Recognition: unknown
FineCog-Nav: Integrating Fine-grained Cognitive Modules for Zero-shot Multimodal UAV Navigation
Pith reviewed 2026-05-10 08:09 UTC · model grok-4.3
The pith
Dividing UAV navigation into fine-grained cognitive modules improves zero-shot instruction following in complex environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FineCog-Nav organizes the navigation task into seven fine-grained cognitive modules inspired by human cognition. Each module employs a moderate-sized foundation model guided by role-specific prompts and follows defined input-output protocols to collaborate with other modules. This design yields stronger results than standard zero-shot baselines on measures of instruction adherence, long-horizon planning, and performance in environments not encountered before, as tested on a new set of 300 curated trajectories.
What carries the argument
The top-down framework of fine-grained cognitive modules that each handle one aspect of navigation through role-specific prompts and structured protocols.
If this is right
- Navigation agents can better manage ambiguous multi-step instructions by processing them through dedicated language and reasoning modules.
- Long-horizon tasks benefit from explicit memory and attention modules that preserve information across extended sequences.
- Generalization to unseen aerial environments increases when each module focuses narrowly on its cognitive function rather than handling the full task.
- Interpretability rises because the output of each module can be examined to trace how decisions are formed.
Where Pith is reading between the lines
- If the protocols between modules are what enable success, the same pattern of structured handoffs could improve other sequential AI systems such as dialogue agents or planning robots.
- Using moderate models per module may allow deployment on hardware with lower memory than required for a single massive model.
- The new benchmark with refined instructions and visual endpoints could be used to diagnose exactly which cognitive steps fail in current navigation systems.
- Extending the imagination module to simulate future views might further reduce errors in path selection.
Load-bearing premise
That the specific division into these cognitive modules combined with role-specific prompts and protocols is what causes the performance improvement rather than simply using several models together.
What would settle it
A test in which the modules are merged into one unified prompt applied across the same collection of moderate-sized models, and the resulting system performs equally well or better on the AerialVLN-Fine benchmark for unseen environments and long trajectories.
Figures















read the original abstract
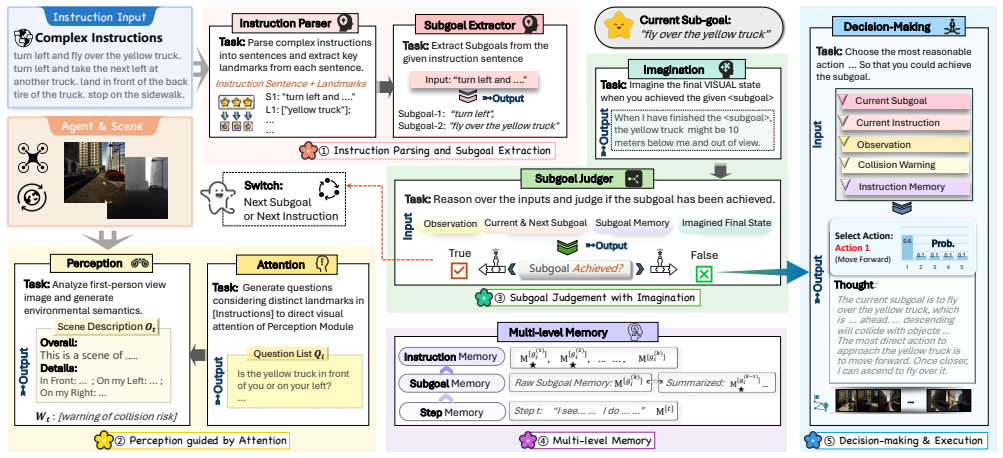
UAV vision-language navigation (VLN) requires an agent to navigate complex 3D environments from an egocentric perspective while following ambiguous multi-step instructions over long horizons. Existing zero-shot methods remain limited, as they often rely on large base models, generic prompts, and loosely coordinated modules. In this work, we propose FineCog-Nav, a top-down framework inspired by human cognition that organizes navigation into fine-grained modules for language processing, perception, attention, memory, imagination, reasoning, and decision-making. Each module is driven by a moderate-sized foundation model with role-specific prompts and structured input-output protocols, enabling effective collaboration and improved interpretability. To support fine-grained evaluation, we construct AerialVLN-Fine, a curated benchmark of 300 trajectories derived from AerialVLN, with sentence-level instruction-trajectory alignment and refined instructions containing explicit visual endpoints and landmark references. Experiments show that FineCog-Nav consistently outperforms zero-shot baselines in instruction adherence, long-horizon planning, and generalization to unseen environments. These results suggest the effectiveness of fine-grained cognitive modularization for zero-shot aerial navigation. Project page: https://smartdianlab.github.io/projects-FineCogNav.