fidelity scores and subjective expressiveness ratings drop compared with the full model.
Figures


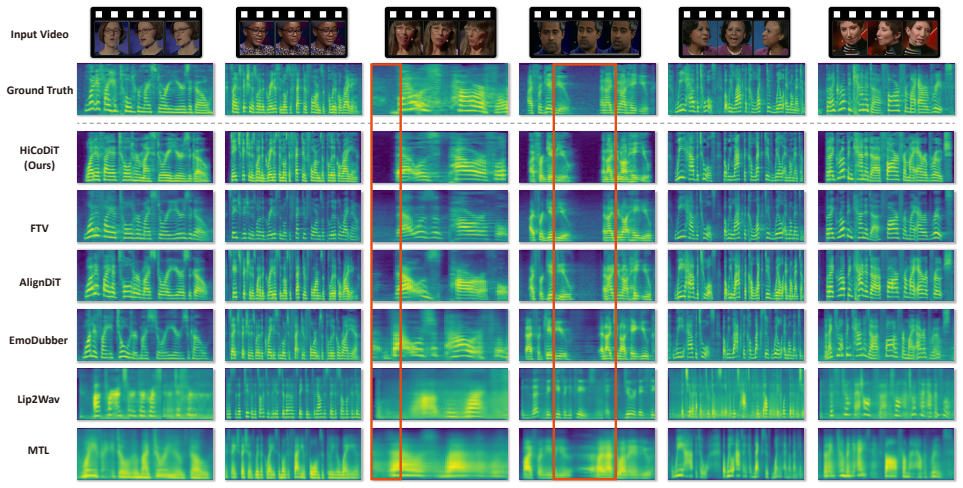

read the original abstract
Video-to-Speech (VTS) generation aims to synthesize speech from a silent video without auditory signals. However, existing VTS methods disregard the hierarchical nature of speech, which spans coarse speaker-aware semantics to fine-grained prosodic details. This oversight hinders direct alignment between visual and speech features at specific hierarchical levels during property matching. In this paper, leveraging the hierarchical structure of Residual Vector Quantization (RVQ)-based codec, we propose HiCoDiT, a novel Hierarchical Codec Diffusion Transformer that exploits the inherent hierarchy of discrete speech tokens to achieve strong audio-visual alignment. Specifically, since lower-level tokens encode coarse speaker-aware semantics and higher-level tokens capture fine-grained prosody, HiCoDiT employs low-level and high-level blocks to generate tokens at different levels. The low-level blocks condition on lip-synchronized motion and facial identity to capture speaker-aware content, while the high-level blocks use facial expression to modulate prosodic dynamics. Finally, to enable more effective coarse-to-fine conditioning, we propose a dual-scale adaptive instance layer normalization that jointly captures global vocal style through channel-wise normalization and local prosody dynamics through temporal-wise normalization. Extensive experiments demonstrate that HiCoDiT outperforms baselines in fidelity and expressiveness, highlighting the potential of discrete modelling for VTS. The code and speech demo are both available at https://github.com/Jiaxin-Ye/HiCoDiT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HiCoDiT, a Hierarchical Codec Diffusion Transformer for video-to-speech (VTS) synthesis. It exploits the hierarchical structure of RVQ-based discrete speech codecs by routing low-level tokens (assumed to encode coarse speaker-aware semantics) through blocks conditioned on lip motion and facial identity, while high-level tokens (assumed to encode fine prosody) are conditioned on facial expressions. A dual-scale adaptive instance normalization (AdaIN) is introduced to jointly model global vocal style and local temporal dynamics. The work claims that this level-specific conditioning yields superior fidelity and expressiveness over flat baselines, with code and demos released.
Significance. If the central hierarchy assumption holds and the reported gains are reproducible, the approach would strengthen discrete-token methods for VTS by enabling more direct visual-to-semantic alignment at multiple scales. The public release of code and speech samples is a clear positive that supports reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): The premise that 'lower-level tokens encode coarse speaker-aware semantics and higher-level tokens capture fine-grained prosody' is asserted without codec-specific validation (e.g., no token visualizations, mutual-information analysis, or ablation on RVQ levels when audio is absent). This separation directly justifies the dual conditioning paths and dual-scale AdaIN; if it does not hold for the chosen codec, the claimed audio-visual alignment advantage over flat baselines is unsupported.
