Recognition: unknown
LayerCache: Exploiting Layer-wise Velocity Heterogeneity for Efficient Flow Matching Inference
Pith reviewed 2026-05-10 15:09 UTC · model grok-4.3
The pith
LayerCache improves flow matching image generation by making independent caching decisions for each transformer layer group based on velocity stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
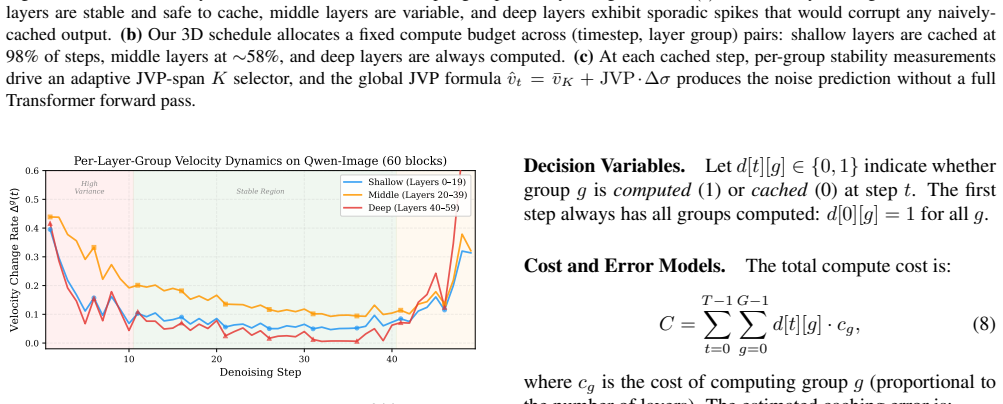
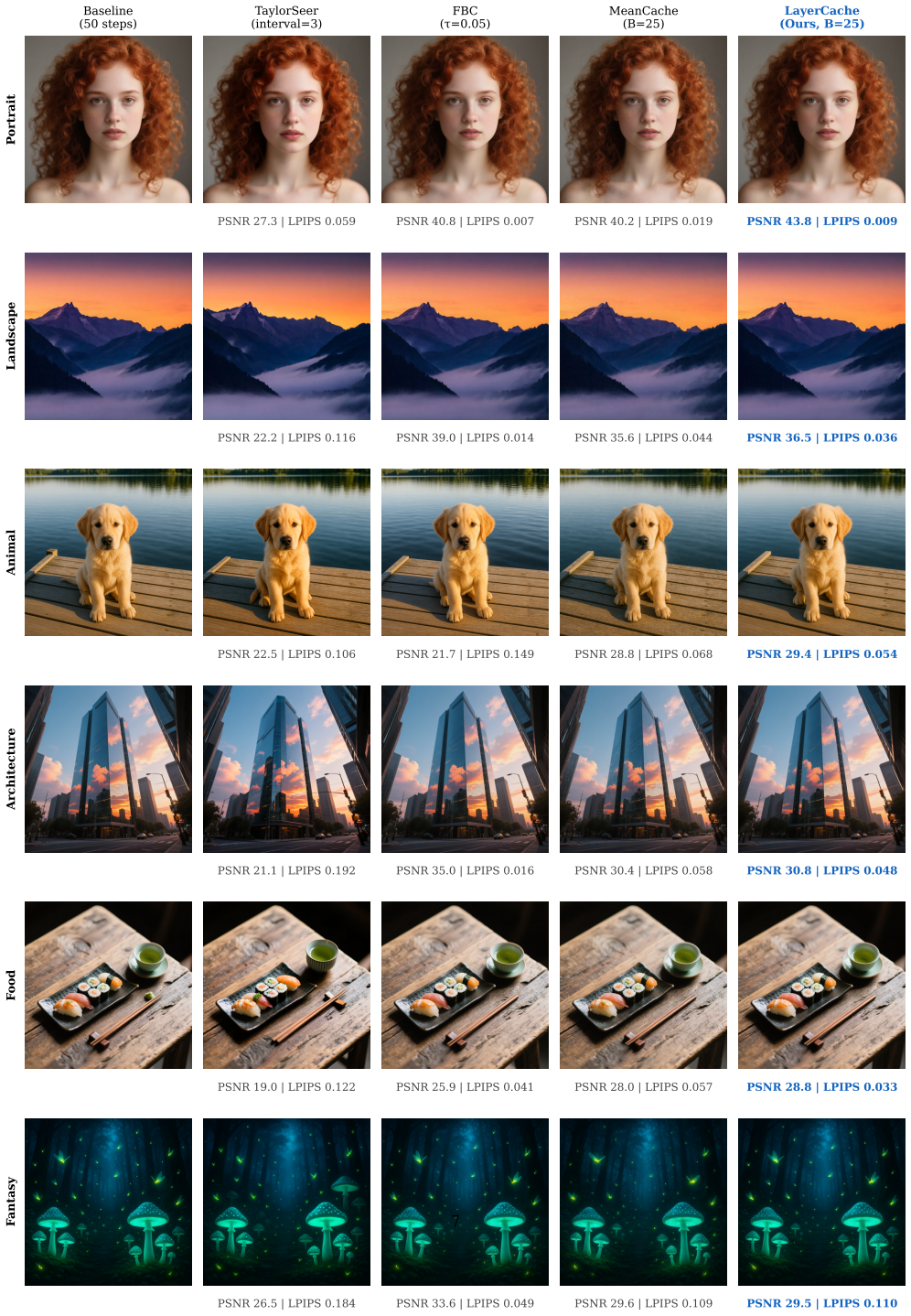
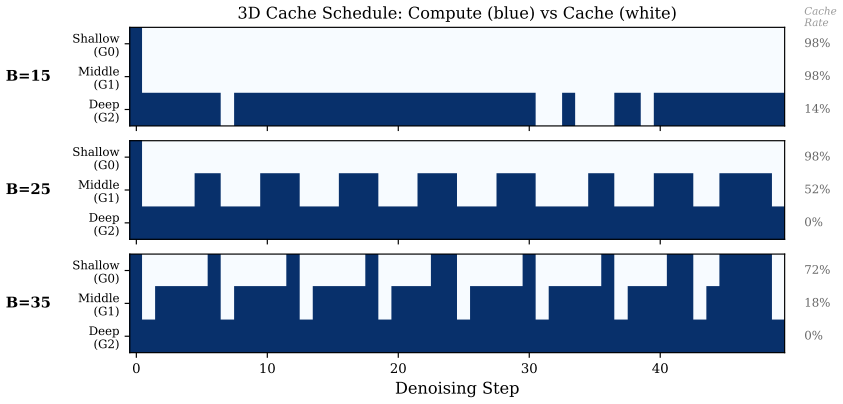
We observe that different layer groups within a flow matching transformer exhibit heterogeneous velocity dynamics, with shallow layers highly stable and deep layers undergoing large changes. Existing methods apply a single caching decision per timestep across the whole model. LayerCache partitions the transformer into layer groups, makes independent per-group caching decisions, introduces an adaptive JVP span K selection based on per-group stability, and solves the resulting three-dimensional scheduling problem with a greedy budget allocation algorithm. On Qwen-Image at 1024x1024 resolution with 50 steps, this produces PSNR 37.46 dB, SSIM 0.9834, and LPIPS 0.0178 at 1.37x speedup, outperform
What carries the argument
Layer-group partitioning with independent per-group caching decisions driven by stability measurements and adaptive JVP span selection, solved by greedy budget allocation across timesteps, groups, and spans.
If this is right
- Produces higher PSNR, SSIM, and lower LPIPS than uniform caching methods such as MeanCache while running faster.
- Places the quality-speed tradeoff ahead of all tested prior caching techniques on the Pareto frontier for 1024x1024 generation.
- Allows more aggressive reuse of computations in stable shallow layers without harming the accuracy of rapidly changing deep layers.
