Recognition: no theorem link
Affordance Agent Harness: Verification-Gated Skill Orchestration
Pith reviewed 2026-05-11 01:51 UTC · model grok-4.3
The pith
A verification-gated harness for affordance agents achieves better grounding accuracy at lower computational cost than fixed skill pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Affordance Agent Harness unifies heterogeneous skills through an evidence store and cost control, retrieves episodic memories for recurring categories, and employs a Router to adaptively select and parameterize skills. An affordance-specific Verifier gates commitments using self-consistency, cross-scale stability, and evidence sufficiency, triggering targeted retries before a final judge fuses accumulated evidence and trajectories into the prediction. Experiments on multiple affordance benchmarks and difficulty-controlled subsets show a stronger accuracy-cost Pareto frontier than fixed-pipeline baselines, improving grounding quality while reducing average skill calls and latency.
What carries the argument
The Affordance Agent Harness, a closed-loop runtime that integrates heterogeneous skills via an evidence store, an adaptive Router for skill selection, and a Verifier that gates commitments on self-consistency, cross-scale stability, and evidence sufficiency metrics.
Load-bearing premise
The self-consistency, cross-scale stability, and evidence sufficiency metrics can reliably gate commitments and trigger useful retries in open-world scenes without any ground-truth labels available at test time.
What would settle it
Running the harness on a new benchmark subset containing highly ambiguous, occluded, or reflective affordances where the verifier produces no accuracy gain or fails to reduce unnecessary skill calls relative to a fixed pipeline would falsify the central claim.
Figures




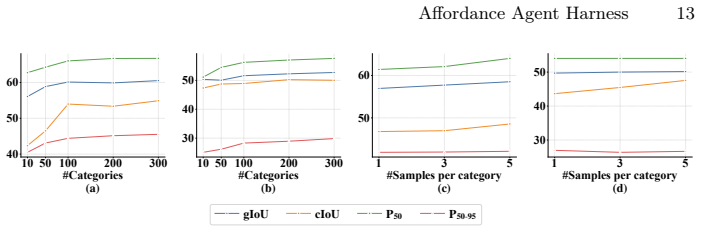










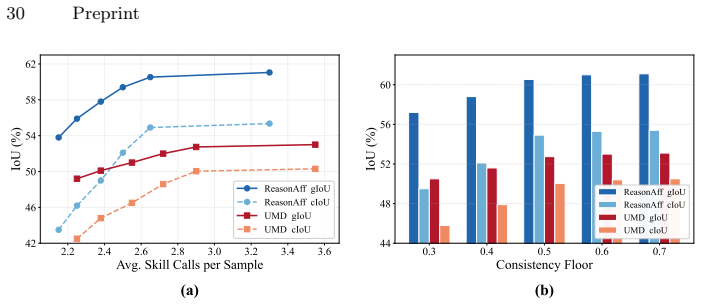






read the original abstract
Affordance grounding requires identifying where and how an agent should interact in open-world scenes, where actionable regions are often small, occluded, reflective, and visually ambiguous. Recent systems therefore combine multiple skills (e.g., detection, segmentation, interaction-imagination), yet most orchestrate them with fixed pipelines that are poorly matched to per-instance difficulty, offer limited targeted recovery from intermediate errors, and fail to reuse experience from recurring objects. These failures expose a systems problem: test-time grounding must acquire the right evidence, decide whether that evidence is reliable enough to commit, and do so under bounded inference cost without access to labels. We propose Affordance Agent Harness, a closed-loop runtime that unifies heterogeneous skills with an evidence store and cost control, retrieves episodic memories to provide priors for recurring categories, and employs a Router to adaptively select and parameterize skills. An affordance-specific Verifier then gates commitments using self-consistency, cross-scale stability, and evidence sufficiency, triggering targeted retries before a final judge fuses accumulated evidence and trajectories into the prediction. Experiments on multiple affordance benchmarks and difficulty-controlled subsets show a stronger accuracy-cost Pareto frontier than fixed-pipeline baselines, improving grounding quality while reducing average skill calls and latency. Project page: https://tenplusgood.github.io/a-harness-page/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the Affordance Agent Harness, a closed-loop verification-gated system for orchestrating heterogeneous skills in affordance grounding. It features an evidence store, episodic memory retrieval, an adaptive Router for skill selection, and a Verifier that uses self-consistency, cross-scale stability, and evidence sufficiency to gate commitments and initiate retries. A final judge fuses the evidence. Experiments are said to demonstrate a superior accuracy-cost Pareto frontier over fixed-pipeline baselines on affordance benchmarks and difficulty-controlled subsets, with better grounding quality and lower average skill calls and latency.
