Recognition: unknown
Beyond Distribution Sharpening: The Importance of Task Rewards
Pith reviewed 2026-05-10 08:03 UTC · model grok-4.3
The pith
Task-reward reinforcement learning produces stable gains on math tasks while pure distribution sharpening leads to unstable and suboptimal results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
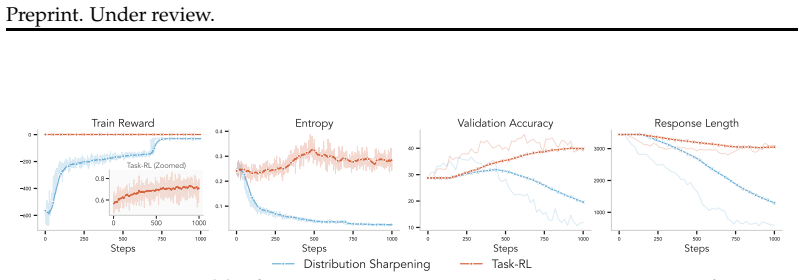
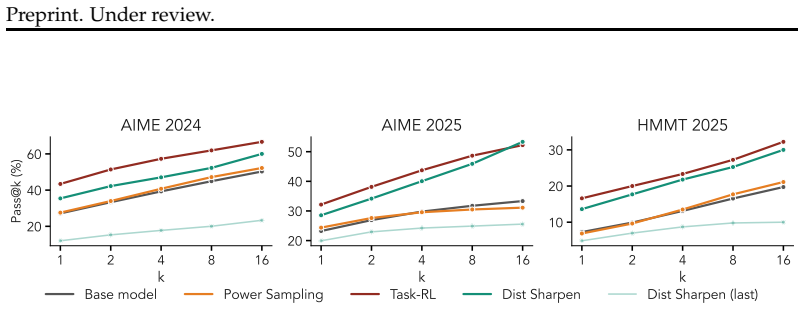
When reinforcement learning implements pure distribution sharpening without task-specific rewards, the optima are unfavorable and the approach is unstable from first principles; incorporating task-based reward signals instead enables robust performance improvements and stable learning on mathematical reasoning tasks.
What carries the argument
Reinforcement learning used as an explicit tool to realize either pure distribution sharpening or full task-reward learning for controlled comparison of the two.
If this is right
- Distribution sharpening alone yields only limited gains on math reasoning tasks.
- Task-based reward signals produce significantly more robust performance improvements.
- Learning remains stable when task rewards are present in the reinforcement learning process.
- Frontier model pipelines benefit from task-reward integration to move beyond latent capability elicitation.
Where Pith is reading between the lines
- The instability result suggests that scaling sharpening methods without task rewards will continue to hit the same unfavorable optima on other reasoning problems.
- Training pipelines could be redesigned to emphasize reward function engineering rather than post-hoc sharpening steps.
- The pattern may be testable by applying the same controlled RL comparison to non-math domains such as code generation or multi-step planning.
Load-bearing premise
That reinforcement learning setups can isolate pure distribution sharpening without any task-specific information entering through the configuration, and that outcomes on the tested small models and math datasets extend to the general case.
What would settle it
An experiment in which pure distribution sharpening, applied to the same models and math datasets, produces performance and stability equal to or greater than task-reward reinforcement learning would falsify the claim of inherent limitations.