- Reduces perceptual difference metrics by about 70 percent relative to baseline caching at comparable or better speed.
Where Pith is reading between the lines
- The same stability signal could be used to automatically discover layer groupings rather than fixing them in advance.
- Energy use for large-scale image generation batches would drop if the per-group decisions scale across many parallel samples.
- The approach may transfer to other iterative transformer generators that also exhibit velocity or activation patterns varying by depth.
- Hardware schedulers could expose layer-group interfaces so that caching decisions are made at runtime based on measured stability.
Load-bearing premise
The observed differences in velocity change across layer groups stay consistent enough across images and timesteps that separate caching decisions can be made without creating visible artifacts or needing heavy per-model retuning.
What would settle it
Apply LayerCache to a flow matching transformer in which velocity change is roughly uniform across all layers; if the method then shows no gain in PSNR, SSIM, or LPIPS over uniform caching at the same speedup, the benefit of exploiting layer-wise heterogeneity is refuted.
Figures


read the original abstract
Flow Matching models achieve state-of-the-art image generation quality but incur substantial inference cost due to iterative denoising through large Transformer networks. We observe that different layer groups within a Transformer exhibit markedly heterogeneous velocity dynamics: shallow layers are highly stable and amenable to aggressive caching, while deep layers undergo large velocity changes that demand full computation. Existing caching methods, however, treat the entire Transformer as a monolithic unit, applying a single caching decision per timestep and thus failing to exploit this heterogeneity. Based on this finding, we propose LayerCache, a layer-aware caching framework that partitions the Transformer into layer groups and makes independent, per-group caching decisions at each denoising step. LayerCache introduces an adaptive JVP span K selection mechanism that leverages per-group stability measurements to balance estimation accuracy and computational savings. We formulate a three-dimensional scheduling problem over timesteps, layer groups, and JVP span, and solve it with a greedy budget allocation algorithm. On Qwen-Image (1024x1024, 50 steps), LayerCache achieves PSNR 37.46 dB (+5.38 dB over MeanCache), SSIM 0.9834, and LPIPS 0.0178 (a 70% reduction over MeanCache) at 1.37x speedup, dominating all prior caching methods on the quality-speed Pareto frontier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that flow-matching Transformers exhibit layer-wise velocity heterogeneity (shallow layers stable, deep layers dynamic), which existing monolithic caching methods fail to exploit. LayerCache partitions the Transformer into layer groups, makes independent per-group caching decisions per denoising step, introduces an adaptive JVP-span-K selection based on per-group stability, and solves the resulting 3-D scheduling problem (timesteps × groups × K) via a greedy budget-allocation algorithm. On Qwen-Image (1024×1024, 50 steps) it reports PSNR 37.46 dB (+5.38 dB vs. MeanCache), SSIM 0.9834, LPIPS 0.0178 (70 % reduction vs. MeanCache) at 1.37× speedup, asserting Pareto dominance over prior caching techniques.
Significance. If the empirical results are reproducible, the work offers a practical, low-overhead route to faster inference for large flow-matching image generators by exploiting internal model dynamics rather than uniform approximations. The concrete metrics, the per-group independence, and the greedy 3-D scheduler constitute clear engineering contributions; the absence of internal contradictions in the described pipeline supports the claim that heterogeneity can be turned into measurable savings without catastrophic quality loss.
major comments (2)
- [Abstract] Abstract: the central empirical claim (Pareto dominance, +5.38 dB PSNR, 70 % LPIPS reduction, 1.37× speedup) is presented without any reference to baseline implementations, hardware, wall-clock measurement protocol, number of samples, or statistical tests; these omissions are load-bearing because the quantitative superiority cannot be verified or reproduced from the given information.
- [Abstract] Abstract / method description: the assumption that velocity heterogeneity is sufficiently consistent across timesteps and models to permit independent per-group caching decisions without visible artifacts is stated but not supported by any reported ablation on group partitioning, sensitivity to K-selection thresholds, or cross-model transfer; this directly affects the generalizability of the 1.37× speedup result.
minor comments (3)
- [Abstract] Abstract: the acronym 'JVP' (Jacobian-vector product) and the precise meaning of 'JVP span K' are introduced without a one-sentence definition, which may hinder readers outside the immediate sub-field.