Significance. If the results are substantiated, this architecture could significantly advance practical systems for open-world robotic affordance perception by enabling adaptive, cost-controlled skill orchestration with label-free verification. It builds on ideas from agent harnesses and verification in AI, offering a concrete implementation that reuses experience and recovers from errors in ambiguous scenes. The focus on Pareto efficiency in accuracy versus cost is particularly relevant for real-time applications.
major comments (3)
- [§4 Experiments] No quantitative results, specific numbers for accuracy, cost, latency, or comparisons to baselines are provided, despite the abstract's claims of improvements. Ablation studies and error analysis are also absent, undermining the ability to assess the strength of the empirical claims.
- [§3.2 Verifier] The central assumption that self-consistency, cross-scale stability, and evidence sufficiency serve as reliable proxies for prediction quality without ground-truth labels is not validated. In open-world scenes, consistent errors across skills (e.g., mis-localization on reflective surfaces) could lead the Verifier to commit incorrectly, negating the purported accuracy and efficiency gains.
- [§4.1 Evaluation Setup] The construction of difficulty-controlled subsets is not detailed, raising the possibility of post-hoc selection bias that inflates the reported Pareto gains. Independent, pre-defined criteria for subset creation should be provided to ensure fair evaluation.
minor comments (1)
- [Abstract] The specific affordance benchmarks used in the experiments are not named, which reduces the informativeness of the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will revise the manuscript to incorporate clarifications, additional details, and supporting analyses where needed.
read point-by-point responses
-
Referee: [§4 Experiments] No quantitative results, specific numbers for accuracy, cost, latency, or comparisons to baselines are provided, despite the abstract's claims of improvements. Ablation studies and error analysis are also absent, undermining the ability to assess the strength of the empirical claims.
Authors: We appreciate the referee highlighting the need for greater numerical transparency. The experimental results are presented via Pareto frontier plots and comparative curves in §4, which encode the specific accuracy, cost, latency, and baseline comparisons. To make these values immediately accessible without requiring figure inspection, we will add a summary table in the revised §4 reporting exact metrics (e.g., mean accuracy, average skill calls, latency) across benchmarks and subsets, with direct numerical comparisons to fixed-pipeline baselines. We will also insert ablation studies isolating each harness component and a dedicated error analysis subsection discussing failure modes and recovery rates. revision: yes
-
Referee: [§3.2 Verifier] The central assumption that self-consistency, cross-scale stability, and evidence sufficiency serve as reliable proxies for prediction quality without ground-truth labels is not validated. In open-world scenes, consistent errors across skills (e.g., mis-localization on reflective surfaces) could lead the Verifier to commit incorrectly, negating the purported accuracy and efficiency gains.
