Recognition: 2 theorem links
· Lean TheoremLarge language models for post-publication research evaluation: Evidence from expert recommendations and citation indicators
Pith reviewed 2026-05-14 22:37 UTC · model grok-4.3
The pith
LLMs identify highly recommended research articles with over 80 percent accuracy but struggle with detailed ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The study benchmarks BERT models, general-purpose LLMs, and reasoning-oriented LLMs on post-publication evaluation tasks using expert recommendations from the H1 Connect platform and citation indicators as ground truth. LLMs achieve accuracy above 0.8 in coarse-grained identification of highly recommended articles. Performance decreases substantially in fine-grained tasks such as article rating and merit classification. Few-shot prompting improves results over zero-shot settings, supervised fine-tuning yields the strongest and most balanced performance, and retrieval-augmented prompting shows mixed effects while overall correlations with citation indicators remain positive but moderate.
What carries the argument
Benchmarking multiple LLM families against expert recommendations on the H1 Connect platform and citation indicators to test automated support for post-publication peer review tasks.
If this is right
- LLMs can provide scalable support for coarse identification of high-quality articles in large publication sets.
- Supervised fine-tuning produces the strongest alignment with expert judgments across tasks.
- Few-shot prompting offers a practical improvement over zero-shot use without additional training.
- Retrieval-augmented prompting does not reliably improve alignment with citation indicators.
Where Pith is reading between the lines
- Research platforms could use LLMs to pre-filter new papers so that human experts focus only on the most promising ones.
- Hybrid human-AI workflows might combine LLM coarse screening with expert review for the detailed ratings where models are weaker.
- Similar benchmarking on recommendation data from other platforms would test whether the accuracy levels generalize beyond the H1 Connect source.
