Recognition: unknown
AST: Adaptive, Seamless, and Training-Free Precise Speech Editing
Pith reviewed 2026-05-10 07:56 UTC · model grok-4.3
The pith
A training-free method edits specific segments of speech by recombining latents from any pre-trained TTS model and modulating guidance only at boundaries to keep the rest unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
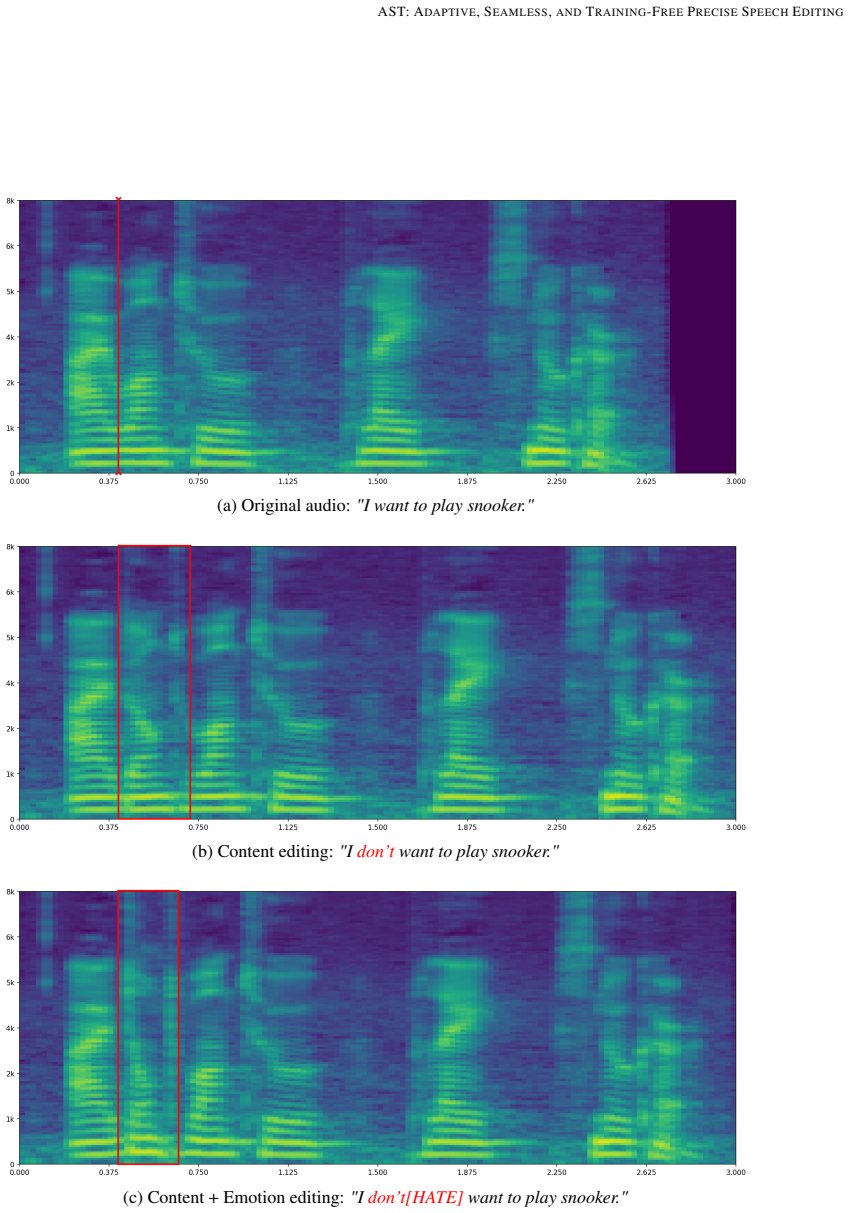
AST resolves the controllability-quality trade-off without extra training by using Latent Recomposition to selectively stitch preserved source segments with newly synthesized targets from a pre-trained autoregressive TTS model, combined with Adaptive Weak Fact Guidance that dynamically modulates a mel-space guidance signal to enforce structural constraints only where necessary at edit boundaries.
What carries the argument
Latent Recomposition, the selective stitching of preserved source segments with synthesized targets inside the latent space of a pre-trained TTS model, paired with Adaptive Weak Fact Guidance that modulates mel-space signals to prevent boundary artifacts.
If this is right
- AST improves temporal consistency over the prior most consistent baseline while reducing Word Error Rate by nearly 70 percent.
- Applying AST to a foundation TTS model reduces WDTW by 27 percent and reaches state-of-the-art speaker preservation and temporal fidelity.
- The same latent manipulation enables precise style editing on chosen segments.
