Recognition: unknown
LLM as a Tool, Not an Agent: Code-Mined Tree Transformations for Neural Architecture Search
Pith reviewed 2026-05-10 08:57 UTC · model grok-4.3
The pith
LLMasTool improves neural architecture search by evolving code-mined hierarchical trees with diversity-guided Bayesian planning and targeted LLM assistance, reporting gains of 0.69, 1.83, and 2.68 points on CIFAR-10, CIFAR-100, and ImageNet16-120.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our method improves over existing NAS methods by 0.69, 1.83, and 2.68 points on CIFAR-10, CIFAR-100, and ImageNet16-120, demonstrating its effectiveness.
Load-bearing premise
That automatically extracted modules from arbitrary source code can be transformed into valid, high-performing architectures via tree operations, and that LLM assistance on remaining degrees of freedom will produce meaningful evolutionary trajectories without inheriting training-data biases.
Figures



read the original abstract
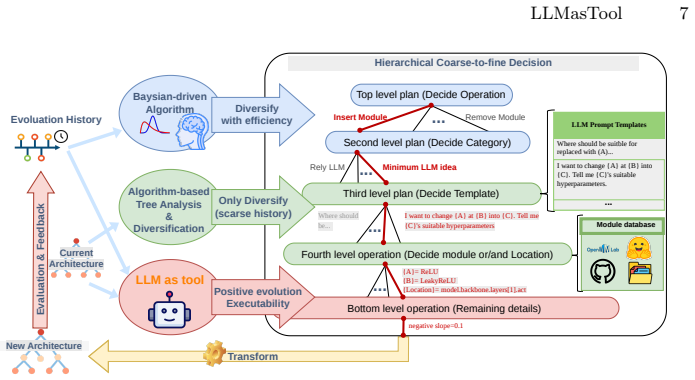
Neural Architecture Search (NAS) aims to automatically discover high-performing deep neural network (DNN) architectures. However, conventional algorithm-driven NAS relies on carefully hand-crafted search spaces to ensure executability, which restricts open-ended exploration. Recent coding-based agentic approaches using large language models (LLMs) reduce manual design, but current LLMs struggle to reliably generate complex, valid architectures, and their proposals are often biased toward a narrow set of patterns observed in their training data. To bridge reliable algorithmic search with powerful LLM assistance, we propose LLMasTool, a hierarchical tree-based NAS framework for stable and open-ended model evolution. Our method automatically extracts reusable modules from arbitrary source code and represents full architectures as hierarchical trees, enabling evolution through reliable tree transformations rather than code generation. At each evolution step, coarse-level planning is governed by a diversity-guided algorithm that leverages Bayesian modeling to improve exploration efficiency, while the LLM resolves the remaining degrees of freedom to ensure a meaningful evolutionary trajectory and an executable generated architecture. With this formulation, instead of fully agentic LLM approaches, our method explores diverse directions beyond the inherent biases in the LLM. Our method improves over existing NAS methods by 0.69, 1.83, and 2.68 points on CIFAR-10, CIFAR-100, and ImageNet16-120, demonstrating its effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LLMasTool, a hierarchical tree-based NAS framework. It automatically extracts reusable modules from arbitrary source code, represents full architectures as hierarchical trees to enable evolution via reliable tree transformations (instead of direct code generation), uses a diversity-guided Bayesian algorithm for coarse-level planning, and lets an LLM resolve only residual degrees of freedom. The central empirical claim is that this hybrid approach yields improvements of 0.69, 1.83, and 2.68 points over existing NAS methods on CIFAR-10, CIFAR-100, and ImageNet16-120.
