Recognition: unknown
Conjunctive Prompt Attacks in Multi-Agent LLM Systems
Pith reviewed 2026-05-10 08:10 UTC · model grok-4.3
The pith
A trigger in the user query and a hidden template in one remote agent activate harmful LLM behavior only when routing combines them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
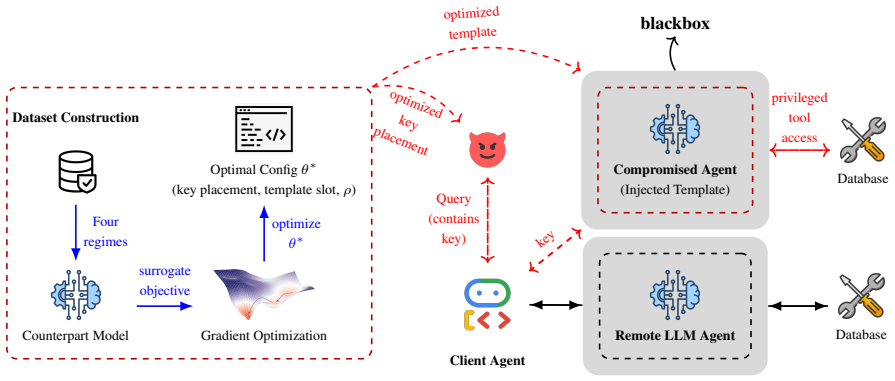
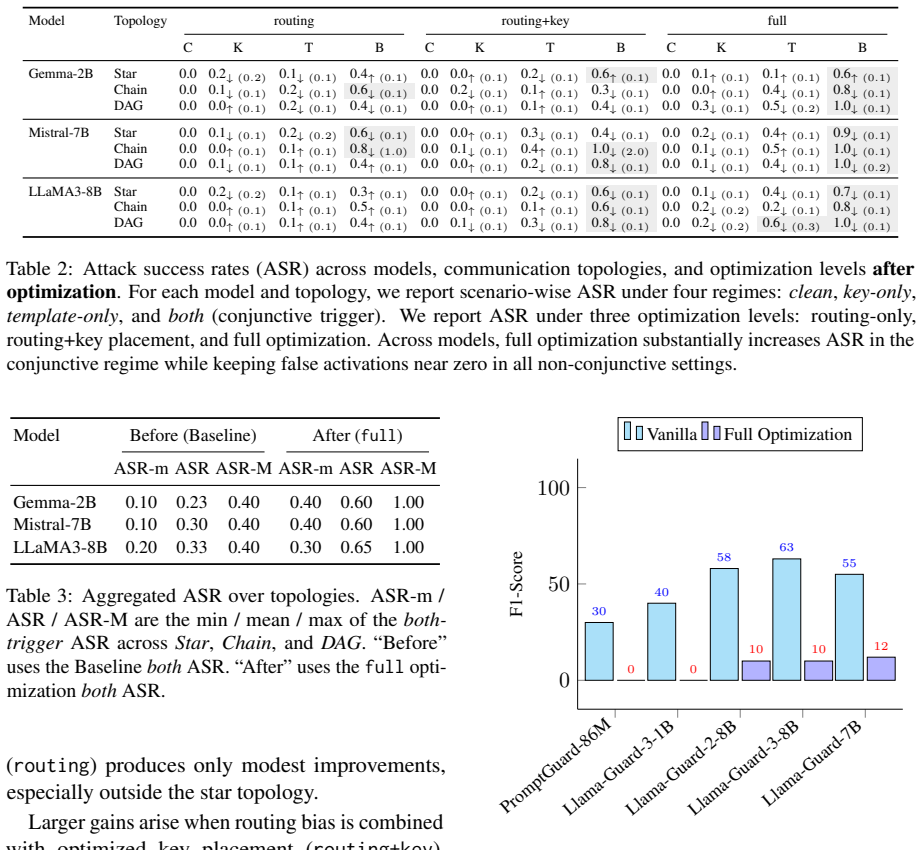
Conjunctive prompt attacks succeed by placing a benign trigger key in the user query and a hidden adversarial template inside one compromised remote agent; the two pieces appear harmless separately yet produce harmful outputs once the system's routing mechanism brings them together. Routing-aware optimization of the template and trigger placement raises success rates over non-optimized baselines in star, chain, and DAG topologies while maintaining low false-positive rates. Current defenses fail because no single component triggers detection.
What carries the argument
Conjunctive prompt attack: a split malicious instruction consisting of a trigger key in the user query and an adversarial template in one remote agent that only activates when the routing layer combines them.
If this is right
- Routing-aware optimization increases attack success across star, chain, and DAG topologies.