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FineCog-Nav, a top-down framework for zero-shot multimodal UAV vision-language navigation that decomposes the task into seven fine-grained cognitive modules (language processing, perception, attention, memory, imagination, reasoning, and decision-making). Each module uses a moderate-sized foundation model with role-specific prompts and structured input-output protocols to enable collaboration and interpretability. The work also introduces AerialVLN-Fine, a benchmark of 300 trajectories derived from AerialVLN with sentence-level instruction-trajectory alignment and refined instructions containing explicit visual endpoints. Experiments are reported to show consistent outperformance over zero-shot baselines in instruction adherence, long-horizon planning, and generalization to unseen environments.
Significance. If the central empirical claims hold and the modular decomposition is isolated as the causal factor, the work could advance zero-shot VLN by offering a more interpretable alternative to generic large-model prompting. The fine-grained benchmark is a constructive addition for evaluation. However, the significance is tempered by the absence of evidence that the reported gains arise specifically from the cognitive modularization rather than from confounding factors such as prompt detail, number of inference steps, or total compute.
major comments (2)
- [Experiments] Experiments section: No ablation is described that isolates the contribution of the fine-grained modular decomposition (role-specific prompts plus structured I/O protocols) from a single unified model baseline given an equivalent total prompt budget or a collapsed multi-module prompt. Without this control, the headline claim that improvements in instruction adherence and long-horizon planning stem from cognitive modularization remains unsupported.
- [Results] Results and evaluation: The abstract asserts consistent outperformance, yet the manuscript provides no quantitative metrics, baseline implementation details, statistical tests, or per-module contribution breakdowns. This absence prevents assessment of effect sizes and reliability of the generalization claims on AerialVLN-Fine.
minor comments (1)
- [Implementation Details] Ensure that all experimental hyperparameters, model sizes, and exact prompt templates are reported in the main text or supplementary material to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: No ablation is described that isolates the contribution of the fine-grained modular decomposition (role-specific prompts plus structured I/O protocols) from a single unified model baseline given an equivalent total prompt budget or a collapsed multi-module prompt. Without this control, the headline claim that improvements in instruction adherence and long-horizon planning stem from cognitive modularization remains unsupported.
Authors: We agree that an ablation isolating the modular decomposition is necessary to rule out confounders such as prompt detail or total inference steps. In the revised manuscript we will add a controlled ablation: a single unified foundation model given a collapsed prompt that concatenates all seven cognitive roles while matching total token budget and number of model calls. Comparative results on instruction adherence and long-horizon metrics will be reported to quantify the benefit attributable to the fine-grained structure and structured I/O protocols. revision: yes
-
Referee: [Results] Results and evaluation: The abstract asserts consistent outperformance, yet the manuscript provides no quantitative metrics, baseline implementation details, statistical tests, or per-module contribution breakdowns. This absence prevents assessment of effect sizes and reliability of the generalization claims on AerialVLN-Fine.