- [§4] §4 (Experiments): The abstract states that 'extensive experiments demonstrate outperformance,' yet no quantitative tables, specific baselines, metrics (e.g., WER, MOS, F0 correlation), or statistical significance tests are referenced in the provided text. Without these, the strength of the fidelity/expressiveness claims cannot be assessed.
minor comments (2)
- [Figure 1 and §3.2] Figure 1 and §3.2: The architecture diagram and block descriptions would benefit from explicit labeling of which RVQ levels are routed to low-level vs. high-level blocks and how the dual-scale AdaIN is applied temporally vs. channel-wise.
- [Notation] Notation: Define the exact RVQ codebook sizes and the number of levels used in the hierarchical diffusion process to avoid ambiguity when reproducing the conditioning scheme.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the validation of our core assumptions and the clarity of our experimental claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The premise that 'lower-level tokens encode coarse speaker-aware semantics and higher-level tokens capture fine-grained prosody' is asserted without codec-specific validation (e.g., no token visualizations, mutual-information analysis, or ablation on RVQ levels when audio is absent). This separation directly justifies the dual conditioning paths and dual-scale AdaIN; if it does not hold for the chosen codec, the claimed audio-visual alignment advantage over flat baselines is unsupported.
Authors: We appreciate this observation. While the hierarchical properties of RVQ (lower levels capturing broader semantics and higher levels refining prosodic details) are established in the speech codec literature (e.g., EnCodec and SoundStream papers), we acknowledge the value of codec-specific validation for our setup. In the revised manuscript we will add (i) visualizations of RVQ token distributions, (ii) mutual-information analysis between individual RVQ levels and visual features, and (iii) an ablation that conditions only on visual inputs (audio absent) to empirically support the level-specific separation. These additions will directly bolster the justification for the dual conditioning paths and dual-scale AdaIN. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract states that 'extensive experiments demonstrate outperformance,' yet no quantitative tables, specific baselines, metrics (e.g., WER, MOS, F0 correlation), or statistical significance tests are referenced in the provided text. Without these, the strength of the fidelity/expressiveness claims cannot be assessed.
Authors: We apologize if the experimental details were not sufficiently cross-referenced in the text the referee received. Section 4 of the full manuscript already contains quantitative tables reporting WER, MOS, F0 correlation, additional fidelity metrics, comparisons against multiple baselines, and statistical significance tests. In the revision we will explicitly cite these results from §4 in both the abstract and §3, and ensure all tables are prominently referenced so that the outperformance claims are immediately verifiable. revision: yes
Circularity Check
No circularity; architecture rests on explicit upfront assumption about RVQ hierarchy rather than self-referential derivation
full rationale
The paper states its core premise directly in the abstract and method section: lower RVQ levels encode coarse speaker semantics while higher levels encode prosody. It then builds level-specific conditioning blocks and dual-scale AdaIN on top of that premise. This is an assumption, not a derivation that reduces to its own outputs or fitted parameters. No equations are shown to be equivalent by construction, no self-citations form a load-bearing chain for the hierarchy claim, and no 'prediction' is statistically forced from a subset of the same data. The empirical results (outperformance on fidelity/expressiveness) are presented as validation of the design choice, not as tautological confirmation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lower-level RVQ tokens encode coarse speaker-aware semantics and higher-level tokens capture fine-grained prosody
