Recognition: unknown
On the Robustness of LLM-Based Dense Retrievers: A Systematic Analysis of Generalizability and Stability
Pith reviewed 2026-05-10 07:47 UTC · model grok-4.3
The pith
LLM-based dense retrievers handle typos and corpus poisoning better than encoder models but remain vulnerable to synonym swaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
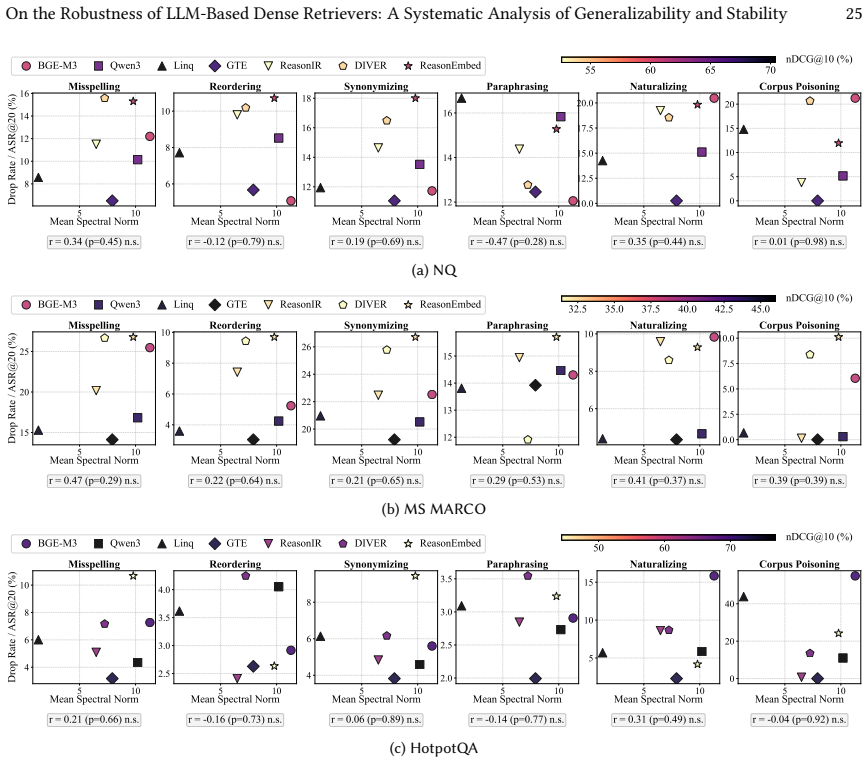
Decoder-only LLM-based dense retrievers exhibit improved robustness against typos and corpus poisoning compared to encoder-only baselines, yet remain vulnerable to semantic perturbations like synonymizing. Instruction-tuned models generally excel in generalizability across diverse datasets, while those optimized for complex reasoning suffer a specialization tax that limits broader effectiveness. Embedding geometry provides predictive signals for lexical stability and scaling model size generally improves robustness.
What carries the argument
Linear mixed-effects models applied across four benchmarks spanning 30 datasets, combined with stability tests using paraphrasing, typos, synonymizing, and corpus poisoning perturbations.
If this is right
- Instruction tuning should be prioritized over reasoning-only optimization for retrieval systems that must work across varied domains.
- Larger model sizes can be expected to deliver measurable gains in resistance to both unintentional and adversarial perturbations.
- Embedding uniformity and angular metrics offer a practical signal for selecting or tuning models that maintain lexical stability.
- Benchmarking protocols for retrievers should routinely include semantic perturbations to avoid overestimating robustness.
Where Pith is reading between the lines
- Training pipelines could add explicit checks on embedding geometry to select or regularize for better stability without extra test-time cost.
- The specialization tax observed in reasoning models suggests multi-objective fine-tuning might recover generalizability while retaining complex capabilities.
- Vulnerability to synonymizing may indicate a broader need for invariance training that applies beyond retrieval to other semantic matching tasks.
- The same evaluation approach could be extended to closed-source or proprietary LLM retrievers to test whether the reported patterns hold.
Load-bearing premise
The four benchmarks and the chosen perturbation methods of paraphrasing, typos, synonymizing, and corpus poisoning adequately represent real-world generalizability and stability challenges for dense retrievers.
