Recognition: 1 theorem link
· Lean TheoremStressWeb: A Diagnostic Benchmark for Web Agent Robustness under Realistic Interaction Variability
Pith reviewed 2026-05-14 23:28 UTC · model grok-4.3
The pith
StressWeb shows that web agents lose substantial performance when layouts shift or interactions are disrupted, unlike their results on clean tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
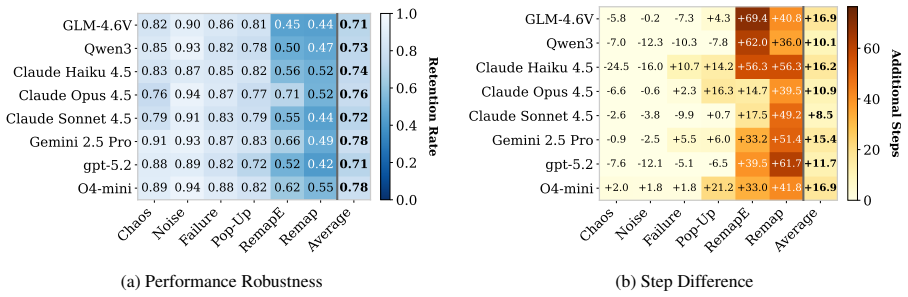
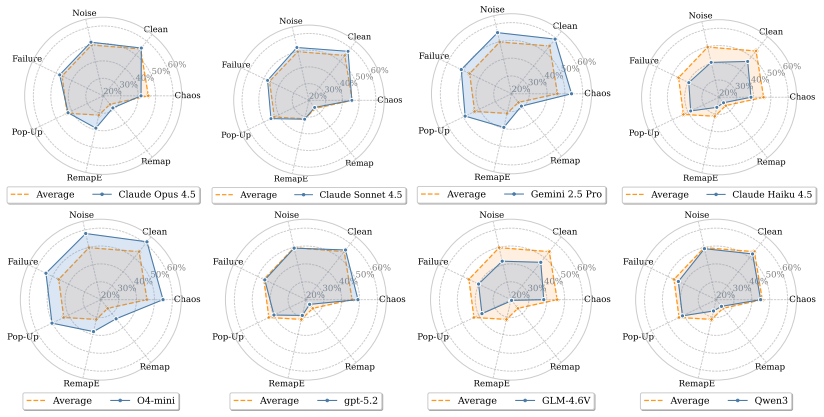
StressWeb constructs clean reference web environments and then applies structured perturbations that emulate interaction variability, allowing direct before-and-after comparison of agent performance. This stress-based approach exposes failure modes and robustness gaps in state-of-the-art multimodal web agents that remain hidden under conventional stable evaluation conditions.
What carries the argument
Structured, controllable perturbations (layout shifts, altered interaction semantics, execution disruptions) applied to clean baseline web workflows, which enable systematic diagnosis by comparing agent behavior across matched clean and stressed settings.
If this is right
- Agents that succeed on clean benchmarks still show large performance drops under the introduced perturbations.
- The benchmark framework supports targeted diagnosis of which types of variability cause which failures.
- Stress evaluation provides a stricter test of whether agents are ready for realistic web conditions.
- Current evaluation practices that rely only on stable settings systematically overestimate robustness.
- The method can be extended by adding further perturbation types while keeping the clean baselines fixed.
Where Pith is reading between the lines
- Training regimes that include similar controlled variability during development could close some of the observed gaps.
- The same stress-comparison approach might be useful for diagnosing robustness in non-web agent domains such as mobile or desktop interfaces.
- If the gaps persist across many agent architectures, it points to a general limitation in how current models handle dynamic page changes.
- The benchmark could serve as a standard addition to existing web agent leaderboards to track progress on robustness separately from raw task success.
Load-bearing premise
The specific perturbations chosen accurately represent the interaction variability that web agents encounter in real use.
What would settle it
If state-of-the-art agents maintain nearly the same task success rates on the perturbed versions of the environments as they do on the clean baselines, the claimed robustness gaps would not hold.