Authors: We acknowledge that the current presentation of results can be improved for clarity and completeness. Although the manuscript contains experimental comparisons, we will revise the Experiments section to include: (i) explicit numerical metrics and tables with success rates, path efficiency, and generalization scores; (ii) full baseline implementation details (model sizes, prompt templates, and inference settings); (iii) statistical significance tests; and (iv) a per-module contribution breakdown. These additions will enable direct evaluation of effect sizes and reliability. revision: yes
Circularity Check
No circularity: empirical framework validated by direct comparison to baselines
full rationale
The paper introduces FineCog-Nav as a modular decomposition of navigation into role-specific cognitive modules, each using moderate-sized models with structured prompts. It constructs AerialVLN-Fine as a new benchmark and reports empirical outperformance over zero-shot baselines in instruction adherence and planning. No equations, derivations, fitted parameters, or self-referential definitions appear. Claims rest on experimental results rather than any reduction of outputs to inputs by construction. Self-citations, if present, are not load-bearing for the central thesis, which remains independently testable via the described benchmarks and comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 27
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S¨ underhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683,
-
[3]
Hengxing Cai, Jinhan Dong, Jingjun Tan, Jingcheng Deng, Sihang Li, Zhifeng Gao, Haidong Wang, Zicheng Su, Agachai Sumalee, and Renxin Zhong. Flightgpt: Towards generaliz- able and interpretable uav vision-and-language navigation with vision-language models.ArXiv, abs/2505.12835, 2025. 2
-
[4]
Peihao Chen, Xinyu Sun, Hongyan Zhi, Runhao Zeng, Thomas H Li, Gaowen Liu, Mingkui Tan, and Chuang Gan. 𝑎2 nav: Action-aware zero-shot robot navigation by exploit- ing vision-and-language ability of foundation models.arXiv preprint arXiv:2308.07997, 2023. 1
-
[5]
History aware multimodal transformer for vision- and-language navigation.Advances in neural information processing systems, 34:5834–5847, 2021
Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision- and-language navigation.Advances in neural information processing systems, 34:5834–5847, 2021. 2
2021
-
[6]
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act lo- cal: Dual-scale graph transformer for vision-and-language navigation.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16516–16526, 2022. 2
2022
-
[7]
Sigurdsson, Robinson Piramuthu, Jesse Thomason, and Gaurav S
Vishnu Sashank Dorbala, Gunnar A. Sigurdsson, Robinson Piramuthu, Jesse Thomason, and Gaurav S. Sukhatme. Clip- nav: Using clip for zero-shot vision-and-language navigation. ArXiv, abs/2211.16649, 2022. 2
-
[8]
Chen, Tongzhou Jiang, Chun ni Zhou, Yi Zhang, and Xin Eric Wang
Yue Fan, Winson X. Chen, Tongzhou Jiang, Chun ni Zhou, Yi Zhang, and Xin Eric Wang. Aerial vision-and-dialog naviga- tion. InAnnual Meeting of the Association for Computational Linguistics, 2022. 2
2022
-
[9]
Speaker-follower models for vision-and-language navigation
Daniel Fried, Ronghang Hu, Volkan Cirik, Anna Rohrbach, Jacob Andreas, Louis-Philippe Morency, Taylor Berg- Kirkpatrick, Kate Saenko, Dan Klein, and Trevor Darrell. Speaker-follower models for vision-and-language navigation. ArXiv, abs/1806.02724, 2018. 2
-
[10]
Octonav: Towards generalist embodied navigation.arXiv preprint arXiv:2506.09839, 2025
Chen Gao, Liankai Jin, Xingyu Peng, Jiazhao Zhang, Yue Deng, Annan Li, He Wang, and Si Liu. Octonav: Towards generalist embodied navigation.arXiv preprint arXiv:2506.09839, 2025. 2
-
[11]
Yunpeng Gao, Zhigang Wang, Linglin Jing, Dong Wang, Xuelong Li, and Bin Zhao. Aerial vision-and-language nav- igation via semantic-topo-metric representation guided llm reasoning.ArXiv, abs/2410.08500, 2024. 1, 2, 5, 20
-
[12]
Openfly: A versatile toolchain and large-scale benchmark for aerial vision-language naviga- tion.arXiv e-prints, pages arXiv–2502, 2025
Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, Yiwen Tang, Yuhang Tang, Shuai Liang, Songyi Zhu, Ziqin Xiong, Yifei Su, Xinyi Ye, Jianan Li, Yan Ding, and Xuelong Li. Openfly: A versatile toolchain and large-scale benchmark for aerial vision-language naviga- tion.arXiv e-pri...