What would settle it
An evaluation in which an LLM-based retriever that is weak against typos or corpus poisoning but strong against synonymizing, or in which embedding geometry metrics show no predictive link to lexical stability on additional models.
Figures



read the original abstract
Decoder-only large language models (LLMs) are increasingly replacing BERT-style architectures as the backbone for dense retrieval, achieving substantial performance gains and broad adoption. However, the robustness of these LLM-based retrievers remains underexplored. In this paper, we present the first systematic study of the robustness of state-of-the-art open-source LLM-based dense retrievers from two complementary perspectives: generalizability and stability. For generalizability, we evaluate retrieval effectiveness across four benchmarks spanning 30 datasets, using linear mixed-effects models to estimate marginal mean performance and disentangle intrinsic model capability from dataset heterogeneity. Our analysis reveals that while instruction-tuned models generally excel, those optimized for complex reasoning often suffer a ``specialization tax,'' exhibiting limited generalizability in broader contexts. For stability, we assess model resilience against both unintentional query variations~(e.g., paraphrasing, typos) and malicious adversarial attacks~(e.g., corpus poisoning). We find that LLM-based retrievers show improved robustness against typos and corpus poisoning compared to encoder-only baselines, yet remain vulnerable to semantic perturbations like synonymizing. Further analysis shows that embedding geometry (e.g., angular uniformity) provides predictive signals for lexical stability and suggests that scaling model size generally improves robustness. These findings inform future robustness-aware retriever design and principled benchmarking. Our code is publicly available at https://github.com/liyongkang123/Robust_LLM_Retriever_Eval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic study of robustness for state-of-the-art open-source LLM-based dense retrievers, examining generalizability across four benchmarks spanning 30 datasets via linear mixed-effects models to estimate marginal mean performance while disentangling model capability from dataset effects, and stability against unintentional variations (paraphrasing, typos) and adversarial attacks (synonymizing, corpus poisoning). Key results indicate that instruction-tuned models generally outperform others but reasoning-optimized models incur a specialization tax in generalizability; LLM retrievers are more robust than encoder baselines to typos and poisoning yet vulnerable to semantic perturbations; embedding geometry (e.g., angular uniformity) predicts lexical stability; and scaling model size improves robustness overall. Code is released publicly.
Significance. If the empirical findings hold under broader conditions, the work offers substantial value to the IR community by quantifying trade-offs in LLM retriever design, demonstrating the utility of statistical modeling for cross-dataset analysis, and identifying embedding geometry as a diagnostic tool. The public code supports reproducibility and enables follow-on work on robustness-aware retrievers and benchmarking practices.
major comments (2)
- [§4] §4 (Experimental Setup) and §5.1 (Generalizability Analysis): The central claims about improved robustness to typos/poisoning, vulnerability to synonymizing, and the specialization tax rest on the assumption that the four chosen benchmarks and four perturbation types adequately proxy real-world query distributions and attacks. The linear mixed-effects marginal means and geometry-stability correlations are therefore conditional on this specific evaluation slice; without explicit discussion or sensitivity analysis for omitted variations (e.g., multi-turn context shifts, domain jargon drift, or gradient-based attacks), the generalizability and stability conclusions risk overstatement.
- [§5.2] §5.2 (Stability Analysis): The reported robustness advantages for LLM retrievers over encoder baselines are quantified via direct effectiveness drops under each perturbation, yet the paper does not report per-perturbation variance or interaction terms from the mixed-effects models that would confirm the differences are not driven by a subset of the 30 datasets.
minor comments (3)
- [§3.2] §3.2: The precise random-effects structure and covariance assumptions of the linear mixed-effects models are not stated; adding the model formula (e.g., performance ~ model_type + (1|dataset)) would allow readers to verify the disentanglement procedure.
- [Figure 4] Figure 4 and Table 2: Axis labels and legend entries use abbreviated model names without a corresponding table of full names and sizes in the caption, reducing readability for readers unfamiliar with the exact checkpoints.
