Recognition: unknown
Gradient-Free Continual Learning in Spiking Neural Networks via Inter-Spike Interval Regularization
Pith reviewed 2026-05-10 14:33 UTC · model grok-4.3
The pith
Spiking networks learn sequentially without forgetting by shielding regularly firing neurons from updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ISI-CV supplies the first gradient-free synaptic importance metric for spiking neural networks by measuring the coefficient of variation of inter-spike intervals; neurons whose firing times are regular (low CV) are presumed to carry task-relevant information and are therefore shielded from weight changes, while irregular neurons adapt freely. The metric requires only spike-time counters and integer operations, both native to neuromorphic hardware.
What carries the argument
ISI-CV, the coefficient of variation of inter-spike intervals, used directly as a per-synapse importance weight that modulates plasticity without any gradient computation.
If this is right
- Continual learning becomes possible on neuromorphic chips that lack back-propagation circuitry.
- Zero forgetting is observed on Split-MNIST and Split-FashionMNIST across multiple random seeds.
- Gradient-based importance methods fail on real DVS event data while ISI-CV succeeds.
- Only local spike counters and integer arithmetic are needed, removing the memory and compute overhead of gradient storage.
Where Pith is reading between the lines
- The same regularity principle could be tested on larger spiking architectures such as spiking transformers or recurrent SNNs.
- ISI-CV might be combined with event-driven hardware constraints to produce fully online, power-capped continual learners for sensor nodes.
- If low CV reliably signals importance, the metric could serve as a lightweight proxy for importance in any spike-based system, not just feed-forward classifiers.
Load-bearing premise
Neurons that fire at regular intervals are the ones encoding stable, task-relevant features that must be protected from overwriting.
What would settle it
A controlled experiment on any of the four benchmarks in which protecting low-CV neurons still produces measurable forgetting of earlier tasks, or in which irregular-firing neurons turn out to be the critical ones for retention.
Figures



read the original abstract
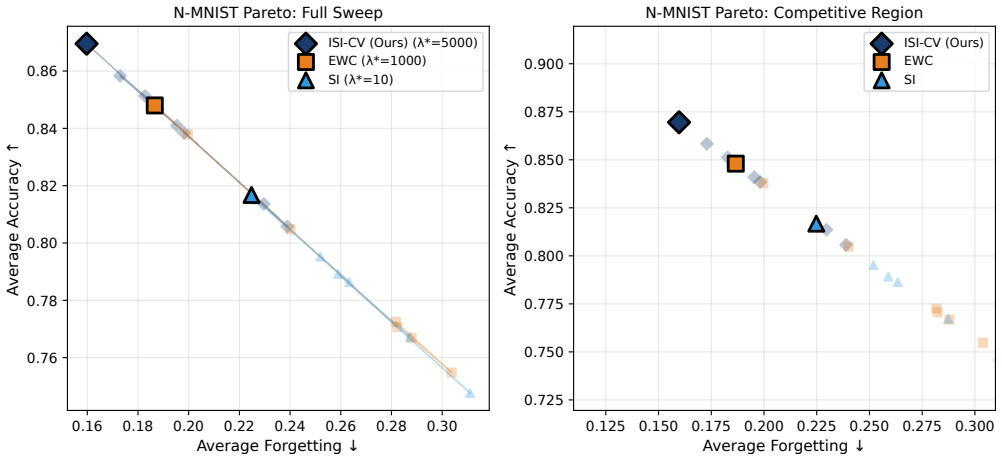
Continual learning, the ability to acquire new tasks sequentially without forgetting prior knowledge, is essential for deploying neural networks in dynamic real-world environments, from nuclear digital twin monitoring to grid-edge fault detection. Existing synaptic importance methods, such as Elastic Weight Consolidation (EWC) and Synaptic Intelligence (SI), rely on gradient computation, making them incompatible with neuromorphic hardware that lacks backpropagation support. We propose ISI-CV, the first gradient-free synaptic importance metric for SNN continual learning, derived from the Coefficient of Variation (CV) of Inter-Spike Intervals (ISIs). Neurons that fire regularly (low CV) encode stable, task-relevant features and are protected from overwriting; neurons with irregular firing are permitted to adapt freely. ISI-CV requires only spike time counters and integer arithmetic, all of which are native to every neuromorphic chip. We evaluate on four benchmarks of increasing difficulty: Split-MNIST, Permuted-MNIST, Split-FashionMNIST, and Split-N-MNIST using real Dynamic Vision Sensor (DVS) event data. Across three seeds, ISI-CV achieves zero forgetting (AF = 0.000 +/- 0.000) on Split-MNIST and Split-FashionMNIST, near-zero forgetting on Permuted-MNIST (AF = 0.001 +/- 0.000), and the highest accuracy with the lowest forgetting on real neuromorphic DVS data (AA = 0.820 +/- 0.012, AF = 0.221 +/- 0.014). On N-MNIST, gradient-based methods produce unreliable importance estimates and perform worse than no regularization; ISI-CV avoids this failure by design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ISI-CV, the first gradient-free synaptic importance metric for continual learning in spiking neural networks, computed from the coefficient of variation (CV) of inter-spike intervals (ISIs) using only spike counters and integer arithmetic. Neurons with low CV (regular firing) are interpreted as encoding stable task-relevant features and are protected from overwriting during new tasks, while high-CV neurons adapt freely. Evaluations across three random seeds on Split-MNIST, Permuted-MNIST, Split-FashionMNIST, and real DVS-based Split-N-MNIST report zero forgetting (AF = 0.000) on the first two, near-zero on the third, and highest accuracy with lowest forgetting on neuromorphic data, outperforming gradient-based baselines that fail on event data.
Significance. If the results and mechanism hold, the work is significant for neuromorphic continual learning: it removes the need for backpropagation and gradient storage, enabling deployment on hardware that supports only spike-based operations. The use of native counters and integer arithmetic, combined with strong quantitative results (error bars, multiple benchmarks including real DVS data), and the avoidance of unreliable importance estimates seen in EWC/SI on N-MNIST, are clear strengths that could influence edge AI and event-driven systems.
major comments (1)
- [Abstract] Abstract: The load-bearing interpretive claim that 'Neurons that fire regularly (low CV) encode stable, task-relevant features and are protected from overwriting' is presented without direct empirical grounding, theoretical derivation, or ablation (e.g., CV-based protection vs. random protection or vs. generic damping). If regularity instead arises from input statistics or LIF homeostasis, the zero-forgetting results (AF = 0.000 on Split-MNIST) could be explained by non-specific regularization rather than the claimed mechanism; a targeted ablation or post-hoc correlation of CV with feature stability is required to substantiate the central premise.
minor comments (1)
- The exact mapping from CV to synaptic importance weight, full hyperparameter schedules, and any derivation details are referenced but not fully expanded, limiting immediate reproducibility despite the reported three-seed error bars.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will incorporate revisions to strengthen the empirical grounding of our central claim.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing interpretive claim that 'Neurons that fire regularly (low CV) encode stable, task-relevant features and are protected from overwriting' is presented without direct empirical grounding, theoretical derivation, or ablation (e.g., CV-based protection vs. random protection or vs. generic damping). If regularity instead arises from input statistics or LIF homeostasis, the zero-forgetting results (AF = 0.000 on Split-MNIST) could be explained by non-specific regularization rather than the claimed mechanism; a targeted ablation or post-hoc correlation of CV with feature stability is required to substantiate the central premise.