2025
-
[13]
Girshick
Ross B. Girshick. Fast r-cnn. InProceedings of the IEEE international conference on computer vision, pages 1440– 1448, 2015. 27
2015
-
[14]
Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. Towards learning a generic agent for vision- and-language navigation via pre-training.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13134–13143, 2020. 2
2020
-
[15]
See, point, fly: A learning- free vlm framework for universal unmanned aerial navigation
Chih Yao Hu, Yang-Sen Lin, Yuna Lee, Chih-Hai Su, Jie- Ying Lee, Shr-Ruei Tsai, Chin-Yang Lin, Kuan-Wen Chen, Tsung-Wei Ke, and Yu-Lun Liu. See, point, fly: A learning- free vlm framework for universal unmanned aerial navigation. InConference on Robot Learning, pages 4697–4708. PMLR,
-
[16]
Vihan Jain, Gabriel Magalhaes, Alexander Ku, Ashish Vaswani, Eugene Ie, and Jason Baldridge. Stay on the path: Instruction fidelity in vision-and-language navigation.arXiv preprint arXiv:1905.12255, 2019. 2
-
[17]
Room-across-room: Multilingual vision- and-language navigation with dense spatiotemporal ground- ing
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. Room-across-room: Multilingual vision- and-language navigation with dense spatiotemporal ground- ing. InConference on Empirical Methods in Natural Lan- guage Processing, 2020. 2
2020
-
[18]
Jungdae Lee, Taiki Miyanishi, Shuhei Kurita, Koya Sakamoto, Daich Azuma, Yutaka Matsuo, and Nakamasa In- oue. Citynav: Language-goal aerial navigation dataset with geographic information.ArXiv, abs/2406.14240, 2024. 2
-
[19]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInter- national Conference on Machine Learning, 2023. 27
2023
-
[20]
Skyvln: Vision-and-language navigation and nmpc control for uavs in urban environments, 2025
Tianshun Li, Tianyi Huai, Zhen Li, Yichun Gao, Haoang Li, and Xinhu Zheng. Skyvln: Vision-and-language navigation and nmpc control for uavs in urban environments, 2025. 2
2025
-
[21]
Aerialvln: Vision-and-language navigation for uavs
Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Yan- ning Zhang, and Qi Wu. Aerialvln: Vision-and-language navigation for uavs. In2023 IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 15338–15348,
-
[22]
Youzhi Liu, Fanglong Yao, Yuanchang Yue, Guangluan Xu, Xian Sun, and Kun Fu. Navagent: Multi-scale urban street view fusion for UA V embodied vision-and-language naviga- tion.CoRR, abs/2411.08579, 2024. 2
-
[23]
Dis- cuss before moving: Visual language navigation via multi- expert discussions, 2023
Yuxing Long, Xiaoqi Li, Wenzhe Cai, and Hao Dong. Dis- cuss before moving: Visual language navigation via multi- expert discussions, 2023. 1, 29 9
2023
-
[24]
Instructnav: Zero-shot system for generic instruction navigation in unexplored environment, 2024
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment, 2024. 2
2024
-
[25]
General evaluation for in- struction conditioned navigation using dynamic time warp- ing
Gabriel Ilharco Magalhaes, Vihan Jain, Alexander Ku, Eu- gene Ie, and Jason Baldridge. General evaluation for in- struction conditioned navigation using dynamic time warp- ing. InNeurIPS Visually Grounded Interaction and Language (ViGIL) Workshop, 2019. 5
2019
-
[26]
Mapping in- structions to actions in 3d environments with visual goal prediction