- [Abstract] Abstract: the speedup factor 1.37× is given without stating the reference runtime or the exact configuration (batch size, precision, hardware), reducing clarity of the efficiency claim.
- The manuscript would benefit from a small illustrative figure or table showing measured velocity variance per layer group at representative timesteps to visually ground the key heterogeneity observation.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation of minor revision. We address each major comment below with targeted revisions to the abstract and additional analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (Pareto dominance, +5.38 dB PSNR, 70 % LPIPS reduction, 1.37× speedup) is presented without any reference to baseline implementations, hardware, wall-clock measurement protocol, number of samples, or statistical tests; these omissions are load-bearing because the quantitative superiority cannot be verified or reproduced from the given information.
Authors: We agree that the abstract, as a concise summary, omits explicit references to the experimental protocol. The full manuscript details the baselines (MeanCache and other prior methods implemented per their original papers), hardware platform, wall-clock timing via CUDA-synchronized measurements, evaluation over a fixed set of samples, and metric computation in Section 4. To improve immediate verifiability of the central claims, we will revise the abstract to include a brief clause referencing the evaluation scale, baseline comparison, and wall-clock nature of the speedup. This change preserves abstract length while directing readers to the reproducible protocol in the body. revision: yes
-
Referee: [Abstract] Abstract / method description: the assumption that velocity heterogeneity is sufficiently consistent across timesteps and models to permit independent per-group caching decisions without visible artifacts is stated but not supported by any reported ablation on group partitioning, sensitivity to K-selection thresholds, or cross-model transfer; this directly affects the generalizability of the 1.37× speedup result.
Authors: Section 3 of the manuscript presents per-layer JVP norm analysis across timesteps, demonstrating that shallow-layer stability and deep-layer dynamism are consistent within the evaluated Qwen-Image model and support independent per-group decisions. We acknowledge, however, that the current version does not include explicit ablations on alternative group partitionings, K-threshold sensitivity, or transfer to other flow-matching models. We will add these analyses in the revision (including sensitivity curves and results on a second architecture) to strengthen the generalizability argument. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core chain begins with an empirical observation of layer-wise velocity heterogeneity in flow-matching Transformers, followed by explicit partitioning into groups, independent per-group caching decisions, an adaptive JVP-span selection rule based on per-group stability measurements, and a greedy algorithm solving the resulting three-dimensional scheduling problem. These steps are algorithmic constructions applied to the observed dynamics rather than any fitted parameter or self-referential definition that reduces the output to the input by construction. Reported metrics (PSNR, SSIM, LPIPS, speedup) are presented as direct empirical measurements on Qwen-Image, with no equations or claims that rename a known result, smuggle an ansatz via self-citation, or treat a fitted quantity as a prediction. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- JVP span K selection thresholds
axioms (1)
- domain assumption Different layer groups exhibit markedly heterogeneous velocity dynamics that remain stable enough for independent caching decisions.
Reference graph
Works this paper leans on
-
[1]
FLUX.1: Text-to-image models
Black Forest Labs. FLUX.1: Text-to-image models. https : / / github . com / black - forest - labs / flux, 2024. 1, 2
2024
-
[2]
Dicache: Let diffusion model determine its own cache.arXiv preprint arXiv:2508.17356, 2025
Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Dahua Lin, and Jiaqi Wang. DiCache: Let dif- fusion model determine its own cache.arXiv preprint arXiv:2508.17356, 2025. 1, 2, 5, 6
-
[3]
First block cache: Dynamic caching for diffusion transformers.https : / / github
Zeyi Cheng. First block cache: Dynamic caching for diffusion transformers.https : / / github . com / chengzeyi/ParaAttention, 2024. 1, 2, 5, 6
2024
-
[4]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yan- nik Marek, and Robin Rombach. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on ...