Authors: We acknowledge the importance of validating the Verifier's proxy assumptions. The manuscript's empirical results on multiple benchmarks show net gains in grounding quality and reduced skill calls, indicating the proxies function effectively on average. However, we agree that explicit checks against potential consistent errors (such as on reflective surfaces) are warranted. In revision we will expand §3.2 with (i) a quantitative correlation analysis between verifier scores and available ground-truth performance on benchmark subsets and (ii) targeted case studies on ambiguous scenes, including observed behavior on reflective surfaces and the frequency of incorrect commitments versus successful retries. revision: yes
-
Referee: [§4.1 Evaluation Setup] The construction of difficulty-controlled subsets is not detailed, raising the possibility of post-hoc selection bias that inflates the reported Pareto gains. Independent, pre-defined criteria for subset creation should be provided to ensure fair evaluation.
Authors: We agree that full transparency on subset construction is essential to rule out selection bias. The difficulty-controlled subsets were generated using independent, pre-defined quantitative criteria (occlusion ratio thresholds, object density, and visual ambiguity scores computed from dataset annotations) applied before any model evaluation. We will revise §4.1 to include a complete description of these criteria, the exact thresholds, the deterministic procedure used, and confirmation that no post-experiment filtering occurred. Pseudocode for the subset generation process will also be added. revision: yes
Circularity Check
No circularity: systems architecture with empirical validation
full rationale
The paper presents a runtime architecture (evidence store, router, verifier using self-consistency/cross-scale stability/evidence sufficiency, final judge) for orchestrating affordance skills. Central claims rest on experimental Pareto-frontier comparisons against fixed-pipeline baselines on benchmarks and difficulty subsets. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain. The verifier metrics are explicitly part of the proposed system and their utility is assessed via external benchmark results rather than by construction or reduction to inputs. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al.: Do as i can, not as i say: Grounding language in robotic affordances. In: arXiv preprint arXiv:2204.01691 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Anthropic: System card: Claude opus 4.6. Tech. rep., Anthropic (2026),https: //www-cdn.anthropic.com/14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, published: 2026-02-06; Accessed: 2026-03-02
work page 2026
-
[4]
Anthropic: System card: Claude sonnet 4.6. Tech. rep., Anthropic (2026),https: //anthropic.com/claude-sonnet-4-6-system-card, published: 2026-02-17; Ac- cessed: 2026-03-02
work page 2026
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bahl, S., Mendonca, R., Chen, L., Jain, U., Pathak, D.: Affordances from human videos as a versatile representation for robotics. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13778–13790 (2023)
work page 2023
-
[6]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S.,etal.:Qwen2.5-vltechnicalreport(2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
arXiv preprint arXiv:2410.02768 (2024)
Chen, J., Ma, K., Huang, H., Fang, H., Sun, H., Hosseinzadeh, M., Liu, Z.: Uncertainty-guided self-questioning and answering for video-language alignment. arXiv preprint arXiv:2410.02768 (2024)
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Gao, D., Lin, K.Q., Shou, M.Z.: Affordance grounding from demon- stration video to target image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6799–6808 (2023)
work page 2023
-
[11]
In: Euro- pean Conference on Computer Vision
