Recognition: unknown
Learning to Reason with Insight for Informal Theorem Proving
Pith reviewed 2026-05-10 08:33 UTC · model grok-4.3
The pith
Training large language models on proofs broken into core techniques and sketches improves their performance on informal theorem proving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
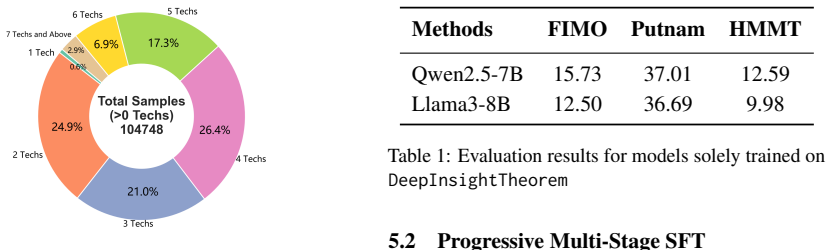
The authors argue that lack of insight is the primary bottleneck in informal theorem proving and address it by constructing the DeepInsightTheorem hierarchical dataset, which explicitly extracts core techniques and proof sketches alongside full proofs, then applying a Progressive Multi-Stage SFT strategy that guides models from basic proof writing to insightful reasoning, resulting in better performance on mathematical benchmarks.
What carries the argument
DeepInsightTheorem, a hierarchical dataset that breaks informal proofs into explicit core techniques, proof sketches, and complete proofs, together with the Progressive Multi-Stage SFT strategy that trains models progressively from basic writing to technique-aware reasoning.
If this is right
- Models trained this way outperform standard supervised fine-tuning on challenging mathematical benchmarks.
- Explicitly teaching core techniques enables better recognition and application when facing new problems.
- Informal theorem proving becomes more practical for large language models because it plays to their natural-language strengths.
- Progressive training stages support a gradual shift from basic skills to advanced insight application.
- The same insight extraction process can be scaled to larger sets of theorems as more data becomes available.
Where Pith is reading between the lines
- The same technique-extraction approach could be tested on non-mathematical reasoning tasks that also require identifying central steps.
- If the gains come from structured data rather than model size, smaller models might reach similar performance with this training method.
- Future checks could measure whether models apply the learned techniques to proofs in entirely new mathematical domains.
- The work leaves open whether the observed gains reflect deeper understanding or simply more efficient higher-level pattern matching.
Load-bearing premise
That the main difficulty for models is failing to spot the central proof methods and that training with those methods highlighted produces genuine skill rather than surface pattern matching.
What would settle it
Evaluating the trained model on a fresh collection of problems that require techniques absent from the training set and checking whether accuracy gains persist after matching the control model for total training data volume.
Figures







read the original abstract
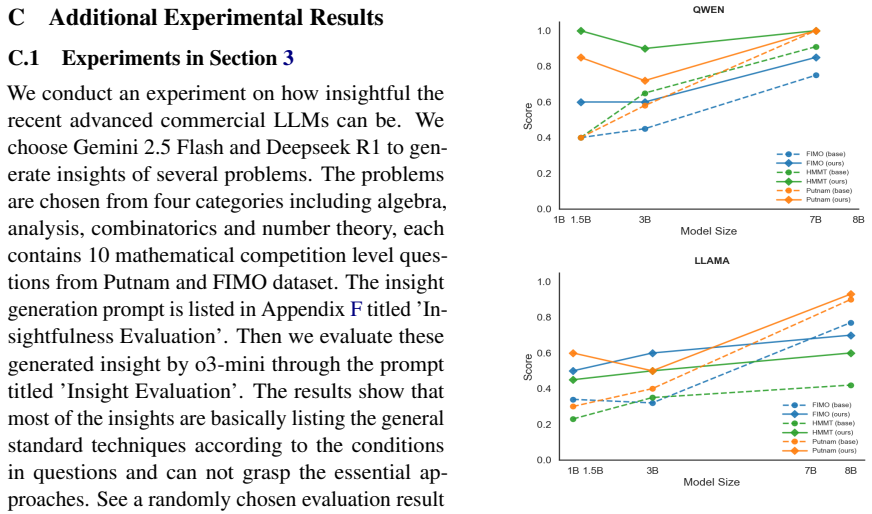
Although most of the automated theorem-proving approaches depend on formal proof systems, informal theorem proving can align better with large language models' (LLMs) strength in natural language processing. In this work, we identify a primary bottleneck in informal theorem proving as a lack of insight, namely the difficulty of recognizing the core techniques required to solve complex problems. To address this, we propose a novel framework designed to cultivate this essential reasoning skill and enable LLMs to perform insightful reasoning. We propose $\mathtt{DeepInsightTheorem}$, a hierarchical dataset that structures informal proofs by explicitly extracting core techniques and proof sketches alongside the final proof. To fully exploit this dataset, we design a Progressive Multi-Stage SFT strategy that mimics the human learning process, guiding the model from basic proof writing to insightful thinking. Our experiments on challenging mathematical benchmarks demonstrate that this insight-aware generation strategy significantly outperforms baselines. These results demonstrate that teaching models to identify and apply core techniques can substantially improve their mathematical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies lack of insight—specifically, difficulty recognizing core techniques for complex problems—as the primary bottleneck in informal theorem proving for LLMs. It introduces DeepInsightTheorem, a hierarchical dataset that explicitly extracts core techniques and proof sketches alongside full proofs, and a Progressive Multi-Stage SFT training strategy that guides models from basic proof writing to insightful reasoning. Experiments on challenging mathematical benchmarks are reported to show that this insight-aware approach significantly outperforms baselines, supporting the broader claim that teaching models to identify and apply core techniques substantially improves mathematical reasoning.
