Recognition: unknown
neuralCAD-Edit: An Expert Benchmark for Multimodal-Instructed 3D CAD Model Editing
Pith reviewed 2026-05-10 09:07 UTC · model grok-4.3
The pith
A benchmark built from real designer sessions shows foundation models trail experts by a wide margin on 3D CAD edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that realistic editing instructions collected from expert CAD designers through direct video capture of their software interactions create a benchmark where current foundation models achieve markedly lower human acceptance rates than the designers themselves, with the best model 53 percent lower in absolute terms.
What carries the argument
The central mechanism is the capture of multimodal editing requests by recording professional designers interacting with live CAD models, including speech, pointing, and drawing to convey precise changes.
If this is right
- AI approaches for 3D CAD editing can now be tested against authentic expert instructions rather than synthetic text prompts.
- Progress in multimodal models can be tracked using both geometric metrics and direct human judgments of edit usefulness.
- The benchmark supplies a concrete target for closing the observed performance difference between models and experts.
- Development of specialized CAD tools can focus on handling combined verbal, visual, and spatial cues from real workflows.
Where Pith is reading between the lines
- Models may need explicit training on spatial reasoning and manufacturing constraints that designers implicitly apply during edits.
- The gap could narrow if future systems incorporate interactive feedback loops similar to how designers refine their own changes.
- Expanding the dataset across more CAD software platforms would test whether the current performance difference generalizes.
Load-bearing premise
The editing requests gathered from ten professional designers are representative of typical expert CAD workflows and that human acceptance trials reliably indicate practical edit quality.
What would settle it
A follow-up experiment in which models trained or evaluated on the benchmark data reach acceptance rates close to those of human experts when tested on new editing requests from additional designers.
Figures



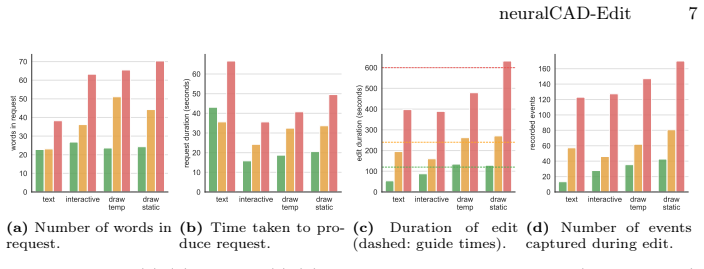


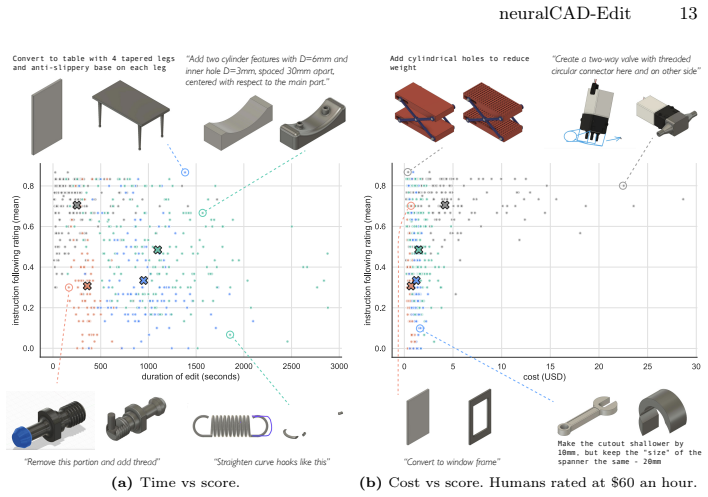
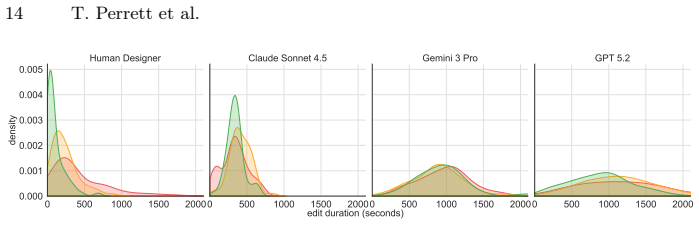
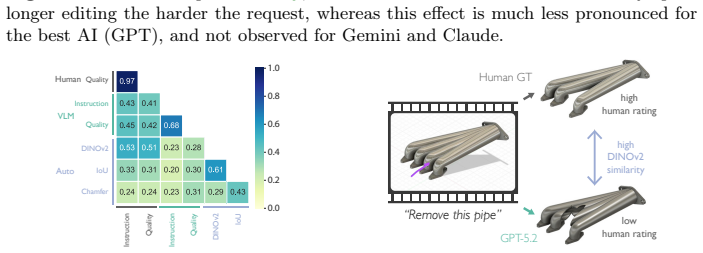
read the original abstract
We introduce neuralCAD-Edit, the first benchmark for editing 3D CAD models collected from expert CAD engineers. Instead of text conditioning as in prior works, we collect realistic CAD editing requests by capturing videos of professional designers, interacting directly with CAD models in CAD software, while talking, pointing and drawing. We recruited ten consenting designers to contribute to this contained study. We benchmark leading foundation models against human CAD experts carrying out edits, and find a large performance gap in both automatic metrics and human evaluations. Even the best foundation model (GPT 5.2) scores 53% lower (absolute) than CAD experts in human acceptance trials, demonstrating the challenge of neuralCAD-Edit. We hope neuralCAD-Edit will provide a solid foundation against which 3D CAD editing approaches and foundation models can be developed. Code/data: https://autodeskailab.github.io/neuralCAD-Edit
