Recognition: unknown
Find, Fix, Reason: Context Repair for Video Reasoning
Pith reviewed 2026-05-10 08:54 UTC · model grok-4.3
The pith
A frozen larger model identifies missing video details and supplies minimal evidence patches to improve smaller models' reasoning without changing the question.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a frozen, tool-using larger model can locate missing spatiotemporal dependencies in a video and deliver minimal evidence patches that let a smaller student model produce more accurate answers to the unchanged question. Training incorporates these patches through Group Relative Policy Optimization with a Robust Improvement Reward that rewards both outcome validity and rationales aligned to the cited evidence. The resulting updates remain group-normalized across the batch, preserving on-policy exploration while steering it toward dependency-aware directions with only small alterations to the training procedure.
What carries the argument
The central mechanism is the Find, Fix, Reason intervention: a frozen larger teacher applies simple tools to identify gaps and returns minimal evidence patches (timestamps, regions) that the student incorporates before re-answering.
If this is right
- Training stays mostly on-policy with only group-normalized rewards to guide exploration.
- The reward simultaneously enforces correct answers and rationales that cite the added evidence.
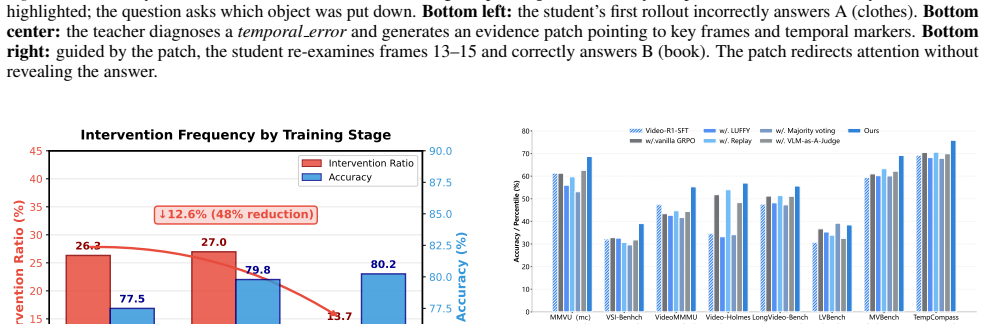
- Accuracy rises consistently on multiple video reasoning benchmarks together with improved generalization.
- The method requires no curated pretraining or two-stage tuning that earlier dynamic-context approaches needed.
- Minimal changes to the existing training stack make the intervention easy to add.
Where Pith is reading between the lines
- The same minimal-patch repair idea could be tested on other multimodal tasks where models miss key context, such as long video or audio sequences.
- Keeping the question fixed may encourage models to learn more robust ways to integrate external evidence during reasoning.
- If the patches stay small, the approach might scale to training runs that use teacher guidance only at selected steps rather than full fine-tuning.
Load-bearing premise
Larger models can reliably spot the exact missing spatiotemporal dependencies and return minimal patches that genuinely help the smaller model answer better without any extra pretraining.
What would settle it
Running the same benchmarks but replacing the teacher's targeted patches with random or irrelevant segments and finding that accuracy gains vanish or reverse would show the repairs are not the source of improvement.
