Recognition: unknown
AIFIND: Artifact-Aware Interpreting Fine-Grained Alignment for Incremental Face Forgery Detection
Pith reviewed 2026-05-10 08:51 UTC · model grok-4.3
The pith
AIFIND stabilizes incremental face forgery detection by aligning volatile features to invariant semantic anchors from low-level artifacts using attention and harmonization modules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
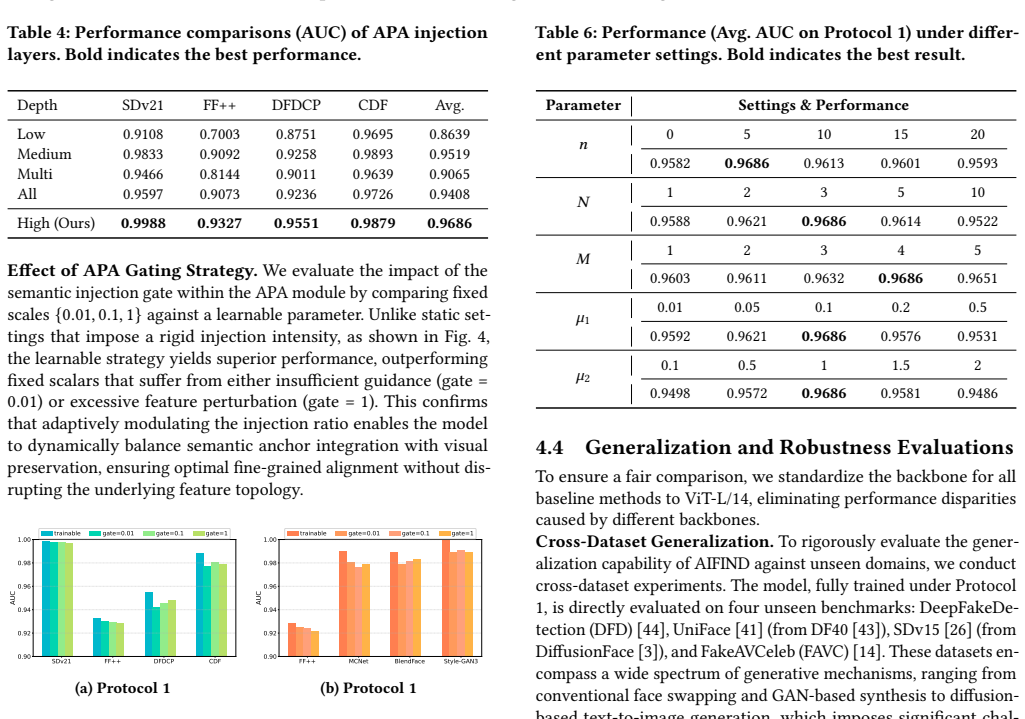
AIFIND leverages semantic anchors to stabilize incremental learning. We design the Artifact-Driven Semantic Prior Generator to instantiate invariant semantic anchors, establishing a fixed coordinate system from low-level artifact cues. These anchors are injected into the image encoder via Artifact-Probe Attention, which explicitly constrains volatile visual features to align with stable semantic anchors. Adaptive Decision Harmonizer harmonizes the classifiers by preserving angular relationships of semantic anchors.
Load-bearing premise
That low-level artifact cues provide invariant semantic anchors capable of constraining the feature space across emerging forgery types without introducing bias or limiting adaptability to new forgeries.
Figures





read the original abstract
As forgery types continue to emerge consistently, Incremental Face Forgery Detection (IFFD) has become a crucial paradigm. However, existing methods typically rely on data replay or coarse binary supervision, which fails to explicitly constrain the feature space, leading to severe feature drift and catastrophic forgetting. To address this, we propose AIFIND, Artifact-Aware Interpreting Fine-Grained Alignment for Incremental Face Forgery Detection, which leverages semantic anchors to stabilize incremental learning. We design the Artifact-Driven Semantic Prior Generator to instantiate invariant semantic anchors, establishing a fixed coordinate system from low-level artifact cues. These anchors are injected into the image encoder via Artifact-Probe Attention, which explicitly constrains volatile visual features to align with stable semantic anchors. Adaptive Decision Harmonizer harmonizes the classifiers by preserving angular relationships of semantic anchors, maintaining geometric consistency across tasks. Extensive experiments on multiple incremental protocols validate the superiority of AIFIND.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-level artifact cues establish invariant semantic anchors that form a fixed coordinate system across forgery types
invented entities (1)
-
Semantic anchors
no independent evidence
Forward citations
Cited by 1 Pith paper
-
STAND: Semantic Anchoring Constraint with Dual-Granularity Disambiguation for Remote Sensing Image Change Captioning
STAND adds semantic anchoring and dual-granularity disambiguation modules to address viewpoint, scale, and knowledge ambiguities in remote sensing change captioning.