Chen, Y.C., Li, W.H., Sun, C., Wang, Y.C.F., Chen, C.S.: Sam4mllm: Enhance multi-modal large language model for referring expression segmentation. In: Euro- pean Conference on Computer Vision. pp. 323–340. Springer (2024) Affordance Agent Harness 39
work page 2024
-
[12]
Chu, H., Deng, X., Chen, X., Li, Y., Hao, J., Nie, L.: 3d-affordancellm: Harnessing large language models for open-vocabulary affordance detection in 3d worlds. arXiv preprint arXiv:2502.20041 (2025)
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Delitzas, A., Takmaz, A., Tombari, F., Sumner, R., Pollefeys, M., Engelmann, F.: Scenefun3d: fine-grained functionality and affordance understanding in 3d scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14531–14542 (2024)
work page 2024
-
[14]
In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deng, S., Xu, X., Wu, C., Chen, K., Jia, K.: 3d affordancenet: A benchmark for vi- sual object affordance understanding. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1778–1787 (2021)
work page 2021
-
[15]
arXiv preprint arXiv:1709.07326 (2017)
Do, T.T., Nguyen, A., Reid, I.: Affordancenet: An end-to-end deep learning ap- proach for object affordance detection. arXiv preprint arXiv:1709.07326 (2017)
-
[16]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S.M., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Dwivedi, S.K., Antić, D., Tripathi, S., Taheri, O., Schmid, C., Black, M.J., Tzionas, D.: Interactvlm: 3d interaction reasoning from 2d foundational models. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 22605–22615 (June 2025)
work page 2025
-
[18]
arXiv preprint arXiv:2408.13024 (2024)
Gao, X., Zhang, P., Qu, D., Wang, D., Wang, Z., Ding, Y., Zhao, B., Li, X.: Learning 2d invariant affordance knowledge for 3d affordance grounding. arXiv preprint arXiv:2408.13024 (2024)
-
[19]
Google DeepMind: Gemini 3 flash: Model card. Tech. rep., Google Deep- Mind (2025),https://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-3-Flash-Model-Card.pdf, published: 2025-12; Accessed: 2026-03-02
work page 2025
-
[20]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Self-Refine: Iterative Refinement with Self-Feedback
Hallinan, S., Gupta, S., Clark, P., Tandon, N., Alon, U., et al.: Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
arXiv preprint arXiv:2407.13761 (2024)
He, S., Ding, H., Jiang, X., Wen, B.: Segpoint: Segment any point cloud via large language model. arXiv preprint arXiv:2407.13761 (2024)
-
[23]
Advances in Neural Information Processing Systems36, 20482–20494 (2023)
Hong, Y., Zhen, H., Chen, P., Zheng, S., Du, Y., Chen, Z., Gan, C.: 3d-llm: In- jecting the 3d world into large language models. Advances in Neural Information Processing Systems36, 20482–20494 (2023)
work page 2023
-
[24]
Journal of Intelligent & Fuzzy Systems45(3), 4935–4947 (2023)
Huang, H., Liu, Z., Han, X., Yang, X., Liu, L.: A belief logarithmic similarity measure based on dempster-shafer theory and its application in multi-source data fusion. Journal of Intelligent & Fuzzy Systems45(3), 4935–4947 (2023)
work page 2023
-
[25]
arXiv preprint arXiv:2408.13123 (2024)
Huang, H., Liu, Z., Letchmunan, S., Deveci, M., Lin, M., Wang, W.: Eviden- tial deep partial multi-view classification with discount fusion. arXiv preprint arXiv:2408.13123 (2024)
-
[26]
Find, Fix, Reason: Context Repair for Video Reasoning
Huang, H., Qin, C., Li, Y., Chen, Y.: Find, fix, reason: Context repair for video reasoning. arXiv preprint arXiv:2604.16243 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
In: Proceedings of the AAAI conference on artificial intelligence
Huang, H., Qin, C., Liu, Z., Ma, K., Chen, J., Fang, H., Ban, C., Sun, H., He, Z.: Trusted unified feature-neighborhood dynamics for multi-view classification. In: Proceedings of the AAAI conference on artificial intelligence. vol. 39, pp. 17413– 17421 (2025)
work page 2025
-
[28]
In: Conference on Robot Learning (CoRL) (2023) 40 Preprint
Huang, W., Wang, C., Zhang, R., Li, Y., Wu, J., Fei-Fei, L.: Voxposer: Composable 3d value maps for robotic manipulation with language models. In: Conference on Robot Learning (CoRL) (2023) 40 Preprint