Significance. If the empirical gains are robust and the insight mechanism can be isolated from data-structure effects, the work offers a practical framework for cultivating structured reasoning in LLMs that aligns with human learning and could extend to other complex reasoning tasks. The hierarchical dataset construction and progressive training procedure are concrete, reproducible contributions that address a recognized limitation in current informal proving systems.
major comments (2)
- [Experiments] Experiments section: The central claim that the hierarchical extraction of core techniques plus progressive SFT produces genuine insight (rather than improved pattern matching on structured data) is load-bearing for the paper's contribution, yet no ablations are described that hold data volume, proof length, and training steps fixed while removing or randomizing the technique/sketch annotations. Without these controls, benchmark gains cannot be attributed to insight cultivation.
- [Abstract and §3] Abstract and §3 (Dataset/Method): The abstract asserts 'significant outperformance' and 'substantially improve their mathematical reasoning' but supplies no quantitative metrics, baseline descriptions, dataset statistics, or ablation results; the full manuscript does not appear to include the isolation experiments needed to support the weakest assumption that insight (vs. structured data exposure) is the operative factor.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction could more explicitly define 'insight' operationally (e.g., via measurable differences in proof structure or technique selection) to avoid conflation with general reasoning improvements.
- [Method] Notation for the Progressive Multi-Stage SFT stages is introduced without a clear diagram or pseudocode; a small table summarizing stage objectives, data subsets, and loss formulations would improve clarity.
Circularity Check
Empirical proposal with no self-referential derivation
full rationale
The paper introduces a new hierarchical dataset (DeepInsightTheorem) that extracts core techniques and proof sketches, paired with a Progressive Multi-Stage SFT training procedure. Claims rest on this novel data construction and training strategy plus benchmark experiments, without equations, fitted parameters, uniqueness theorems, or self-citations that reduce any result to prior inputs by construction. The argument is self-contained as an empirical intervention rather than a closed derivation loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can acquire insightful reasoning by training on proofs annotated with core techniques and proof sketches
Reference graph
Works this paper leans on
-
[1]
Formal theorem proving by rewarding llms to decompose proofs hierarchically.Preprint, arXiv:2411.01829. Google Gemini Team. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. Technical report, Google. Fabian Gloeckle, Jannis Limperg, Gabriel Synnaeve, and Amaury Hayat. 202...
-
[2]
Reasoning in reasoning: A hierarchical frame- work for (better and faster) neural theorem proving. InThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24. Ziyin Zhang, Jiahao Xu, Zhiwei He, Tian Liang, Qiuzhi Liu, Yansi Li, Linfeng Song, Zhenwen Liang, Zhu- osheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2025a. DEEPTHEOREM: Advanci...
-
[3]
Minif2f: a cross-system benchmark for for- mal olympiad-level mathematics. InInternational Conference on Learning Representations (ICLR). ArXiv:2109.00110. Pei Zhou, Jay Pujara, Xiang Ren, Xinyun Chen, Heng- Tze Cheng, Quoc V . Le, Ed H. Chi, Denny Zhou, Swaroop Mishra, and Huaixiu Steven Zheng. 2024. Self-discover: Large language models self-compose reas...