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces neuralCAD-Edit, the first benchmark for multimodal-instructed 3D CAD model editing. Editing requests are collected from ten professional designers via videos of direct interactions in CAD software (including speech, pointing, and drawing). Leading foundation models are benchmarked against human CAD experts on the same tasks, with the key result that the best model (GPT 5.2) scores 53% lower (absolute) than experts in human acceptance trials. The work positions the benchmark and released data/code as a foundation for future 3D CAD editing research.
Significance. If the collected requests and evaluation protocols hold, the benchmark would be a useful contribution to multimodal 3D modeling and computer vision by moving beyond synthetic or text-only instructions to real expert workflows. The direct head-to-head comparison with human experts provides a concrete performance target. Releasing the data and code is a positive step for reproducibility in this domain.
major comments (2)
- [§3 (Data Collection)] §3 (Data Collection): The central claim of a 53% performance gap and the benchmark's utility rest on the editing requests being realistic and representative of expert CAD workflows. The manuscript describes a 'contained study' with ten consenting designers but provides no details on designer selection criteria, years of experience, industry domains, CAD software diversity, model complexity distribution, or quantitative breakdown of edit types (e.g., parametric changes vs. topology edits). This absence directly affects whether the gap generalizes.
- [§5 (Evaluation)] §5 (Evaluation): The 53% absolute gap in human acceptance trials is the primary quantitative result. However, the manuscript lacks complete specification of the automatic metrics (definition, computation, and any validation against ground truth), the human trial protocol (number of evaluators per edit, blinding procedures, acceptance criteria, and inter-rater reliability), and how edits were validated as successful. These details are required to interpret and reproduce the reported gap.
minor comments (2)
- [Abstract] Abstract: 'GPT 5.2' is referenced without clarification on whether it corresponds to a publicly available model version or internal variant; this should be aligned with the models listed in the experimental section.
- [Figures and Tables] Figure captions and tables: Ensure all automatic metric definitions and human evaluation scales are explicitly stated in captions or legends so readers can interpret results without cross-referencing the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript introducing neuralCAD-Edit. We address each major comment point-by-point below, indicating planned revisions where applicable.
read point-by-point responses
-
Referee: [§3 (Data Collection)] The central claim of a 53% performance gap and the benchmark's utility rest on the editing requests being realistic and representative of expert CAD workflows. The manuscript describes a 'contained study' with ten consenting designers but provides no details on designer selection criteria, years of experience, industry domains, CAD software diversity, model complexity distribution, or quantitative breakdown of edit types (e.g., parametric changes vs. topology edits). This absence directly affects whether the gap generalizes.
