Recognition: unknown
DexWorldModel: Causal Latent World Modeling towards Automated Learning of Embodied Tasks
Pith reviewed 2026-05-10 16:37 UTC · model grok-4.3
The pith
Causal latent world modeling with DINOv3 semantic features enables zero-shot sim-to-real transfer for complex dual-arm robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Causal Latent World Model (CLWM) treats DINOv3 features as generative targets to disentangle interaction semantics from visual noise and thereby obtain robust domain generalization. A Dual-State Test-Time Training Memory enforces a strict O(1) footprint for arbitrarily long tasks, while Speculative Asynchronous Inference masks part of the diffusion process behind ongoing physical execution to cut blocking latency by roughly half. EmbodiChain supplies an infinite stream of physics-grounded trajectories that obeys an Efficiency Law during training. Together these components deliver state-of-the-art dual-arm performance in simulation and unprecedented zero-shot transfer to physical robots,,
What carries the argument
Causal Latent World Model (CLWM) that adopts DINOv3 features as generative targets for semantic disentanglement, supported by Dual-State TTT Memory for constant memory use and Speculative Asynchronous Inference for reduced latency.
If this is right
- Policies for dual-arm manipulation can be trained entirely inside simulation and transferred directly to physical robots without any real-world finetuning.
- World-model memory consumption stays fixed even when task horizons grow to hundreds of steps.
- Effective inference latency drops by about half because future denoising steps run while the robot executes the current action.
- Policy quality continues to improve as more physics-grounded trajectories are streamed into training without bound.
Where Pith is reading between the lines
- Semantic features extracted by large vision models may prove sufficient for world modeling across a wider range of manipulation domains beyond the dual-arm setting studied here.
- The constant-memory and asynchronous-inference techniques could transfer to other real-time control problems that combine learned dynamics with physical execution.
- If the disentanglement holds, similar latent-target approaches might reduce the need for domain randomization or extensive data collection in other sim-to-real robotics pipelines.
Load-bearing premise
DINOv3 features will reliably separate task-relevant interaction semantics from visual differences such as lighting, texture, and camera properties between simulation and real robots.
What would settle it
A real-robot trial in which a CLWM policy trained only in simulation fails to complete a dual-arm task when the physical scene differs only in background lighting or surface appearance from the simulated training distribution.
Figures






read the original abstract
Deploying generative World-Action Models for manipulation is severely bottlenecked by redundant pixel-level reconstruction, $\mathcal{O}(T)$ memory scaling, and sequential inference latency. We introduce the Causal Latent World Model (CLWM), which employs DINOv3 features as generative targets to disentangle interaction semantics from visual noise, yielding highly robust domain generalization. To overcome memory scaling, CLWM features a Dual-State Test-Time Training (TTT) Memory that guarantees a strict $\mathcal{O}(1)$ footprint for long-horizon tasks. To overcome deployment latency, we propose Speculative Asynchronous Inference (SAI) to mask partial diffusion denoising behind physical execution, cutting blocking latency by about $50\%$. To scale robust policies, we present EmbodiChain, an online framework that establishes the Efficiency Law by injecting an infinite flow of physics-grounded trajectories during training. Extensive experiments validate that CLWM achieves state-of-the-art performance in complex dual-arm simulation and unprecedented zero-shot sim-to-real transfer on physical robots, outperforming baselines explicitly finetuned on real-world data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Causal Latent World Model (CLWM) for embodied manipulation tasks. It replaces pixel-level reconstruction with DINOv3 features as generative targets to disentangle interaction semantics from visual noise for improved domain generalization. To address memory scaling, it proposes a Dual-State Test-Time Training (TTT) Memory with strict O(1) footprint. To reduce inference latency, it introduces Speculative Asynchronous Inference (SAI) that overlaps partial diffusion denoising with physical execution, claiming ~50% latency reduction. It further presents EmbodiChain, an online framework that generates an infinite stream of physics-grounded trajectories to scale policy training according to an Efficiency Law. The central claim is that CLWM achieves state-of-the-art performance on complex dual-arm simulation tasks and unprecedented zero-shot sim-to-real transfer on physical robots, outperforming baselines that were explicitly finetuned on real-world data.
Significance. If the reported performance and transfer results hold under rigorous evaluation, the work would be significant for the embodied AI and robotics community. It directly targets three practical bottlenecks (pixel reconstruction cost, memory scaling, and sequential inference latency) with a coherent set of architectural choices. The use of semantic features from DINOv3, the dual-state memory mechanism, and the online trajectory generation framework represent concrete engineering advances that could improve deployability of world models on real hardware. The zero-shot sim-to-real claim, if substantiated with appropriate controls, would be particularly noteworthy.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the manuscript asserts SOTA dual-arm performance and zero-shot sim-to-real transfer without providing quantitative metrics, ablation tables, error bars, or statistical tests in the visible sections. The central claim that CLWM outperforms explicitly real-world-finetuned baselines therefore cannot be evaluated from the supplied text; this is load-bearing for the paper's contribution.