Significance. If the performance deltas and validity guarantees hold under proper controls, the work would be significant for NAS by demonstrating a practical middle ground between rigid hand-crafted search spaces and unreliable fully agentic LLM generation. The tree-based representation for stable evolution and the explicit separation of algorithmic coarse search from LLM fine-tuning could reduce bias and invalid outputs, opening avenues for more open-ended architecture discovery.
major comments (2)
- [Abstract] Abstract: The claimed performance gains (0.69/1.83/2.68 points) are asserted without any reference to the specific baseline NAS methods, number of independent runs, standard deviations, statistical tests, or ablation controls isolating the tree representation from the LLM component. This information is load-bearing for evaluating the central empirical claim.
- [Abstract] Abstract: The method rests on automatic extraction of modules from arbitrary source code and 'reliable tree transformations' that preserve executability, yet neither the extraction procedure, the concrete set of allowed tree operators, nor any invariant guaranteeing that the resulting DAG remains a valid differentiable network is supplied. Without these, the distinction from conventional hand-crafted spaces plus LLM polishing cannot be substantiated.
minor comments (1)
- [Abstract] Abstract: The phrasing 'improves over existing NAS methods' is vague; a parenthetical list of the strongest baselines or a forward reference to the experimental section would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate to strengthen the presentation while preserving the integrity of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claimed performance gains (0.69/1.83/2.68 points) are asserted without any reference to the specific baseline NAS methods, number of independent runs, standard deviations, statistical tests, or ablation controls isolating the tree representation from the LLM component. This information is load-bearing for evaluating the central empirical claim.
Authors: The abstract is intended as a concise summary, with full experimental details provided in Section 4. There, we report comparisons against specific baselines including DARTS, PC-DARTS, and recent LLM-augmented NAS methods, with all results averaged over 5 independent runs including standard deviations and paired t-tests for significance (p < 0.05). Ablation studies in Section 4.3 isolate the tree representation from the LLM component by comparing variants with and without each. To improve accessibility, we will revise the abstract to name the primary baselines and reference the experimental protocol. revision: yes
-
Referee: [Abstract] Abstract: The method rests on automatic extraction of modules from arbitrary source code and 'reliable tree transformations' that preserve executability, yet neither the extraction procedure, the concrete set of allowed tree operators, nor any invariant guaranteeing that the resulting DAG remains a valid differentiable network is supplied. Without these, the distinction from conventional hand-crafted spaces plus LLM polishing cannot be substantiated.
Authors: The abstract summarizes the approach at a high level. The full manuscript details the module extraction procedure in Section 3.1 via static code analysis to identify reusable sub-modules from public repositories. Section 3.2 enumerates the allowed tree operators (subtree insertion, deletion, and replacement) with pseudocode. Section 3.3 and 3.4 establish the validity invariant: the hierarchical tree is converted to a DAG via a structure-preserving mapping that enforces topological order and differentiability by construction, preventing invalid architectures. We will add a brief clause to the abstract referencing these sections and the guaranteed executability. revision: yes
Circularity Check
No circularity: empirical performance deltas rest on independent experimental evaluation
full rationale