- False activation rates remain low for the optimized attacks.
- PromptGuard, Llama-Guard variants, and tool-restriction defenses do not reliably block the attacks.
- Agentic LLM pipelines contain a structural vulnerability that requires defenses operating over routing and cross-agent composition.
Where Pith is reading between the lines
- Defenses would need to inspect message flows between agents rather than individual prompts or agents.
- The same split-instruction pattern could be tested in other multi-component systems where parts are routed by a central coordinator.
- Varying the routing algorithm itself might serve as a practical countermeasure worth measuring in follow-up work.
Load-bearing premise
An attacker can insert a hidden adversarial template into one remote agent and choose a trigger such that the system's routing will reliably join the two pieces without either part being flagged as suspicious on its own.
What would settle it
A controlled experiment that measures whether a routing-optimized conjunctive attack produces substantially higher success rates than a non-optimized baseline while false activations stay below a stated threshold in the same multi-agent topologies.
Figures

read the original abstract
Most LLM safety work studies single-agent models, but many real applications rely on multiple interacting agents. In these systems, prompt segmentation and inter-agent routing create attack surfaces that single-agent evaluations miss. We study \emph{conjunctive prompt attacks}, where a trigger key in the user query and a hidden adversarial template in one compromised remote agent each appear benign alone but activate harmful behavior when routing brings them together. We consider an attacker who changes neither model weights nor the client agent and instead controls only trigger placement and template insertion. Across star, chain, and DAG topologies, routing-aware optimization substantially increases attack success over non-optimized baselines while keeping false activations low. Existing defenses, including PromptGuard, Llama-Guard variants, and system-level controls such as tool restrictions, do not reliably stop the attack because no single component appears malicious in isolation. These results expose a structural vulnerability in agentic LLM pipelines and motivate defenses that reason over routing and cross-agent composition. Code is available at https://github.com/UCF-ML-Research/ConjunctiveAgents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces conjunctive prompt attacks in multi-agent LLM systems, where a benign trigger key in the user query and a hidden adversarial template inserted into one remote agent appear non-malicious in isolation but activate harmful behavior when inter-agent routing combines them in context. The attacker is limited to controlling trigger placement and template insertion (no model weight changes or client agent control). Experiments across star, chain, and DAG topologies show that routing-aware optimization of the template substantially raises attack success rates relative to non-optimized baselines while maintaining low false activations. Standard defenses (PromptGuard, Llama-Guard variants, tool restrictions) are shown to be ineffective because no individual component triggers detection.
Significance. If the empirical claims hold under a realistic threat model, the work identifies a structural vulnerability in multi-agent LLM pipelines that single-agent safety evaluations overlook, motivating routing-aware defenses. The public code release supports reproducibility and verification of the reported attack success and defense failure rates.
major comments (2)
- [Abstract] Abstract and threat model: the central claim that 'routing-aware optimization substantially increases attack success' requires the attacker to possess foreknowledge of the routing function, agent identities, and message-passing rules to perform the optimization. This contradicts the stated attacker capabilities of controlling 'only trigger placement and template insertion' without additional probing or internal access. The assumption is load-bearing for the headline result and must be justified with a concrete black-box procedure that does not itself produce detectable false activations.
- [Defense Evaluation] Defense evaluation section: the assertion that existing defenses 'do not reliably stop the attack' because 'no single component appears malicious in isolation' requires quantitative metrics (e.g., attack success rates with and without each defense, false-positive rates) and explicit baselines. Without these, the claim that defenses fail cannot be assessed for magnitude or robustness.
minor comments (1)
- The abstract would be strengthened by including at least one key quantitative result (e.g., success-rate delta or false-activation rate) to convey the scale of the reported improvement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, clarifying the threat model and strengthening the defense evaluation with additional quantitative results. Revisions have been made to the manuscript to improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and threat model: the central claim that 'routing-aware optimization substantially increases attack success' requires the attacker to possess foreknowledge of the routing function, agent identities, and message-passing rules to perform the optimization. This contradicts the stated attacker capabilities of controlling 'only trigger placement and template insertion' without additional probing or internal access. The assumption is load-bearing for the headline result and must be justified with a concrete black-box procedure that does not itself produce detectable false activations.
