Recognition: unknown
AstroVLM: Expert Multi-agent Collaborative Reasoning for Astronomical Imaging Quality Diagnosis
Pith reviewed 2026-05-10 07:32 UTC · model grok-4.3
The pith
A multi-agent system of vision-language models diagnoses astronomical image quality by coordinating agents across interdependent subtasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
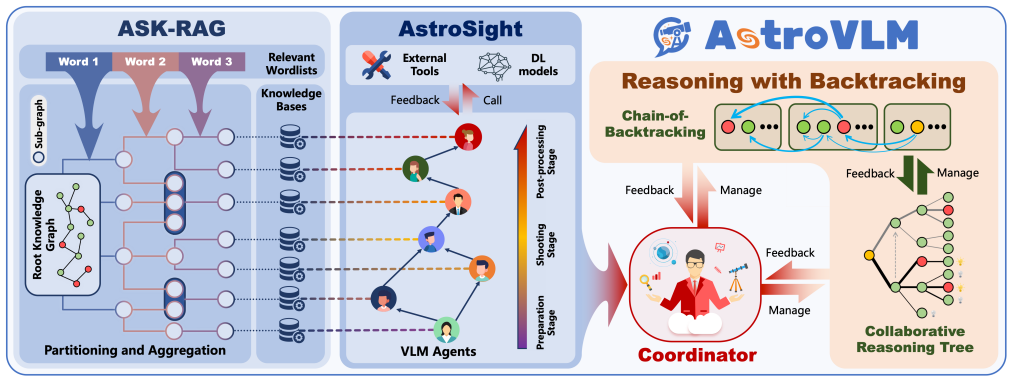
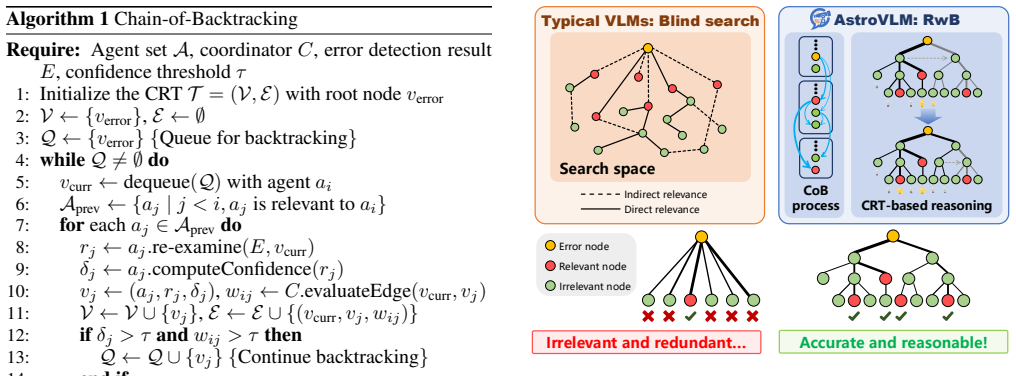
AstroVLM is a collaborative multi-agent system for diagnosing the quality of astronomical images. By assigning expert agents to different subtasks and enabling them to reason jointly, the system addresses the complex underlying correlations among steps in the imaging process. Experiments on real-world data show that AstroVLM outperforms all tested baselines.
What carries the argument
AstroVLM, the expert multi-agent collaborative reasoning system that distributes subtasks across specialized agents and routes their shared conclusions to localize quality issues.
If this is right
- Single vision-language models are insufficient for tasks whose subtasks have strong mutual influences.
- Multi-agent collaboration improves performance when the underlying processes are interdependent.
- The same agent-coordination pattern can serve as a template for language models applied to other complicated multi-process tasks.
Where Pith is reading between the lines
- Similar agent teams could be tested on other imaging domains that also involve sequential steps with feedback between them.
- Adding more agents or explicit knowledge modules for rare defect types might further raise accuracy on edge cases.
- The framework suggests a route to automated checks that scale to the volume of data produced by modern observatories.
Load-bearing premise
Expert multi-agent collaborative reasoning can effectively capture and resolve the complex underlying correlations among subtasks in the astronomical imaging process.
What would settle it
Running AstroVLM on a held-out collection of astronomical images and finding that its accuracy in quality diagnosis and error localization does not exceed that of the strongest single vision-language model baseline.
Figures






read the original abstract
Vision Language Models (VLMs) have been applied to several specific domains and have shown strong problem-solving capabilities. However, astronomical imaging, a quite complex problem involving multidisciplinary knowledge and several subtasks, has not been adequately studied. Due to the complexity of the astronomical imaging process, both world-class astronomical organizations, such as NASA, and expert enthusiasts devote a great deal of time and effort. This is because the processes in astronomical imaging have complex underlying correlations that significantly influence one another, making the quality diagnosis and error localization of astronomical images challenging. To address this problem, we propose AstroVLM, a collaborative multi-agent system for diagnosing the quality of astronomical images. Experiment results show that AstroVLM outperforms all baselines on real-world astronomical imaging quality diagnosis tasks, providing a reference for language models to handle complicated multi-process tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AstroVLM, a collaborative multi-agent system based on Vision Language Models (VLMs) for diagnosing the quality of astronomical images. It models complex underlying correlations among multiple subtasks in the astronomical imaging process and claims that experimental results demonstrate outperformance over all baselines on real-world tasks, serving as a reference for language models handling complicated multi-process tasks.