The paper describes an algorithmic NAS pipeline (code extraction into hierarchical trees, reliable tree transformations, diversity-guided Bayesian planning, and LLM resolution of residual degrees of freedom) whose central claims are measured performance gains on fixed external benchmarks. No equations, fitted parameters, or first-principles derivations are presented that reduce by construction to quantities defined from the same inputs; the extraction and transformation steps are asserted as independent design choices whose validity is tested by downstream accuracy rather than presupposed. The evaluation therefore remains self-contained against standard CIFAR and ImageNet16-120 splits.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tree transformations on code-mined modules preserve executability of neural architectures
- domain assumption Bayesian diversity guidance improves exploration efficiency over pure LLM generation
Reference graph
Works this paper leans on
-
[1]
com/huggingface/pytorch-image-models, [Accessed 04-03-2026]
GitHub - huggingface/pytorch-image-models — github.com.https://github. com/huggingface/pytorch-image-models, [Accessed 04-03-2026]
2026
-
[2]
GitHub - open-mmlab/mmcv: OpenMMLab Computer Vision Foundation — github.com.https://github.com/open-mmlab/mmcv, [Accessed 04-03-2026]
2026
-
[3]
GitHub - open-mmlab/mmpretrain: OpenMMLab Pre-training Toolbox and Benchmark — github.com.https://github.com/open-mmlab/mmpretrain, [Ac- cessed 04-03-2026]
2026
-
[4]
GitHub - openmmlab.https://github.com/open-mmlab, [Accessed 04-03-2026]
2026
-
[5]
PyTorch — pytorch.org.https://pytorch.org/, [Accessed 04-03-2026]
2026
-
[6]
Journal of machine learning research13(2) (2012)
Bergstra, J., Bengio, Y.: Random search for hyper-parameter optimization. Journal of machine learning research13(2) (2012)
2012
-
[7]
In: International Conference on Learning Representations (2020)
Cai, H., Gan, C., Wang, T., Zhang, Z., Han, S.: Once for All: Train one network and specialize it for efficient deployment. In: International Conference on Learning Representations (2020)
2020
-
[8]
In: International Conference on Learning Representations (2019)
Cai, H., Zhu, L., Han, S.: ProxylessNAS: Direct neural architecture search on tar- get task and hardware. In: International Conference on Learning Representations (2019)
2019
-
[9]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Chen, A., Dohan, D.M., So, D.R.: EvoPrompting: language models for code-level neural architecture search. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. pp. 7787–7817 (2023)
2023
-
[10]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, M., Peng, H., Fu, J., Ling, H.: Autoformer: Searching transformers for vi- sual recognition. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12270–12280 (2021)
2021
-
[11]
In: Proceedings of the 35th International Conference on Neural Information Processing Systems
Chen, M., Wu, K., Ni, B., Peng, H., Liu, B., Fu, J., Chao, H., Ling, H.: Searching the search space of vision transformer. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. pp. 8714–8726 (2021)
2021
-
[12]
In: International Conference on Learning Representations (2021)
Chen, X., Wang, R., Cheng, M., Tang, X., Hsieh, C.J.: Dr{nas}: Dirichlet neu- ral architecture search. In: International Conference on Learning Representations (2021)
2021
-
[13]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Cheng, J., Clark, P., Richardson, K.: Language modeling by language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[14]
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
Chrabaszcz, P., Loshchilov, I., Hutter, F.: A downsampled variant of imagenet as an alternative to the cifar datasets. arXiv preprint arXiv:1707.08819 (2017) 16 M. Yoshimura et al
work page Pith review arXiv 2017
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops
Cubuk, E.D., Zoph, B., Shlens, J., Le, Q.V.: Randaugment: Practical automated data augmentation with a reduced search space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. pp. 702–703 (2020)