Authors: We agree that providing more context on the data collection process would help readers evaluate the representativeness of the benchmark. In the revised manuscript, we will expand §3 to include a quantitative breakdown of edit types (e.g., counts of parametric changes versus topology edits) and details on the CAD software used, as these were recorded. We will also add a limitations subsection discussing the contained nature of the study and its implications for generalizability. However, detailed information on designer selection criteria, years of experience, and industry domains was not collected to respect participant privacy and consent agreements, so we are unable to provide a full breakdown of these aspects. revision: partial
-
Referee: [§5 (Evaluation)] The 53% absolute gap in human acceptance trials is the primary quantitative result. However, the manuscript lacks complete specification of the automatic metrics (definition, computation, and any validation against ground truth), the human trial protocol (number of evaluators per edit, blinding procedures, acceptance criteria, and inter-rater reliability), and how edits were validated as successful. These details are required to interpret and reproduce the reported gap.
Authors: We acknowledge that the evaluation section requires more detailed specification to ensure reproducibility. In the revised manuscript, we will substantially expand §5 with complete definitions and computation procedures for the automatic metrics, including any ground-truth validations performed. We will also fully describe the human evaluation protocol, including the number of evaluators per edit, blinding procedures, specific acceptance criteria, inter-rater reliability statistics (such as Fleiss' kappa), and the validation process for successful edits. All of this information is available from our experimental records and will be documented clearly. revision: yes
- Detailed designer selection criteria, years of experience, industry domains, CAD software diversity, and model complexity distribution, because these specifics were not systematically recorded during the contained study.
Circularity Check
No circularity: empirical benchmark via new data collection
full rationale
The paper introduces neuralCAD-Edit as a benchmark constructed from multimodal editing requests captured from ten professional CAD designers, then measures foundation model performance against human experts using automatic metrics and human acceptance trials. No derivations, equations, fitted parameters, or predictions appear in the provided text. Central claims rest on direct empirical comparison to external human baselines rather than any self-referential reduction, self-citation chain, or ansatz. The work is self-contained data collection and evaluation with no load-bearing steps that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human evaluators can reliably judge the quality and acceptability of CAD model edits
Reference graph
Works this paper leans on
-
[1]
Cadquery.https://github.com/CadQuery/cadquery
-
[2]
Gemini api documentation.https://ai.google.dev/gemini-api/docs/video- understanding#transcribe-video, accessed 1-Feb-2026
2026
-
[3]
In: International Conference on Computer Vision (2025)
Agrawal,H.,Schoop,E.,Pan,X.,Mahajan,A.,Seff,A.,Feng,D.,Cheng,R.,Teran, A.R.M.Y., Gomez, E., Sundararajan, A., Huang, F., Swearngin, A., Moorthy, M., Nichols, J., Toshev, A.: UINavBench: A Framework for Comprehensive Evaluation of Interactive Digital Agents. In: International Conference on Computer Vision (2025)
2025
-
[4]
arXiv preprint arXiv:2406.00144 (2024)
Badagabettu, A., Yarlagadda, S.S., Farimani, A.B.: Query2cad: Generating cad models using natural language queries. arXiv preprint arXiv:2406.00144 (2024)
-
[5]
INTERSPEECH 2023 (2023)
Bain, M., Huh, J., Han, T., Zisserman, A.: Whisperx: Time-accurate speech tran- scription of long-form audio. INTERSPEECH 2023 (2023)
2023
-
[6]
In: Computer Vision and Pattern Recogntion (2023)
Black, M.J., Patel, P., Tesch, J., Yang, J.: Bedlam: A synthetic dataset of bodies exhibiting detailed lifelike animated motion. In: Computer Vision and Pattern Recogntion (2023)
2023
-
[7]
In: Computer Vision and Pattern Recogntion (2023)
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Computer Vision and Pattern Recogntion (2023)
2023
-
[8]
In: Computer Vision and Pattern Recogntion (2017)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: Computer Vision and Pattern Recogntion (2017)
2017
-
[9]
Chandrasegaran, S., Ramanujan, D., Elmqvist, N.: How do sketching and non- sketching actions convey design intent? In: Proceedings of the 2018 Designing In- teractive Systems Conference (2018)
2018
-
[10]
In: Computer Vision and Pattern Recogntion (2025)
Chen, C., Wei, J., Chen, T., Zhang, C., Yang, X., Zhang, S., Yang, B., Foo, C.S., Lin, G., Huang, Q., Liu, F.: Cadcrafter: Generating computer-aided design models from unconstrained images. In: Computer Vision and Pattern Recogntion (2025)
2025
-
[11]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., Malik, J.: SAM 3D: 3Dfy Anything in Images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review arXiv 2025
-
[12]
arXiv preprint arXiv:2210.11427 (2022)
Couairon, G., Verbeek, J., Schwenk, H., Cord, M.: Diffedit: Diffusion-based seman- tic image editing with mask guidance. arXiv preprint arXiv:2210.11427 (2022)
-
[13]
Perrett et al
Deitke, M., Clark, C., Lee, S., Tripathi, R., Yang, Y., Park, J.S., Salehi, M., Muen- nighoff, N., Lo, K., Soldaini, L., Lu, J., Anderson, T., Bransom, E., Ehsani, K., Ngo, H., Chen, Y., Patel, A., Yatskar, M., Callison-Burch, C., Head, A., Hen- drix, R., Bastani, F., VanderBilt, E., Lambert, N., Chou, Y., Chheda, A., Sparks, J., Skjonsberg, S., Schmitz, ...
