Recognition: unknown
MemExplorer: Navigating the Heterogeneous Memory Design Space for Agentic Inference NPUs
Pith reviewed 2026-05-10 07:40 UTC · model grok-4.3
The pith
MemExplorer automatically designs heterogeneous memory systems for NPUs running agentic LLMs, achieving up to 2.3x higher energy efficiency than baselines under fixed power budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemExplorer supplies a unified abstraction for diverse memory technologies across on-chip and off-chip levels and automatically selects an efficient heterogeneous memory system together with NPU design choices to balance throughput and power between prefilling and decoding devices. Under the same power budget for agentic workloads, it reaches up to 2.3 times higher energy efficiency than the baseline NPU and 3.23 times higher than H100 in the prefill-only setting. Under equivalent performance targets in the decode setting, it delivers up to 1.93 times and 2.72 times higher power efficiency over the baseline NPU and H100, respectively.
What carries the argument
MemExplorer, the memory system synthesizer that applies a unified abstraction to model memory technologies at different hierarchy levels and jointly optimizes those memories with NPU parameters such as matrix engine size for phase-specific balance.
Load-bearing premise
The internal models of workload phases, memory technology parameters, and power-throughput trade-offs inside MemExplorer must match the behavior of real hardware and actual agentic LLM execution on heterogeneous NPU systems.
What would settle it
Build a physical heterogeneous NPU prototype using the exact memory and engine sizes recommended by MemExplorer, measure its energy and power efficiency on the same agentic workloads, and compare those measurements directly to the tool's predictions.
Figures




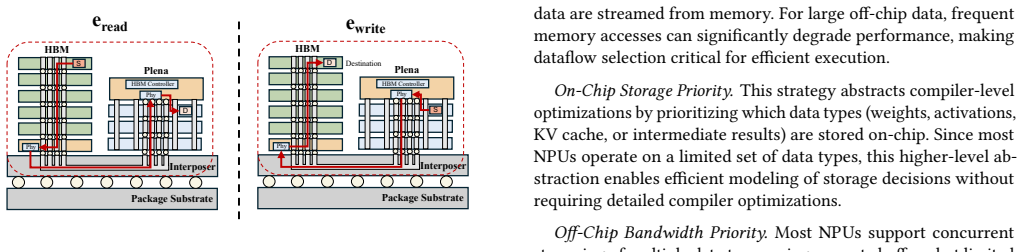

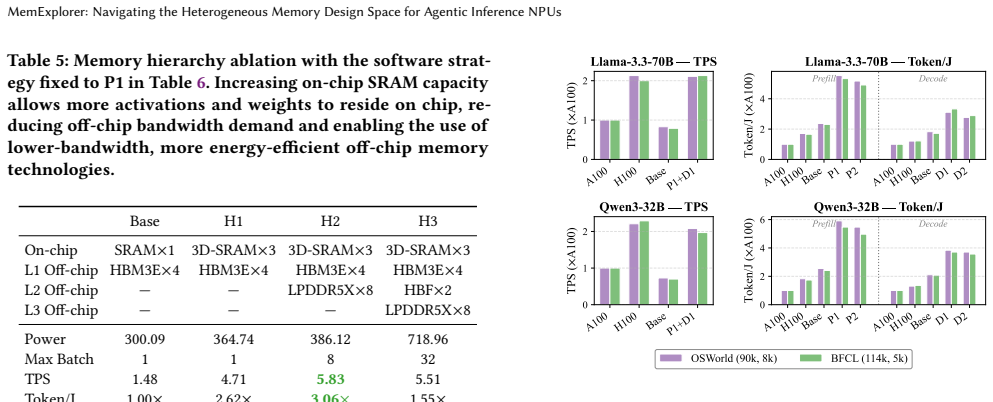


read the original abstract
Emerging agentic LLM workloads are driving rapidly growing demand on both memory capacity and bandwidth, with different phases of inference (e.g., prefill and decode) imposing distinct requirements. Industry is responding by composing heterogeneous accelerators into single interconnected systems, as exemplified by NVIDIA's Vera Rubin platform, where each device brings its own memory architecture. This heterogeneity is further compounded by a widening landscape of available memory technologies: high-density on-chip SRAM, HBM, LPDDR, GDDR, and emerging options such as high-bandwidth flash (HBF), each offering different capacity, bandwidth, and power trade-offs. Identifying the right memory architecture for next-generation inference accelerators requires navigating a vast and rapidly evolving design space, in which the interplay between workload characteristics, NPU design dimensions, and memory system design remains largely underexplored. To address this challenge, we present MemExplorer, a new memory system synthesizer for heterogeneous NPU systems. MemExplorer provides a unified abstraction for modeling diverse memory technologies across different hierarchy levels (e.g., on-chip and off-chip) and automatically determines an efficient heterogeneous memory system together with NPU design choices (e.g., matrix engine size) to balance throughput and power between prefilling and decoding devices in a multi-device NPU system. Experimental results show that, under the same power budget for agentic workloads, MemExplorer achieves up to 2.3x higher energy efficiency than the baseline NPU and 3.23x higher than H100 in the prefill-only setting. Under equivalent performance targets in the decode setting, it further delivers up to 1.93x and 2.72x higher power efficiency over the baseline NPU and H100, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemExplorer, a memory system synthesizer for heterogeneous NPU systems targeting agentic LLM workloads. It provides a unified abstraction for modeling diverse memory technologies (SRAM, HBM, LPDDR, GDDR, HBF) across on-chip and off-chip hierarchies, and automatically optimizes memory configurations together with NPU parameters such as matrix engine size to balance throughput and power between prefill and decode phases in multi-device setups. The central claims are quantitative efficiency improvements: up to 2.3x higher energy efficiency than a baseline NPU and 3.23x higher than H100 under the same power budget in the prefill-only setting, and up to 1.93x and 2.72x higher power efficiency in the decode setting under equivalent performance targets.