Reference graph
Works this paper leans on
- [1]
-
[2]
Pietro Buzzega, Matteo Boschini, Angelo Porrello, and Simone Calderara. 2021. Rethinking experience replay: a bag of tricks for continual learning. In2020 25th International Conference on Pattern Recognition. 2180–2187
2021
- [3]
-
[4]
Jikang Cheng, Zhiyuan Yan, Ying Zhang, Li Hao, Jiaxin Ai, Qin Zou, Chen Li, and Zhongyuan Wang. 2025. Stacking brick by brick: Aligned feature isolation for incremental face forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13927–13936
2025
-
[5]
Xinjie Cui, Yuezun Li, Ao Luo, Jiaran Zhou, and Junyu Dong. 2025. Forensics adapter: Adapting clip for generalizable face forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19207– 19217
2025
-
[6]
Brian Dolhansky, Russ Howes, Ben Pflaum, Nicole Baram, and Cristian Canton Ferrer. 2019. The Deepfake Detection Challenge (DFDC) Preview Dataset
2019
-
[7]
Hui Guo, Shu Hu, Xin Wang, Ming-Ching Chang, and Siwei Lyu. 2022. Eyes tell all: Irregular pupil shapes reveal gan-generated faces. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing. 2904–2908
2022
-
[8]
Zonghui Guo, Yingjie Liu, Jie Zhang, Haiyong Zheng, and Shiguang Shan. 2025. Face Forgery Video Detection via Temporal Forgery Cue Unraveling. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7396–7405
2025
-
[9]
Jiangpeng He, Zhihao Duan, and Fengqing Zhu. 2025. CL-LoRA: Continual Low- Rank Adaptation for Rehearsal-Free Class-Incremental Learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 30534– 30544
2025
-
[10]
Fa-Ting Hong and Dan Xu. 2023. Implicit identity representation conditioned memory compensation network for talking head video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision
2023
-
[11]
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, and Chen Change Loy. 2020. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detec- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2889–2898
2020
-
[12]
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. Alias-free generative adversarial networks.Ad- vances in Neural Information Processing Systems34 (2021), 852–863
2021
-
[13]
Hossein Kashiani, Niloufar Alipour Talemi, and Fatemeh Afghah. 2025. Freqde- bias: Towards generalizable deepfake detection via consistency-driven frequency debiasing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8775–8785
2025
- [14]
-
[15]
Minha Kim and Shahroz Tariq. 2021. Cored: Generalizing fake media detection with continual representation using distillation. InProceedings of the 29th ACM International Conference on Multimedia. 337–346
2021
-
[16]
Youngeun Kim, Yuhang Li, and Priyadarshini Panda. 2024. One-stage prompt- based continual learning. InEuropean Conference on Computer Vision. 163–179
2024
-
[17]
Jiashuo Li, Shaokun Wang, Bo Qian, Yuhang He, Xing Wei, Qiang Wang, and Yihong Gong. 2025. Dynamic integration of task-specific adapters for class incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 30545–30555
2025
-
[18]
Yuezun Li, Ming-Ching Chang, and Siwei Lyu. 2018. In Ictu Oculi: Exposing AI Generated Fake Face Videos by Detecting Eye Blinking. InIEEE International Workshop on Information Forensics and Security
2018
-
[19]
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. 2020. Celeb-df: A large-scale challenging dataset for deepfake forensics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2020
-
[20]
Kaiqing Lin, Yuzhen Lin, Weixiang Li, Taiping Yao, and Bin Li. 2025. Standing on the shoulders of giants: Reprogramming visual-language model for general deepfake detection. InProceedings of the AAAI Conference on Artificial Intelligence. 5262–5270
2025
-
[21]
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, Wan- Teh Chang, Wei Hua, Manfred Georg, and Matthias Grundmann. 2019. MediaPipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172 (2019)
work page internal anchor Pith review arXiv 2019
- [22]
-
[23]
Seyed-Mohsen Moosavi-Dezfooli and Alhussein Fawzi. 2017. Universal adversar- ial perturbations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1765–1773
2017
-
[24]
Kun Pan, Yifang Yin, Yao Wei, Feng Lin, Zhongjie Ba, Zhenguang Liu, Zhibo Wang, Lorenzo Cavallaro, and Kui Ren. 2023. Dfil: Deepfake incremental learning by exploiting domain-invariant forgery clues. InProceedings of the 31st ACM International Conference on Multimedia. 8035–8046
2023
-
[25]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning. PmLR, 8748–8763
2021
-
[26]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695
2022
-
[27]
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. Faceforensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF International Conference on Computer Vision. 1–11
2019
-
[28]