work page 2023
-
[29]
Detect anything via next point prediction,
Jiang, Q., Huo, J., Chen, X., Xiong, Y., Zeng, Z., Chen, Y., Ren, T., Yu, J., Zhang, L.: Detect anything via next point prediction. arXiv preprint arXiv:2510.12798 (2025)
-
[30]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
work page 2023
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning seg- mentation via large language model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9579–9589 (2024)
work page 2024
-
[32]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Li, G., Sun, D., Sevilla-Lara, L., Jampani, V.: One-shot open affordance learning with foundation models. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 3086–3096 (2024)
work page 2024
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, X., Zhang, M., Geng, Y., Geng, H., Long, Y., Shen, Y., Zhang, R., Liu, J., Dong, H.: Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18061–18070 (2024)
work page 2024
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Liang, F., Wu, B., Dai, X., Li, K., Zhao, Y., Zhang, H., Zhang, P., Vajda, P., Mar- culescu, D.: Open-vocabulary semantic segmentation with mask-adapted clip. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 7061–7070 (2023)
work page 2023
-
[35]
Advances in neural information processing systems36(2024)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36(2024)
work page 2024
-
[36]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
work page 2024
-
[37]
arXiv preprint arXiv:2503.06520 (2025)
Liu, Y., Peng, B., Zhong, Z., Yue, Z., Lu, F., Yu, B., Jia, J.: Seg-zero: Reasoning- chain guided segmentation via cognitive reinforcement. ArXivabs/2503.06520 (2025)
-
[38]
Liu, Y., Qu, T., Zhong, Z., Peng, B., Liu, S., Yu, B., Jia, J.: Visionreasoner: Uni- fied visual perception and reasoning via reinforcement learning. arXiv preprint arXiv:2505.12081 (2025)
-
[39]
In: International conference on artificial neural networks
Liu, Z., Huang, H., Letchmunan, S.: Adaptive weighted multi-view evidential clus- tering. In: International conference on artificial neural networks. pp. 265–277. Springer (2023)
work page 2023
-
[40]
Knowledge-Based Systems294, 111770 (2024)
Liu, Z., Huang, H., Letchmunan, S., Deveci, M.: Adaptive weighted multi-view ev- idential clustering with feature preference. Knowledge-Based Systems294, 111770 (2024)
work page 2024
-
[41]
arXiv preprint arXiv:2412.09511 (2024)
Lu, D., Kong, L., Huang, T., Lee, G.H.: Geal: Generalizable 3d affordance learning with cross-modal consistency. arXiv preprint arXiv:2412.09511 (2024)
-
[42]
IEEE Transactions on Neural Networks and Learn- ing Systems (2023)
Luo, H., Zhai, W., Zhang, J., Cao, Y., Tao, D.: Learning visual affordance ground- ing from demonstration videos. IEEE Transactions on Neural Networks and Learn- ing Systems (2023)
work page 2023
-
[43]
Advances in Neural Information Processing Systems36, 72983–73007 (2023)
Minderer, M., Gritsenko, A., Houlsby, N.: Scaling open-vocabulary object detec- tion. Advances in Neural Information Processing Systems36, 72983–73007 (2023)
work page 2023
-
[44]
In: Conference on robot learning
Mo, K., Qin, Y., Xiang, F., Su, H., Guibas, L.: O2o-afford: Annotation-free large- scale object-object affordance learning. In: Conference on robot learning. pp. 1666–
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Mo, K., Zhu, S., Chang, A.X., Yi, L., Tripathi, S., Guibas, L.J., Su, H.: Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object un- Affordance Agent Harness 41 derstanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 909–918 (2019)
work page 2019
-
[46]
Simulation tools for model- based robotics: Comparison of bullet, havok, mujoco, ode and physx,
Myers, A., Teo, C.L., Fermüller, C., Aloimonos, Y.: Affordance detection of tool parts from geometric features. In: 2015 IEEE International Conference on Robotics and Automation (ICRA). pp. 1374–1381 (2015).https://doi.org/10.1109/ICRA. 2015.7139369