Significance. If the internal power, throughput, and phase-specific workload models are shown to be accurate, MemExplorer would offer a valuable engineering tool for navigating the expanding design space of heterogeneous memories in next-generation inference NPUs. This addresses an underexplored interplay between agentic workload phases and memory technology trade-offs, with potential to inform platforms like NVIDIA Vera Rubin and improve energy efficiency in large-scale LLM inference.
major comments (1)
- Abstract: The headline efficiency claims (2.3x energy efficiency vs. baseline NPU, 3.23x vs. H100 in prefill; 1.93x/2.72x power efficiency in decode) are generated by the synthesizer using its internal models of capacity/bandwidth/power trade-offs and agentic phase behaviors, yet the manuscript supplies no methodology, validation against real hardware or cycle-accurate simulators, error bars, or description of how overfitting to specific traces is avoided. This is load-bearing because the numerical results cannot be assessed for support without evidence that the models do not systematically mis-estimate power or bandwidth utilization.
minor comments (1)
- Abstract: The description of the baseline NPU and the exact power budgets or performance targets used for the comparisons is not provided, which would aid in interpreting the magnitude of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on the validation and transparency of our modeling approach below. We have revised the manuscript to provide additional details on the methodology while acknowledging inherent limitations of design-space exploration for future systems.
read point-by-point responses
-
Referee: [—] Abstract: The headline efficiency claims (2.3x energy efficiency vs. baseline NPU, 3.23x vs. H100 in prefill; 1.93x/2.72x power efficiency in decode) are generated by the synthesizer using its internal models of capacity/bandwidth/power trade-offs and agentic phase behaviors, yet the manuscript supplies no methodology, validation against real hardware or cycle-accurate simulators, error bars, or description of how overfitting to specific traces is avoided. This is load-bearing because the numerical results cannot be assessed for support without evidence that the models do not systematically mis-estimate power or bandwidth utilization.
Authors: We agree that the abstract's headline claims require stronger supporting context on the underlying models to allow proper assessment. The full manuscript (Section 3) presents the unified abstraction and analytical models for capacity, bandwidth, and power, parameterized directly from published vendor specifications and technology datasheets for SRAM, HBM, LPDDR, GDDR, and HBF. Agentic phase behaviors are captured via trace-driven analysis using aggregated statistics from representative workloads rather than per-trace fitting. In response to this comment, we have expanded the methodology description with explicit equations for the power and bandwidth estimators, added a dedicated subsection on model assumptions and limitations, and included a sensitivity study showing how results vary with key parameters. We have also incorporated literature-based comparisons to cycle-accurate simulator outputs for baseline homogeneous configurations. However, the results are deterministic outputs of the synthesizer and thus do not include statistical error bars; the models are physics-based analytical formulations, not learned models, so overfitting to specific traces is not applicable. Direct validation against real hardware or full cycle-accurate simulation for every heterogeneous configuration is not feasible, as many explored designs involve hypothetical combinations and emerging technologies without physical implementations. revision: partial
- Comprehensive validation of all reported efficiency numbers against physical hardware or cycle-accurate simulators for the full range of heterogeneous configurations, given the exploratory focus on future and emerging memory technologies.
