Recognition: unknown
Cut Your Losses! Learning to Prune Paths Early for Efficient Parallel Reasoning
Pith reviewed 2026-05-10 08:48 UTC · model grok-4.3
The pith
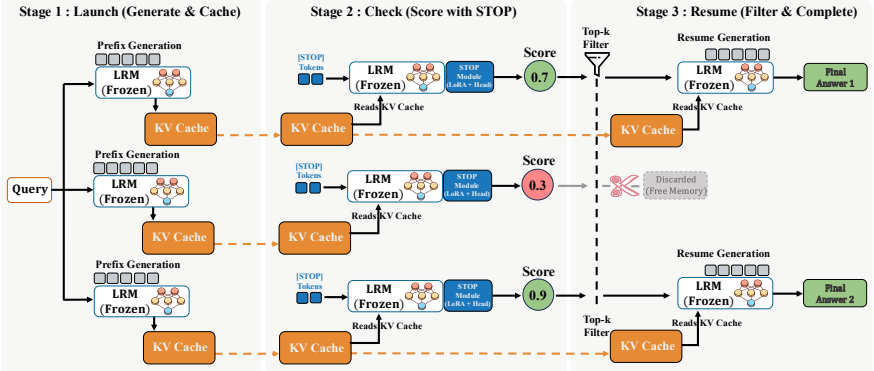
STOP is a new learnable internal path-pruning technique that improves efficiency and accuracy of parallel reasoning in LRMs under fixed compute budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
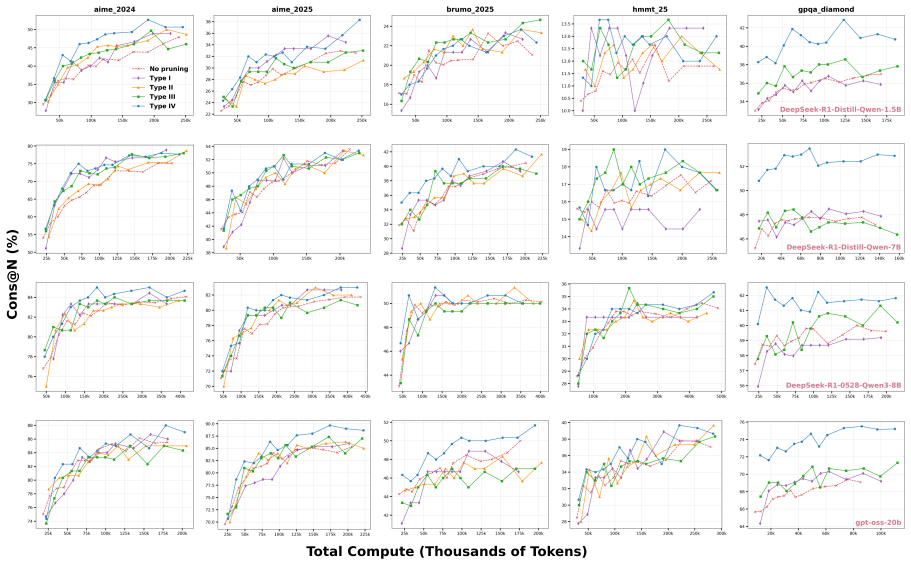
STOP achieves superior effectiveness and efficiency compared to existing baselines, for instance boosting GPT-OSS-20B accuracy on AIME25 from 84% to nearly 90% under fixed compute budgets.
Load-bearing premise
That the proposed taxonomy is exhaustive and that learnable internal pruning signals can be trained reliably without introducing new failure modes or overfitting to the evaluation tasks.