Dipendra Misra, Andrew Bennett, Valts Blukis, Eyvind Niklasson, Max Shatkhin, and Yoav Artzi. Mapping in- structions to actions in 3d environments with visual goal prediction. InConference on Empirical Methods in Natural Language Processing, 2018. 2
2018
-
[27]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339– 9347, 2019. 2
2019
-
[28]
Uav-vln: End-to-end vision language guided navigation for uavs.ArXiv, abs/2504.21432, 2025
Pranav Saxena, Nishant Raghuvanshi, and Neena Goveas. Uav-vln: End-to-end vision language guided navigation for uavs.ArXiv, abs/2504.21432, 2025. 2
-
[29]
Thomson/Wadsworth Belmont, CA, 2006
Robert J Sternberg and Karin Sternberg.Cognitive Psychol- ogy. Thomson/Wadsworth Belmont, CA, 2006. 3
2006
-
[30]
Xiangyu Wang, Donglin Yang, Ziqin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hongsheng Li, Yue Liao, and Si Liu. Towards realistic uav vision-language navigation: Platform, benchmark, and methodology.ArXiv, abs/2410.07087, 2024. 1, 2, 4, 7
-
[31]
Uav-flow colosseo: A real-world benchmark for flying-on-a-word uav imitation learning,
Xiangyu Wang, Donglin Yang, Yue Liao, Wenhao Zheng, Bin Dai, Hongsheng Li, Si Liu, et al. Uav-flow colosseo: A real-world benchmark for flying-on-a-word uav imitation learning.arXiv preprint arXiv:2505.15725, 2025. 2
-
[32]
Gridmm: Grid memory map for vision-and- language navigation.2023 IEEE/CVF International Confer- ence on Computer Vision, pages 15579–15590, 2023
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Gridmm: Grid memory map for vision-and- language navigation.2023 IEEE/CVF International Confer- ence on Computer Vision, pages 15579–15590, 2023. 2
2023
-
[33]
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Han- qing Wang, Yilun Chen, Xihui Liu, and Jiangmiao Pang. Streamvln: Streaming vision-and-language navigation via slowfast context modeling.ArXiv, abs/2507.05240, 2025. 2
-
[34]
V oronav: V oronoi-based zero-shot object navigation with large language model,
Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shang- hang Zhang, and Chang Liu. Voronav: Voronoi-based zero- shot object navigation with large language model.ArXiv, abs/2401.02695, 2024. 2
-
[35]
Aeroduo: Aerial duo for uav-based vision and language navigation.Proceed- ings of the 33rd ACM International Conference on Multime- dia, 2025
Ruipu Wu, Yige Zhang, Jinyu Chen, Linjiang Huang, Shifeng Zhang, Xu Zhou, Liang Wang, and Si Liu. Aeroduo: Aerial duo for uav-based vision and language navigation.Proceed- ings of the 33rd ACM International Conference on Multime- dia, 2025. 2
2025
-
[36]
Uav-on: A benchmark for open-world object goal navigation with aerial agents
Jianqiang Xiao, Yuexuan Sun, Yixin Shao, Boxi Gan, Rongqiang Liu, Yanjin Wu, Weili Guan, and Xiang Deng. Uav-on: A benchmark for open-world object goal navigation with aerial agents. InProceedings of the 33rd ACM Interna- tional Conference on Multimedia, 2025. 2
2025
-
[37]
Haotian Xu, Yue Hu, Chen Gao, Zhengqiu Zhu, Yong Zhao, Yong Li, and Quanjun Yin. Geonav: Empowering mllms with explicit geospatial reasoning abilities for language-goal aerial navigation.ArXiv, abs/2504.09587, 2025. 2
-
[38]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Aeroverse: Uav-agent benchmark suite for sim- ulating, pre-training, finetuning, and evaluating aerospace embodied world models, 2024
Fanglong Yao, Yuanchang Yue, Youzhi Liu, Xian Sun, and Kun Fu. Aeroverse: Uav-agent benchmark suite for sim- ulating, pre-training, finetuning, and evaluating aerospace embodied world models, 2024. 2, 4