Figures




read the original abstract
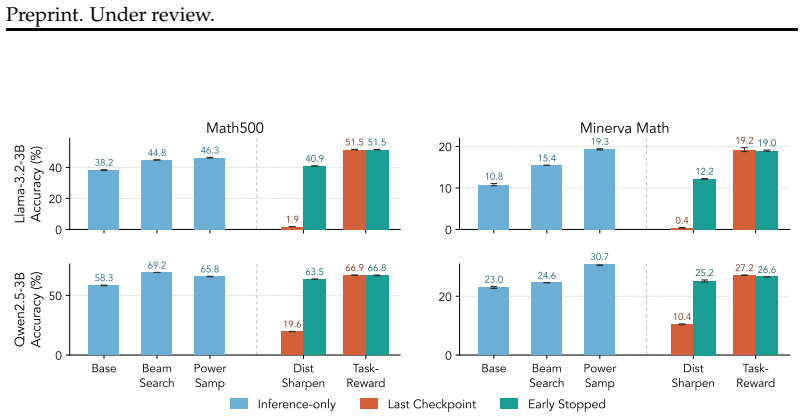
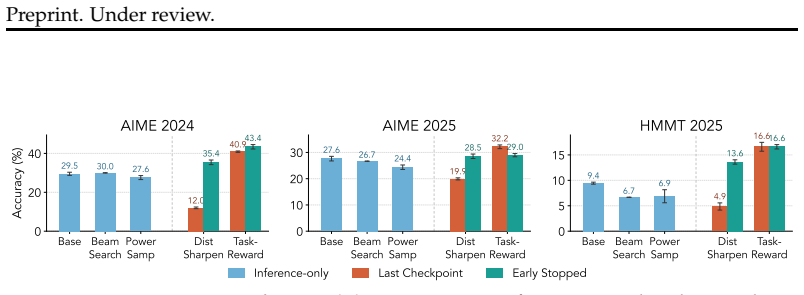
Frontier models have demonstrated exceptional capabilities following the integration of task-reward-based reinforcement learning (RL) into their training pipelines, enabling systems to evolve from pure reasoning models into sophisticated agents. However, debate persists regarding whether RL genuinely instills new skills within a base model or merely sharpens its existing distribution to elicit latent capabilities. To address this dichotomy, we present an explicit comparison between distribution sharpening and task-reward-based learning, utilizing RL as a tool to implement both paradigms. Our analysis reveals the inherent limitations of distribution sharpening, demonstrating from first principles how and why the optima can be unfavorable and the approach fundamentally unstable. Furthermore, our experiments using Llama-3.2-3B-Instruct, Qwen2.5-3B-Instruct and Qwen3-4B-Instruct-2507 on math datasets confirm that sharpening yields limited gains, whereas incorporating task-based reward signal can greatly help achieve robust performance improvements and stable learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares distribution sharpening and task-reward-based RL in LLM post-training. It claims a first-principles analysis showing that sharpening has unfavorable optima and is fundamentally unstable, while experiments on math datasets with Llama-3.2-3B-Instruct, Qwen2.5-3B-Instruct, and Qwen3-4B-Instruct demonstrate limited gains from sharpening versus robust, stable improvements when explicit task rewards are added. RL is used symmetrically to implement both paradigms.
Significance. If the claimed separation between pure distribution sharpening (eliciting latent capabilities without task-specific learning) and task-reward RL holds, the work would help clarify the mechanisms behind RL's benefits in frontier-model training. The symmetric use of RL for both conditions is a methodological strength that controls for the optimizer itself. The result, if substantiated, would support prioritizing task-grounded rewards over sharpening-only approaches for stable performance gains.
major comments (2)
- [Abstract / theoretical analysis] Abstract and theoretical analysis: the claim of a 'first-principles demonstration' that distribution sharpening yields unfavorable optima and is 'fundamentally unstable' is not accompanied by explicit derivation steps, equations, or the mathematical formulation of the objective and its instability. Without these, the central theoretical argument cannot be evaluated for correctness or generality.
- [Experiments] Experiments section: the RL implementation for the 'pure distribution sharpening' condition is not shown to exclude task-specific reward signals. On math datasets, standard rewards rely on answer correctness or verification against labels; if this signal is present in the sharpening arm (as appears likely given the setup), the comparison collapses, the instability claim cannot be isolated to sharpening per se, and the experimental conclusion that sharpening yields 'limited gains' is undermined.
minor comments (2)
- [Experiments] Missing details on data splits, exact reward formulations, training hyperparameters, statistical significance tests, and variance across runs make the experimental claims difficult to reproduce or assess.
- [Experiments] The manuscript should clarify whether the three models and math datasets were chosen to stress-test generalization or simply for computational convenience; this affects how far the results speak to frontier-model training.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the clarity of our theoretical claims and experimental controls. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical analysis: the claim of a 'first-principles demonstration' that distribution sharpening yields unfavorable optima and is 'fundamentally unstable' is not accompanied by explicit derivation steps, equations, or the mathematical formulation of the objective and its instability. Without these, the central theoretical argument cannot be evaluated for correctness or generality.
Authors: We agree that the current presentation would benefit from greater explicitness. The manuscript contains the core objective and instability argument, but the step-by-step derivations are condensed. In the revised version we will expand the theoretical section to include the full mathematical formulation of the distribution-sharpening objective, the derivation of its stationary points, and the analysis showing why those points are unfavorable and the dynamics are unstable. This will allow direct evaluation of the claims. revision: yes
-
Referee: [Experiments] Experiments section: the RL implementation for the 'pure distribution sharpening' condition is not shown to exclude task-specific reward signals. On math datasets, standard rewards rely on answer correctness or verification against labels; if this signal is present in the sharpening arm (as appears likely given the setup), the comparison collapses, the instability claim cannot be isolated to sharpening per se, and the experimental conclusion that sharpening yields 'limited gains' is undermined.