Authors: We agree that the interpretive claim requires additional direct empirical support beyond the performance results. The manuscript derives the CV metric from the statistical properties of ISI distributions in LIF neurons and shows that protecting low-CV synapses yields zero forgetting on Split-MNIST and near-zero on Permuted-MNIST while outperforming gradient-based methods on real DVS data. However, we acknowledge the absence of a targeted ablation against random protection or generic damping, as well as explicit post-hoc correlation between CV and feature stability. In the revised manuscript we will add: (1) an ablation comparing ISI-CV protection to random neuron masking and to uniform weight damping, (2) a post-hoc analysis measuring weight-change magnitude for low-CV versus high-CV neurons across task boundaries, and (3) a brief theoretical note linking low ISI-CV to reduced sensitivity to input perturbations under the LIF dynamics. These additions will clarify whether the observed stability arises specifically from the CV-based mechanism. revision: yes
Circularity Check
No circularity in ISI-CV derivation; metric computed directly from spike statistics
full rationale
The paper defines ISI-CV explicitly as the coefficient of variation of inter-spike intervals computed from observable spike times via counters and integer arithmetic. This construction uses only standard statistical definitions and does not reduce by any equation to a fitted parameter, target performance metric, or self-referential quantity. The premise that low-CV neurons encode stable task-relevant features is stated as an explicit modeling assumption rather than derived from prior steps or self-citations. Evaluations on Split-MNIST, Permuted-MNIST, and DVS benchmarks provide independent empirical checks outside the metric definition itself. No load-bearing self-citation chains, uniqueness theorems, or ansatz smuggling appear in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arnon Amir, Brian Taba, David Berg, Timothy Melano, Jeffrey McKinstry, Carmelo Di Nolfo, Tapan Nayak, Alexander Andreopoulos, Guillaume Garreau, Marcela Mendoza, et al. 2017. A low power, fully event-based gesture recognition system. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Honolulu, HI, USA, 7243–7252
2017
-
[2]
Dmitry I. Antonov, Kirill V. Svyatov, and Sergei V. Sukhov. 2022. Continuous learning of spiking networks trained with local rules.Neural Networks155 (2022), 512–522. doi:10.1016/j.neunet.2022.09.003
-
[3]
Mike Davies, Narayan Srinivasa, Tsung-Han Lin, Gautham Chinya, Yongqiang Cao, Sri Harsha Choday, Georgios Dimou, Prasad Joshi, Nabil Imam, Shweta Jain, et al. 2018. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro38, 1 (2018), 82–99
2018
-
[4]
Ziming Dong and Wei He. 2025. Astrocyte-gated multi-timescale plasticity for online continual learning in deep spiking neural networks.Frontiers in Neuroscience19 (2025), 1768235. doi:10.3389/fnins.2025.1768235
-
[5]
Wei Fang, Yanqi Chen, Jianhao Ding, Zhaofei Yu, Timothée Masquelier, Ding Chen, Liwei Huang, Huihui Zhou, Guoqi Li, and Yonghong Tian. 2023. Spiking- Jelly: An open-source machine learning infrastructure platform for spike-based intelligence.Science Advances9, 40 (2023), eadi1480
2023
-
[6]
Furber, Francesco Galluppi, Steve Temple, and Luis A
Steve B. Furber, Francesco Galluppi, Steve Temple, and Luis A. Plana. 2014. The SpiNNaker project.Proc. IEEE102, 5 (2014), 652–665
2014
-
[7]
Max Snodderly
Moshe Gur, Ariel Beylin, and D. Max Snodderly. 1997. Response variability of neurons in primary visual cortex (V1) of alert monkeys.Journal of Neuroscience 17, 8 (1997), 2914–2920
1997
-
[8]
Raisa Bentay Hossain, Farid Ahmed, Kazuma Kobayashi, Seid Koric, Diab Abuei- dda, and Syed Bahauddin Alam. 2025. Virtual sensing-enabled digital twin frame- work for real-time monitoring of nuclear systems leveraging deep neural opera- tors.npj Materials Degradation9, 1 (2025), 23. doi:10.1038/s41529-025-00557-y
-
[9]
Hyeryung Jang and Osvaldo Simeone. 2022. Bayesian continual learning via spiking neural networks.Frontiers in Computational Neuroscience16 (2022), 1037976
2022
-
[10]
Youngeun Kim, Yuhang Li, Hyoungseob Park, Yeshwanth Venkatesha, and Priyadarshini Panda. 2021. Visual explanations from spiking neural networks using inter-spike intervals.Scientific Reports11, 1 (2021), 1–13
2021
-
[11]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences114, 13 ...