Reference graph
Works this paper leans on
-
[1]
LRS3-TED: a large- scale dataset for visual speech recognition,
Triantafyllos Afouras, Joon Son Chung, and Andrew Zisser- man. LRS3-TED: A large-scale dataset for visual speech recognition.arXiv preprint:1809.00496, 2018. 5
-
[2]
Johnson, Jonathan Ho, Daniel Tar- low, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tar- low, and Rianne van den Berg. Structured denoising diffu- sion models in discrete state-spaces. InAdv. Neural Inform. Process. Syst., pages 17981–17993, 2021. 2
2021
-
[3]
Re- pLDM: Reprogramming pretrained latent diffusion models for high-quality, high-efficiency, high-resolution image gen- eration
Boyuan Cao, Jiaxin Ye, Yujie Wei, and Hongming Shan. Re- pLDM: Reprogramming pretrained latent diffusion models for high-quality, high-efficiency, high-resolution image gen- eration. InAdv. Neural Inform. Process. Syst.2
-
[4]
V2C: Visual voice cloning
Qi Chen, Mingkui Tan, Yuankai Qi, Jiaqiu Zhou, Yuanqing Li, and Qi Wu. V2C: Visual voice cloning. InIEEE Conf. Comput. Vis. Pattern Recog., pages 21210–21219, 2022. 1, 5
2022
-
[5]
DiffV2S: Diffusion-based video-to-speech synthesis with vision- guided speaker embedding
Jeongsoo Choi, Joanna Hong, and Yong Man Ro. DiffV2S: Diffusion-based video-to-speech synthesis with vision- guided speaker embedding. InInt. Conf. Comput. Vis., pages 7778–7787, 2023. 1, 2, 6
2023
-
[6]
AlignDiT: Multimodal aligned dif- fusion transformer for synchronized speech generation
Jeongsoo Choi, Ji-Hoon Kim, Kim Sung-Bin, Tae-Hyun Oh, and Joon Son Chung. AlignDiT: Multimodal aligned dif- fusion transformer for synchronized speech generation. In ACM Int. Conf. Multimedia, 2025. 6, 7
2025
-
[7]
Out of time: Au- tomated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: Au- tomated lip sync in the wild. InACCV . Int. Worksh., pages 251–263, 2016. 5
2016
-
[8]
V oxceleb2: Deep speaker recognition,
Joon Son Chung, Arsha Nagrani, and Andrew Zisser- man. V oxceleb2: Deep speaker recognition.arXiv preprint:1806.05622, 2018. 5
-
[9]
Learning to dub movies via hierarchical prosody models
Gaoxiang Cong, Liang Li, Yuankai Qi, Zheng-Jun Zha, Qi Wu, Wenyu Wang, Bin Jiang, Ming-Hsuan Yang, and Qingming Huang. Learning to dub movies via hierarchical prosody models. InIEEE Conf. Comput. Vis. Pattern Recog., pages 14687–14697, 2023. 1
2023
-
[10]
FlowDubber: Movie dubbing with llm- based semantic-aware learning and flow matching based voice enhancing
Gaoxiang Cong, Liang Li, Jiadong Pan, Zhedong Zhang, Amin Beheshti, Anton van den Hengel, Yuankai Qi, and Qingming Huang. FlowDubber: Movie dubbing with llm- based semantic-aware learning and flow matching based voice enhancing. InACM Int. Conf. Multimedia, pages 905– 914, 2025. 1
2025
-
[11]
EmoDubber: Towards high quality and emotion con- trollable movie dubbing
Gaoxiang Cong, Jiadong Pan, Liang Li, Yuankai Qi, Yuxin Peng, Anton van den Hengel, Jian Yang, and Qingming Huang. EmoDubber: Towards high quality and emotion con- trollable movie dubbing. InIEEE Conf. Comput. Vis. Pattern Recog., pages 15863–15873, 2025. 6
2025
-
[12]
A study of dropout- induced modality bias on robustness to missing video frames for audio-visual speech recognition
Yusheng Dai, Hang Chen, Jun Du, Ruoyu Wang, Shihao Chen, Haotian Wang, and Chin-Hui Lee. A study of dropout- induced modality bias on robustness to missing video frames for audio-visual speech recognition. InIEEE Conf. Comput. Vis. Pattern Recog., pages 27435–27445, 2024. 3
2024
-
[13]
Visual-aware speech recog- nition for noisy scenarios