2024
-
[40]
Jianlin Ye, Savvas Papaioannou, and Panayiotis S. Kolios. Vlm-rrt: Vision language model guided rrt search for au- tonomous uav navigation.2025 International Conference on Unmanned Aircraft Systems (ICUAS), pages 633–640, 2025. 2
2025
-
[41]
L3mvn: Leveraging large language models for visual target naviga- tion
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. L3mvn: Leveraging large language models for visual target naviga- tion. In2023 IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS), 2023. 2
2023
-
[42]
Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, and Xing Wei. Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation.arXiv preprint arXiv:2509.22548, 2025. 2
-
[43]
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024. 2
-
[44]
Navid: Video-based vlm plans the next step for vision-and-language navigation,
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and Wang He. Navid: Video-based vlm plans the next step for vision-and-language navigation.ArXiv, abs/2402.15852,
-
[45]
Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, Yuxin Fan, Wenjun Li, Zhibo Chen, Fei Gao, Qi Wu, Zhizheng Zhang, and He Wang. Embodied navigation foundation model.ArXiv, abs/2509.12129, 2025. 2, 7
-
[46]
Weichen Zhang, Chen Gao, Shiquan Yu, Ruiying Peng, Baining Zhao, Qian Zhang, Jinqiang Cui, Xinlei Chen, and Yong Li. Citynavagent: Aerial vision-and-language naviga- tion with hierarchical semantic planning and global memory. arXiv preprint arXiv:2505.05622, 2025. 1, 2
-
[47]
Xinyuan Zhang, Yonglin Tian, Fei Lin, Yue Liu, Jing Ma, Korn’elia S’ara Szatm’ary, and Fei-Yue Wang. Logisticsvln: Vision-language navigation for low-altitude terminal delivery based on agentic uavs.ArXiv, abs/2505.03460, 2025. 2
-
[48]
Recognize anything: A strong image tagging model.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1724–1732, 2023
Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, 10 Yaqian Li, Siyi Liu, Yandong Guo, and Lei Zhang. Recognize anything: A strong image tagging model.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1724–1732, 2023. 29
2024
-
[49]
Yuhang Zhang, Haosheng Yu, Jiaping Xiao, and Mir Feroskhan. Grounded vision-language navigation for uavs with open-vocabulary goal understanding.ArXiv, abs/2506.10756, 2025. 2
-
[50]
Linqing Zhong, Chen Gao, Zihan Ding, Yue Liao, Huimin Ma, Shifeng Zhang, Xu Zhou, and Si Liu. Topv-nav: Unlock- ing the top-view spatial reasoning potential of mllm for zero- shot object navigation.arXiv preprint arXiv:2411.16425,
-
[51]
Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models. InAAAI Conference on Artificial Intelligence,
-
[52]
Navgpt-2: Unleashing navigational reasoning capability for large vision-language models
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, and Qi Wu. Navgpt-2: Unleashing navigational reasoning capability for large vision-language models. InEuropean Conference on Computer Vision, pages 260–278. Springer,
-
[53]
Esc: ex- ploration with soft commonsense constraints for zero-shot object navigation
Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. Esc: ex- ploration with soft commonsense constraints for zero-shot object navigation. InProceedings of the 40th International Conference on Machine Learning. JMLR.org, 2023. 2 11 FineCog-Nav: Integrating Fine-grained Cognitive Modules for Zero-shot Multimodal...