-
[4]
Use the monotonicity and divergence ofgto establish{X > x} ⊆ {g(X)≥g(x)}, implying P(X > x)≤P(g(X)≥g(x))
-
[5]
Apply Markov’s inequality to the nonnegative integrableg(X), yieldingg(x)P(X > x)≤ E[g(X)1 {g(X)≥g(x)} ]
-
[6]
Observe pointwise convergenceg(X)1 {g(X)≥g(x)} →0due tog(x)→ ∞, and dominate byg(X)
-
[7]
Invoke the Dominated Convergence Theorem to showE[g(X)1 {g(X)≥g(x)} ]→0
-
[8]
Concludelim x→∞ g(x)P(X > x) = 0via the squeeze theorem on0≤g(x)P(X > x)≤ E[g(X)1 {g(X)≥g(x)} ]. </sketch> <proof> Sincegis monotone nondecreasing, for anyx≥0, the conditionX > ximpliesg(X)≥g(x). This gives the event inclusion: {X > x} ⊆ {g(X)≥g(x)}, which, by monotonicity of probability, yields: P(X > x)≤P(g(X)≥g(x)). Asg(X)is nonnegative andE[g(X)]<∞, M...
-
[9]
Maximizing Data Utility
The distribution of each class of techniques is summarized in Figure 8. Maximizing Data Utility. A fundamental princi- ple of DeepInsightTheorem is its self-contained nature. The creation of the hierarchical structure (q,{t i}, s, p) is achieved solely through the analy- sis of the information already embedded within the original proofs. By doing so, we i...
-
[10]
Note that such idea can not vaguely hints without providing concrete methods and identifying the core non-trivial step
see if there exists an idea in this insight that is highly key to the solution, which in general is likely to be found or realized after several thinking steps, or the other steps in the solution are far easier after dealing with this core idea. Note that such idea can not vaguely hints without providing concrete methods and identifying the core non-trivi...
-
[11]
Check if the idea gives the precise techniques key and adapted particularly to the question
see if the core ideas described in the insight is accurate enough. Check if the idea gives the precise techniques key and adapted particularly to the question. It does not need to be containing details but accurately describe mentioned techniques. And hence determine whether the idea is a simple scratch or an accurate expression
-
[12]
check whether the question can be solved by filling basic mathematical and logical deductions ONLY under the core techniques in the insight
see if the core techniques mentioned in this insight are all core techniques for the question. check whether the question can be solved by filling basic mathematical and logical deductions ONLY under the core techniques in the insight. And hence determine whether the insight is comprehensive or incomplete. –output: For 1, if all ideas in the insight are n...
-
[13]
’deep identification’/ ’shallow quick guess’/’mixed’
-
[14]
’detailed expression’/’simple scratch’/’mixed’
-
[15]
’comprehensive’/’incomplete’/’mixed’ 18 Data Construction Analyze the mathematical problem and solution below: Problem: {question} Solution: {response} Perform these tasks:
-
[16]
Note that the core mathematical techniques are not those basic logic deductions
First identify 1-3 core mathematical techniques used in the solution by considering if there are some specific constructions, theorem or existed results calling and smart mathematical transformations, where the smart transformation may not be known results and are subtle and hard to note. Note that the core mathematical techniques are not those basic logi...
-
[17]
\\}}$\\end{{enumerate}}’ 19 Data Construction (cont’d) [t] 3
Create a proof sketch integrating these techniques analyzed from task 1, which serves as a high-level proof organization: - Format: Numbered steps in LaTeX - Each step: 1 sentence with key mathematical reasoning - Include essential formulas in math mode - Example: ’\\begin{{enumerate}}\\item Assume $P$ is countable: $P = \\{{x_1, x_2, \\. . . \\}}$\\end{{...
-
[18]
Output: - mathematical techniques: string (LaTeX formatted) - proof sketch: string (LaTeX enumerated steps) - solution: string (LaTeX formatted) The mathematical techniques are enclosed within <tech></tech>, the proof sketch is enclosed within <sketch></sketch> and the solution is enclosed within <proof></proof>, respectively, i.e., <tech> mathematical te...
-
[19]
Analyze the proof step by step
-
[20]
Flag any logical errors
For each criterion: - Logical Validity: Check if each step follows logically from the previous one. Flag any logical errors. - Completeness: Verify if all necessary cases and steps are included to prove the theorem. - Clarity: Assess if the proof is clear, unambiguous, and well-explained
-
[21]
Assign a sub-score (0 to 1) for each criterion and compute the total score using the weights: (0.4×validity) + (0.3×completeness) + (0.3× clarity)
-
[22]
validity
Provide a brief explanation (2-3 sentences) summarizing any errors or issues and justifying the score. Output: - Your total score: float; - Your sub-scores and corresponding brief explanation: - Sub-score: float; - Brief explanation: string (LaTeX formatted) The total score is enclosed in <score></score>, and the sub-scores with corresponding explanation ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.