Load-bearing premise
Expert recommendations on the H1 Connect platform and citation indicators constitute reliable, unbiased ground truths for measuring research quality.
What would settle it
A follow-up study that collects new independent expert ratings on the same articles and finds that LLM outputs no longer align closely with those ratings or with later citation outcomes would show the original benchmarking does not hold.
Figures

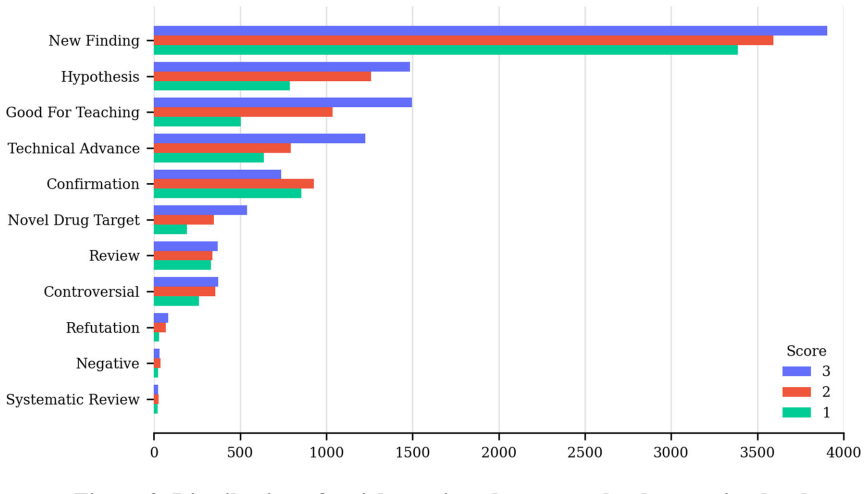




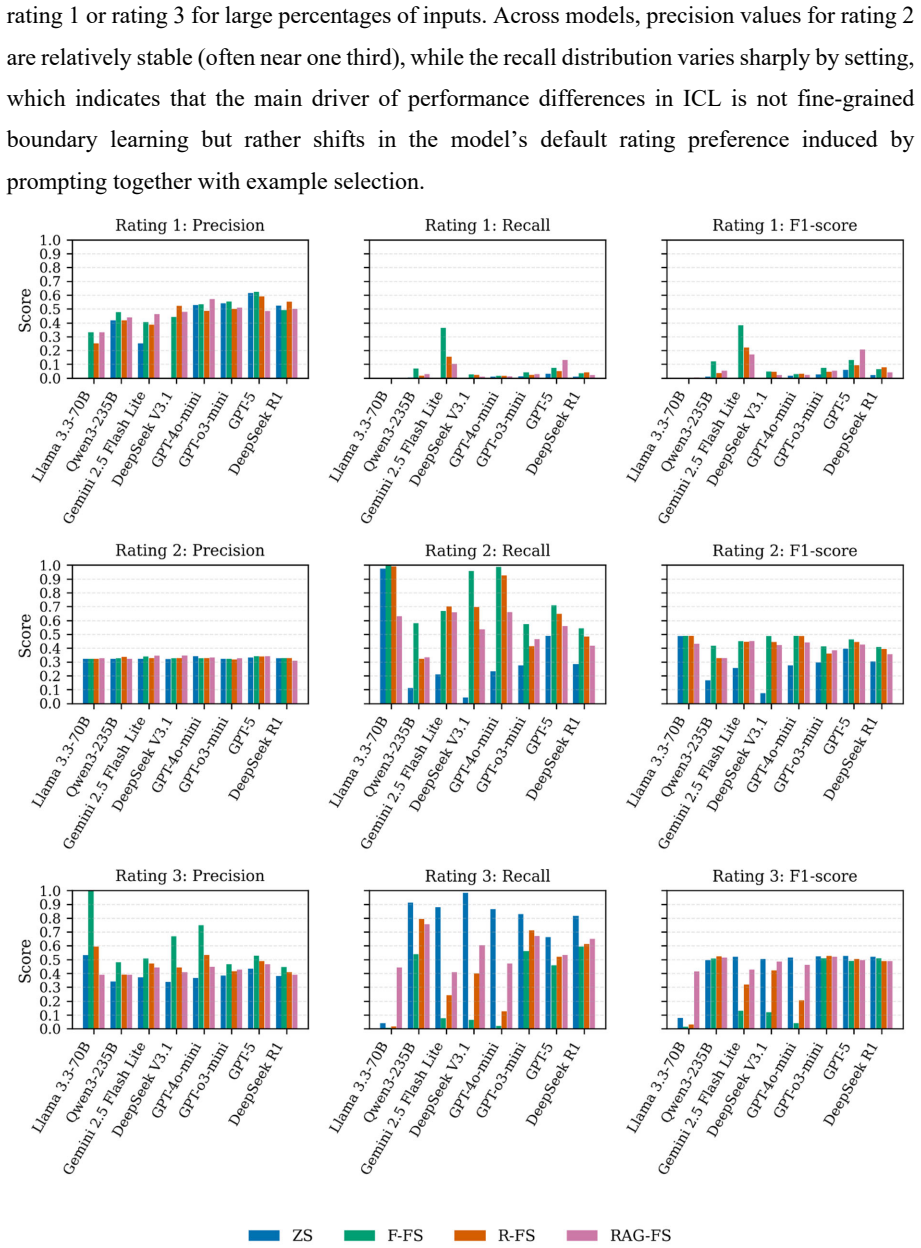





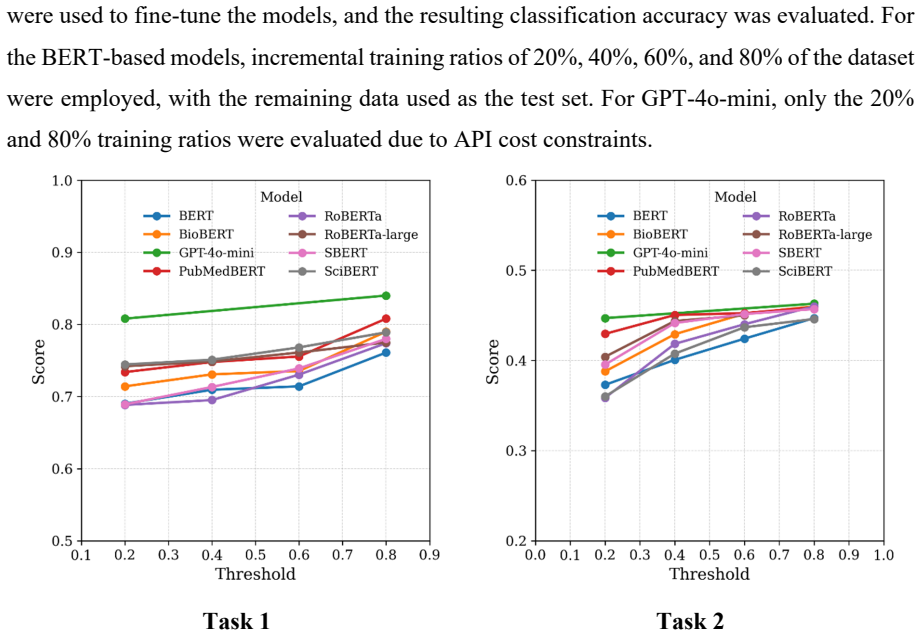
read the original abstract
Assessing the quality of scientific research is essential for scholarly communication, yet widely used approaches face limitations in scalability, subjectivity, and time delay. Recent advances in large language models (LLMs) offer new opportunities for automated research evaluation based on textual content. This study examines whether LLMs can support post-publication peer review tasks by benchmarking their outputs against expert judgments and citation-based indicators. Two evaluation tasks are constructed using articles from the H1 Connect platform: identifying high-quality articles and performing finer-grained evaluation including article rating, merit classification, and expert style commenting. Multiple model families, including BERT models, general-purpose LLMs, and reasoning oriented LLMs, are evaluated under multiple learning strategies. Results show that LLMs perform well in coarse grained evaluation tasks, achieving accuracy above 0.8 in identifying highly recommended articles. However, performance decreases substantially in fine-grained rating tasks. Few-shot prompting improves performance over zero-shot settings, while supervised fine-tuning produces the strongest and most balanced results. Retrieval augmented prompting improves classification accuracy in some cases but does not consistently strengthen alignment with citation indicators. The overall correlations between model outputs and citation indicators remain positive but