Authors: We appreciate the referee's concern about potential reward leakage. In the pure-sharpening arm we deliberately employ a non-task-specific reward (entropy-based or consistency-based signals that do not reference ground-truth labels or answer correctness). The task-reward arm adds the explicit correctness signal on top of the same RL optimizer. This symmetry is described in the experimental setup, but we acknowledge the description is not sufficiently detailed. We will add explicit reward-function pseudocode, ablation tables confirming the absence of label-based signals in the sharpening condition, and further controls to isolate the effect. revision: partial
Circularity Check
No significant circularity in theoretical or experimental claims
full rationale
The paper derives its central claims via an explicit first-principles theoretical analysis of distribution sharpening's instability and unfavorable optima, followed by an empirical comparison that applies RL symmetrically to implement both the sharpening condition and the task-reward condition. No equations or results reduce by construction to fitted parameters, self-defined quantities, or self-citations; the reward signals for each arm are independently specified, and the math-dataset experiments on the listed models serve as external validation rather than tautological outputs. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gall \'e , Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet \"U st \"u n, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1...
2024
-
[2]
Mislav Balunovi \'c , Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi \'c , and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions. arXiv preprint arXiv:2505.23281, 2025
-
[3]
Flow network based generative models for non-iterative diverse candidate generation
Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. Flow network based generative models for non-iterative diverse candidate generation. Advances in neural information processing systems, 34: 0 27381--27394, 2021
2021
-
[4]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention. arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review arXiv 2025
- [5]
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2601.15609 , year=
Mingyuan Fan, Weiguang Han, Daixin Wang, Cen Chen, Zhiqiang Zhang, and Jun Zhou. When sharpening becomes collapse: Sampling bias and semantic coupling in rl with verifiable rewards, 2026. URL https://arxiv.org/abs/2601.15609
-
[8]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645 0 (8081): 0 633--638, 2025
2025
-
[9]
Andre He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting grpo beyond distribution sharpening, 2025. URL https://arxiv.org/abs/2506.02355
-
[10]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review arXiv 2021
-
[11]
Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin. Amortizing intractable inference in large language models. arXiv preprint arXiv:2310.04363, 2023
-
[12]
Foster, Dhruv Rohatgi, Cyril Zhang, Max Simchowitz, Jordan T
Audrey Huang, Adam Block, Dylan J Foster, Dhruv Rohatgi, Cyril Zhang, Max Simchowitz, Jordan T Ash, and Akshay Krishnamurthy. Self-improvement in language models: The sharpening mechanism. arXiv preprint arXiv:2412.01951, 2024
-
[13]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
arXiv preprint arXiv:2601.21590 , year=
Xiaotong Ji, Rasul Tutunov, Matthieu Zimmer, and Haitham Bou Ammar. Scalable power sampling: Unlocking efficient, training-free reasoning for llms via distribution sharpening, 2026. URL https://arxiv.org/abs/2601.21590
-
[15]
Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901,
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think. arXiv preprint arXiv:2510.14901, 2025
-
[16]
arXiv preprint arXiv:2510.13786 , year=
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms. arXiv preprint arXiv:2510.13786, 2025
-
[17]
Buy 4 REINFORCE samples, get a baseline for free!, 2019
Wouter Kool, Herke van Hoof, and Max Welling. Buy 4 REINFORCE samples, get a baseline for free!, 2019. URL https://openreview.net/forum?id=r1lgTGL5DE
2019
-
[18]
Reinforcement Learning from Human Feedback
Nathan Lambert. Reinforcement learning from human feedback. arXiv preprint arXiv:2504.12501, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. Advances in neural information processing systems, 35: 0 3843--3857, 2022
2022
-
[20]
Let's verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The twelfth international conference on learning representations, 2023
2023
-
[21]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, et al. Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl. Notion Blog, 3 0 (5), 2025
2025
-
[23]
Trajectory balance: Improved credit assignment in gflownets
Nikolay Malkin, Moksh Jain, Emmanuel Bengio, Chen Sun, and Yoshua Bengio. Trajectory balance: Improved credit assignment in gflownets. Advances in Neural Information Processing Systems, 35: 0 5955--5967, 2022
2022
-
[24]
Variational inference for monte carlo objectives
Andriy Mnih and Danilo Rezende. Variational inference for monte carlo objectives. In International Conference on Machine Learning, pp.\ 2188--2196. PMLR, 2016
2016
-
[25]
Asynchronous methods for deep reinforcement learning.arXiv preprint arXiv:1602.01783,
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning, 2016. URL https://arxiv.org/abs/1602.01783
- [26]
-
[27]
Correcting length bias in neural machine translation
Kenton Murray and David Chiang. Correcting length bias in neural machine translation. In Ond r ej Bojar, Rajen Chatterjee, Christian Federmann, Mark Fishel, Yvette Graham, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Philipp Koehn, Christof Monz, Matteo Negri, Aur \'e lie N \'e v \'e ol, Mariana Neves, Matt Post, Lucia Specia, Marco Turchi, and Kari...