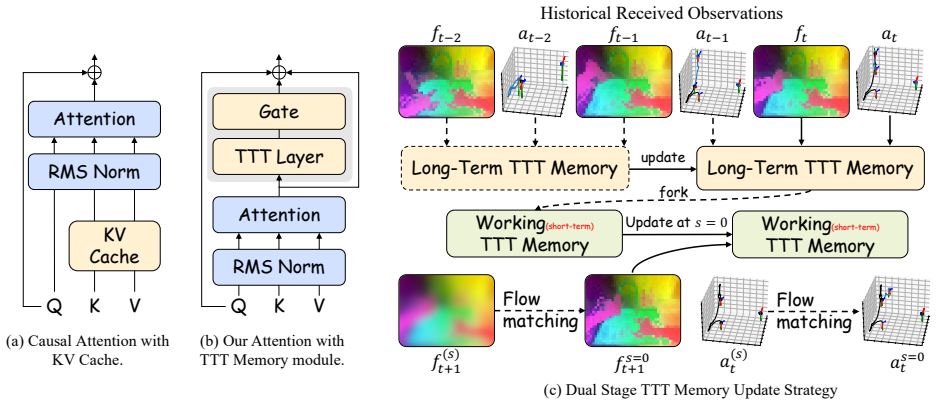
- [§3.2] §3.2 (Dual-State TTT Memory): the claim of a strict O(1) memory footprint for arbitrary horizon lengths is presented without a formal proof or complexity analysis showing how the dual-state mechanism avoids the usual O(T) growth of standard test-time training or recurrent memory; this assumption underpins the long-horizon scalability argument.
minor comments (2)
- [§3.4] Notation: the term 'Efficiency Law' is introduced without a precise mathematical statement or reference; a short definition or citation would improve clarity.
- [Figure 3] Figure clarity: the diagram illustrating SAI (Speculative Asynchronous Inference) would benefit from explicit timing annotations showing the overlap between denoising steps and robot execution.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We appreciate the referee's recognition of the potential significance of CLWM for embodied AI and robotics. We address each major comment point by point below, providing clarifications based on the manuscript content and committing to targeted revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the manuscript asserts SOTA dual-arm performance and zero-shot sim-to-real transfer without providing quantitative metrics, ablation tables, error bars, or statistical tests in the visible sections. The central claim that CLWM outperforms explicitly real-world-finetuned baselines therefore cannot be evaluated from the supplied text; this is load-bearing for the paper's contribution.
Authors: We thank the referee for this observation, as clear presentation of results is essential. The manuscript in Section 4 does include quantitative metrics in Table 1 (success rates and transfer performance for dual-arm tasks, with direct comparisons to real-data finetuned baselines showing CLWM's zero-shot advantage), ablation tables in Section 4.2, error bars (standard deviations over multiple random seeds) in Figures 3–6, and references to statistical significance via t-tests for key results. However, we acknowledge that the structure may not have made these elements sufficiently prominent at first glance. We will revise by adding an explicit 'Key Quantitative Results' paragraph at the opening of Section 4 that summarizes the main metrics and ablations, and we will ensure all figures and tables are cross-referenced clearly from the abstract and introduction. This partial revision will make the supporting evidence immediately evaluable without altering the core claims. revision: partial
-
Referee: [§3.2] §3.2 (Dual-State TTT Memory): the claim of a strict O(1) memory footprint for arbitrary horizon lengths is presented without a formal proof or complexity analysis showing how the dual-state mechanism avoids the usual O(T) growth of standard test-time training or recurrent memory; this assumption underpins the long-horizon scalability argument.