Figures





read the original abstract
Reinforcement learning has advanced video reasoning in large multi-modal models, yet dominant pipelines either rely on on-policy self-exploration, which plateaus at the model's knowledge boundary, or hybrid replay that mixes policies and demands careful regularization. Dynamic context methods zoom into focused evidence but often require curated pretraining and two-stage tuning, and their context remains bounded by a small model's capability. In contrast, larger models excel at instruction following and multi-modal understanding, can supply richer context to smaller models, and rapidly zoom in on target regions via simple tools. Building on this capability, we introduce an observation-level intervention: a frozen, tool-integrated teacher identifies the missing spatiotemporal dependency and provides a minimal evidence patch (e.g., timestamps, regions etc.) from the original video while the question remains unchanged. The student answers again with the added context, and training updates with a chosen-rollout scheme integrated into Group Relative Policy Optimization (GRPO). We further propose a Robust Improvement Reward (RIR) that aligns optimization with two goals: outcome validity through correct answers and dependency alignment through rationales that reflect the cited evidence. Advantages are group-normalized across the batch, preserving on-policy exploration while directing it along causally meaningful directions with minimal changes to the training stack. Experiments on various related benchmarks show consistent accuracy gains and strong generalization. Code will be available at https://jethrojames.github.io/FFR/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Find, Fix, Reason (FFR), an observation-level intervention for improving video reasoning in smaller multimodal models. A frozen larger teacher model, equipped with simple tools, detects missing spatiotemporal dependencies in the input video and supplies minimal evidence patches (e.g., specific timestamps or regions) while leaving the question unchanged. The student model then re-answers with this added context; training proceeds via a chosen-rollout scheme inside Group Relative Policy Optimization (GRPO) augmented by a Robust Improvement Reward (RIR) that rewards both outcome correctness and rationale-evidence alignment. Group normalization preserves on-policy exploration. Experiments on related video-reasoning benchmarks are reported to yield consistent accuracy gains and improved generalization.
Significance. If the empirical results and causal attribution hold, the method offers a lightweight way to steer RL-based video-reasoning training toward causally relevant context without curated pretraining, two-stage tuning, or heavy regularization. It leverages the instruction-following and tool-use strengths of larger models to repair context for smaller students, potentially broadening the applicability of GRPO-style optimization to multimodal tasks where self-exploration plateaus.
major comments (2)
- The central claim that teacher-identified patches causally improve student answers via targeted dependency repair is load-bearing, yet the manuscript provides no ablation comparing targeted patches against non-targeted context additions (random timestamps, generic extra frames, or uniform region sampling). Without this control, it remains possible that any additional video evidence, rather than the 'Find' step, drives the gains; this must be addressed in the Experiments section with quantitative results and error bars.
- The abstract and method description state that the teacher 'identifies the missing spatiotemporal dependency' and supplies a 'minimal evidence patch,' but supply no concrete prompting strategy, tool API details, or selection criteria (e.g., how patch minimality is enforced or how conflicts between multiple candidate patches are resolved). These implementation specifics are required to evaluate reproducibility and to confirm the intervention is not simply additional context.
minor comments (2)
- The claim of 'strong generalization' is stated without reference to specific benchmark names, dataset statistics, or cross-dataset transfer results; these should be tabulated with exact metrics and baselines in the Experiments section.
- Notation for RIR and the chosen-rollout scheme should be formalized with equations (currently described only at a high level) so that the reward formulation and normalization can be inspected for consistency with standard GRPO.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We agree that the two major comments identify important gaps in the current manuscript and will revise accordingly to strengthen the causal claims and reproducibility.
read point-by-point responses
-
Referee: The central claim that teacher-identified patches causally improve student answers via targeted dependency repair is load-bearing, yet the manuscript provides no ablation comparing targeted patches against non-targeted context additions (random timestamps, generic extra frames, or uniform region sampling). Without this control, it remains possible that any additional video evidence, rather than the 'Find' step, drives the gains; this must be addressed in the Experiments section with quantitative results and error bars.
Authors: We agree this ablation is necessary to support the central claim. In the revised manuscript we will add a dedicated ablation subsection in Experiments that directly compares our teacher-identified targeted patches against three non-targeted controls: random timestamps, generic extra frames, and uniform region sampling. All conditions will be evaluated on the same benchmarks with multiple random seeds, reporting mean accuracy and standard error bars. This will quantify whether the gains arise specifically from the dependency-repair step rather than from any additional video evidence. revision: yes
-
Referee: The abstract and method description state that the teacher 'identifies the missing spatiotemporal dependency' and supplies a 'minimal evidence patch,' but supply no concrete prompting strategy, tool API details, or selection criteria (e.g., how patch minimality is enforced or how conflicts between multiple candidate patches are resolved). These implementation specifics are required to evaluate reproducibility and to confirm the intervention is not simply additional context.