Significance. If the experimental claims are substantiated with rigorous, reproducible validation, the work could offer a practical reference for deploying multi-agent VLM systems on interdependent scientific workflows, with potential utility for astronomical organizations in streamlining image quality assessment.
major comments (2)
- [Abstract] Abstract: The central claim that 'Experiment results show that AstroVLM outperforms all baselines on real-world astronomical imaging quality diagnosis tasks' is asserted without any reported metrics, baseline descriptions, dataset size, evaluation protocol, or error analysis. This absence is load-bearing for the paper's primary contribution.
- [Methods/Experiments (as described)] The manuscript provides no details on the multi-agent architecture, including how expert collaboration is implemented to capture inter-subtask correlations, the specific VLMs or prompting strategies employed, or any ablation studies isolating the contribution of the collaborative reasoning component.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving the clarity and rigor of our manuscript. We address each major comment below and will revise the paper accordingly to better substantiate our claims and provide necessary methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experiment results show that AstroVLM outperforms all baselines on real-world astronomical imaging quality diagnosis tasks' is asserted without any reported metrics, baseline descriptions, dataset size, evaluation protocol, or error analysis. This absence is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract does not currently include the supporting details needed to substantiate the performance claim. In the revised manuscript, we will expand the abstract to report specific quantitative metrics (e.g., accuracy, precision, recall), describe the baselines, specify the real-world dataset size, outline the evaluation protocol, and include a brief summary of error analysis. This will make the central contribution self-contained and verifiable from the abstract. revision: yes
-
Referee: [Methods/Experiments (as described)] The manuscript provides no details on the multi-agent architecture, including how expert collaboration is implemented to capture inter-subtask correlations, the specific VLMs or prompting strategies employed, or any ablation studies isolating the contribution of the collaborative reasoning component.
Authors: We acknowledge that the current manuscript version lacks sufficient detail on these elements. We will revise the Methods and Experiments sections to provide a full description of the multi-agent architecture, explain the specific mechanisms by which expert collaboration models inter-subtask correlations in the astronomical imaging process, name the VLMs used along with the prompting strategies, and add ablation studies that isolate the contribution of the collaborative reasoning component. These changes will improve reproducibility and allow readers to assess the role of multi-agent collaboration. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces AstroVLM as an empirical multi-agent VLM system for astronomical image quality diagnosis and validates it via experimental comparisons to baselines on real-world tasks. No mathematical derivation chain, equations, fitted parameters, or first-principles results are present. Claims do not reduce to self-definitions, renamed inputs, or load-bearing self-citations; the central outperformance result is externally falsifiable through the reported experiments and does not rely on any internal construction that equates outputs to inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pro- cessing color in astronomical imagery.arXiv preprint arXiv:1308.5237,
Kimberly K Arcand, Megan Watzke, Travis Rector, Zoltan G Levay, Joseph DePasquale, and Olivia Smarr. Pro- cessing color in astronomical imagery.arXiv preprint arXiv:1308.5237,
-
[2]
An empirical study on generalizations of the relu ac- tivation function
Chaity Banerjee, Tathagata Mukherjee, and Eduardo Pasil- iao Jr. An empirical study on generalizations of the relu ac- tivation function. InProceedings of the 2019 ACM south- east conference, pages 164–167,
2019
-
[3]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Probing the course of cosmic expansion with a combination of obser- vational data.Journal of Cosmology and Astroparticle Physics, 2010(11):031,
Zhengxiang Li, Puxun Wu, and Hongwei Yu. Probing the course of cosmic expansion with a combination of obser- vational data.Journal of Cosmology and Astroparticle Physics, 2010(11):031,
2010
-
[5]
Encouraging divergent thinking in large language mod- els through multi-agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language mod- els through multi-agent debate. InProceedings of the 2024 conference on empirical methods in natural language pro- cessing, pages 17889–17904,
2024
-
[6]
Siril: An advanced tool for astronomical image processing.arXiv preprint arXiv:2408.03346,
Cyril Richard, Vincent Hourdin, C ´ecile Melis, and Adrian Knagg-Baugh. Siril: An advanced tool for astronomical image processing.arXiv preprint arXiv:2408.03346,
-
[7]
Rethinking the bounds of llm reasoning: Are multi-agent discussions the key?
Qineng Wang, Zihao Wang, Ying Su, Hanghang Tong, and Yangqiu Song. Rethinking the bounds of llm reason- ing: Are multi-agent discussions the key?arXiv preprint arXiv:2402.18272,
-
[8]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal under- standing.arXiv preprint arXiv:2412.10302,
work page internal anchor Pith review arXiv
-
[9]
Haoyuan Wu, Haisheng Zheng, Zhuolun He, and Bei Yu. Divergent thoughts toward one goal: Llm-based multi- agent collaboration system for electronic design automa- tion.arXiv preprint arXiv:2502.10857,
-
[10]
Survey of astro- nomical image processing methods
Hai Jing Zhu, Bo Chong Han, and Bo Qiu. Survey of astro- nomical image processing methods. InImage and Graph- ics: 8th International Conference, ICIG 2015, Tianjin, China, August 13–16, 2015, Proceedings, Part III, pages 420–429. Springer,
2015
-
[11]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.