- [Abstract] Abstract and §1: The phrase 'specialization tax' is introduced without a concise definition or reference to prior usage in the IR literature; a parenthetical gloss on first use would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important considerations regarding the scope of our evaluation and the statistical details in the stability analysis. We address each major comment below, noting the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup) and §5.1 (Generalizability Analysis): The central claims about improved robustness to typos/poisoning, vulnerability to synonymizing, and the specialization tax rest on the assumption that the four chosen benchmarks and four perturbation types adequately proxy real-world query distributions and attacks. The linear mixed-effects marginal means and geometry-stability correlations are therefore conditional on this specific evaluation slice; without explicit discussion or sensitivity analysis for omitted variations (e.g., multi-turn context shifts, domain jargon drift, or gradient-based attacks), the generalizability and stability conclusions risk overstatement.
Authors: We agree that our evaluation is conditioned on the selected benchmarks and perturbation types, which may not fully represent all real-world query distributions or attack vectors. These were chosen to systematically examine both unintentional variations and adversarial attacks across diverse datasets. We will revise the manuscript to include a dedicated Limitations section that explicitly discusses the evaluation scope, acknowledges the absence of sensitivity analyses for omitted variations such as multi-turn context shifts or gradient-based attacks, and outlines directions for future work. This addition will provide necessary context for interpreting the findings. revision: partial
-
Referee: [§5.2] §5.2 (Stability Analysis): The reported robustness advantages for LLM retrievers over encoder baselines are quantified via direct effectiveness drops under each perturbation, yet the paper does not report per-perturbation variance or interaction terms from the mixed-effects models that would confirm the differences are not driven by a subset of the 30 datasets.
Authors: The stability analysis focuses on average effectiveness drops per perturbation type to quantify comparative robustness. The linear mixed-effects models were applied primarily to the generalizability analysis. We acknowledge that reporting per-perturbation variance and interaction terms would help confirm consistency across datasets. In the revised version, we will add these details, including per-perturbation standard deviations and relevant interaction effects, to demonstrate that the observed advantages are not driven by a subset of datasets. revision: yes
Circularity Check
No circularity: purely empirical evaluation with standard statistical analysis
full rationale
The paper performs direct empirical measurements of retrieval performance across 30 datasets in four benchmarks, applies standard linear mixed-effects models to compute marginal means, and correlates embedding geometry metrics with stability outcomes. No derivations, predictions, or uniqueness claims are made that reduce by construction to fitted parameters, self-definitions, or self-citation chains. All load-bearing steps rely on external benchmarks and observable data rather than internal reparameterization of the same quantities. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear mixed-effects models can disentangle intrinsic model capability from dataset heterogeneity to yield marginal mean performance estimates.
Reference graph
Works this paper leans on
-
[1]
Mira Ait-Saada and Mohamed Nadif. 2023. Is Anisotropy Truly Harmful? A Case Study on Text Clustering. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 1194–1203. doi:10.1...
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.16609 2023
-
[3]
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. 2016. Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268(2016)
work page internal anchor Pith review arXiv 2016
-
[4]
Parishad BehnamGhader, Nicholas Meade, and Siva Reddy. 2025. Exploiting Instruction-Following Retrievers for Malicious Information Retrieval. In Findings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for ...
2025
-
[5]
Matan Ben-Tov and Mahmood Sharif. 2025. GASLITEing the Retrieval: Exploring Vulnerabilities in Dense Embedding-based Search. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, CCS 2025, Taipei, Taiwan, October 13-17, 2025, Chun-Ying Huang, Jyh-Cheng Chen, Shiuh-Pyng Shieh, David Lie, and Véronique Cortier (Eds.). ACM,...
-
[6]
Bruce Croft, and Mark Sanderson
Valeria Bolotova, Vladislav Blinov, Falk Scholer, W. Bruce Croft, and Mark Sanderson. 2022. A Non-Factoid Question-Answering Taxonomy. InSIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, Enrique Amigó, Pablo Castells, Julio Gonzalo, Ben Carterette, J. Shane Culpe...