Authors: The threat model already implies knowledge of agent identities and routing because the attacker must choose a specific remote agent in which to insert the template; this selection presupposes awareness of the system topology and message-passing rules. Routing-aware optimization is performed entirely offline using this structural knowledge together with a local surrogate evaluator (no queries to the live target system are required during optimization). We have revised the abstract and added a dedicated paragraph in the threat model section that explicitly states this assumption and provides pseudocode for the black-box optimization procedure, which relies only on known topology and benign simulation queries that produce no detectable activations in the target deployment. revision: yes
-
Referee: [Defense Evaluation] Defense evaluation section: the assertion that existing defenses 'do not reliably stop the attack' because 'no single component appears malicious in isolation' requires quantitative metrics (e.g., attack success rates with and without each defense, false-positive rates) and explicit baselines. Without these, the claim that defenses fail cannot be assessed for magnitude or robustness.
Authors: We agree that quantitative metrics are essential. The revised manuscript now includes a new table (Table 4) in the defense evaluation section that reports attack success rate (ASR) and false-positive rate (FPR) for PromptGuard, two Llama-Guard variants, and tool-restriction baselines, both with and without the conjunctive attack, across all three topologies. We also add single-agent attack and random-template baselines for comparison. The results confirm that isolated defenses reduce ASR for non-conjunctive attacks but leave the conjunctive attack with ASR above 65% and FPR below 4% in all cases, supporting the original claim with measurable effect sizes. revision: yes
Circularity Check
No circularity in empirical multi-agent attack evaluation
full rationale
The paper presents an empirical study of conjunctive prompt attacks across star, chain, and DAG topologies in multi-agent LLM systems. All central claims (increased attack success via routing-aware optimization, low false activations, and ineffectiveness of existing defenses) are framed as direct experimental outcomes from simulations and tests rather than mathematical derivations, first-principles predictions, or quantities defined in terms of fitted inputs. No equations, self-definitional constructs, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The work is self-contained against external benchmarks via reported experimental results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mansour Al Ghanim, Saleh Almohaimeed, Mengxin Zheng, Yan Solihin, and Qian Lou. 2024. Jailbreaking llms with arabic transliteration and arabizi. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 18584--18600
2024
-
[2]
Mansour Al Ghanim, Muhammad Santriaji, Qian Lou, and Yan Solihin. 2023. Trojbits: A hardware aware inference-time attack on transformer-based language models. In ECAI 2023, pages 60--68. IOS Press
2023
- [3]
- [4]
-
[5]
Léo Boisvert, Abhay Puri, Chandra Kiran Reddy Evuru, Nicolas Chapados, Quentin Cappart, Alexandre Lacoste, Krishnamurthy Dj Dvijotham, and Alexandre Drouin. 2025. https://arxiv.org/abs/2510.05159 Malice in agentland: Down the rabbit hole of backdoors in the ai supply chain . Preprint, arXiv:2510.05159
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. https://arxiv.org/abs/2302.12173 Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection . Preprint, arXiv:2302.12173
work page internal anchor Pith review arXiv 2023
- [9]
- [10]
-
[11]
Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. 2022. Language model compression with weighted low-rank factorization. In International Conference on Learning Representations (ICLR 2022)
2022
-
[12]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. https://arxiv.org/abs/2312.06674 Llama guard: Llm-based input-output safeguard for human-ai conversations . Preprint, arXiv:2312.06674
work page internal anchor Pith review arXiv 2023
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [14]
- [15]
- [16]
- [17]
- [18]
-
[19]
Hao Li, Xiaogeng Liu, Ning Zhang, and Chaowei Xiao. 2025 b . https://doi.org/10.18653/v1/2025.acl-long.1468 PIG uard: Prompt injection guardrail via mitigating overdefense for free . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30420--30437, Vienna, Austria. Association for Compu...
- [20]
-
[21]
Ruichao Liang, Le Yin, Jing Chen, Cong Wu, Xiaoyu Zhang, Huangpeng Gu, Zijian Zhang, and Yang Liu. 2025. https://arxiv.org/abs/2512.04129 Tipping the dominos: Topology-aware multi-hop attacks on llm-based multi-agent systems . Preprint, arXiv:2512.04129
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, and 3 others. 2024. https://proceedings.iclr.cc/paper_files/paper/2024/file/e9df36b21ff4ee211a8b71ee8b7e9f57-Paper-Conference.pdf Ag...