Authors: We acknowledge that the current manuscript lacks these implementation details. In the revision we will expand the Method section with a new subsection and add an appendix that specifies: (1) the exact system and user prompts given to the frozen teacher, (2) the tool API signatures and calling format, (3) the quantitative criteria used to enforce patch minimality (e.g., frame count or region area thresholds), and (4) the conflict-resolution rule when multiple candidate patches are proposed. These additions will make the intervention fully reproducible and demonstrate that it is not equivalent to generic extra context. revision: yes
Circularity Check
No circularity: empirical intervention with no derivations or self-referential reductions
full rationale
The paper proposes an observation-level training intervention using a frozen larger teacher to supply minimal evidence patches for video reasoning, integrated into GRPO with a Robust Improvement Reward (RIR). No equations, parameter fittings, or mathematical derivations are described anywhere in the provided text. Claims rest on experimental accuracy gains across benchmarks rather than any derivation chain. There are no self-citations invoked as load-bearing premises, no uniqueness theorems, no ansatzes smuggled via prior work, and no renaming of known results as new organization. The method is presented as a practical, self-contained change to the training stack without reducing any 'prediction' or central result to its own inputs by construction. This is a standard empirical contribution whose reasoning chain does not exhibit circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Affordance Agent Harness: Verification-Gated Skill Orchestration
Affordance Agent Harness is a verification-gated orchestration system that unifies skills via an evidence store, episodic memory priors, an adaptive router, and a self-consistency verifier to improve accuracy-cost tra...
-
Affordance Agent Harness: Verification-Gated Skill Orchestration
Affordance Agent Harness is a verification-gated orchestration framework that adaptively combines heterogeneous skills, retrieves episodic memories, and uses self-consistency checks to improve affordance grounding acc...
Reference graph
Works this paper leans on
-
[1]
First, think through your analysis in <think> tags: - Identify what the student misunderstood - Determine the specific type of error - Identify minimal evidence that would correct the error
-
[2]
error_classification
Then provide structured output in <answer> tags. ## Error Categories (choose one): - ‘temporal‘: Misunderstood temporal sequences or event ordering - ‘spatial‘: Incorrect interpretation of specific frame(s) - ‘misconception‘: Misinterpretation of task requirements or question intent ## Output Format <think> [Your analysis of the student’s error] </think> ...
-
[3]
NEVER name the attribute value (color, count, object identity, direction)
-
[4]
NEVER describe frame content that would make the answer self-evident
-
[5]
ALWAYS redirect to a region or temporal window, requiring the student to RE-OBSERVE the visual evidence independently
-
[6]
blind test
If unsure whether guidance leaks the answer, apply the "blind test": Could someone who has NOT seen the video determine the answer from your patch alone? If yes, the patch is too revealing. Remember: Your role is to help students discover their errors through guided exploration, not to provide answers. Every piece of evidence should require the student to...
2025
-
[7]
Each rollout τi consists of the model’s reasoning trajectory and final answer
Rollout Generation.For each training sample, the student model generates G rollouts (typically G= 8 ) using temperature sampling. Each rollout τi consists of the model’s reasoning trajectory and final answer. During generation, we maintain visual context (images or videos) alongside text prompts to ensure proper multi-modal reasoning
-
[8]
The teacher uses predefined tools to examine specific frames, temporal segments, or spatial regions, generating targeted guidance without revealing the answer
Teacher Intervention.When a rollout produces an incorrect answer (verified through rule-based matching), the frozen teacher model analyzes the error and provides a minimal evidence patch ci. The teacher uses predefined tools to examine specific frames, temporal segments, or spatial regions, generating targeted guidance without revealing the answer. This i...
-
[9]
I see clothes in the scene
Second-Round Generation with Evidence.For incorrect rollouts, the student generates a new response τ ′ i conditioned on both the original input and the teacher’s evidence patch. This second-round generation allows the student to correct its reasoning while maintaining on-policy exploration. D.2. More Implementation Details Our implementation integrates th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.