-
[7]
Xingyu Cai, Jiaji Huang, Yuchen Bian, and Kenneth Church. 2021. Isotropy in the Contextual Embedding Space: Clusters and Manifolds. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/ forum?id=xYGNO86OWDH
2021
-
[8]
Jianlyu Chen, Junwei Lan, Chaofan Li, Defu Lian, and Zheng Liu. 2025. ReasonEmbed: Enhanced Text Embeddings for Reasoning-Intensive Document Retrieval. arXiv:2510.08252 [cs.IR] https://arxiv.org/abs/2510.08252
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi- Granularity Text Embeddings Through Self-Knowledge Distillation. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computat...
-
[10]
Xilun Chen, Kushal Lakhotia, Barlas Oguz, Anchit Gupta, Patrick Lewis, Stan Peshterliev, Yashar Mehdad, Sonal Gupta, and Wen-tau Yih. 2022. Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?. InFindings of the Association for Computational Linguistics: EMNLP 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Assoc...
-
[11]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. 2025. BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent.C...
-
[12]
Chanyeol Choi, Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, and Jy-yong Sohn. 2024. Linq-Embed-Mistral Technical Report.CoRRabs/2412.03223 (2024). arXiv:2412.03223 doi:10.48550/ARXIV.2412.03223 Manuscript submitted to ACM 30 Yongkang Li, Panagiotis Eustratiadis, Yixing Fan, and Evangelos Kanoulas
-
[13]
Shane Culpepper, Guglielmo Faggioli, Nicola Ferro, and Oren Kurland
J. Shane Culpepper, Guglielmo Faggioli, Nicola Ferro, and Oren Kurland. 2022. Topic Difficulty: Collection and Query Formulation Effects.ACM Trans. Inf. Syst.40, 1 (2022), 19:1–19:36. doi:10.1145/3470563
-
[14]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Vol...
-
[15]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
work page internal anchor Pith review arXiv 2024
- [16]
-
[17]
Kawin Ethayarajh. 2019. How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, ...
-
[18]
Nicola Ferro. 2017. What Does Affect the Correlation Among Evaluation Measures?ACM Trans. Inf. Syst.36, 2 (2017), 19:1–19:40. doi:10.1145/3106371
-
[19]
Nicola Ferro and Mark Sanderson. 2017. Sub-corpora Impact on System Effectiveness. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, August 7-11, 2017, Noriko Kando, Tetsuya Sakai, Hideo Joho, Hang Li, Arjen P. de Vries, and Ryen W. White (Eds.). ACM, 901–904. doi:10....
-
[20]
Nicola Ferro and Mark Sanderson. 2022. How Do You Test a Test?: A Multifaceted Examination of Significance Tests. InWSDM ’22: The Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event / Tempe, AZ, USA, February 21 - 25, 2022, K. Selcuk Candan, Huan Liu, Leman Akoglu, Xin Luna Dong, and Jiliang Tang (Eds.). ACM, 280–288. doi:1...
-
[21]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jone...
-
[22]
Alejandro Fuster Baggetto and Victor Fresno. 2022. Is anisotropy really the cause of BERT embeddings not being semantic?. InFindings of the Association for Computational Linguistics: EMNLP 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 4271–4281. doi:10.18653/v1/202...
-
[23]
2013.Linear Mixed-Effects Model
Andrzej Gałecki and Tomasz Burzykowski. 2013.Linear Mixed-Effects Model. Springer New York, New York, NY, 245–273. doi:10.1007/978-1-4614- 3900-4_13
-
[24]
Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. 2019. Representation Degeneration Problem in Training Natural Language Generation Models. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=SkEYojRqtm
2019
-
[25]
Nathan Godey, Éric Clergerie, and Benoît Sagot. 2024. Anisotropy Is Inherent to Self-Attention in Transformers. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Yvette Graham and Matthew Purver (Eds.). Association for Computational Linguistics, St. Julian’s, Malta, 35–48...
-
[26]
Tim Hagen, Harrisen Scells, and Martin Potthast. 2024. Revisiting Query Variation Robustness of Transformer Models. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 4283–4296. doi:10.18653/v1/2024.findings-emnlp.248
-
[27]
Matthias Hein and Maksym Andriushchenko. 2017. Formal Guarantees on the Robustness of a Classifier against Adversarial Manipulation. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wal...
2017
-
[28]
Sebastian Hofstätter, Sheng-Chieh Lin, Jheng-Hong Yang, Jimmy Lin, and Allan Hanbury. 2021. Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling. InSIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021. ACM, 113–122. doi:10.1145/3...