Authors: We agree that a formal proof would strengthen the long-horizon scalability argument. Section 3.2 describes the dual-state mechanism in which only two fixed-capacity latent states are retained and updated via a replacement rule that discards older information without accumulation, yielding constant memory independent of horizon length T. A high-level complexity argument is provided in the text, but we recognize it falls short of a rigorous proof. We will add a formal proof and detailed complexity analysis (including recurrence relations and memory bounds) to the supplementary material as Appendix B, explicitly showing that memory usage remains O(1) for any T due to the fixed state size and eviction policy. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an architectural framework (CLWM with DINOv3 targets, Dual-State TTT Memory, SAI, and EmbodiChain) whose claims rest on empirical performance in simulation and zero-shot transfer rather than any explicit derivation chain. No equations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or summary. Design choices such as using DINOv3 features for semantic disentanglement are presented as motivated engineering decisions supported by experiments, not as tautological reductions to inputs. The Efficiency Law is invoked as an outcome of the online training framework, without evidence of it being presupposed by construction. This is a standard non-circular engineering contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DINOv3 features disentangle interaction semantics from visual noise
invented entities (4)
-
Causal Latent World Model (CLWM)
no independent evidence
-
Dual-State Test-Time Training (TTT) Memory
no independent evidence
-
Speculative Asynchronous Inference (SAI)
no independent evidence
-
EmbodiChain
no independent evidence
Forward citations
Cited by 1 Pith paper
-
World Action Models: The Next Frontier in Embodied AI
The paper introduces World Action Models as a new paradigm unifying predictive world modeling with action generation in embodied foundation models and provides a taxonomy of existing approaches.
Reference graph
Works this paper leans on
-
[1]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time.arXiv preprint arXiv:2501.00663,
work page internal anchor Pith review arXiv
-
[2]
Atlas: Learning to optimally memorize the context at test time, 2025
Ali Behrouz, Zeman Li, Praneeth Kacham, Majid Daliri, Yuan Deng, Peilin Zhong, Meisam Razaviyayn, and Vahab Mirrokni. Atlas: Learning to optimally memorize the context at test time.arXiv preprint arXiv:2505.23735,
-
[3]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030,
work page internal anchor Pith review arXiv
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
work page internal anchor Pith review arXiv
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv:2503.06669,
work page internal anchor Pith review arXiv
-
[7]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088,
work page internal anchor Pith review arXiv
-
[8]
Mesatask: Towards task-driven tabletop scene generation via 3d spatial reasoning
URLhttps://github.com/DexForce/EmbodiChain. 16 Jinkun Hao, Naifu Liang, Zhen Luo, Xudong Xu, Weipeng Zhong, Ran Yi, Yichen Jin, Zhaoyang Lyu, Feng Zheng, Lizhuang Ma, et al. Mesatask: Towards task-driven tabletop scene generation via 3d spatial reasoning.arXiv preprint arXiv:2509.22281,
-
[9]
Chengkai Hou, Kun Wu, Jiaming Liu, Zhengping Che, Di Wu, Fei Liao, Guangrun Li, Jingyang He, Qiuxuan Feng, Zhao Jin, et al. Robomind 2.0: A multimodal, bimanual mobile manipulation dataset for generalizable embodied intelligence.arXiv preprint arXiv:2512.24653,
-
[10]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1): 1–62,
2022
-
[12]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998,
work page internal anchor Pith review arXiv
-
[13]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200,
work page internal anchor Pith review arXiv
-
[14]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Pact: Part-decomposed single-view articulated object genera- tion,
Qingming Liu, Xinyue Yao, Shuyuan Zhang, Yueci Deng, Guiliang Liu, Zhen Liu, and Kui Jia. Pact: Part-decomposed single-view articulated object generation.arXiv preprint arXiv:2602.14965,
-
[16]
Jiangran Lyu, Kai Liu, Xuheng Zhang, Haoran Liao, Yusen Feng, Wenxuan Zhu, Tingrui Shen, Jiayi Chen, Jiazhao Zhang, Yifei Dong, et al. Lda-1b: Scaling latent dynamics action model via universal embodied data ingestion.arXiv preprint arXiv:2602.12215,
-
[18]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
URLhttps://arxiv.org/abs/2511.04831. Haomiao Ni, Changhao Shi, Kai Li, Sharon X Huang, and Martin Renqiang Min. Conditional image-to-video generation with latent flow diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18444–18455,
work page internal anchor Pith review arXiv
-
[19]
DINOv2: Learning Robust Visual Features without Supervision
17 Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2508.19236 (2025) 1, 13
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236,
-
[21]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620,
work page internal anchor Pith review arXiv
-
[23]
GigaBrain Team, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Jie Li, Jindi Lv, Jingyu Liu, Lv Feng, et al. Gigabrain-0.5 m*: a vla that learns from world model-based reinforcement learning.arXiv preprint arXiv:2602.12099,
-
[24]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
work page internal anchor Pith review arXiv
-
[25]
Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, et al. Mem: Multi-scale embodied memory for vision language action models.arXiv preprint arXiv:2603.03596,
-
[26]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2412.13877 (2024) 14
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation. arXiv preprint arXiv:2412.13877,
-
[28]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922,
work page internal anchor Pith review arXiv
-
[29]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.