Balaji Darur and Karan Singla. Visual-aware speech recog- nition for noisy scenarios. InProc. Conf. Empir. Methods Natural Lang. Process., pages 16709–16717, 2025. 1
2025
-
[14]
High fidelity neural audio compression.Trans
Alexandre D ´efossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression.Trans. Mach. Learn. Res., 2023, 2023. 2, 3
2023
-
[15]
Arcface: Additive angular mar- gin loss for deep face recognition.IEEE Trans
Jiankang Deng, Jia Guo, Jing Yang, Niannan Xue, Irene Kot- sia, and Stefanos Zafeiriou. Arcface: Additive angular mar- gin loss for deep face recognition.IEEE Trans. Pattern Anal. Mach. Intell., 44(10):5962–5979, 2022. 3
2022
-
[16]
MixGAN-TTS: Efficient and stable speech synthesis based on diffusion model.IEEE Access, 11:57674–57682,
Yan Deng, Ning Wu, Chengjun Qiu, Yangyang Luo, and Yan Chen. MixGAN-TTS: Efficient and stable speech synthesis based on diffusion model.IEEE Access, 11:57674–57682,
-
[17]
ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker veri- fication
Brecht Desplanques, Jenthe Thienpondt, and Kris De- muynck. ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker veri- fication. InAnnu. Conf. Int. Speech Commun. Assoc., pages 3830–3834, 2020. 5
2020
-
[18]
Self-evolving embodied ai.arXiv preprint:2602.04411, 2026
Tongtong Feng, Xin Wang, and Wenwu Zhu. Self-evolving embodied ai.arXiv preprint:2602.04411, 2026. 1
-
[19]
Communicating emotion: The role of prosodic features.Psychological bulletin, 97(3):412, 1985
Robert W Frick. Communicating emotion: The role of prosodic features.Psychological bulletin, 97(3):412, 1985. 3
1985
-
[20]
Face2Speech: Towards multi-speaker text-to-speech synthesis using an embedding vector predicted from a face image
Shunsuke Goto, Kotaro Onishi, Yuki Saito, Kentaro Tachibana, and Koichiro Mori. Face2Speech: Towards multi-speaker text-to-speech synthesis using an embedding vector predicted from a face image. InAnnu. Conf. Int. Speech Commun. Assoc., pages 1321–1325, 2020. 1, 2
2020
-
[21]
Weiss, Heiga Zen, Yonghui Wu, Yuxuan Wang, Yuan Cao, Ye Jia, Zhifeng Chen, Jonathan Shen, Patrick Nguyen, and Ruoming Pang
Wei-Ning Hsu, Yu Zhang, Ron J. Weiss, Heiga Zen, Yonghui Wu, Yuxuan Wang, Yuan Cao, Ye Jia, Zhifeng Chen, Jonathan Shen, Patrick Nguyen, and Ruoming Pang. Hierar- chical generative modeling for controllable speech synthesis. InInt. Conf. Learn. Represent., 2019. 2
2019
-
[22]
Faces that speak: Jointly synthesising talking face and speech from text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, et al. Faces that speak: Jointly synthesising talking face and speech from text. InIEEE Conf. Comput. Vis. Pattern Recog., pages 8818–8828, 2024. 1
2024
-
[23]
Minki Kang, Wooseok Han, and Eunho Yang. Face- StyleSpeech: Improved face-to-voice latent mapping for nat- ural zero-shot speech synthesis from a face image.arXiv preprint:2311.05844, 2023. 1
-
[24]
Cam- bridge University Press, 2011
Frank P Kelly.Reversibility and stochastic networks. Cam- bridge University Press, 2011. 3
2011
-
[25]
Let there be sound: Reconstructing high quality speech from silent videos
Ji-Hoon Kim, Jaehun Kim, and Joon Son Chung. Let there be sound: Reconstructing high quality speech from silent videos. InAAAI Conf. Artif. Intell., pages 2759–2767, 2024. 6
2024
-
[26]
From faces to voices: Learning hi- erarchical representations for high-quality video-to-speech
Ji-Hoon Kim, Jeongsoo Choi, Jaehun Kim, Chaeyoung Jung, and Joon Son Chung. From faces to voices: Learning hi- erarchical representations for high-quality video-to-speech. InIEEE Conf. Comput. Vis. Pattern Recog., pages 15874– 15884, 2025. 1, 2, 6, 7
2025
-
[27]
Lip-to-speech synthesis in the wild with multi-task learning
Minsu Kim, Joanna Hong, and Yong Man Ro. Lip-to-speech synthesis in the wild with multi-task learning. InIEEE Conf. Acoust. Speech Signal Process., pages 1–5, 2023. 2, 6
2023
-
[28]