-
[47]
Nasiriany, S., Kirmani, S., Ding, T., Smith, L., Zhu, Y., Driess, D., Sadigh, D., Xiao, T.: Rt-affordance: Affordances are versatile intermediate representations for robot manipulation. arXiv preprint arXiv:2411.02704 (2024)
-
[48]
In: 2023 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS)
Nguyen, T., Vu, M.N., Vuong, A., Nguyen, D., Vo, T., Le, N., Nguyen, A.: Open- vocabulary affordance detection in 3d point clouds. In: 2023 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). pp. 5692–5698. IEEE (2023)
work page 2023
-
[49]
Advances in Neural Information Processing Systems36, 4585–4596 (2023)
Ning, C., Wu, R., Lu, H., Mo, K., Dong, H.: Where2explore: Few-shot affordance learning for unseen novel categories of articulated objects. Advances in Neural Information Processing Systems36, 4585–4596 (2023)
work page 2023
-
[50]
arXiv preprint arXiv:2402.17766 (2024)
Qi, Z., Dong, R., Zhang, S., Geng, H., Han, C., Ge, Z., Yi, L., Ma, K.: Shapellm: Universal 3d object understanding for embodied interaction. arXiv preprint arXiv:2402.17766 (2024)
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qian, S., Chen, W., Bai, M., Zhou, X., Tu, Z., Li, L.E.: Affordancellm: Ground- ing affordance from vision language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7587–7597 (2024)
work page 2024
-
[52]
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026),https: //qwen.ai/blog?id=qwen3.5
work page 2026
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rasheed, H., Maaz, M., Shaji, S., Shaker, A., Khan, S., Cholakkal, H., Anwer, R.M., Xing, E., Yang, M.H., Khan, F.S.: Glamm: Pixel grounding large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13009–13018 (2024)
work page 2024
-
[54]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ren, Z., Huang, Z., Wei, Y., Zhao, Y., Fu, D., Feng, J., Jin, X.: Pixellm: Pixel rea- soning with large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26374–26383 (2024)
work page 2024
-
[56]
arXiv preprint arXiv:2602.13195 (2026)
Sahoo, A., Gkioxari, G.: Conversational image segmentation: Grounding abstract concepts with scalable supervision. arXiv preprint arXiv:2602.13195 (2026)
-
[57]
Advances in neural information processing systems36, 68539–68551 (2023)
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettle- moyer, L., Cancedda, N., Scialom, T.: Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems36, 68539–68551 (2023)
work page 2023
-
[58]
arXiv preprint arXiv:2411.19626 (2024)
Shao, Y., Zhai, W., Yang, Y., Luo, H., Cao, Y., Zha, Z.J.: Great: Geometry- intention collaborative inference for open-vocabulary 3d object affordance ground- ing. arXiv preprint arXiv:2411.19626 (2024)
-
[59]
Advances in neural information processing systems36, 8634–8652 (2023)
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Lan- guage agents with verbal reinforcement learning. Advances in neural information processing systems36, 8634–8652 (2023)
work page 2023
-
[60]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3 (2025),https://ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
arXiv preprint arXiv:2505.16517 (2025)
Song, Z., Ouyang, G., Li, M., Ji, Y., Wang, C., Xu, Z., Zhang, Z., Zhang, X., Jiang, Q., Chen, Z., et al.: Maniplvm-r1: Reinforcement learning for reason- ing in embodied manipulation with large vision-language models. arXiv preprint arXiv:2505.16517 (2025)
-
[62]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Su, A., Wang, H., Ren, W., Lin, F., Chen, W.: Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning. arXiv preprint arXiv:2505.15966 (2025)
work page internal anchor Pith review arXiv 2025
-
[63]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Sun, P., Chen, S., Zhu, C., Xiao, F., Luo, P., Xie, S., Yan, Z.: Going denser with open-vocabulary part segmentation. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 15453–15465 (2023)