Figures






read the original abstract
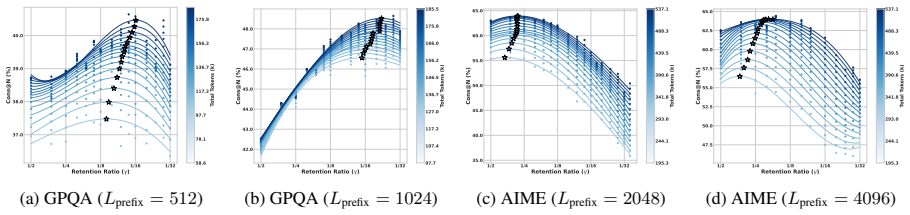
Parallel reasoning enhances Large Reasoning Models (LRMs) but incurs prohibitive costs due to futile paths caused by early errors. To mitigate this, path pruning at the prefix level is essential, yet existing research remains fragmented without a standardized framework. In this work, we propose the first systematic taxonomy of path pruning, categorizing methods by their signal source (internal vs. external) and learnability (learnable vs. non-learnable). This classification reveals the unexplored potential of learnable internal methods, motivating our proposal of STOP (Super TOken for Pruning). Extensive evaluations across LRMs ranging from 1.5B to 20B parameters demonstrate that STOP achieves superior effectiveness and efficiency compared to existing baselines. Furthermore, we rigorously validate the scalability of STOP under varying compute budgets - for instance, boosting GPT-OSS-20B accuracy on AIME25 from 84% to nearly 90% under fixed compute budgets. Finally, we distill our findings into formalized empirical guidelines to facilitate optimal real-world deployment. Code, data and models are available at https://bijiaxihh.github.io/STOP
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a systematic taxonomy for path pruning in parallel reasoning with large reasoning models (LRMs), classifying methods by signal source (internal vs. external) and learnability (learnable vs. non-learnable). It proposes STOP, a learnable internal pruning method that trains a 'super token' predictor to discard futile reasoning paths early. Across LRMs from 1.5B to 20B parameters, STOP is shown to improve accuracy and efficiency over baselines under fixed compute budgets, with a reported lift from 84% to nearly 90% on AIME25 for GPT-OSS-20B; the work also distills empirical guidelines and releases code, data, and models.
Significance. If the central results hold under broader conditions, STOP could meaningfully advance efficient parallel reasoning by enabling more paths within a fixed token budget without external verifiers. The taxonomy provides a useful organizing framework, and the open release of code and models supports reproducibility and follow-up work.
major comments (2)
- [§5.2] §5.2 (Experiments on AIME25 and related benchmarks): The reported accuracy gains (e.g., 84% to ~90% for the 20B model) rely on a learned pruning classifier trained on the same narrow distribution of math problems used for evaluation. No cross-domain (e.g., coding or science) or cross-model transfer results are presented, leaving the claim that the internal signal reliably discards only futile prefixes vulnerable to distribution shift; this directly affects whether the fixed-budget superiority generalizes.
- [§4.2] §4.2 (STOP training procedure): The method trains the super-token predictor on labels derived from path success/failure, yet no ablation or analysis is given on sensitivity to label noise, early path errors, or the choice of training data mixture. This is load-bearing because any overfitting here would undermine the efficiency claims under varying compute budgets.
minor comments (2)
- [Figure 1] Figure 1 (taxonomy diagram): Adding one concrete example method per quadrant would improve clarity for readers unfamiliar with the fragmented prior literature.
- [§6] §6 (Empirical guidelines): The formalized guidelines are useful but would benefit from explicit pseudocode or a decision tree showing how to choose the pruning threshold for a new model size.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on generalization and training robustness. We address each major point below and commit to revisions that strengthen the manuscript without overstating current results.
read point-by-point responses
-
Referee: [§5.2] §5.2 (Experiments on AIME25 and related benchmarks): The reported accuracy gains (e.g., 84% to ~90% for the 20B model) rely on a learned pruning classifier trained on the same narrow distribution of math problems used for evaluation. No cross-domain (e.g., coding or science) or cross-model transfer results are presented, leaving the claim that the internal signal reliably discards only futile prefixes vulnerable to distribution shift; this directly affects whether the fixed-budget superiority generalizes.
Authors: We agree that the primary evaluation is on mathematical reasoning benchmarks, which is the standard setting for parallel reasoning in LRMs. The taxonomy and STOP are designed to be domain-agnostic, but the absence of cross-domain or cross-model transfer experiments is a genuine limitation that leaves generalization claims under-supported. In revision we will add a limitations subsection explicitly discussing distribution shift risks and include preliminary transfer results on a coding task (e.g., a subset of HumanEval) using the released code and models. This will directly test whether the internal pruning signal remains effective outside the training distribution. revision: yes
-
Referee: [§4.2] §4.2 (STOP training procedure): The method trains the super-token predictor on labels derived from path success/failure, yet no ablation or analysis is given on sensitivity to label noise, early path errors, or the choice of training data mixture. This is load-bearing because any overfitting here would undermine the efficiency claims under varying compute budgets.