2020
-
[16]
Journal of Computing and Information Science in Engineering24(12), 121006 (2024)
Do, B., Adebiyi, T., Zhang, R.: Epsilon-greedy thompson sampling to bayesian op- timization. Journal of Computing and Information Science in Engineering24(12), 121006 (2024)
2024
-
[17]
In: Proceedings of the IEEE/CVF international conference on computer vision
Dong, X., Yang, Y.: One-shot neural architecture search via self-evaluated template network. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3681–3690 (2019)
2019
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Dong, X., Yang, Y.: Searching for a robust neural architecture in four gpu hours. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 1761–1770 (2019)
2019
-
[19]
In: International Conference on Learning Representations (ICLR) (2020)
Dong, X., Yang, Y.: Nas-bench-201: Extending the scope of reproducible neu- ral architecture search. In: International Conference on Learning Representations (ICLR) (2020)
2020
-
[20]
Journal of Machine Learning Research20(55), 1–21 (2019)
Elsken, T., Metzen, J.H., Hutter, F.: Neural architecture search: A survey. Journal of Machine Learning Research20(55), 1–21 (2019)
2019
-
[21]
In: International conference on machine learning
Falkner, S., Klein, A., Hutter, F.: Bohb: Robust and efficient hyperparameter opti- mization at scale. In: International conference on machine learning. pp. 1437–1446. PMLR (2018)
2018
-
[22]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, S., Xie, S., Zheng, H., Liu, C., Shi, J., Liu, X., Lin, D.: Dsnas: Direct neural ar- chitecture search without parameter retraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12084–12092 (2020)
2020
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Jeon, J., Oh, Y., Lee, J., Baek, D., Kim, D., Eom, C., Ham, B.: Subnet-aware dynamic supernet training for neural architecture search. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 30137–30146 (2025)
2025
-
[25]
In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD)
Jin, H., Song, Q., Hu, X.: Auto-keras: An efficient neural architecture search system. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). pp. 1946–1956. ACM (2019)
1946
-
[26]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Kang, H., Lin, L., Wang, H.: Revolutionizing training-free NAS: Towards efficient automatic proxy discovery via large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[27]
In: Convolutional neural networks with swift for tensor- flow: image recognition and dataset categorization, pp
Koonce, B.: Mobilenetv3. In: Convolutional neural networks with swift for tensor- flow: image recognition and dataset categorization, pp. 125–144. Springer (2021)
2021
-
[28]
Master’s thesis, University of Tronto (2009)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images. Master’s thesis, University of Tronto (2009)
2009
-
[29]
arXiv preprint arXiv:2509.26037 (2025)
Li, Z., Lin, Z., Wang, Y.: CoLLM-NAS: Collaborative large language mod- els for efficient knowledge-guided neural architecture search. arXiv preprint arXiv:2509.26037 (2025)
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Liu, C., Chen, L.C., Schroff, F., Adam, H., Hua, W., Yuille, A.L., Fei-Fei, L.: Auto- deeplab: Hierarchical neural architecture search for semantic image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[31]
In: Proceed- ings of the European Conference on Computer Vision (ECCV)
Liu, C., Zoph, B., Neumann, M., Shlens, J., Hua, W., Li, L.J., Fei-Fei, L., Yuille, A.L., Huang, J., Murphy, K.: Progressive neural architecture search. In: Proceed- ings of the European Conference on Computer Vision (ECCV). pp. 19–34 (2018) LLMasTool 17
2018
-
[32]
In: 7th International Conference on Learning Representations (ICLR 2019)
Liu, H., Simonyan, K., Yang, Y.: DARTS: Differentiable architecture search. In: 7th International Conference on Learning Representations (ICLR 2019). OpenRe- view.net (2019)
2019
-
[33]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10012–10022 (2021)
2021
-