2024
-
[14]
In: Computer Vision and Pattern Recogntion (2009)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: Computer Vision and Pattern Recogntion (2009)
2009
-
[15]
In: Computer Vision and Pattern Recogntion (2025)
Gu, Y., Huang, I., Je, J., Yang, G., Guibas, L.: Blendergym: benchmarking foun- dational model systems for graphics editing. In: Computer Vision and Pattern Recogntion (2025)
2025
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Jimenez, C.E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., Narasimhan, K.: Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770 (2023)
work page internal anchor Pith review arXiv 2023
-
[18]
In: Computer Vision and Pattern Recogntion (2017)
Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., Girshick, R.: Clevr: A diagnostic dataset for compositional language and elemen- tary visual reasoning. In: Computer Vision and Pattern Recogntion (2017)
2017
-
[19]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[20]
In: Advances in Neural Information Processing Systems (2024)
Khan, M.S., Sinha, S., Sheikh, T.U., Stricker, D., Ali, S.A., Afzal, M.Z.: Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts. In: Advances in Neural Information Processing Systems (2024)
2024
-
[21]
In: International Conference on Computer Vision (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything. In: International Conference on Computer Vision (2023)
2023
-
[22]
In: Computer Vision and Pattern Recogntion (2019)
Koch, S., Matveev, A., Jiang, Z., Williams, F., Artemov, A., Burnaev, E., Alexa, M., Zorin, D., Panozzo, D.: Abc: A big cad model dataset for geometric deep learning. In: Computer Vision and Pattern Recogntion (2019)
2019
-
[23]
Journal of chiropractic medicine15(2), 155–163 (2016)
Koo, T.K., Li, M.Y.: A guideline of selecting and reporting intraclass correlation coefficients for reliability research. Journal of chiropractic medicine15(2), 155–163 (2016)
2016
-
[24]
Proceedings of the IEEE86(11), 2278–2324 (2002)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proceedings of the IEEE86(11), 2278–2324 (2002)
2002
-
[25]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (2025)
Lee, M., Zhang, D., Jambon, C., Kim, Y.M.: Brepdiff: Single-stage b-rep diffusion model. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (2025)
2025
-
[26]
In: International Conference on Computer Vision (2025)
Li, H., Erkoc, Z., Li, L., Sirigatti, D., Rosov, V., Dai, A., Nießner, M.: Meshpad: Interactive sketch-conditioned artist-reminiscent mesh generation and editing. In: International Conference on Computer Vision (2025)
2025
-
[27]
In: Computer Vision and Pattern Recogntion (2025)
Li, J., Ma, W., Li, X., Lou, Y., Zhou, G., Zhou, X.: Cad-llama: Leveraging large language models for computer-aided design parametric 3d model generation. In: Computer Vision and Pattern Recogntion (2025)
2025
-
[28]
ACM Transactions on Graphics (TOG)44(6), 1–18 (2025)
Li, P., Zhang, W., Quan, W., Zhang, B., Wonka, P., Yan, D.: Brepgpt: Autore- gressive b-rep generation with voronoi half-patch. ACM Transactions on Graphics (TOG)44(6), 1–18 (2025)
2025
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) neuralCAD-Edit 17
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., Cao, Y.P.: Triposg: High-fidelity 3d shape synthesis using large- scale rectified flow models. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) neuralCAD-Edit 17
2025
-
[30]
In: Computer Vision and Pattern Recogntion (2025)
Li, Y., Lin, C., Liu, Y., Long, X., Zhang, C., Wang, N., Li, X., Wang, W., Guo, X.: Caddreamer: Cad object generation from single-view images. In: Computer Vision and Pattern Recogntion (2025)
2025
-
[31]
arXiv preprint arXiv:2508.10201 (2025)
Liu, Y., Dutt, N.S., Li, C., Mitra, N.J.: B-repler: Semantic b-rep latent editor using large language models. arXiv preprint arXiv:2508.10201 (2025)
-
[32]
In: Computer Vision and Pattern Recogntion (2021)