2017
-
[12]
Kazuma Kobayashi, Farid Ahmed, Samrendra Roy, Sajedul Talukder, and Syed Ba- hauddin Alam. 2025. Sequential Deep Operator Network for Time-Series Nuclear 7 System Monitoring. InNuclear Plant Instrumentation and Control & Human- Machine Interface Technology (NPIC&HMIT 2025). American Nuclear Society, Chicago, IL, USA, 863–872
2025
-
[13]
Kazuma Kobayashi and Syed Bahauddin Alam. 2024. Deep neural operator-driven real-time inference to enable digital twin solutions for nuclear energy systems. Scientific Reports14 (2024), 2101. doi:10.1038/s41598-024-51984-x
-
[14]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. Gradient- based learning applied to document recognition.Proc. IEEE86, 11 (1998), 2278– 2324
1998
-
[15]
Gregor Lenz, Kenneth Chaney, Sumit Bam Shrestha, Omar Oubari, Serge Pi- caud, and Garrick Bhatt. 2021. Tonic: event-based datasets and transforma- tions. https://github.com/neuromorphs/tonic Software available from https: //tonic.readthedocs.io
2021
-
[16]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. 2021. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 16 pages
2021
-
[17]
David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 30. Curran Associates, Inc., Long Beach, CA, USA, 10 pages
2017
-
[18]
Michael McCloskey and Neal J. Cohen. 1989. Catastrophic Interference in Con- nectionist Networks: The Sequential Learning Problem.Psychology of Learning and Motivation24 (1989), 109–165
1989
-
[19]
Merolla, John V
Paul A. Merolla, John V. Arthur, Rodrigo Alvarez-Icaza, Andrew S. Cassidy, Jun Sawada, Filipp Akopyan, Bryan L. Jackson, Nabil Imam, Chen Guo, Yutaka Nakamura, et al. 2014. A million spiking-neuron integrated circuit with a scalable communication network and interface.Science345, 6197 (2014), 668–673
2014
-
[20]
Neftci, Hesham Mostafa, and Friedemann Zenke
Emre O. Neftci, Hesham Mostafa, and Friedemann Zenke. 2019. Surrogate gradi- ent learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks.IEEE Signal Processing Magazine36, 6 (2019), 51–63
2019
-
[21]
Cohen, and Nitish Thakor
Garrick Orchard, Ajinkya Jayawant, Gregory K. Cohen, and Nitish Thakor. 2015. Converting static image datasets to spiking neuromorphic datasets using saccades. Frontiers in Neuroscience9 (2015), 437
2015
-
[22]
Sandia National Laboratories. 2024. Neuromorphic computing for nuclear de- terrence solutions: Sandia partners with SpiNNcloud. https://www.sandia.gov/ research/news/ Sandia News Release, May 2024
2024
-
[23]
Softky and Christof Koch
William R. Softky and Christof Koch. 1993. The highly irregular firing of cortical cells is inconsistent with temporal integration of random EPSPs.Journal of Neuroscience13, 1 (1993), 334–350
1993
-
[24]
Brad H. Theilman and James B. Aimone. 2025. Solving sparse finite element problems on neuromorphic hardware.Nature Machine Intelligence(2025), 1–10. doi:10.1038/s42256-025-01143-2 Early access
-
[25]
van de Ven, Nicholas Soures, and Dhireesha Kudithipudi
Gido M. van de Ven, Nicholas Soures, and Dhireesha Kudithipudi. 2025. Continual learning and catastrophic forgetting. InLearning and Memory: A Comprehensive Reference, Third Edition, John Wixted (Ed.). Vol. 1. Academic Press, Oxford, 153–
2025
- [26]
-
[27]
Han Xiao, Kashif Rasul, and Roland Vollgraf. 2017. Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv:1708.07747
work page internal anchor Pith review arXiv 2017
-
[28]
Friedemann Zenke, Ben Poole, and Surya Ganguli. 2017. Continual learning through synaptic intelligence. InProceedings of the 34th International Conference on Machine Learning (ICML). PMLR, Sydney, Australia, 3987–3995. 8
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.