2023
-
[54]
Analysis of Issues in AerialVLN Dataset
Dataset Details 12 7.1. Analysis of Issues in AerialVLN Dataset . . 12 7.2. Detailed Construction Process . . . . . . . . 12 7.3. Dataset Statistics . . . . . . . . . . . . . . . 14
-
[55]
Demo Video
More Analysis 15 8.1. Demo Video . . . . . . . . . . . . . . . . . 15 8.2. Qualitative Comparison with Baselines . . . 15 8.3. Quantitative Analysis of Ablations . . . . . . 16 8.4. Qualitative Analysis of Ablations . . . . . . 17
-
[56]
Design of the Human Study Process
Human Study Details 19 9.1. Design of the Human Study Process . . . . . 19 9.2. Analysis of Human Study Results . . . . . . 20 10 . More Evaluations 21 10.1 . Controlled Evaluation . . . . . . . . . . . . 21 10.2 . Generalization Evaluation . . . . . . . . . . 22 10.3 . Efficiency Evaluation . . . . . . . . . . . . . 22 10.4 . Ablation of Collision Warnin...
-
[57]
building
Dataset Details 7.1. Analysis of Issues in AerialVLN Dataset While AerialVLN serves as a challenging and milestone benchmark for UA V VLN, we have observed a substan- tial proportion of flawed data samples during experimental analysis. To systematically analyze these issues, we ran- domly sampled 200 trajectory-instruction pairs from the AerialVLN-S subse...
-
[58]
Fly forward to the roadblock and turn back to the bridge
More Analysis 8.1. Demo Video To provide a more comprehensive and intuitive understand- ing of the navigation process, we additionally include a demonstration video in the supplementary material, to which we kindly refer interested readers for further insight. In this demo, we showcase not only the full navigation trajectory of our proposedFineCog-Nav, bu...
-
[59]
UAV VLN (Drone Vision-Language Navigation) requires drones to autonomously navigate in a 3D continuous space from a first-person perspective based on natural language instructions
Human Study Details In this section, we first present the detailed design of the human study questionnaire, followed by correlation and sig- nificance analyses of the human study results. 9.1. Design of the Human Study Process The questionnaire consists of three parts: an introduction page, ten evaluation pages, and a farewell page. Below, we present the ...
-
[60]
Controlled Evaluation See, Point, Fly (SPF)[15] is a zero-shot UA V-VLN frame- work, which shows high success rates in their paper
More Evaluations 10.1. Controlled Evaluation See, Point, Fly (SPF)[15] is a zero-shot UA V-VLN frame- work, which shows high success rates in their paper. How- ever, their evaluation is limited to self-constructed tasks that 21 are nearly saturated (success rates of 90–100%), offering little room for meaningful comparison. In contrast, our benchmark encom...
-
[61]
" if_check_collision(depth_img, 1): risks +=
Detailed Prompts for BaseModel In designing the Basemodel, we retained only the most basic and minimal prompt to minimize performance gains from prompt engineering. Specifically, the Basemodel consists of two modules: Perception, responsible for scene understand- ing, and Action, responsible for decision-making. 11.1. Perception Perception Describe the im...
-
[62]
These modifications mainly include:
Detailed Prompts for Framework Baselines Since most existing zero-shot methods are designed for dis- crete ground-level navigation, we made specific adjustments to each method to adapt them to the aerial VLN setting. These modifications mainly include:
-
[63]
Replacing all original outputs designed to select away- pointwithactionselection from a predefined set of UA V- executable commands, including ascend, descend, turn left, turn right, move left, and move right
-
[64]
The modified versions of the baseline codes will be released 26 as open-source
Replacing all terms likeindoorandvehiclein the prompts withoutdoorandUAV, respectively. The modified versions of the baseline codes will be released 26 as open-source. We provide the specific modifications made for each baseline method. All deleted content from the original prompts is highlighted in light gray, while the added modifications are marked in ...
-
[65]
In our adaptation, we replace GPT-4 with the LLM defined in our setup, BLIP-2 with our selected VLM, and convert its discrete waypoint output to UA V-compatible action outputs
to generate scene descriptions, GPT-4 [1] for navigation reasoning, and GPT-3.5-turbo for history management. In our adaptation, we replace GPT-4 with the LLM defined in our setup, BLIP-2 with our selected VLM, and convert its discrete waypoint output to UA V-compatible action outputs. We want to highlight that NavGPT does not use standalone prompts to ob...