moderate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks large language models (LLMs) for post-publication research evaluation using articles from the H1 Connect platform. It defines coarse-grained tasks (identifying highly recommended articles) and fine-grained tasks (rating, merit classification, expert-style commenting), testing BERT models, general-purpose LLMs, and reasoning LLMs under zero-shot, few-shot, supervised fine-tuning, and retrieval-augmented prompting. Key results are that LLMs reach accuracy above 0.8 on coarse identification, with supervised fine-tuning strongest and most balanced, while fine-grained performance drops substantially and correlations with citation indicators remain positive but moderate.
Significance. If the empirical patterns hold after addressing ground-truth concerns, the work supplies concrete evidence that LLMs can scale coarse post-publication screening, offering a practical complement to delayed citation metrics and subjective peer review. The systematic comparison across model families and learning strategies supplies actionable guidance for deployment in information-retrieval settings.
major comments (2)
- [Section 3] Section 3 (Task Construction): No inter-expert agreement statistics or reliability metrics are reported for the H1 Connect labels used as ground truth. Without these, the central accuracy claim (>0.8 on highly recommended articles) cannot be interpreted as evidence that models assess intrinsic quality rather than reproduce platform-specific visibility or prestige cues.
- [Section 5] Section 5 (Results): Accuracy differences across strategies (e.g., supervised fine-tuning vs. few-shot) and the reported performance drop on fine-grained tasks lack statistical significance tests, confidence intervals, or baseline comparisons, so it is unclear whether the observed gaps exceed what would be expected from sampling variability alone.
minor comments (2)
- [Abstract] Abstract: The phrase 'post-publication peer review tasks' is used loosely; the study evaluates classification and rating rather than full review, so a more precise description would improve clarity.