Circularity Check
No circularity: MemExplorer claims rest on independent modeling abstractions and reported experimental outcomes
full rationale
The paper introduces MemExplorer as an engineering synthesizer that applies unified abstractions to model heterogeneous memory technologies (SRAM, HBM, LPDDR, etc.) and jointly optimizes NPU parameters such as matrix engine size for prefill/decode phases. The reported gains (2.3x energy efficiency vs. baseline NPU, 3.23x vs. H100 in prefill; 1.93x/2.72x power efficiency in decode) are presented as outputs of this exploration under fixed power or performance targets. No equations, parameter-fitting steps, or self-citations appear in the abstract or described derivation chain that would make these results tautological by construction; the tool's internal models are treated as external inputs to the search rather than being redefined from the same outputs. The work is therefore self-contained as a design-space navigator whose validity hinges on model accuracy rather than on any internal reduction to its own fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang
-
[3]
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents. arXiv:2504.00906 [cs.AI] https://arxiv.org/abs/2504.00906 11
-
[4]
Quarot: Outlier-free 4-bit inference in rotated llms,
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. 2024. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs. arXiv:2404.00456 [cs.LG] https://arxiv.org/abs/2404.00456
-
[5]
ASML. 2024. ASML TWINSCAN NXE EUV Lithography Systems. https: //www.asml.com/products/euv-lithography-systems/twinscan-nxe3400b Maximum exposure field size of 26 mm×33 mm
2024
-
[6]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2025. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. arXiv:2412.15204 [cs.CL] https://arxiv.org/abs/2412.15204
-
[7]
Hyungjoo Chae, Namyoung Kim, Kai Tzu iunn Ong, Minju Gwak, Gwanwoo Song, Jihoon Kim, Sunghwan Kim, Dongha Lee, and Jinyoung Yeo. 2025. Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation. arXiv:2410.13232 [cs.CL] https://arxiv.org/abs/2410.13232
-
[8]
Victor Chen, Bassem Abdel-Dayem, Changhua Wan, and Feng Ling. 2022. Overcoming Design Challenges for High Bandwidth Memory Interface with CoWoS. In2022 IEEE International Symposium on Electromagnetic Compati- bility & Signal/Power Integrity (EMCSI). IEEE, Piscataway, NJ, USA, 455–458. https://doi.org/10.1109/EMCSI39492.2022.10050234
- [9]
-
[10]
L. T. Clark, V. Vashishtha, L. Shifren, A. Gujja, S. Sinha, B. Cline, C. Ramamurthy, and G. Yeric. 2016. ASAP: A 7-nm finFET predictive process design kit.Microelec- tronics Journal53 (July 2016), 105–115. https://doi.org/10.1016/j.mejo.2016.04.006
-
[11]
Bita Darvish Rouhani, Ritchie Zhao, Venmugil Elango, Rasoul Shafipour, Mathew Hall, Maral Mesmakhosroshahi, Ankit More, Levi Melnick, Maximilian Golub, Girish Varatkar, Lai Shao, Gaurav Kolhe, Dimitry Melts, Jasmine Klar, Renee L’Heureux, Matt Perry, Doug Burger, Eric Chung, Zhaoxia (Summer) Deng, Sam Naghshineh, Jongsoo Park, and Maxim Naumov. 2023. With...
-
[12]
Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. 2020. Differentiable expected hypervolume improvement for parallel multi-objective Bayesian opti- mization.Advances in neural information processing systems (NeurIPS)33 (2020), 9851–9864
2020
-
[13]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. 2002. A fast and elitist multiobjective genetic algorithm: NSGA-II.IEEE transactions on evolutionary computation (TEC)6, 2 (2002), 182–197
2002
-
[14]
2026.High Bandwidth Flash (HBF) Overview
Emergent Mind. 2026.High Bandwidth Flash (HBF) Overview. Emergent Mind. https://www.emergentmind.com/topics/high-bandwidth-flash-hbf Updated Jan. 12, 2026. Accessed: 2026-03-16
2026
-
[15]
Michael TM Emmerich, Kyriakos C Giannakoglou, and Boris Naujoks. 2006. Single-and multiobjective evolutionary optimization assisted by Gaussian ran- dom field metamodels.IEEE Transactions on Evolutionary Computation (TEC)10, 4 (2006), 421–439
2006
-
[16]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2023. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. arXiv:2210.17323 [cs.LG] https://arxiv.org/abs/2210.17323
work page internal anchor Pith review arXiv 2023
-
[17]
Team GLM, :, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Jingyu Sun, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, ...