Figures







read the original abstract
Large language model-based web agents have demonstrated strong performance on realistic web interaction tasks. However, existing evaluations are predominantly conducted under relatively stable and well-behaved interaction conditions, which may overestimate agent robustness. High task success in such idealized settings does not necessarily reflect performance under realistic web interaction. To address this limitation, we introduce a diagnostic stress-testing benchmark for web agents. We first construct realistic and controllable web environments that provide clean and stable interaction workflows as reference baselines. We then introduce structured and controlled perturbations that emulate interaction variability, including shifting layouts, altered interaction semantics, and execution disruptions. By comparing agent behavior between clean and perturbed settings, our framework enables systematic diagnosis of robustness under what-if interaction scenarios. Through extensive evaluation of state-of-the-art multimodal web agents, we show that stress-based evaluation exposes failure modes and substantial robustness gaps that remain hidden under clean benchmark conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StressWeb, a diagnostic benchmark for LLM-based multimodal web agents. It constructs clean, controllable reference web environments as baselines and applies three families of structured perturbations (layout shifts, altered interaction semantics, execution disruptions) to emulate realistic interaction variability. By comparing agent performance in clean vs. perturbed settings, the work claims to expose failure modes and substantial robustness gaps that remain hidden under standard clean-benchmark conditions.
Significance. If the perturbations can be shown to align with real-world interaction distributions, the benchmark would offer a useful diagnostic framework for identifying robustness limitations in web agents, potentially guiding improvements toward more reliable deployment. The controlled what-if comparison approach is a methodological strength for systematic diagnosis.
major comments (2)
- [Abstract] Abstract: the central claim that 'stress-based evaluation exposes failure modes and substantial robustness gaps' rests on unshown quantitative evidence; no metrics, success rates, error bars, or specific agent results are provided to substantiate the magnitude or statistical significance of the gaps.
- [Abstract] Abstract and implied methods: the headline claim requires that the three perturbation families produce failure statistics approximating genuine web variability, yet no quantitative validation (action-sequence divergence, error-type histograms, or alignment with real-user traces) is described; without this, the observed gaps could be artifacts of the synthetic edits.
minor comments (1)
- [Abstract] The abstract refers to 'extensive evaluations' without specifying the number of agents, tasks, or runs; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger substantiation in the abstract. We will revise the abstract to include key quantitative results from our evaluations. On the second point, we clarify that StressWeb is designed as a controlled diagnostic benchmark using structured perturbations for what-if analysis, not as a statistical replica of real-world distributions; we will expand the methods discussion to better articulate this rationale without claiming direct alignment to user traces.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'stress-based evaluation exposes failure modes and substantial robustness gaps' rests on unshown quantitative evidence; no metrics, success rates, error bars, or specific agent results are provided to substantiate the magnitude or statistical significance of the gaps.
Authors: The full manuscript contains extensive evaluations of multiple state-of-the-art multimodal web agents, reporting success rates, failure breakdowns, and performance deltas between clean and perturbed conditions with statistical details. We agree the abstract should surface these numbers and will revise it to include representative metrics (e.g., average success drops and error-type frequencies) along with brief mention of evaluation scale. revision: yes
-
Referee: [Abstract] Abstract and implied methods: the headline claim requires that the three perturbation families produce failure statistics approximating genuine web variability, yet no quantitative validation (action-sequence divergence, error-type histograms, or alignment with real-user traces) is described; without this, the observed gaps could be artifacts of the synthetic edits.
Authors: The benchmark does not claim to reproduce real-world failure distributions; its contribution is the controlled what-if comparison that isolates specific robustness issues. Perturbations are grounded in documented web interaction patterns from prior literature, but we do not provide direct statistical alignment metrics because that is outside the stated diagnostic scope. We will add a dedicated paragraph in the methods section justifying the perturbation design and noting this distinction explicitly. revision: partial
Circularity Check
No significant circularity in benchmark construction or claims
full rationale
The paper introduces reference environments as baselines and applies structured perturbations (layout shifts, semantic changes, execution disruptions) to create diagnostic comparisons. No equations, fitted parameters, or self-referential definitions appear; the robustness gaps are measured directly against the paper's own clean baselines without reducing to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The derivation chain remains independent and externally falsifiable via the described agent evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structured perturbations (layout shifts, semantic alterations, execution disruptions) can emulate realistic web interaction variability
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first construct realistic and controllable web environments that provide clean and stable interaction workflows as reference baselines. We then introduce structured and controlled perturbations that emulate interaction variability, including shifting layouts, altered interaction semantics, and execution disruptions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854. A Comparison with Existing Web Agent Benchmarks To provide a broader perspective on the design space of web agent benchmarks, Table 2 summa- rizes key properties of representative benchmarks and evaluation frameworks. The comparison highlights several imp...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Text-based selectors button:has-text("Text") a:has-text("Link") text="Exact Text"
-
[3]
Element + class button.primary div.card input.search-input
-
[4]
ID selector #element-id
-
[5]
Attribute selector [placeholder="Search"] [type="submit"] If selector-based interaction repeatedly fails, visual coordinates may be used as a fallback. Selectors should remain simple and avoid deep nesting. -------------------------------------------------- Output format All responses must be valid JSON objects. Example: { "action_type": "CLICK", "paramet...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.