Luo, S., Hu, W.: Diffusion probabilistic models for 3d point cloud generation. In: Computer Vision and Pattern Recogntion (2021)
2021
-
[33]
In: Computer Vision and Pattern Recogntion (2024)
Majumdar, A., Ajay, A., Zhang, X., Putta, P., Yenamandra, S., Henaff, M., Sil- wal, S., Mcvay, P., Maksymets, O., Arnaud, S., Yadav, K., Li, Q., Newman, B., Sharma, M., Berges, V., Zhang, S., Agrawal, P., Bisk, Y., Batra, D., Kalakrishnan, M., Meier, F., Paxton, C., Sax, S., Rajeswaran, A.: Openeqa: Embodied ques- tion answering in the era of foundation m...
2024
-
[34]
In: International Conference on Computer Vision (2025)
Mallis, D., Karadeniz, A.S., Cavada, S., Rukhovich, D., Foteinopoulou, N., Cherenkova, K., Kacem, A., Aouada, D.: Cad-assistant: tool-augmented vllms as generic cad task solvers. In: International Conference on Computer Vision (2025)
2025
-
[35]
In: Advances in Neural Information Processing Systems Datasets and Benchmarks Track (2025)
Man, B., Nehme, G., Alam, M.F., Ahmed, F.: Videocad: A dataset and model for learning long-horizon 3d cad ui interactions from video. In: Advances in Neural Information Processing Systems Datasets and Benchmarks Track (2025)
2025
-
[36]
In: Findings of the Association for Computational Linguistics: EMNLP 2025 (2025)
McCarthy, W.P., Vaduguru, S., Willis, K.D., Matejka, J., Fan, J.E., Fried, D., Pu, Y.: mrcad: Multimodal communication to refine computer-aided designs. In: Findings of the Association for Computational Linguistics: EMNLP 2025 (2025)
2025
-
[37]
In: Eu- ropean Conference on Computer Vision (2020)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: Eu- ropean Conference on Computer Vision (2020)
2020
-
[38]
In: Advances in Neural Information Processing Systems Datasets and Bench- marks Track (2021)
Mu, T., Ling, Z., Xiang, F., Yang, D., Li, X., Tao, S., Huang, Z., Jia, Z., Su, H.: Maniskill: Generalizable manipulation skill benchmark with large-scale demonstra- tions. In: Advances in Neural Information Processing Systems Datasets and Bench- marks Track (2021)
2021
-
[39]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fer- nandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Syn- naeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual fe...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
arXiv preprint arXiv:2509.00269 (2025)
Parelli, M., Oechsle, M., Niemeyer, M., Tombari, F., Geiger, A.: 3d-latte: Latent space 3d editing from textual instructions. arXiv preprint arXiv:2509.00269 (2025)
-
[41]
Patwardhan, T., Dias, R., Proehl, E., Kim, G., Wang, M., Watkins, O., Fishman, S.P., Aljubeh, M., Thacker, P., Fauconnet, L., Kim, N.S., Chao, P., Miserendino, S., Chabot, G., Li, D., Sharman, M., Barr, A., Glaese, A., Tworek, J.: Gdpval: Evaluating ai model performance on real-world economically valuable tasks. arXiv preprint arXiv:2510.04374 (2025)
-
[42]
In: Computer Vision and Pattern Recogntion (2025)
Perrett, T., Darkhalil, A., Sinha, S., Emara, O., Pollard, S., Parida, K., Liu, K., Gatti, P., Bansal, S., Flanagan, K., Chalk, J., Zhu, Z., Guerrier, R., Abdelazim, F., Zhu, B., Moltisanti, D., Wray, M., Doughty, H., Damen, D.: Hd-epic: A highly- detailed egocentric video dataset. In: Computer Vision and Pattern Recogntion (2025)
2025
-
[43]
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Zhang, C.B.C., Shaaban, M., Ling, J., Shi, S., et al.: Humanity’s last exam. arXiv preprint arXiv:2501.14249 (2025) 18 T. Perrett et al
work page internal anchor Pith review arXiv 2025
-
[44]
In: Advances in Neural Information Processing Systems (2023)
Pătrăucean, V., Smaira, L., Gupta, A., Continente, A.R., Markeeva, L., Banarse, D., Koppula, S., Heyward, J., Malinowski, M., Yang, Y., Doersch, C., Matejovi- cova, T., Sulsky, Y., Miech, A., Frechette, A., Klimczak, H., Koster, R., Zhang, J., Winkler, S., Aytar, Y., Osindero, S., Damen, D., Zisserman, A., Carreira, J.: Per- ception test: A diagnostic ben...