Hier- Speech: Bridging the gap between text and speech by hierar- chical variational inference using self-supervised representa- tions for speech synthesis
Sang-Hoon Lee, Seung-Bin Kim, Ji-Hyun Lee, et al. Hier- Speech: Bridging the gap between text and speech by hierar- chical variational inference using self-supervised representa- tions for speech synthesis. InAdv. Neural Inform. Process. Syst., 2022. 2
2022
-
[29]
NaturalL2S: End-to- end high-quality multispeaker lip-to-speech synthesis with 9 differential digital signal processing.Neural Networks, 194: 108163, 2026
Yifan Liang, Fangkun Liu, Andong Li, Xiaodong Li, Chengyou Lei, and Chengshi Zheng. NaturalL2S: End-to- end high-quality multispeaker lip-to-speech synthesis with 9 differential digital signal processing.Neural Networks, 194: 108163, 2026. 1
2026
-
[30]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInt. Conf. Learn. Represent., 2019. 5
2019
-
[31]
Discrete diffusion modeling by estimating the ratios of the data distri- bution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distri- bution. InInt. Conf. on Mach. Learn., 2024. 2, 3, 4, 5
2024
-
[32]
DPM-Solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Mach
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Mach. Intell. Res., 22 (4):730–751, 2025. 2
2025
-
[33]
EmoBox: Multilingual multi-corpus speech emo- tion recognition toolkit and benchmark
Ziyang Ma, Mingjie Chen, Hezhao Zhang, Zhisheng Zheng, Wenxi Chen, Xiquan Li, Jiaxin Ye, Xie Chen, and Thomas Hain. EmoBox: Multilingual multi-corpus speech emo- tion recognition toolkit and benchmark. InAnnu. Conf. Int. Speech Commun. Assoc., 2024. 5
2024
-
[34]
emotion2vec: Self- supervised pre-training for speech emotion representation
Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, Shiliang Zhang, and Xie Chen. emotion2vec: Self- supervised pre-training for speech emotion representation. In Findings Proc. Annu. Meeting Assoc. Comput. Linguistics, pages 15747–15760, 2024. 5
2024
-
[35]
Jiawei Mao, Rui Xu, Xuesong Yin, Yuanqi Chang, Bin- ling Nie, and Aibin Huang. POSTER V2: A simpler and stronger facial expression recognition network.arXiv preprint:2301.12149, 2023. 3, 8
-
[36]
Concrete score matching: Generalized score matching for discrete data
Chenlin Meng, Kristy Choi, Jiaming Song, and Stefano Er- mon. Concrete score matching: Generalized score matching for discrete data. InAdv. Neural Inform. Process. Syst., 2022. 2
2022
-
[37]
arXiv preprint arXiv:2406.03736 , year=
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing dis- crete diffusion secretly models the conditional distributions of clean data.CoRR, abs/2406.03736, 2024. 3
-
[38]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InInt. Conf. Comput. Vis., pages 4172– 4182, 2023. 8
2023
-
[39]
V oiceCraft: Zero-shot speech editing and text-to-speech in the wild
Puyuan Peng, Po-Yao Huang, Shang-Wen Li, Abdelrah- man Mohamed, and David Harwath. V oiceCraft: Zero-shot speech editing and text-to-speech in the wild. InProc. Annu. Meeting Assoc. Comput. Linguistics, pages 12442–12462,
-
[40]
Powerset multi-class cross entropy loss for neural speaker diarization
Alexis Plaquet and Herv ´e Bredin. Powerset multi-class cross entropy loss for neural speaker diarization. InAnnu. Conf. Int. Speech Commun. Assoc., 2023. 5
2023
-
[41]
Audio-visual automatic speech recogni- tion: An overview.Issues in visual and audio-visual speech processing, 22:23, 2004
Gerasimos Potamianos, Chalapathy Neti, Juergen Luettin, Iain Matthews, et al. Audio-visual automatic speech recogni- tion: An overview.Issues in visual and audio-visual speech processing, 22:23, 2004. 1
2004
-
[42]
K. R. Prajwal, Rudrabha Mukhopadhyay, Vinay P. Nam- boodiri, and C. V . Jawahar. Learning individual speaking styles for accurate lip to speech synthesis. InIEEE Conf. Comput. Vis. Pattern Recog., pages 13793–13802, 2020. 6
2020
-