- The new LibriSpeech-Edit dataset supplies a larger public benchmark, and WDTW provides a metric focused on temporal consistency in unedited regions.
Where Pith is reading between the lines
- The boundary-only guidance technique might extend to targeted editing in other sequential generative tasks such as music or sound design.
- Because no retraining is required, the method could let researchers add editing features to newly released TTS models in any language with minimal effort.
- WDTW could serve as a standard evaluation tool for any audio generation system where preserving overall timing matters.
- Testing the approach on noisy or accented real-world recordings would show whether the latent stitching remains stable outside clean studio data.
Load-bearing premise
That selective latent-space stitching from a pre-trained autoregressive TTS model combined with dynamically modulated mel-space guidance will preserve acoustic context, speaker identity, and temporal fidelity in unedited regions without introducing artifacts or requiring any task-specific adaptation.
What would settle it
If AST is applied to a new set of speech edits and the Word Error Rate in edited regions does not drop substantially below baselines or if listeners detect more artifacts at boundaries than in the most consistent prior method, the central claim would be falsified.
Figures





read the original abstract
Text-based speech editing aims to modify specific segments while preserving speaker identity and acoustic context. Existing methods rely on task-specific training, which incurs high data costs and struggles with temporal fidelity in unedited regions. Meanwhile, adapting Text-to-Speech (TTS) models often faces a trade-off between editing quality and consistency. To address these issues, we propose AST, an Adaptive, Seamless, and Training-free precise speech editing framework. Leveraging a pre-trained autoregressive TTS model, AST introduces Latent Recomposition to selectively stitch preserved source segments with newly synthesized targets. Furthermore, AST extends this latent manipulation to enable precise style editing for specific speech segments. To prevent artifacts at these edit boundaries, the framework incorporates Adaptive Weak Fact Guidance (AWFG). AWFG dynamically modulates a mel-space guidance signal, enforcing structural constraints only where necessary without disrupting the generative manifold. To fill the gap of publicly accessible benchmarks, we introduce LibriSpeech-Edit, a new and larger speech editing dataset. As existing metrics poorly evaluate temporal consistency in unedited regions, we propose Word-level Dynamic Time Warping (WDTW). Extensive experiments demonstrate that AST resolves the controllability-quality trade-off without extra training. Compared to the previous most temporally consistent baseline, AST improves consistency while reducing Word Error Rate by nearly 70%. Moreover, applying AST to a foundation TTS model reduces WDTW by 27%, achieving state-of-the-art speaker preservation and temporal fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AST, a training-free speech editing framework that uses a pre-trained autoregressive TTS model. It introduces Latent Recomposition for selectively stitching preserved source segments with synthesized target segments in latent space, Adaptive Weak Fact Guidance (AWFG) to dynamically modulate mel-space guidance and suppress boundary artifacts, the LibriSpeech-Edit dataset, and the Word-level Dynamic Time Warping (WDTW) metric to better evaluate temporal consistency in unedited regions. The central claims are that AST resolves the controllability-quality trade-off, reduces Word Error Rate by nearly 70% relative to the most consistent baseline, reduces WDTW by 27% on a foundation TTS model, and achieves state-of-the-art speaker preservation and temporal fidelity without task-specific training or adaptation.
Significance. If the core claims hold under rigorous validation, the work would be significant for speech synthesis and editing: it shows that precise, high-fidelity editing is possible in a training-free manner by leveraging existing autoregressive foundation models, introduces a new public benchmark dataset that addresses gaps in existing resources, and proposes WDTW as a metric focused on unedited-region fidelity. These contributions could reduce reliance on costly task-specific fine-tuning and enable broader use of large TTS models for editing applications.
major comments (3)
- [§3.2] §3.2 (Latent Recomposition): The selective stitching procedure in the autoregressive latent space does not analyze how the splice affects the conditioning history for tokens generated after the edit boundary; because the base model is autoregressive, any alteration to the latent context can propagate inconsistencies into unedited regions, which is load-bearing for the claim that acoustic context, speaker identity, and temporal fidelity are preserved without artifacts.
- [§3.3] §3.3 (AWFG): No derivation or explicit schedule is given for the dynamic modulation of the mel-space guidance signal; it is unclear how the weakening factor is computed from boundary mismatch (e.g., prosody or phonetic context shifts) or whether the modulation remains stable under large source-target discrepancies, directly affecting the assertion that AWFG prevents artifacts while staying on the generative manifold.