2024
-
[5]
MeanCache: From instantaneous to average velocity for ac- celerating flow matching inference
Huanlin Gao, Ping Chen, Fuyuan Shi, Ruijia Wu, Yantao Li, Qiang Hui, Yuren You, Ting Lu, Chao Tan, Shaoan Zhao, Zhaoxiang Liu, Fang Zhao, Kai Wang, and Shiguo Lian. MeanCache: From instantaneous to average velocity for ac- celerating flow matching inference. InInternational Con- ference on Learning Representations (ICLR), 2026. 1, 2, 3, 6
2026
-
[6]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico Kolter, and Kaiming He. Mean flows for one-step genera- tive modeling.arXiv preprint arXiv:2505.13447, 2025. 1, 2, 3
work page internal anchor Pith review arXiv 2025
-
[7]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, et al. HunyuanVideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Guandong Li. SpectralCache: Frequency-aware error- bounded caching for accelerating diffusion transformers. arXiv preprint arXiv:2603.05315, 2026. 1, 2, 10
-
[9]
Guandong Li and Zhaobin Chu. EditID: Training-free ed- itable id customization for text-to-image generation.arXiv preprint arXiv:2503.12526, 2025. 10
-
[10]
Guandong Li and Zhaobin Chu. EditIDv2: Editable id customization with data-lubricated id feature integration for text-to-image generation.arXiv preprint arXiv:2509.05659,
-
[11]
Multimedia Systems, Springer, 2025. 10
2025
-
[12]
Guandong Li and Mengxia Ye. Inject where it mat- ters: Training-free spatially-adaptive identity preserva- tion for text-to-image personalization.arXiv preprint arXiv:2602.13994, 2026. 10
-
[13]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Repre- sentations (ICLR), 2023. 1, 2, 3
2023
-
[14]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model.arXiv preprint arXiv:2411.19108, 2024. 1, 2, 5, 6
-
[15]
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accel- erating diffusion models with TaylorSeers.arXiv preprint arXiv:2503.06923, 2025. 1, 2, 5, 6
-
[16]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Rep- resentations (ICLR), 2023. arXiv:2209.03003. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [17]
-
[18]
Deep- Cache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deep- Cache: Accelerating diffusion models for free. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1, 2
2024
-
[19]
MagCache: Fast video generation with magnitude-aware cache
Zehong Ma, Longhui Zhou, Hongbo Zhang, Daquan Xu, Mike Zheng Shou, Jiashi Feng, and Shilong Liu. MagCache: Fast video generation with magnitude-aware cache. InAd- vances in Neural Information Processing Systems (NeurIPS),
- [20]
-
[21]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023. 1, 2 10
2023
-
[22]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 1, 2
2022
-
[23]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InInternational Conference on Machine Learning (ICML), 2023. 2, 10
2023
-
[24]
Cache me if you can: Accelerating diffusion models through block caching
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, Christian Rupprecht, Daniel Cre- mers, Peter Vajda, and Jialiang Wang. Cache me if you can: Accelerating diffusion models through block caching. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pa...
2024
-
[25]
Qwen-Image: A versatile image generation model based on flow matching.arXiv preprint,
Bin Wu, Yixiao Zhan, et al. Qwen-Image: A versatile image generation model based on flow matching.arXiv preprint,
-
[26]
Real-time video generation with pyramid attention broadcast
Xuanlei Zhao, Xiaolong Jin, Kai Wang, and Yang You. Real-time video generation with pyramid attention broad- cast. InInternational Conference on Learning Representa- tions (ICLR), 2025. arXiv:2408.12588. 1, 2
-
[27]
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Lin- feng Zhang. Accelerating diffusion transformers with token- wise feature caching. InInternational Conference on Learn- ing Representations (ICLR), 2025. arXiv:2410.05317. 1, 2 A. Additional Experimental Results Table 3 shows the per-category breakdown of qual- ity metrics across all 20 evaluation pro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.