-
[66]
- There is a small, cylindrical object (possibly a barrel or a container) placed near the center-right of the foreground
**Foreground:** - The ground is a flat, smooth, concrete surface, likely a rooftop or a paved area. - There is a small, cylindrical object (possibly a barrel or a container) placed near the center-right of the foreground. It is dark in color and appears to be made of metal or a similar material
-
[67]
The wall is solid and appears to be part of a building or structure
**Left Side:** - A tall, red brick wall runs vertically along the left side of the scene. The wall is solid and appears to be part of a building or structure. - The wall extends from the foreground into the background, creating a boundary on the left side of the scene
-
[68]
- The right side is less prominent compared to the left, and the structure is not fully visible
**Right Side:** - On the right side, there is a partial view of another structure or wall, which appears to be made of a different material (possibly metal or concrete) and is painted in a dark color. - The right side is less prominent compared to the left, and the structure is not fully visible
-
[69]
The tree is relatively large and occupies a significant portion of the background on the right side
**Background:** - Beyond the wall on the left, there is a tree with green foliage. The tree is relatively large and occupies a significant portion of the background on the right side. - In the far background, there is a power line structure (a tall electrical tower) visible, with multiple power lines running horizontally across the scene. The lines stretc...
-
[70]
The path appears clear, but the cylindrical object might be an obstacle if you need to navigate around it
**Forward (Straight Ahead):** - Moving forward would take you along the concrete surface, away from the viewer’s perspective. The path appears clear, but the cylindrical object might be an obstacle if you need to navigate around it
-
[71]
The wall is a solid barrier, so navigating to the left would require staying close to the wall or finding a way around it
**Left:** - Moving left would bring you closer to the red brick wall. The wall is a solid barrier, so navigating to the left would require staying close to the wall or finding a way around it
-
[72]
The area appears open, but the partial structure might limit movement in that direction
**Right:** - Moving right would take you toward the dark structure on the right side. The area appears open, but the partial structure might limit movement in that direction
-
[73]
### **Obstacles:** - The **cylindrical object** in the foreground could be an obstacle if precise navigation is required
**Backward:** - Moving backward would take you away from the scene, back toward the origin point of the viewer. ### **Obstacles:** - The **cylindrical object** in the foreground could be an obstacle if precise navigation is required. - The **red brick wall** on the left side is a solid barrier that would need to be navigated around if moving left is neces...
-
[74]
action step 2 ... Action plan: Get Scene Prompt Please describe the current outdoor scene as detailed as possible, including the objects you can see, their relative positions, the layout of the scene, and the possible directions that can be navigated. Also, point out any obstacles and landmarks that might be helpful for navigation. Action Make Prompt You ...
-
[75]
evaluate the history and observation to decide which step of action plan you are at
-
[76]
Each navigable viewpoint has a unique ID, you should only answer the ID action in the Final An- swer
choose one viewpoint from the navigable view- points the next action from the action list. Each navigable viewpoint has a unique ID, you should only answer the ID action in the Final An- swer. —- Starting below, you should strictly follow this for- mat: History: the history of previous steps you have taken Observation: the current observation of the envir...
-
[77]
Evaluate the new observation and history
-
[78]
Update the history with the previous action and the new observation. History:{history} Previous action:{previous action} Observation:{observation} Update history with the new observation: Back Trace Prompt You are an agent following an action plan to navi- gation in indoor outdoor environment. 28 NavGPT Prompt You are currently at an intermediate step of ...
-
[79]
For clarity, each module is highlighted using the corresponding background color from the pipeline diagram
Detailed Prompts for FineCog-Nav We follow the order of module descriptions in Figure 2 of the main text to present our detailed prompt designs. For clarity, each module is highlighted using the corresponding background color from the pipeline diagram. 13.1. Instruction Parser Instruction Parser decomposes the long, complex instruction into a sequence of ...
-
[80]
SENTENCE SEGMENTATION - Split input text into individual sentences using periods as separators - Preserve original wording including leading conjunctions (e.g., “and...”) - Maintain original capitalization and spacing
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.