- [Experiments] Experiments (Table 1 and LibriSpeech-Edit results): The reported 70% WER reduction and 27% WDTW improvement are presented without error bars, component ablations (stitching alone vs. AWFG alone), or explicit rules for test-set selection and edit-segment sampling; these omissions make it impossible to determine whether the gains are statistically reliable or whether they generalize beyond the chosen conditions, which is central to validating the resolution of the controllability-quality trade-off.
minor comments (2)
- [Abstract and §4] The abstract and §4 could more explicitly state the number of baselines, exact evaluation protocol, and how LibriSpeech-Edit edit segments were chosen to improve reproducibility.
- [§3] Notation for the latent-space stitching operation and the AWFG modulation function could be formalized with equations to aid clarity.
Simulated Author's Rebuttal
Thank you for the constructive review of our manuscript on AST for precise speech editing. We address each of the major comments point by point below, providing clarifications and committing to revisions that strengthen the paper's rigor and transparency.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Latent Recomposition): The selective stitching procedure in the autoregressive latent space does not analyze how the splice affects the conditioning history for tokens generated after the edit boundary; because the base model is autoregressive, any alteration to the latent context can propagate inconsistencies into unedited regions, which is load-bearing for the claim that acoustic context, speaker identity, and temporal fidelity are preserved without artifacts.
Authors: We thank the referee for pointing out this important aspect of autoregressive models. In our Latent Recomposition approach, the preserved source segments' latents are used to maintain the conditioning history up to the edit point, and the new target latents are inserted seamlessly. However, we agree that an explicit analysis of potential propagation effects would enhance the manuscript. In the revised version, we will add a subsection discussing the impact on subsequent token generation and include additional experiments measuring consistency metrics in regions far from the edit boundary to demonstrate that artifacts do not propagate significantly, thanks to the adaptive guidance mechanism. revision: yes
-
Referee: [§3.3] §3.3 (AWFG): No derivation or explicit schedule is given for the dynamic modulation of the mel-space guidance signal; it is unclear how the weakening factor is computed from boundary mismatch (e.g., prosody or phonetic context shifts) or whether the modulation remains stable under large source-target discrepancies, directly affecting the assertion that AWFG prevents artifacts while staying on the generative manifold.
Authors: We appreciate this feedback on the AWFG component. The weakening factor is dynamically computed based on a mismatch score between the boundary latents of source and target, using a combination of prosodic and phonetic similarity measures. To address the lack of explicit details, we will include a full derivation of the modulation schedule in the revised manuscript, along with pseudocode for the computation and analysis of its stability under varying discrepancy levels. This will clarify how it enforces constraints only where necessary without deviating from the generative manifold. revision: yes
-
Referee: [Experiments] Experiments (Table 1 and LibriSpeech-Edit results): The reported 70% WER reduction and 27% WDTW improvement are presented without error bars, component ablations (stitching alone vs. AWFG alone), or explicit rules for test-set selection and edit-segment sampling; these omissions make it impossible to determine whether the gains are statistically reliable or whether they generalize beyond the chosen conditions, which is central to validating the resolution of the controllability-quality trade-off.
Authors: We agree that providing error bars, ablations, and detailed experimental protocols is essential for validating the results. In the revised manuscript, we will add error bars (standard deviations over multiple runs or seeds) to the reported metrics in Table 1, include component ablations isolating the contributions of Latent Recomposition and AWFG, and provide explicit details on the test-set selection criteria and edit-segment sampling procedure from LibriSpeech-Edit. These additions will allow readers to assess the statistical reliability and generalizability of the improvements. revision: yes
Circularity Check
No circularity: empirical claims rest on external pre-trained model and new experiments
full rationale
The paper introduces a training-free editing framework that reuses a frozen autoregressive TTS model via latent recomposition and AWFG modulation. All headline performance numbers (70% WER drop, 27% WDTW reduction, SOTA fidelity) are reported from comparative experiments on the newly introduced LibriSpeech-Edit benchmark; no equations, fitted parameters, or self-citations are invoked to derive these quantities by construction. The method description contains no self-definitional loops, no renaming of known results as novel derivations, and no load-bearing uniqueness theorems from the authors' prior work. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Latent Recomposition
no independent evidence
-
Adaptive Weak Fact Guidance (AWFG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Natural tts synthesis by conditioning wavenet on mel spectrogram predictions
Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 4779–4783. IEEE, 2018
2018
-
[2]
Fastspeech: Fast, robust and controllable text to speech.Advances in neural information processing systems, 32, 2019