[34]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lu, S., Hu, Y., Yang, L., Sun, Z., Mei, J., Tan, J., Song, C.: PA&DA: Jointly sampling path and data for consistent NAS. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11940–11949 (2023)
2023
-
[36]
Mobilevit: Light- weight, general-purpose, and mobile-friendly vision trans- former
Mehta, S., Rastegari, M.: Mobilevit: light-weight, general-purpose, and mobile- friendly vision transformer. arXiv preprint arXiv:2110.02178 (2021)
-
[37]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mills, K.G., Han, F.X., Salameh, M., Lu, S., Zhou, C., He, J., Sun, F., Niu, D.: Building optimal neural architectures using interpretable knowledge. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5726–5735 (2024)
2024
-
[38]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Mills, K.G., Niu, D., Salameh, M., Qiu, W., Han, F.X., Liu, P., Zhang, J., Lu, W., Jui, S.: AIO-P: Expanding neural performance predictors beyond image classifi- cation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 9180–9189 (2023)
2023
-
[39]
arXiv preprint arXiv:2210.07998 (2022)
Movahedi, S., Adabinejad, M., Imani, A., Keshavarz, A., Dehghani, M., Shakery, A., Araabi, B.N.:Λ-DARTS: Mitigating performance collapse by harmonizing op- eration selection among cells. arXiv preprint arXiv:2210.07998 (2022)
-
[40]
In: proceedings of the Genetic and Evolutionary Computation Conference
Nasir, M.U., Earle, S., Togelius, J., James, S., Cleghorn, C.: LLMatic: Neural architecture search via large language models and quality diversity optimization. In: proceedings of the Genetic and Evolutionary Computation Conference. pp. 1110–1118 (2024)
2024
-
[41]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Oh, Y., Lee, H., Ham, B.: Efficient few-shot neural architecture search by counting the number of nonlinear functions. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 19740–19748 (2025)
2025
-
[42]
In: Proceedings of the 35th International Conference on Machine Learning (ICML)
Pham, H., Guan, M., Zoph, B., Le, Q., Dean, J.: Efficient neural architecture search via parameters sharing. In: Proceedings of the 35th International Conference on Machine Learning (ICML). Proceedings of Machine Learning Research, vol. 80, pp. 4095–4104. PMLR (2018)
2018
-
[43]
In: International conference on machine learning
Pham, H., Guan, M., Zoph, B., Le, Q., Dean, J.: Efficient neural architecture search via parameters sharing. In: International conference on machine learning. pp. 4095–4104. PMLR (2018)
2018
-
[44]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2022)
Qian, J., Zheng, S., Li, Y., Zhang, J., Lin, Z., Liu, J., Wang, B., Gao, Y.: When NAS meets trees: An efficient algorithm for neural architecture search. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2022)
2022
-
[45]
arXiv preprint arXiv:2402.18443 (2024)
Rahman, M.H., Chakraborty, P.: Lemo-nade: Multi-parameter neural architecture discovery with llms. arXiv preprint arXiv:2402.18443 (2024)
-
[46]
In: Proceedings of the aaai conference on artificial intel- ligence
Real, E., Aggarwal, A., Huang, Y., Le, Q.V.: Regularized evolution for image clas- sifier architecture search. In: Proceedings of the aaai conference on artificial intel- ligence. vol. 33, pp. 4780–4789 (2019)
2019
-
[47]
In: Proceedings of the 34th 18 M
Real, E., Moore, S., Selle, A., Saxena, S., Suematsu, Y.L., Tan, J., Le, Q.V., Ku- rakin, A.: Large-scale evolution of image classifiers. In: Proceedings of the 34th 18 M. Yoshimura et al. International Conference on Machine Learning (ICML). Proceedings of Machine Learning Research, vol. 70, pp. 2902–2911. PMLR (2017)
2017
-
[48]
Foundations and Trends in Machine Learning11(1), 1–96 (2018)
Russo, D.J., Roy, B.V., Kazerouni, A., Osband, I., Wen, Z.: A tutorial on thompson sampling. Foundations and Trends in Machine Learning11(1), 1–96 (2018)
2018
-
[49]
arXiv preprint arXiv:2403.20080 (2024)