Anurag Roy, Riddhiman Moulick, Vinay K Verma, Saptarshi Ghosh, and Abir Das
-
[29]
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Convolutional prompting meets language models for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23616–23626
- [30]
-
[31]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, and Devi Parikh. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE/CVF International Con- ference on Computer Vision. 618–626
2017
-
[32]
Kaede Shiohara and Toshihiko Yamasaki. 2022. Detecting deepfakes with self- blended images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18720–18729
2022
-
[33]
Kaede Shiohara, Xingchao Yang, and Takafumi Taketomi. 2023. Blendface: Re- designing identity encoders for face-swapping. InProceedings of the IEEE/CVF International Conference on Computer Vision. 7634–7644
2023
-
[34]
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira
-
[35]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11909–11919
-
[36]
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, and Leonid Karlinsky. 2024. Adaptive memory replay for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3605–3615
2024
-
[37]
Ke Sun, Shen Chen, Taiping Yao, Xiaoshuai Sun, Shouhong Ding, and Rongrong Ji. 2025. Continual face forgery detection via historical distribution preserving. International Journal of Computer Vision133, 3 (2025), 1067–1084
2025
-
[38]
Ke Sun, Shen Chen, Taiping Yao, Ziyin Zhou, Jiayi Ji, Xiaoshuai Sun, Chia- Wen Lin, and Rongrong Ji. 2025. Towards general visual-linguistic face forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19576–19586
2025
-
[39]
Jiahe Tian, Cai Yu, Xi Wang, Peng Chen, Zihao Xiao, Jizhong Han, and Yesheng Chai. 2024. Dynamic mixed-prototype model for incremental deepfake detection. InProceedings of the 32nd ACM International Conference on Multimedia. 8129– 8138
2024
-
[40]
Qiang Wang, Xiang Song, Yuhang He, Jizhou Han, Chenhao Ding, Xinyuan Gao, and Yihong Gong. 2025. Boosting Domain Incremental Learning: Selecting the Optimal Parameters is All You Need. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4839–4849
2025
-
[41]
Zhicheng Wang, Yufang Liu, Tao Ji, Xiaoling Wang, Yuanbin Wu, Congcong Jiang, Ye Chao, Zhencong Han, Ling Wang, Xu Shao, et al. 2023. Rehearsal-free continual language learning via efficient parameter isolation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10933–10946
2023
-
[42]
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. 2022. Learning to prompt for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2022
-
[43]
Chao Xu, Jiangning Zhang, Yue Han, Guanzhong Tian, Xianfang Zeng, Ying Tai, Yabiao Wang, Chengjie Wang, and Yong Liu. 2022. Designing one unified frame- work for high-fidelity face reenactment and swapping. InEuropean Conference on Computer Vision. Springer, 54–71
2022
-
[44]
Zhiyuan Yan, Yuhao Luo, Siwei Lyu, Qingshan Liu, and Baoyuan Wu. 2024. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8984–8994
2024
-
[45]
Zhiyuan Yan, Taiping Yao, Shen Chen, Yandan Zhao, Xinghe Fu, Junwei Zhu, Donghao Luo, Chengjie Wang, Shouhong Ding, Yunsheng Wu, et al. 2024. Df40: Toward next-generation deepfake detection.Advances in Neural Information Processing Systems37 (2024), 29387–29434. ICMR ’26, June 16-19, 2026, Amsterdam, Netherlands Hao Wang, Beichen Zhang ∗, Yanpei Gong, Sha...
2024
-
[46]
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. 2023. DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection. InAd- vances in Neural Information Processing Systems, Vol. 36. 4534–4565
2023
-
[47]
Zhiyuan Yan, Yandan Zhao, Shen Chen, Mingyi Guo, Xinghe Fu, Taiping Yao, Shouhong Ding, Yunsheng Wu, and Li Yuan. 2025. Generalizing deepfake video detection with plug-and-play: Video-level blending and spatiotemporal adapter tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12615–12625
2025
-
[48]
Xin Yang, Yuezun Li, and Siwei Lyu. 2019. Exposing deep fakes using inconsistent head poses. InICASSP 2019-2019 IEEE international conference on acoustics, speech and signal processing. 8261–8265
2019
-
[49]
Andrii Yermakov, Jan Cech, and Jiri Matas. 2025. Unlocking the Hidden Potential of CLIP in Generalizable Deepfake Detection.arXiv(2025)
2025
-
[50]
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. 2024. Boosting continual learning of vision-language models via mixture-of- experts adapters. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23219–23230
2024
-
[51]
Jiaran Zhou, Yuezun Li, Baoyuan Wu, Bin Li, Junyu Dong, et al. 2024. Freqblender: Enhancing deepfake detection by blending frequency knowledge.Advances in Neural Information Processing Systems37 (2024), 44965–44988
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.