- [Table 1] Table 1: Column headers for model families and strategies are not fully aligned with the text descriptions in Section 4, making cross-referencing cumbersome.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below. Where the comments identify gaps in statistical reporting or limitations discussion, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Task Construction): No inter-expert agreement statistics or reliability metrics are reported for the H1 Connect labels used as ground truth. Without these, the central accuracy claim (>0.8 on highly recommended articles) cannot be interpreted as evidence that models assess intrinsic quality rather than reproduce platform-specific visibility or prestige cues.
Authors: We agree that inter-expert agreement metrics would strengthen interpretation. Unfortunately, the H1 Connect dataset provides only a single aggregated expert recommendation label per article and does not release the underlying individual reviewer ratings, so Cohen's kappa or similar statistics cannot be computed. We have therefore revised Section 3 to explicitly frame the task as alignment with platform expert judgments rather than direct measurement of intrinsic quality. A new paragraph in the Limitations section discusses the possibility that labels may partly reflect visibility or prestige cues and cautions against over-interpreting the >0.8 accuracy as evidence of quality assessment independent of platform signals. revision: yes
-
Referee: [Section 5] Section 5 (Results): Accuracy differences across strategies (e.g., supervised fine-tuning vs. few-shot) and the reported performance drop on fine-grained tasks lack statistical significance tests, confidence intervals, or baseline comparisons, so it is unclear whether the observed gaps exceed what would be expected from sampling variability alone.
Authors: We accept this criticism. In the revised manuscript we have added 95% bootstrap confidence intervals (1,000 resamples) around all accuracy, F1, and correlation figures. We also report McNemar's tests for paired comparisons between prompting strategies and a majority-class baseline. The performance advantage of supervised fine-tuning over few-shot prompting and the drop from coarse to fine-grained tasks remain statistically significant (p < 0.01). These additions appear in the updated Section 5 and a new Appendix table. revision: yes
Circularity Check
No circularity: empirical benchmarking against external expert and citation labels
full rationale
The paper performs direct empirical benchmarking of LLM outputs against independently sourced H1 Connect expert recommendations and citation counts. No equations, fitted parameters, or derivations are present that reduce any reported accuracy or correlation to a quantity defined by the model's own outputs or by self-citation. The central claims rest on measured agreement with external labels rather than any self-referential construction. While the reliability of those external labels is a substantive question, it does not create circularity within the paper's reported logic or results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert recommendations from the H1 Connect platform accurately reflect article quality
- domain assumption Citation indicators serve as a valid proxy for research impact
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearResults show that LLMs perform well in coarse grained evaluation tasks, achieving accuracy above 0.8 in identifying highly recommended articles.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTask 1: High-quality article identification... Low-quality articles are defined as those with no expert recommendations and high-quality articles are those with three or more expert recommendations.
Reference graph
Works this paper leans on
-
[3]
providing a short commen tary accompanying their recommendations or ev aluations, explainin g wh y the y believe the 41 Learning strategy Prompt research or trial is important and discussing its potential impact on current understanding, future research, or clinical practice. Your answer will contain three part s separated by newlines. Just give the answe...
-
[6]
providing a short commen tary accompanying their recommendations or evaluations, explaining why they believe the research or trial is important and discussing its potential impact on current understanding, future research, or clinical practice. Your answer will contain three part s separated by newlines. Just give the answer with nothing else: A rating on...
-
[7]
Identifying and recommending articles, studies, and research outputs that you consider significan t and impactful in the relevant fields. You assess the quality, relevance, and potential impact of the research and provide your expert opinion on its importance
-
[8]
evaluating clinical trial result s and providing insights into their implications for clinical care and medical advancements. You assess the design, methodology, results, and potential applications of the trials, offering your expert perspective on the significance and relevance of the findings
-
[9]
providing a short commen tary accompanying their recommendations or evaluations, explaining why they believe the research or trial is important and discussing its potential impact on current understanding, future research, or clinical practice. Your answer will contain three part s separated by newlines. Just give the answer with nothing else: A rating on...
work page 1955
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.