Sakuma,Y.,Yoshimura,M.,Otsuka,J.,Irie,A.,Ohashi,T.:Mixed-precisionsuper- net training from vision foundation models using low rank adapter. arXiv preprint arXiv:2403.20080 (2024)
-
[50]
Advances in Neural Information Processing Systems36, 74455–74477 (2023)
Salameh, M., Mills, K., Hassanpour, N., Han, F., Zhang, S., Lu, W., Jui, S., Zhou, C., Sun, F., Niu, D.: AutoGO: Automated computation graph optimization for neural network evolution. Advances in Neural Information Processing Systems36, 74455–74477 (2023)
2023
-
[51]
Advances in Neural Information Processing Systems37, 25687–25708 (2024)
Shi, Y., Dong, M., Xu, C.: Multi-scale vmamba: Hierarchy in hierarchy visual state space model. Advances in Neural Information Processing Systems37, 25687–25708 (2024)
2024
-
[52]
In: International conference on machine learning
So, D., Le, Q., Liang, C.: The evolved transformer. In: International conference on machine learning. pp. 5877–5886 (2019)
2019
-
[53]
Stamoulis, D., Ding, R., Wang, D., Lymberopoulos, D., Priyantha, B., Liu, J., Marculescu, D.: Single-path NAS: Device-aware efficient convnet design. In: Joint Workshop on On-Device Machine Learning & Compact Deep Neural Network Rep- resentations withIndustrialApplications (ODML-CDNNRIA)inConjunctionwith International Conference on Machine Learning (2019)
2019
-
[54]
Suganuma, M., Shirakawa, S., Nagao, T.: A genetic programming approach to designingconvolutionalneuralnetworkarchitectures.In:Proceedingsofthegenetic and evolutionary computation conference. pp. 497–504 (2017)
2017
-
[55]
In: European con- ference on computer vision
Tian, Y., Krishnan, D., Isola, P.: Contrastive multiview coding. In: European con- ference on computer vision. pp. 776–794. Springer (2020)
2020
-
[56]
In: Proceedings of the 33rd International Conference on Machine Learning (ICML)
Wei, T., Wang, C., Rui, Y., Chen, C.W.: Network morphism. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). Proceedings of Machine Learning Research, vol. 48, pp. 564–572. PMLR (2016)
2016
-
[57]
Machine learning8(3), 229–256 (1992)
Williams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning8(3), 229–256 (1992)
1992
-
[58]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Wu, B., Dai, X., Zhang, P., Wang, Y., Sun, F., Wu, Y., Tian, Y., Vajda, P., Jia, Y., Keutzer, K.: FBNet: Hardware-aware efficient convnet design via differentiable neural architecture search. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 10734–10742 (2019)
2019
-
[59]
In: International Conference on Learning Representations (ICLR) (2025)
Xiao, C., Li, M., Zhang, Z., Meng, D., Zhang, L.: Spatial-mamba: Effective visual state space models via structure-aware state fusion. In: International Conference on Learning Representations (ICLR) (2025)
2025
-
[60]
In: International Conference on Learning Representations (2019)
Xie, S., Zheng, H., Liu, C., Lin, L.: SNAS: stochastic neural architecture search. In: International Conference on Learning Representations (2019)
2019
-
[61]
In: International Conference on Learning Representations (2020)
Xu, Y., Xie, L., Zhang, X., Chen, X., Qi, G.J., Tian, Q., Xiong, H.: Pc-darts: Par- tial channel connections for memory-efficient architecture search. In: International Conference on Learning Representations (2020)
2020
-
[62]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025) LLMasTool 19
Yang, Z., Shi, J., Zhang, H., Chen, X., Zhang, Y., Zhang, Y., Huang, J., Yang, S., Liu, D., Chen, L., Chen, W.: NADER: Neural architecture design via multi-agent collaboration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025) LLMasTool 19
2025
-
[64]
In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ye, P., Li, B., Li, Y., Chen, T., Fan, J., Ouyang, W.: b-darts: Beta-decay regu- larization for differentiable architecture search. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10874–10883 (2022)
2022
-
[65]
arXiv preprint arXiv:2603.16423 (2026)
Yoshimura, M., Hayashi, T., Hoshino, Y., Wang, W.Y., Ohashi, T.: Sf-mamba: Rethinking state space model for vision. arXiv preprint arXiv:2603.16423 (2026)
-
[66]