-
[28]
Nemo rl: A scalable and efficient post-training library
NVIDIA. Nemo rl: A scalable and efficient post-training library. https://github.com/NVIDIA-NeMo/RL, 2025. GitHub repository
2025
-
[29]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022
work page internal anchor Pith review arXiv 2022
-
[30]
Eligibility traces for off-policy policy evaluation
Doina Precup, Richard S Sutton, and Satinder Singh. Eligibility traces for off-policy policy evaluation. 2000
2000
-
[31]
Q., Lo, A., Berrada, G., Lample, G., Rute, J., Barmentlo, J., Yadav, K., Khandelwal, K., Chandu, K
Abhinav Rastogi, Albert Q Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, Jason Rute, Joep Barmentlo, Karmesh Yadav, Kartik Khandelwal, Khyathi Raghavi Chandu, et al. Magistral. arXiv preprint arXiv:2506.10910, 2025
-
[32]
Composer 2 technical report.arXiv preprint arXiv:2603.24477, 2026
Cursor Research, Aaron Chan, Ahmed Shalaby, Alexander Wettig, Aman Sanger, Andrew Zhai, Anurag Ajay, Ashvin Nair, Charlie Snell, Chen Lu, et al. Composer 2 technical report. arXiv preprint arXiv:2603.24477, 2026
-
[33]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
arXiv preprint arXiv:2512.21852 , year=
Vedant Shah, Johan Obando-Ceron, Vineet Jain, Brian Bartoldson, Bhavya Kailkhura, Sarthak Mittal, Glen Berseth, Pablo Samuel Castro, Yoshua Bengio, Nikolay Malkin, et al. A comedy of estimators: On kl regularization in rl training of llms. arXiv preprint arXiv:2512.21852, 2025
-
[35]
Spurious rewards: Rethinking training signals in rlvr.arXiv preprint arXiv:2506.10947,
Rulin Shao, Shuyue Stella Li, Rui Xin, Scott Geng, Yiping Wang, Sewoong Oh, Simon Shaolei Du, Nathan Lambert, Sewon Min, Ranjay Krishna, et al. Spurious rewards: Rethinking training signals in rlvr. arXiv preprint arXiv:2506.10947, 2025
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
arXiv preprint arXiv:2506.09477 , year=
Yunhao Tang and Rémi Munos. On a few pitfalls in kl divergence gradient estimation for rl, 2025. URL https://arxiv.org/abs/2506.09477
-
[39]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, C Du, C Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms, 2025. URL https://arxiv. org/abs/2501.12599, 118, 2025 a
work page internal anchor Pith review arXiv 2025
-
[40]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review arXiv 2026
-
[41]
Ling Team, Anqi Shen, Baihui Li, Bin Hu, Bin Jing, Cai Chen, Chao Huang, Chao Zhang, Chaokun Yang, Cheng Lin, et al. Every step evolves: Scaling reinforcement learning for trillion-scale thinking model. arXiv preprint arXiv:2510.18855, 2025 b
-
[42]
Simple statistical gradient-following algorithms for connectionist reinforcement learning
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8 0 (3): 0 229--256, 1992
1992
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Yilin Yang, Liang Huang, and Mingbo Ma. Breaking the beam search curse: A study of (re-)scoring methods and stopping criteria for neural machine translation. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun ' ichi Tsujii (eds.), Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp.\ 3054--3059, Brussels, Belg...
-
[45]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
mh-llm: Fast metropolis-hastings sampler for llms
Max Zuo. mh-llm: Fast metropolis-hastings sampler for llms. https://github.com/maxzuo/mh-llm, 2024. GitHub repository
2024
-
[47]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[48]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[49]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[50]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.