work page internal anchor Pith review arXiv 2024
-
[18]
Minho Ha, Euiseok Kim, and Hoshik Kim. 2026. H3: Hybrid Architecture Using High Bandwidth Memory and High Bandwidth Flash for Cost-Efficient LLM Inference.IEEE Computer Architecture Letters25, 1 (2026), 49–52. https://doi.or g/10.1109/LCA.2026.3660969
-
[19]
Energy Efficient Design
Dion Harris. 2023. NVIDIA Grace and Grace Hopper Update. Presentation at the HPC User Forum, Argonne National Laboratory. https://www.hpcuserf orum.com/wp-content/uploads/2023/09/Dion-Harris-Update-on-NVIDIA- Grace_Grace-Hopper.2.pdf Slide 15: "Energy Efficient Design" highlights LPDDR5X at 5 pJ/bit vs. DDR5 at 35 pJ/bit
2023
-
[20]
JEDEC Solid State Technology Association. 2023. GDDR6 SGRAM Standard. https://www.jedec.org/standards-documents/docs/jesd250 JESD250
2023
-
[21]
Hongshin Jun, Jinhee Cho, Kangseol Lee, Ho-Young Son, Kwiwook Kim, Hanho Jin, and Keith Kim. 2017. HBM (High Bandwidth Memory) DRAM Technology and Architecture. In2017 IEEE International Memory Workshop (IMW). IEEE, Piscataway, NJ, USA, 1–4. https://doi.org/10.1109/IMW.2017.7939084
-
[22]
Joungho Kim. 2026. HBF Technology, Workload Analysis and Roadmap. Pre- sentation slides, TeraByte Interconnection and Package Laboratory (TERALAB), KAIST. https://www.dropbox.com/scl/fo/pv1wqpyvqjz7qdra1z94e/AFeIVtavoj2 HDWxbLzzYN7o/HBF_Workload_and_Roadmap_Joungho_Kim.pdf School of Electrical Engineering, KAIST. Accessed: 2026-03-14
2026
-
[23]
Scott Knowlton. 2026. LPDDR6 vs. LPDDR5 and LPDDR5X: What’s the Differ- ence? Synopsys Blog. https://www.synopsys.com/blogs/chip-design/lpddr6-vs- lpddr5x-lpddr5-differences.html Accessed: 2026-03-14
2026
-
[24]
Jeong-Jun Lee and Peng Li. 2020. Reconfigurable Dataflow Optimization for Spatiotemporal Spiking Neural Computation on Systolic Array Accelerators. In2020 IEEE 38th International Conference on Computer Design (ICCD). IEEE, Piscataway, NJ, USA, 57–64. https://doi.org/10.1109/ICCD50377.2020.00027
- [25]
-
[26]
Nisa Bostancı, Ataberk Olgun, A
Haocong Luo, Yahya Can Tuğrul, F. Nisa Bostancı, Ataberk Olgun, A. Giray Yağlıkçı, and Onur Mutlu. 2024. Ramulator 2.0: A Modern, Modular, and Ex- tensible DRAM Simulator.IEEE Comput. Archit. Lett.23, 1 (Jan. 2024), 112–116. https://doi.org/10.1109/LCA.2023.3333759
-
[27]
Xiaoyu Ma and David Patterson. 2026. Challenges and Research Directions for Large Language Model Inference Hardware. https://doi.org/10.48550/arXiv.260 1.05047 arXiv:2601.05047 [cs.AR]
-
[28]
AI Meta. 2024. Introducing meta llama 3: The most capable openly available llm to date. https://ai.meta.com/blog/meta-llama-3/. Meta AI blog post, Accessed: 2026-04-10
2024
-
[29]
Micron Technology, Inc. 2019. Micron GDDR6 Memory Product Flyer. https: //www.mouser.co.uk/pdfDocs/gddr6_product_flyer.pdf. Technical product flyer, accessed: 2026-03-14
2019
-
[30]
