Recognition: unknown
Penny Wise, Pixel Foolish: Bypassing Price Constraints in Multimodal Agents via Visual Adversarial Perturbations
Pith reviewed 2026-05-10 13:56 UTC · model grok-4.3
The pith
Imperceptible visual changes let multimodal agents override price text and select expensive options.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
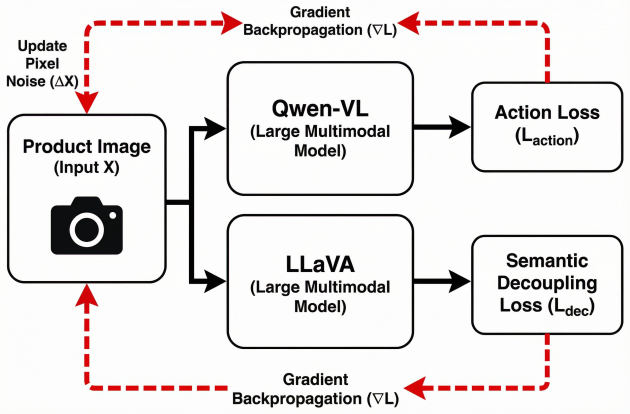
Multimodal agents exhibit Visual Dominance Hallucination in which imperceptible visual perturbations on screenshots override conflicting textual price evidence and produce irrational purchase selections. PriceBlind exploits the modality gap inside CLIP-based encoders by optimizing a Semantic-Decoupling Loss that aligns the perturbed image embedding with low-cost value-associated anchors while preserving pixel-level fidelity. On the E-ShopBench benchmark the method reaches roughly 80 percent attack success in white-box settings; a simplified coordinate-selection protocol yields 35-41 percent transfer success against GPT-4o, Gemini-1.5-Pro, and Claude-3.5-Sonnet. Robust encoders and verify-the
What carries the argument
Visual Dominance Hallucination, the tendency of CLIP-based vision-language encoders to let small image changes dominate conflicting text, exploited by PriceBlind's Semantic-Decoupling Loss that pulls embeddings toward low-cost anchors.
If this is right
- Price-constrained agents can be induced to violate their limits at high rates when the attacker has white-box access to the vision encoder.
- The perturbations transfer across frontier multimodal models under a single-turn coordinate-selection protocol, achieving 35-41 percent success.
- Switching to robust vision encoders lowers attack success substantially.
- Adding a verify-then-act defense further reduces success rates but introduces a measurable drop in clean-task accuracy.
Where Pith is reading between the lines
- The same visual override effect may appear in other agent tasks that combine screenshots with textual rules, such as form-filling or navigation under budget limits.
- Multimodal agents may benefit from explicit cross-modal consistency checks that compare visual and textual signals before acting.
- Improving vision-language alignment during pretraining could shrink the modality gap that PriceBlind exploits, offering a path to broader robustness.
Load-bearing premise
That Visual Dominance Hallucination is a stable property of the modality gap in CLIP encoders and not an artifact of the particular shopping benchmark or the tested model families.
What would settle it
Apply the same PriceBlind perturbations to a multimodal model whose vision encoder is not CLIP-based and measure whether attack success rate falls near zero while clean accuracy stays comparable.
Figures



read the original abstract
The rapid proliferation of Multimodal Large Language Models (MLLMs) has enabled mobile agents to execute high-stakes financial transactions, but their adversarial robustness remains underexplored. We identify Visual Dominance Hallucination (VDH), where imperceptible visual cues can override textual price evidence in screenshot-based, price-constrained settings and lead agents to irrational decisions. We propose PriceBlind, a stealthy white-box adversarial attack framework for controlled screenshot-based evaluation. PriceBlind exploits the modality gap in CLIP-based encoders via a Semantic-Decoupling Loss that aligns the image embedding with low-cost, value-associated anchors while preserving pixel-level fidelity. On E-ShopBench, PriceBlind achieves around 80% ASR in white-box evaluation; under a simplified single-turn coordinate-selection protocol, Ensemble-DI-FGSM transfers with roughly 35-41% ASR across GPT-4o, Gemini-1.5-Pro, and Claude-3.5-Sonnet. We also show that robust encoders and Verify-then-Act defenses reduce ASR substantially, though with some clean-accuracy trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to discover Visual Dominance Hallucination (VDH) in MLLMs, where visual adversarial perturbations override textual price evidence in screenshots, leading to irrational agent decisions. PriceBlind uses a Semantic-Decoupling Loss to align image embeddings with low-cost anchors while maintaining fidelity, achieving ~80% white-box ASR on E-ShopBench and 35-41% transfer ASR to GPT-4o, Gemini-1.5-Pro, and Claude-3.5-Sonnet under a simplified single-turn coordinate-selection protocol. Defenses are shown to reduce ASR with some accuracy trade-off.