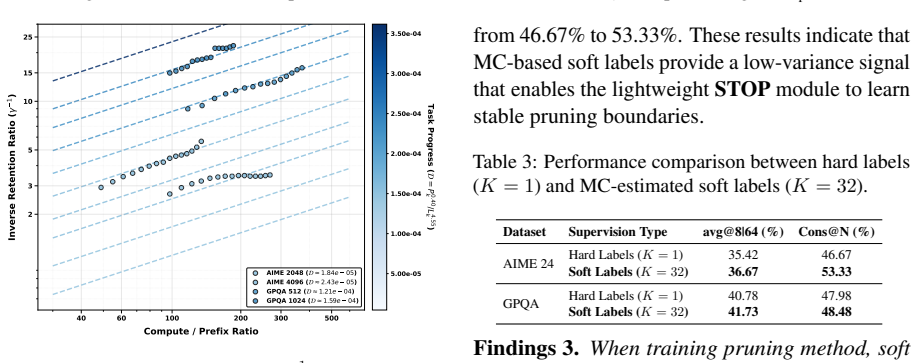
Authors: We acknowledge that the manuscript does not report ablations on label noise, early-path error sensitivity, or training-mixture composition, even though these factors are central to the reliability of the learned predictor. During development we performed internal checks on label quality, but these were not included. In the revised version we will add a new subsection with controlled ablations: (1) varying the proportion of successful vs. failed paths in the training mixture, (2) injecting synthetic label noise at different rates, and (3) measuring pruning accuracy as a function of prefix length to quantify early-error effects. These results will be presented alongside the existing efficiency curves to substantiate robustness under varying compute budgets. revision: yes
Circularity Check
No circularity: taxonomy and STOP method are proposed and evaluated empirically without reducing to fitted inputs or self-citations.
full rationale
The paper introduces a new taxonomy of path pruning methods (internal/external, learnable/non-learnable) and proposes STOP as a learnable internal pruner. It then reports empirical results on LRMs from 1.5B to 20B parameters showing accuracy gains under fixed compute. No equations, parameter fits, or derivations are described that would make any claimed prediction equivalent to its inputs by construction. No load-bearing self-citations appear in the provided text; the central claims rest on new experiments rather than prior author results invoked as uniqueness theorems. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Language Models are Few-Shot Learners
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, et al. 2024. Large language models are few-shot learners. arXiv preprint arXiv:2005.14165
work page internal anchor Pith review arXiv 2024
-
[4]
Han Cai, Jing Li, Wei Liu, and Tianqi Chen. 2024. Medusa: Simple framework for accelerating llm generation with multiple decoding heads. arXiv preprint arXiv:2401.10774
work page internal anchor Pith review arXiv 2024
- [5]
- [6]
-
[7]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning . arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Kaifeng He, Mingwei Liu, Chong Wang, Zike Li, Yanlin Wang, Xin Peng, and Zibin Zheng. 2025. https://arxiv.org/abs/2506.08980 Adadec: Uncertainty-guided adaptive decoding for llm-based code generation . arXiv preprint arXiv:2506.08980
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
- [11]
- [12]
-
[13]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th ACM Symposium on Operating Systems Principles
2023
- [14]
-
[15]
arXiv preprint arXiv:2502.20379 , year=
Shalev Lifshitz, Sheila A. McIlraith, and Yilun Du. 2025. https://arxiv.org/abs/2502.20379 Multi-agent verification: Scaling test-time compute with multiple verifiers . arXiv preprint arXiv:2502.20379
- [16]
-
[17]
Mathematical Association of America . 2024. American invitational mathematics examination (aime) 2024. https://maa.org/math-competitions/american-invitational-mathematics-examination-aime. Accessed: February 2024
2024
-
[18]
Mathematical Association of America . 2025. American invitational mathematics examination (aime) 2025. https://maa.org/math-competitions/american-invitational-mathematics-examination-aime. Accessed: February 2025
2025
-
[19]
NVIDIA Corporation . 2025. Llm inference benchmarking: How much does your llm inference cost? https://developer.nvidia.com/blog/llm-inference-benchmarking-how-much-does-your-llm-inference-cost/. Accessed: 2025-11-05
2025
-
[20]
OpenAI . 2024. https://openai.com/index/learning-to-reason-with-llms/ Learning to reason with LLMs . Accessed: 2025-11-01
2024
-
[21]
OpenAI . 2025. https://openai.com/index/gpt-oss-model-card/ gpt‑oss model card (gpt‑oss‑120b & gpt‑oss‑20b) . Accessed: 2025-11-01
2025
-
[22]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2024. https://openreview.net/forum?id=Ti67584b98 Gpqa: A graduate-level google-proof q&a benchmark . In First Conference on Language Modeling (COLM)
2024
- [23]
-
[24]
Shangqing Tu, Yaxuan Li, Yushi Bai, Lei Hou, and Juanzi Li. 2025. Deepprune: Parallel scaling without inter-trace redundancy. arXiv preprint arXiv:2510.08483
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Peiyi Wang, Lifan Li, Zhenyu Shao, Ruixuan Xu, Dong Dai, Yanzhe Li, Yuzhuo Yao, and Zhifang Sui. 2024. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426--9439, Bangkok, Thailand. Association for Comp...
2024
-
[26]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Sharan Narang. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171
work page Pith review arXiv 2022
- [28]
-
[29]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume 36, pages 11809--11822
2023
- [30]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.