2023
-
[45]
In: International Conference on Machine Learning (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (2021)
2021
-
[46]
In: International Conference on Machine Learning (2023)
Radford,A.,Kim,J.W.,Xu,T.,Brockman,G.,McLeavey,C.,Sutskever,I.:Robust speech recognition via large-scale weak supervision. In: International Conference on Machine Learning (2023)
2023
-
[47]
In: Advances in Neural Information Processing Systems (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crowson, K., Schmidt, L., Kaczmarczyk, R., Jitsev, J.: Laion-5b: An open large-scale dataset for training next generation image-text models. In: Advances in Neural Information Processing Systems (2022)
2022
-
[48]
In: Computer Vision and Pattern Recogntion (2022)
Thrush, T., Jiang, R., Bartolo, M., Singh, A., Williams, A., Kiela, D., Ross, C.: Winoground: Probing vision and language models for visio-linguistic composition- ality. In: Computer Vision and Pattern Recogntion (2022)
2022
-
[49]
In: Advances in Neural Information Processing Systems (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (2017)
2017
-
[50]
Computer Aided Geometric Design111, 102327 (2024)
Wang, H., Zhao, M., Wang, Y., Quan, W., Yan, D.M.: Vq-cad: Computer-aided de- sign model generation with vector quantized diffusion. Computer Aided Geometric Design111, 102327 (2024)
2024
-
[51]
arXiv preprint arXiv:2501.19054 (2025)
Wang, R., Yuan, Y., Sun, S., Bian, J.: Text-to-cad generation through infusing visual feedback in large language models. arXiv preprint arXiv:2501.19054 (2025)
-
[52]
In: Advances in Neural Information Processing Systems (2024)
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., Li, T., Ku, M., Wang, K., Zhuang, A., Fan, R., Yue, X., Chen, W.: Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In: Advances in Neural Information Processing Systems (2024)
2024
-
[53]
Rensselaer Polytechnic Institute (1986)
Weiler, K.J.: Topological structures for geometric modeling (Boundary represen- tation, manifold, radial edge structure). Rensselaer Polytechnic Institute (1986)
1986
-
[54]
In: DESIGN International Design Conference, Dubrovnik (2002)
Williams, A., Cowdroy, R.: How designers communicate ideas to each other in design meetings. In: DESIGN International Design Conference, Dubrovnik (2002)
2002
-
[55]
In: Computer Vision and Pattern Recogntion (2022)
Willis, K.D.D., Jayaraman, P.K., Chu, H., Tian, Y., Li, Y., Grandi, D., Sanghi, A., Tran, L., Lambourne, J.G., Solar-Lezama, A., Matusik, W.: Joinable: Learning bottom-up assembly of parametric cad joints. In: Computer Vision and Pattern Recogntion (2022)
2022
-
[56]
ACM Transactions on Graphics (TOG)40(4) (2021)
Willis, K.D.D., Pu, Y., Luo, J., Chu, H., Du, T., Lambourne, J.G., Solar-Lezama, A., Matusik, W.: Fusion 360 gallery: A dataset and environment for programmatic cad construction from human design sequences. ACM Transactions on Graphics (TOG)40(4) (2021)
2021
-
[57]
In: European Conference on Computer Vision (2024)
Wu, S., Khasahmadi, A.H., Katz, M., Jayaraman, P.K., Pu, Y., Willis, K., Liu, B.: Cadvlm: Bridging language and vision in the generation of parametric cad sketches. In: European Conference on Computer Vision (2024)
2024
-
[58]
In: Computer Vision and Pattern Recogntion (2025) neuralCAD-Edit 19
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Computer Vision and Pattern Recogntion (2025) neuralCAD-Edit 19
2025
-
[59]
Xie, H., Ju, F.: Text-to-cadquery: A new paradigm for cad generation with scalable large model capabilities. arXiv preprint arXiv:2505.06507 (2025)