[43]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInt. Conf. on Mach. Learn., pages 28492–28518, 2023. 1, 5
2023
-
[44]
SpeechBrain: A general-purpose speech toolkit,
Mirco Ravanelli, Titouan Parcollet, Peter Plantinga, Aku Rouhe, et al. SpeechBrain: A general-purpose speech toolkit.arXiv preprint:2106.04624, 2021. 1, 5
-
[45]
Chandan K. A. Reddy, Vishak Gopal, and Ross Cutler. Dns- mos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InIEEE Conf. Acoust. Speech Signal Process., pages 6493–6497, 2021. 5
2021
-
[46]
Utmos: Utokyo-sarulab sys- tem for voicemos challenge 2022.arXiv preprint arXiv:2204.02152,
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Ko- riyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. Ut- mos: Utokyo-sarulab system for voicemos challenge 2022. arXiv preprint:2204.02152, 2022. 5
-
[47]
Learning audio-visual speech representa- tion by masked multimodal cluster prediction
Bowen Shi, Wei-Ning Hsu, Kushal Lakhotia, and Abdelrah- man Mohamed. Learning audio-visual speech representa- tion by masked multimodal cluster prediction. InInt. Conf. Learn. Represent., 2022. 3
2022
-
[48]
Lip reading sentences in the wild
Joon Son Chung, Andrew Senior, Oriol Vinyals, and Andrew Zisserman. Lip reading sentences in the wild. InIEEE Conf. Comput. Vis. Pattern Recog., pages 6447–6456, 2017. 5
2017
-
[49]
Score-based continuous-time discrete diffusion models
Haoran Sun, Lijun Yu, Bo Dai, Dale Schuurmans, and Han- jun Dai. Score-based continuous-time discrete diffusion models. InInt. Conf. Learn. Represent., 2023. 3
2023
-
[50]
V oiceCraft-Dub: Automated video dubbing with neural codec language mod- els
Kim Sung-Bin, Jeongsoo Choi, Puyuan Peng, Joon Son Chung, Tae-Hyun Oh, and David Harwath. V oiceCraft-Dub: Automated video dubbing with neural codec language mod- els. InInt. Conf. Comput. Vis., 2025. 2
2025
-
[51]
V oxLingua107: A dataset for spoken language recognition
J ¨orgen Valk and Tanel Alum¨ae. V oxLingua107: A dataset for spoken language recognition. InProc. IEEE SLT Workshop,
-
[52]
Generalized end-to-end loss for speaker verifica- tion
Li Wan, Quan Wang, Alan Papir, and Ignacio L ´opez- Moreno. Generalized end-to-end loss for speaker verifica- tion. InIEEE Conf. Acoust. Speech Signal Process., pages 4879–4883, 2018. 3
2018
-
[53]
FLDM- VTON: Faithful latent diffusion model for virtual try-on
Chenhui Wang, Tao Chen, Zhihao Chen, Zhizhong Huang, Taoran Jiang, Qi Wang, and Hongming Shan. FLDM- VTON: Faithful latent diffusion model for virtual try-on. In Proc. Int. Joint Conf. Artif. Intell., pages 1362–1370, 2024. 2
2024
-
[54]
Brain-WM: Brain glioblastoma world model.arXiv preprint:2603.07562, 2026
Chenhui Wang, Boyun Zheng, Liuxin Bao, Zhihao Peng, Peter YM Woo, Hongming Shan, and Yixuan Yuan. Brain-WM: Brain glioblastoma world model.arXiv preprint:2603.07562, 2026. 2
-
[55]
Yuxuan Wang, Daisy Stanton, Yu Zhang, R. J. Skerry-Ryan, Eric Battenberg, Joel Shor, Ying Xiao, Ye Jia, Fei Ren, and Rif A. Saurous. Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis. InInt. Conf. on Mach. Learn., pages 5167–5176, 2018. 5
2018
-
[56]
Maskgct: Zero-shot text-to-speech with masked generative codec transformer
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Shunsi Zhang, and Zhizheng Wu. MaskGCT: Zero-shot text-to- speech with masked generative codec transformer.arXiv preprint:2409.00750, 2024. 2, 4, 5
-
[57]
Dreamvideo-2: Zero-shot subject- driven video customization with precise motion control
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Xiang Wang, Hao- nan Qiu, Rui Zhao, Yutong Feng, Feng Liu, Zhizhong Huang, Jiaxin Ye, Yingya Zhang, and Hongming Shan. DreamVideo-2: Zero-shot subject-driven video customiza- tion with precise motion control.arXiv preprint:2410.13830,
-
[58]
CTL-MTNet: A novel capsnet and transfer learning-based mixed task net for single-corpus and cross-corpus speech emotion recogni- tion