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech: Fast, robust and controllable text to speech.Advances in neural information processing systems, 32, 2019
2019
-
[3]
Fastspeech 2: Fast and high-quality end-to-end text to speech,
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech 2: Fast and high-quality end-to-end text to speech.arXiv preprint arXiv:2006.04558, 2020
-
[4]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech
Jaehyeon Kim, Jungil Kong, and Juhee Son. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. InInternational conference on machine learning, pages 5530–5540. PMLR, 2021
2021
-
[5]
Neural codec language models are zero-shot text to speech synthesizers.IEEE Transactions on Audio, Speech and Language Processing, 33:705–718, 2025
Sanyuan Chen, Chengyi Wang, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers.IEEE Transactions on Audio, Speech and Language Processing, 33:705–718, 2025
2025
-
[6]
Audiolm: a language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31:2523–2533, 2023
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. Audiolm: a language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31:2523–2533, 2023
2023
-
[7]
Editspeech: A text based speech editing system using partial inference and bidirectional fusion
Daxin Tan, Liqun Deng, Yu Ting Yeung, Xin Jiang, Xiao Chen, and Tan Lee. Editspeech: A text based speech editing system using partial inference and bidirectional fusion. In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 626–633. IEEE, 2021
2021
-
[8]
Campnet: Context-aware mask prediction for end-to-end text-based speech editing.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:2241–2254, 2022
Tao Wang, Jiangyan Yi, Ruibo Fu, Jianhua Tao, and Zhengqi Wen. Campnet: Context-aware mask prediction for end-to-end text-based speech editing.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:2241–2254, 2022
2022
-
[9]
Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
1997
-
[10]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[11]
Fluentspeech: Stutter-oriented automatic speech editing with context-aware diffusion models
Ziyue Jiang, Qian Yang, Jialong Zuo, Zhenhui Ye, Rongjie Huang, Yi Ren, and Zhou Zhao. Fluentspeech: Stutter-oriented automatic speech editing with context-aware diffusion models. InFindings of the Association for Computational Linguistics: ACL 2023, pages 11655–11671, 2023
2023
-
[12]
V oicecraft: Zero-shot speech editing and text-to-speech in the wild
Puyuan Peng, Po-Yao Huang, Shang-Wen Li, Abdelrahman Mohamed, and David Harwath. V oicecraft: Zero-shot speech editing and text-to-speech in the wild. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12442–12462, 2024. 13 AST: ADAPTIVE, SEAMLESS,ANDTRAINING-FREEPRECISESPEECHEDITING
2024
-
[13]
Ssr-speech: Towards stable, safe and robust zero-shot text-based speech editing and synthesis
Helin Wang, Meng Yu, Jiarui Hai, Chen Chen, Yuchen Hu, Rilin Chen, Najim Dehak, and Dong Yu. Ssr-speech: Towards stable, safe and robust zero-shot text-based speech editing and synthesis. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[14]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023
2023
-
[15]
An edit friendly ddpm noise space: Inversion and manipulations
Inbar Huberman-Spiegelglas, Vladimir Kulikov, and Tomer Michaeli. An edit friendly ddpm noise space: Inversion and manipulations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12469–12478, 2024
2024
-
[16]
V ALL-E 2: Neural codec language models are human parity zero-shot text to speech synthesizers
Sanyuan Chen, Shujie Liu, Long Zhou, Yanqing Liu, Xu Tan, Jinyu Li, Sheng Zhao, Yao Qian, and Furu Wei. Vall-e 2: Neural codec language models are human parity zero-shot text to speech synthesizers.arXiv preprint arXiv:2406.05370, 2024
-
[17]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407, 2024
-
[18]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review arXiv 2024
-
[19]
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training.arXiv preprint arXiv:2505.17589, 2025
-
[20]
Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system,
Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, and Lu Wang. Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system.arXiv preprint arXiv:2502.05512, 2025
-
[21]
Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech
Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 35139–35148, 2026
2026
-
[22]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[23]
Step-audio-editx technical report.arXiv preprint arXiv:2511.03601, 2025
Chao Yan, Boyong Wu, Peng Yang, Pengfei Tan, Guoqiang Hu, Li Xie, Yuxin Zhang, Fei Tian, Xuerui Yang, Xiangyu Zhang, et al. Step-audio-editx technical report.arXiv preprint arXiv:2511.03601, 2025
-
[24]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
Stable flow: Vital layers for training-free image editing
Omri Avrahami, Or Patashnik, Ohad Fried, Egor Nemchinov, Kfir Aberman, Dani Lischinski, and Daniel Cohen- Or. Stable flow: Vital layers for training-free image editing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7877–7888, 2025
2025
-
[26]
Librispeech: an asr corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015
2015
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors
Chandan KA Reddy, Vishak Gopal, and Ross Cutler. Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6493–6497. IEEE, 2021
2021
-
[29]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
2022
-
[30]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[31]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, et al. Qwen3-asr technical report.arXiv preprint arXiv:2601.21337, 2026. 14
work page internal anchor Pith review arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.