-
[60]
In: Sigraph Asia (2025)
Xu, X., Jayaraman, P.K., Lambourne, J.G., Liu, Y., Malpure, D., Meltzer, P.: Autobrep: Autoregressive b-rep generation with unified topology and geometry. In: Sigraph Asia (2025)
2025
-
[61]
ACM Transactions on Graphics (TOG)43(4), 1–14 (2024)
Xu, X., Lambourne, J., Jayaraman, P., Wang, Z., Willis, K., Furukawa, Y.: Brep- gen: A b-rep generative diffusion model with structured latent geometry. ACM Transactions on Graphics (TOG)43(4), 1–14 (2024)
2024
-
[62]
In: International Design Engineering Technical Conferences and Computers and Information in Engineering Conference (2025)
Yu, N., Alam, M.F., Hart, A.J., Ahmed, F.: Gencad-3d: Cad program genera- tion using multimodal latent space alignment and synthetic dataset balancing. In: International Design Engineering Technical Conferences and Computers and Information in Engineering Conference (2025)
2025
-
[63]
arXiv preprint arXiv:2502.03997 (2025)
Yuan, Y., Sun, S., Liu, Q., Bian, J.: Cad-editor: A locate-then-infill framework with automated training data synthesis for text-based cad editing. arXiv preprint arXiv:2502.03997 (2025)
-
[64]
In: International Conference on Computer Vision (2021)
Zhou, L., Du, Y., Wu, J.: 3d shape generation and completion through point-voxel diffusion. In: International Conference on Computer Vision (2021)
2021
-
[65]
In: Asian Conference on Machine Learning (2025) A Video examples The videos on the project webpage contain four examples from neuralCAD-Edit
Zuo, Z., Gan, Y., Long, J., Liu, X.: CAD-HLLM: Generating executable CAD from text with hierarchical LLM planning. In: Asian Conference on Machine Learning (2025) A Video examples The videos on the project webpage contain four examples from neuralCAD-Edit. One request from each of the four modalities is shown. They are described in Section 2.2 of the main...
2025
-
[66]
Text, medium For each modality, we show:
-
[67]
Request video. 20 T. Perrett et al
-
[68]
Logged events are displayed as captions
Sped up viewport renders from the requestor performing the edit, and the human baseline (who has only seen the request video) performing the edit. Logged events are displayed as captions
-
[69]
B Rubrics The human and VLM evals use the same rubrics for rating edits
Output CAD models from humans and AIs alongside the input model. B Rubrics The human and VLM evals use the same rubrics for rating edits. We collect two scores from each:instruction following, which measures how well the edit conforms to the request, andquality, which measures the quality of the work done. Both are on a 1-7 scale, from worst to best. We l...
-
[70]
Makes things worse or goes in completely the wrong direction
-
[71]
Makes an attempt, demonstrates a rough understanding of the request but many parts incorrect or incomplete
-
[72]
Mostly does what is asked, but with noticeable errors or omissions
-
[73]
Does what is asked, with small errors or omissions
-
[74]
Perfect - follows the request precisely with no errors or omissions
-
[75]
Above and beyond - perfect with helpful extras that a thoughtful expert designer would include. Quality
-
[76]
No model or edit produced
-
[77]
Very poor - erroneous model, impossible geometry, overlapping geometries, incomplete sketches etc
-
[78]
Poor - simplistic, blocky
-
[79]
Average - acceptable first pass
-
[80]
Good attempt with room for improvement
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.