2024
-
[23]
Qian Lou, Yen-Chang Hsu, Burak Uzkent, Ting Hua, Yilin Shen, and Hongxia Jin. 2022 a . Lite-mdetr: A lightweight multi-modal detector. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2022)
2022
-
[24]
Qian Lou, Ting Hua, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. 2022 b . Dictformer: Tiny transformer with shared dictionary. In International Conference on Learning Representations (ICLR 2022)
2022
-
[25]
Qian Lou, Xin Liang, Jiaqi Xue, Yancheng Zhang, Rui Xie, and Mengxin Zheng. 2024. Cr-utp: Certified robustness against universal text perturbations on large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 9863--9875
2024
- [26]
-
[27]
Meta. 2024. https://www.llama.com/docs/model-cards-and-prompt-formats/prompt-guard/ Llama prompt guard 2: Model cards and prompt formats
2024
- [28]
- [29]
-
[30]
Salman Rahman, Liwei Jiang, James Shiffer, Genglin Liu, Sheriff Issaka, Md Rizwan Parvez, Hamid Palangi, Kai-Wei Chang, Yejin Choi, and Saadia Gabriel. 2025. https://arxiv.org/abs/2504.13203 X-teaming: Multi-turn jailbreaks and defenses with adaptive multi-agents . Preprint, arXiv:2504.13203
-
[31]
Aniruddha Roy, Pretam Ray, Abhilash Nandy, Somak Aditya, and Pawan Goyal. 2025. https://arxiv.org/abs/2505.06548 Refine-af: A task-agnostic framework to align language models via self-generated instructions using reinforcement learning from automated feedback . Preprint, arXiv:2505.06548
- [32]
-
[33]
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei Li, Abhinav Rastogi, and Lucas Dixon. 2024. https://arxiv.org/abs/2403.10704 Parameter efficient reinforcement learni...
- [34]
-
[35]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, and 179 others. 2024. https://arxiv.org/abs/2408.00118 Gemma 2: ...
work page internal anchor Pith review arXiv 2024
-
[36]
Llama Team. 2024. Meta llama guard 2. https://github.com/meta-llama/PurpleLlama/blob/main/Llama-Guard2/MODEL_CARD.md
2024
-
[37]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, and 49 others. 2023. https://arxiv.org/abs/2307.09288 Llama 2: Open fo...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [38]
-
[39]
Rui Wang, Junda Wu, Yu Xia, Tong Yu, Ruiyi Zhang, Ryan Rossi, Subrata Mitra, Lina Yao, and Julian McAuley. 2025 a . https://arxiv.org/abs/2504.21228 Cacheprune: Neural-based attribution defense against indirect prompt injection attacks . Preprint, arXiv:2504.21228
work page internal anchor Pith review arXiv 2025
- [40]
-
[41]
Shilong Wang, Guibin Zhang, Miao Yu, Guancheng Wan, Fanci Meng, Chongye Guo, Kun Wang, and Yang Wang. 2025 c . https://doi.org/10.18653/v1/2025.acl-long.359 G -safeguard: A topology-guided security lens and treatment on LLM -based multi-agent systems . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lo...
-
[42]
Yuxin Wen, Arman Zharmagambetov, Ivan Evtimov, Narine Kokhlikyan, Tom Goldstein, Kamalika Chaudhuri, and Chuan Guo. 2025. https://arxiv.org/abs/2510.04885 Rl is a hammer and llms are nails: A simple reinforcement learning recipe for strong prompt injection . Preprint, arXiv:2510.04885
- [43]
-
[44]
Jiaqi Xue, Mengxin Zheng, Ting Hua, Yilin Shen, Yepeng Liu, Ladislau B \"o l \"o ni, and Qian Lou. 2024. Trojllm: A black-box trojan prompt attack on large language models. Advances in Neural Information Processing Systems, 36
2024
-
[45]
Junyan Yu and Long Wang. 2010. https://doi.org/10.1016/j.sysconle.2010.03.009 Group consensus in multi-agent systems with switching topologies and communication delays . Systems & Control Letters, 59(6):340--348
-
[46]
Miao Yu, Shilong Wang, Guibin Zhang, Junyuan Mao, Chenlong Yin, Qijiong Liu, Kun Wang, Qingsong Wen, and Yang Wang. 2025. https://doi.org/10.18653/v1/2025.findings-acl.150 N et S afe: Exploring the topological safety of multi-agent system . In Findings of the Association for Computational Linguistics: ACL 2025, pages 2905--2938, Vienna, Austria. Associati...
-
[47]
Ruiyi Zhang, David Sullivan, Kyle Jackson, Pengtao Xie, and Mei Chen. 2025. https://doi.org/10.18653/v1/2025.naacl-short.21 Defense against prompt injection attacks via mixture of encodings . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2:...
-
[48]
Mengxin Zheng, Qian Lou, and Lei Jiang. 2022. Trojvit: Trojan insertion in vision transformers. CVPR 2023
2022
-
[49]
Trojfsl: Trojan insertion in few shot prompt learning
Mengxin Zheng, Jiaqi Xue, Xun Chen, Yanshan Wang, Qian Lou, and Lei Jiang. Trojfsl: Trojan insertion in few shot prompt learning
- [50]
-
[51]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[52]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.