In: The Thirteenth International Conference on Learning Representations (2025)
Yoshimura, M., Hayashi, T., Maeda, Y.: Mambapeft: Exploring parameter-efficient fine-tuning for mamba. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[67]
In: European Conference on Computer Vision
Yu, J., Jin, P., Liu, H., Bender, G., Kindermans, P.J., Tan, M., Huang, T., Song, X., Pang, R., Le, Q.: BigNAS: Scaling up neural architecture search with big single- stage models. In: European Conference on Computer Vision. pp. 702–717 (2020)
2020
-
[68]
In: European Conference on Computer Vision
Zhang, B., Wu, X., Miao, H., Guo, C., Yang, B.: Dependency-aware differentiable neural architecture search. In: European Conference on Computer Vision. pp. 219– 236 (2024)
2024
-
[69]
In: Interna- tional Conference on Machine Learning
Zhang, M., Su, S.W., Pan, S., Chang, X., Abbasnejad, E.M., Haffari, R.: idarts: Differentiable architecture search with stochastic implicit gradients. In: Interna- tional Conference on Machine Learning. pp. 12557–12566. PMLR (2021)
2021
-
[70]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolu- tional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6848–6856 (2018)
2018
-
[71]
In: International Conference on Machine Learning
Zhao, Y., Wang, L., Tian, Y., Fonseca, R., Guo, T.: Few-shot neural architecture search. In: International Conference on Machine Learning. pp. 12707–12718 (2021)
2021
- [72]
-
[73]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhou, X., Feng, L., Wu, X., Lu, Z., Tan, K.C.: Design principle transfer in neu- ral architecture search via large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39 (2025)
2025
-
[74]
In: 39th Annual AAAI Conference on Artificial Intelligence (AAAI 2025)
Zhou, X., Wu, X., Feng, L., Lu, Z., Tan, K.C.: Design principle transfer in neural architecture search via large language models. In: 39th Annual AAAI Conference on Artificial Intelligence (AAAI 2025). pp. 23000–23008 (2025)
2025
-
[75]
In: ICML
Zhu, L., Liao, B., Zhang, Q., Wang, X., Liu, W., Wang, X.: Vision mamba: Effi- cient visual representation learning with bidirectional state space model. In: ICML. OpenReview.net (2024)
2024
-
[76]
In: 5th International Conference on Learning Representations (ICLR 2017), Conference Track Proceedings
Zoph, B., Le, Q.V.: Neural architecture search with reinforcement learning. In: 5th International Conference on Learning Representations (ICLR 2017), Conference Track Proceedings. OpenReview.net (2017)
2017
-
[77]
In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR)
Zoph, B., Vasudevan, V., Shlens, J., Le, Q.V.: Learning transferable architectures for scalable image recognition. In: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 8697–8710 (June 2018) A Limitation and Future Works Various evaluations demonstrated that LLMasTool achieves significant perfor- mance improvement...
2018
-
[78]
Swap Module,
Therefore, compared to conventional NAS approaches based on evolution- ary algorithms [31,52,54] or reinforcement learning [42,76,77], the overall time overhead is minimal. However, because the training cost for each candidate ar- chitecture is still high, searching over larger-scale model structures would re- quire substantially more time. To discover la...
-
[79]
, 25no rm _cf g = dict ( 26# torch . nn . B a t c h N o r m 2 d 27type = ’ B a t c h N o r m 2 d ’ , 28eps =1 e -05 , 29m ome nt um =0.1) , 30act_cfg = dict ( 31# torch . nn . SiLU 32type = ’ SiLU ’ , 33inplace = False )) , 34dict ( 35# m m p r e t r a i n . models . b a c k b o n e s . resnet . B a s i c B l o c k 36type = ’ B a s i c B l o c k ’ , 37i n...
-
[80]
, 105stride =1 , 106n u m _ h e a d s =4 , 107di m_ he ad = None , 108qk _r at io =1.0 , 109qk v_ bi as = False , 110s c a l e _ p o s _ e m b e d = True ) , 111dict ( 112type = ’ M y R e s h a p e ’ , 113shape =[ 114-1 , 11516 , 11616 , 11716 118]) , 119dict ( 120type = ’ Conv2d ’ , 121i n _ c h a n n e l s =16 , 122o u t _ c h a n n e l s =16 , 123k e r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.