Micron Technology, Inc. 2025. LPDDR5X DRAM Components. https://www.mi cron.com/products/memory/dram-components/lpddr5x/. Micron product page, accessed: 2026-03-14
2025
-
[31]
2025.Next-Generation GDDR7 Memory Technology
Seunghyun Moon. 2025.Next-Generation GDDR7 Memory Technology. Technical Report. JEDEC. https://www.jedec.org/sites/default/files/Seunghyun%20Moon_ 03_29_25_Final.pdf JEDEC Presentation
2025
- [32]
-
[33]
arXiv preprint arXiv:2603.08721 , year=
Jiayi Nie, Haoran Wu, Yao Lai, Zeyu Cao, Cheng Zhang, Binglei Lou, Erwei Wang, Jianyi Cheng, Timothy M. Jones, Robert Mullins, Rika Antonova, and Yiren Zhao. 2026. KernelCraft: Benchmarking for Agentic Close-to-Metal Kernel Generation on Emerging Hardware. arXiv:2603.08721 [cs.AR] https://arxiv.org/ abs/2603.08721
-
[34]
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2025. Large Language Diffusion Models. arXiv:2502.09992 [cs.CL] https://arxiv.org/abs/2502.09992
work page internal anchor Pith review arXiv 2025
-
[35]
NVIDIA Corporation. 2018. NVIDIA Tesla V100 GPU Architecture Datasheet. https://images.nvidia.com/content/technologies/volta/pdf /volta-v100- datasheet-update-us-1165301-r5.pdf. Version R5
2018
-
[36]
NVIDIA Corporation. 2026. NVIDIA Vera Rubin Platform Opens the Next Frontier of Agentic AI. https://nvidianews.nvidia.com/news/nvidia-vera-rubin- platform. Press release, Accessed: 2026-03-22
2026
-
[37]
Marcelo Orenes-Vera, Esin Tureci, Margaret Martonosi, and David Wentzlaff
-
[38]
arXiv:2312.10244 [cs.AR] https://arxiv.org/abs/2312.10244
Muchisim: A Simulation Framework for Design Exploration of Multi-Chip Manycore Systems. arXiv:2312.10244 [cs.AR] https://arxiv.org/abs/2312.10244
-
[39]
Introducing gpt-5.4.https://openai.com/index/introducing-gpt-5-4/, 2026a
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christo- pher Ré, and Azalia Mirhoseini. 2025. KernelBench: Can LLMs Write Efficient GPU Kernels? arXiv:2502.10517 [cs.LG] https://arxiv.org/abs/2502.10517
-
[40]
Yoshihiko Ozaki, Yuki Tanigaki, Shuhei Watanabe, and Masaki Onishi. 2020. Multiobjective tree-structured parzen estimator for computationally expensive optimization problems. InProceedings of the 2020 genetic and evolutionary com- putation conference. Association for Computing Machinery, New York, NY, USA, 533–541
2020
-
[41]
Neel Patel, Amin Mamandipoor, Derrick Quinn, and Mohammad Alian. 2023. XFM: Accelerated Software-Defined Far Memory. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture(Toronto, ON, Canada)(MICRO ’23). Association for Computing Machinery, New York, NY, USA, 769–783. https://doi.org/10.1145/3613424.3623776
- [42]
-
[43]
Gonzalez
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. The Berkeley Function Calling Leader- board (BFCL): From Tool Use to Agentic Evaluation of Large Language Models. Proceedings of the Forty-second International Conference on Machine Learning via OpenReview. https://openreview.net/forum?...