work page 2023
-
[64]
arXiv preprint arXiv:2404.11000 (2024)
Tong, E., Opipari, A., Lewis, S., Zeng, Z., Jenkins, O.C.: Oval-prompt: Open- vocabulary affordance localization for robot manipulation through llm affordance- grounding. arXiv preprint arXiv:2404.11000 (2024)
-
[65]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Van Vo, T., Vu, M.N., Huang, B., Nguyen, T., Le, N., Vo, T., Nguyen, A.: Open- vocabulary affordance detection using knowledge distillation and text-point cor- relation. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 13968–13975. IEEE (2024)
work page 2024
-
[66]
arXiv preprint arXiv:2505.18291 (2025)
Wan, Z., Xie, Y., Zhang, C., Lin, Z., Wang, Z., Stepputtis, S., Ramanan, D., Sycara, K.: Instructpart: Task-oriented part segmentation with instruction reason- ing. arXiv preprint arXiv:2505.18291 (2025)
-
[67]
Wang, H., Wang, S., Zhong, Y., Yang, Z., Wang, J., Cui, Z., Yuan, J., Han, Y., Liu, M., Ma, Y.: Affordance-r1: Reinforcement learning for generalizable affordance reasoning in multimodal large language model. arXiv preprint arXiv:2508.06206 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
arXiv preprint arXiv:2508.01651 (2025)
Wang, H., Zhang, Z., Ji, K., Liu, M., Yin, W., Chen, Y., Liu, Z., Zeng, X., Gui, T., Zhang, H.: Dag: Unleash the potential of diffusion model for open-vocabulary 3d affordance grounding. arXiv preprint arXiv:2508.01651 (2025)
-
[69]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, D., Fu, Y., Huang, S., Liu, Y., Jia, F., Liu, N., Dai, F., Wang, T., Anwer, R.M., Khan, F.S., et al.: Ragnet: Large-scale reasoning-based affordance segmen- tation benchmark towards general grasping. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11980–11990 (2025)
work page 2025
-
[71]
Wu, R., Cheng, K., Zhao, Y., Ning, C., Zhan, G., Dong, H.: Learning environment- awareaffordancefor3darticulatedobjectmanipulationunderocclusions.Advances in Neural Information Processing Systems36, 60966–60983 (2023)
work page 2023
-
[72]
Wu, S., Zhu, Y., Huang, Y., Zhu, K., Gu, J., Yu, J., Shi, Y., Wang, J.: Af- forddp: Generalizable diffusion policy with transferable affordance. arXiv preprint arXiv:2412.03142 (2024)
-
[73]
Re- woo: Decoupling reasoning from observations for ef- ficient augmented language models
Xu, B., Peng, Z., Lei, B., Mukherjee, S., Liu, Y., Xu, D.: Rewoo: Decoupling rea- soning from observations for efficient augmented language models. arXiv preprint arXiv:2305.18323 (2023)
-
[74]
arXiv preprint arXiv:2202.13519 (2022)
Xu, C., Chen, Y., Wang, H., Zhu, S.C., Zhu, Y., Huang, S.: Partafford: Part-level affordance discovery from 3d objects. arXiv preprint arXiv:2202.13519 (2022)
-
[75]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xu, M., Zhang, Z., Wei, F., Hu, H., Bai, X.: Side adapter network for open- vocabulary semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2945–2954 (2023) Affordance Agent Harness 43
work page 2023
-
[76]
Pointllm: Empowering large language models to understand point clouds,
Xu, R., Wang, X., Wang, T., Chen, Y., Pang, J., Lin, D.: PointLLM: Empowering large language models to understand point clouds. arXiv preprint arXiv:2308.16911 (2023)
-
[77]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Yang, Y., Zhai, W., Luo, H., Cao, Y., Luo, J., Zha, Z.J.: Grounding 3d object affordance from 2d interactions in images. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 10905–10915 (2023)
work page 2023
-
[79]
ReAct: Synergizing Reasoning and Acting in Language Models
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Syn- ergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[80]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
You, H., Zhang, H., Gan, Z., Du, X., Zhang, B., Wang, Z., Cao, L., Chang, S.F., Yang, Y.: Ferret: Refer and ground anything anywhere at any granularity. arXiv preprint arXiv:2310.07704 (2023)
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.