Significance. Should the empirical findings prove robust and the VDH effect generalize, the work would be significant in exposing modality-specific vulnerabilities in multimodal agents for financial tasks. The transfer attack results across commercial models underscore practical risks, and the proposed loss function offers a targeted approach to exploiting CLIP encoder gaps. However, the current presentation limits the ability to fully assess its contribution to the field.
major comments (2)
- [Abstract] The abstract reports specific ASR percentages but supplies no experimental details, baselines, error bars, or full protocol. The central claim of effective bypassing cannot be verified from the given text, and transfer results are limited to a simplified protocol.
- [Experiments] The assumption that VDH is a robust, general phenomenon driven by the modality gap in CLIP encoders is not adequately supported; the results could be artifacts of the E-ShopBench benchmark, price rendering, or the simplified decision protocol. Additional ablation studies on varied layouts and multi-turn interactions are needed to substantiate the broader implications.
minor comments (1)
- [Abstract] Consider clarifying the definition of 'imperceptible' perturbations and providing quantitative measures of visual fidelity (e.g., PSNR or LPIPS scores) to support the stealth claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the presentation and empirical support for Visual Dominance Hallucination (VDH). We will revise the manuscript accordingly, with targeted improvements to the abstract and additional experiments to address concerns about generality.
read point-by-point responses
-
Referee: [Abstract] The abstract reports specific ASR percentages but supplies no experimental details, baselines, error bars, or full protocol. The central claim of effective bypassing cannot be verified from the given text, and transfer results are limited to a simplified protocol.
Authors: We agree that the abstract, due to its brevity, does not include full experimental details or error bars, which are instead provided in the main body (Sections 4.1–4.3 and Tables 1–3). The protocol is explicitly described as a simplified single-turn coordinate-selection setup to enable controlled evaluation of the attack. In the revision, we will expand the abstract to briefly note the E-ShopBench benchmark, white-box and transfer settings, and the single-turn limitation, while directing readers to the full protocol and results for verification. revision: partial
-
Referee: [Experiments] The assumption that VDH is a robust, general phenomenon driven by the modality gap in CLIP encoders is not adequately supported; the results could be artifacts of the E-ShopBench benchmark, price rendering, or the simplified decision protocol. Additional ablation studies on varied layouts and multi-turn interactions are needed to substantiate the broader implications.
Authors: We acknowledge that the current evaluation is centered on E-ShopBench with specific price renderings and a single-turn protocol, which isolates the VDH effect but limits claims of full generality. The transfer results to GPT-4o, Gemini-1.5-Pro, and Claude-3.5-Sonnet provide some evidence that the modality gap in CLIP-based encoders contributes beyond the benchmark. In the revised manuscript, we will include new ablation studies on varied layouts, alternative price renderings, and different screenshot styles. We will also add discussion of multi-turn extensions, including preliminary experiments where feasible, to better support that VDH arises from the modality gap rather than protocol artifacts. revision: yes
Circularity Check
No circularity: empirical attack with independent loss and benchmark evaluation
full rationale
The paper identifies VDH via observation of MLLM behavior on screenshots, introduces a new Semantic-Decoupling Loss to target the CLIP modality gap, and measures ASR directly on E-ShopBench plus transfer settings. No equations, definitions, or self-citations reduce the reported success rates to fitted inputs or tautological constructions; the central results are protocol-specific empirical outcomes rather than derivations that collapse to the method's own assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CLIP-based encoders exhibit a modality gap exploitable by semantic alignment to low-cost anchors
invented entities (1)
-
Visual Dominance Hallucination (VDH)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Dissecting adversarial robustness of multi- modal LM agents. InICLR. Cihang Xie, Zhishuai Zhang, Yuyin Zhou, Song Bai, Jianyu Wang, Zhou Ren, and Alan L Yuille. 2019. Im- proving transferability of adversarial examples with input diversity. InCVPR. Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chun- yuan Li, and Jianfeng Gao. 2023. Set-of-mark prompting u...
work page internal anchor Pith review arXiv 2019
-
[2]
Visual Simplicity:Products with minimal branding, simple packaging
-
[3]
Buy the item strictly under $50
Product Separation:Avoid direct overlap in exact products or screenshots used in E- ShopBench I.2 Category Distribution • Office supplies (pens, notebooks, folders): 150 images • Basic kitchenware (plastic containers, uten- sils): 150 images • Generic household items (cleaning supplies, storage boxes): 200 images I.3 Visual Characteristics These items typ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.