2025
-
[44]
PatSnap Eureka. 2025. The HBM Wars: SK Hynix’s Dominance, Samsung’s Roadmap, and the Looming Threat of Cyclicality. https://eureka.patsnap.com /insight/the-hbm-wars-sk-hynixs-dominance-samsungs-roadmap-and-the- looming-threat-of-cyclicality. Accessed: 2026-03-16
2025
- [45]
-
[46]
Qwen Team. 2025. Qwen2.5-1M Technical Report. arXiv:2501.15383 [cs.CL] https://arxiv.org/abs/2501.15383
work page internal anchor Pith review arXiv 2025
-
[47]
Qwen Team. 2026. Qwen3.5: Towards Native Multimodal Agents. https: //qwen.ai/blog?id=qwen3.5
2026
-
[48]
Matthias Seeger. 2004. Gaussian processes for machine learning.International journal of neural systems14, 02 (2004), 69–106
2004
-
[49]
Prado, Kirill Bykov, and Norbert Wehn
Lukas Steiner, Matthias Jung, Felipe S. Prado, Kirill Bykov, and Norbert Wehn
-
[50]
DRAMSys4.0: An Open-Source Simulation Framework for In-depth DRAM Analyses.Int. J. Parallel Program.50, 2 (April 2022), 217–242. https://doi.org/10 .1007/s10766-022-00727-4
2022
-
[51]
TechPowerUp. 2023. Samsung GDDR7 Memory Operates at Lower Voltage, Built on Same Node as 24 Gbps GDDR6. https://www.techpowerup.com/311457/sam sung-gddr7-memory-operates-at-lower-voltage-built-on-same-node-as-24- gbps-g6. Accessed: 2026-03-16
2023
-
[52]
TechPowerUp. 2025. NVIDIA B200 GPU Specifications. https://www.techpowe rup.com/gpu-specs/b200.c4210. Accessed: 2026-03-22
2025
-
[53]
James Wang. 2026. AWS and Cerebras Collaboration Sets a New Standard for AI Inference Speed and Performance in the Cloud. https://www.cerebras.ai/blog/c erebras-is-coming-to-aws. Accessed: 2026-04-07
2026
-
[54]
Haoran Wu, Can Xiao, Jiayi Nie, Xuan Guo, Binglei Lou, Jeffrey T. H. Wong, Zhiwen Mo, Cheng Zhang, Przemyslaw Forys, Wayne Luk, Hongxiang Fan, Jianyi Cheng, Timothy M. Jones, Rika Antonova, Robert Mullins, and Aaron Zhao. 2025. Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference. arXiv:2509.09505 [cs.AR] https://arxiv....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
John Wuu, Rahul Agarwal, Michael Ciraula, Carl Dietz, Brett Johnson, Dave Johnson, Russell Schreiber, Raja Swaminathan, Will Walker, and Samuel Naffziger
-
[56]
In2022 IEEE International Solid-State Circuits Conference (ISSCC), Vol
3D V-Cache: the Implementation of a Hybrid-Bonded 64MB Stacked Cache for a 7nm x86-64 CPU. In2022 IEEE International Solid-State Circuits Conference (ISSCC), Vol. 65. IEEE, Piscataway, NJ, USA, 428–429. https://doi.org/10.1109/IS SCC42614.2022.9731565
work page doi:10.1109/is 2022
-
[57]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu
-
[58]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. arXiv:2404.07972 [cs.AI] https://arxiv.org/abs/24 04.07972
work page internal anchor Pith review arXiv
-
[59]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
S. Yu. 2022.Semiconductor Memory Devices and Circuits. CRC Press, Boca Raton, FL, USA. https://books.google.co.uk/books?id=FPBjEAAAQBAJ
2022
-
[61]
Shimeng Yu and Tae-Hyeon Kim. 2024. Semiconductor Memory Technologies: State-of-the-Art and Future Trends.Computer57, 1 (2024), 150–154. https: //doi.org/10.1109/MC.2023.3332791
-
[62]
Zhongshen Zeng, Pengguang Chen, Shu Liu, Haiyun Jiang, and Jiaya Jia. 2025. MR-GSM8K: A Meta-Reasoning Benchmark for Large Language Model Evalua- tion. The Thirteenth International Conference on Learning Representations via OpenReview. https://openreview.net/forum?id=br4H61LOoI
2025
- [63]
- [64]
-
[65]
Jingchen Zhu, Chenhao Xue, Yiqi Chen, Zhao Wang, Chen Zhang, Yu Shen, Yifan Chen, Zekang Cheng, Yu Jiang, Tianqi Wang, Yibo Lin, Wei Hu, Bin Cui, Runsheng Wang, Yun Liang, and Guangyu Sun. 2024. Theseus: Exploring Efficient Wafer-Scale Chip Design for Large Language Models. arXiv:2407.02079 [cs.AR] https://arxiv.org/abs/2407.02079
-
[66]
Eckart Zitzler, Lothar Thiele, Marco Laumanns, Carlos M Fonseca, and Vi- viane Grunert Da Fonseca. 2003. Performance assessment of multiobjective optimizers: An analysis and review.IEEE Transactions on evolutionary computa- tion (TEC)7, 2 (2003), 117–132. 13
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.