Xin-Cheng Wen, Jiaxin Ye, Yan Luo, Yong Xu, Xuan-Ze Wang, Chang-Li Wu, and Kun-Hong Liu. CTL-MTNet: A novel capsnet and transfer learning-based mixed task net for single-corpus and cross-corpus speech emotion recogni- tion. InProc. Int. Joint Conf. Artif. Intell., pages 2305–2311,
-
[59]
DCTTS: Discrete diffusion model with contrastive learning for text- to-speech generation
Zhichao Wu, Qiulin Li, Sixing Liu, and Qun Yang. DCTTS: Discrete diffusion model with contrastive learning for text- to-speech generation. InIEEE Conf. Acoust. Speech Signal Process., pages 11336–11340. IEEE, 2024. 2
2024
-
[60]
Diffsound: Discrete dif- fusion model for text-to-sound generation.IEEE ACM Trans
Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. Diffsound: Discrete dif- fusion model for text-to-sound generation.IEEE ACM Trans. Audio Speech Lang. Process., 31:1720–1733, 2023. 2
2023
-
[61]
Emo- DNA: Emotion decoupling and alignment learning for cross- corpus speech emotion recognition
Jiaxin Ye, Yujie Wei, Xin-Cheng Wen, Chenglong Ma, Zhizhong Huang, Kunhong Liu, and Hongming Shan. Emo- DNA: Emotion decoupling and alignment learning for cross- corpus speech emotion recognition. InACM Int. Conf. Mul- timedia, pages 5956–5965, 2023. 1
2023
-
[62]
Temporal modeling matters: A novel temporal emotional modeling approach for speech emotion recognition
Jiaxin Ye, Xin-Cheng Wen, Yujie Wei, Yong Xu, Kunhong Liu, and Hongming Shan. Temporal modeling matters: A novel temporal emotional modeling approach for speech emotion recognition. InIEEE Conf. Acoust. Speech Signal Process.,, pages 1–5, 2023. 1
2023
-
[63]
Emotional face-to-speech
Jiaxin Ye, Boyuan Cao, and Hongming Shan. Emotional face-to-speech. InInt. Conf. on Mach. Learn., 2025. 1, 5, 6
2025
-
[64]
LipV oicer: Generating speech from silent videos guided by lip reading
Yochai Yemini, Aviv Shamsian, Lior Bracha, Sharon Gan- not, and Ethan Fetaya. LipV oicer: Generating speech from silent videos guided by lip reading. InInt. Conf. Learn. Rep- resent., 2024. 2
2024
-
[65]
A survey on personalized content synthesis with diffusion models.Mach
Xulu Zhang, Xiaoyong Wei, Wentao Hu, Jinlin Wu, Jiaxin Wu, Wengyu Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing Li. A survey on personalized content synthesis with diffusion models.Mach. Intell. Res., 22(5):817–848, 2025. 2
2025
-
[66]
Shengkui Zhao, Zexu Pan, and Bin Ma. Clearervoice-studio: Bridging advanced speech processing research and practical deployment.arXiv preprint:2506.19398, 2025. 5
-
[67]
POSTER: A pyramid cross-fusion transformer network for facial expres- sion recognition
Ce Zheng, Mat ´ıas Mendieta, and Chen Chen. POSTER: A pyramid cross-fusion transformer network for facial expres- sion recognition. InInt. Conf. Comput. Vis. Workshop, pages 3138–3147, 2023. 8
2023
-
[68]
Srcodec: Split-residual vector quantization for neural speech codec
Youqiang Zheng, Weiping Tu, Li Xiao, and Xinmeng Xu. Srcodec: Split-residual vector quantization for neural speech codec. InIEEE Conf. Acoust. Speech Signal Process., pages 451–455, 2024. 2
2024
-
[69]
Unified thinker: A general reasoning modular core for image generation, 2026
Sashuai Zhou, Qiang Zhou, Jijin Hu, Hanqing Yang, Yue Cao, Junpeng Ma, Yinchao Ma, Jun Song, Tiezheng Ge, Cheng Yu, Bo Zheng, and Zhou Zhao. Unified thinker: A general reasoning modular core for image generation, 2026. 2
2026
-
[70]
Spatialreward: Verifi- able spatial reward modeling for fine-grained spatial consis- tency in text-to-image generation, 2026
Sashuai Zhou, Qiang Zhou, Junpeng Ma, Yue Cao, Ruofan Hu, Ziang Zhang, Xiaoda Yang, Zhibin Wang, Jun Song, Cheng Yu, Bo Zheng, and Zhou Zhao. Spatialreward: Verifi- able spatial reward modeling for fine-grained spatial consis- tency in text-to-image generation, 2026. 2 11
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.