-
[29]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised Dense Information Retrieval with Contrastive Learning.Trans. Mach. Learn. Res.2022 (2022). https://openreview.net/forum?id=jKN1pXi7b0
2022
-
[30]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.CoRRabs/2310.0682...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[31]
Matt Jordan and Alexandros G. Dimakis. 2020. Exactly Computing the Local Lipschitz Constant of ReLU Networks. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsu...
2020
-
[32]
Euna Jung, Jungwon Park, Jaekeol Choi, Sungyoon Kim, and Wonjong Rhee. 2023. Isotropic Representation Can Improve Dense Retrieval. In Advances in Knowledge Discovery and Data Mining - 27th Pacific-Asia Conference on Knowledge Discovery and Data Mining, PAKDD 2023, Osaka, Manuscript submitted to ACM On the Robustness of LLM-Based Dense Retrievers: A System...
-
[33]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP
2020
-
[34]
Dense passage retrieval for open-domain question answering
Association for Computational Linguistics, 6769–6781. doi:10.18653/V1/2020.EMNLP-MAIN.550
-
[35]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020. ACM, 39–48. doi:10. 1145/3397271.3401075
-
[36]
Alexandra Kuznetsova, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest Package: Tests in Linear Mixed Effects Models.Journal of Statistical Software82, 13 (2017), 1–26. doi:10.18637/jss.v082.i13
-
[37]
Russell Lenth. 2023. emmeans: Estimated Marginal Means, aka Least-Squares Means_.R package version 1.8. 5(2023). https://cran.r-project.org/ web/packages/emmeans/
2023
-
[38]
Yongkang Li, Panagiotis Eustratiadis, and Evangelos Kanoulas. 2025. Reproducing HotFlip for Corpus Poisoning Attacks in Dense Retrieval. In Advances in Information Retrieval - 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6-10, 2025, Proceedings, Part IV (Lecture Notes in Computer Science, Vol. 15575). Springer, 95–111....
-
[39]
Yongkang Li, Panagiotis Eustratiadis, Simon Lupart, and Evangelos Kanoulas. 2025. Unsupervised Corpus Poisoning Attacks in Continuous Space for Dense Retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025, Nicola Ferro, Maria Maistro, Gabriell...
-
[40]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281(2023). https://arxiv.org/abs/2308.03281
work page internal anchor Pith review arXiv 2023
-
[41]
Sheng-Chieh Lin, Akari Asai, Minghan Li, Barlas Oguz, Jimmy Lin, Yashar Mehdad, Wen-tau Yih, and Xilun Chen. 2023. How to Train Your Dragon: Diverse Augmentation Towards Generalizable Dense Retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023. Association for Computational Linguistics, 6385–640...
-
[42]
Jiawei Liu, Yangyang Kang, Di Tang, Kaisong Song, Changlong Sun, Xiaofeng Wang, Wei Lu, and Xiaozhong Liu. 2022. Order-Disorder: Imitation Adversarial Attacks for Black-box Neural Ranking Models. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security(Los Angeles, CA, USA)(CCS ’22). Association for Computing Machinery, New ...
-
[43]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Wei Chen, Yixing Fan, and Xueqi Cheng. 2023. Topic-oriented Adversarial Attacks against Black-box Neural Ranking Models. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 23-27, 2023, Hsin-Hsi Chen, Wei-...
-
[44]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2024. Multi-granular Adversarial Attacks against Black-box Neural Ranking Models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, Grace Hui Yang, Hongning ...
-
[45]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2025. On the Scaling of Robustness and Effectiveness in Dense Retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025, Nicola Ferro, Maria Maistro, Gabriella P...
-
[46]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Wei Chen, Yixing Fan, and Xueqi Cheng. 2023. Black-box Adversarial Attacks against Dense Retrieval Models: A Multi-view Contrastive Learning Method. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management(Birmingham, United Kingdom)(CIKM ’23). Association for Co...
-
[47]
Yu-An Liu, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2025. Robust Neural Information Retrieval: An Adversarial and Out-of-Distribution Perspective.ACM Trans. Inf. Syst.44, 1, Article 17 (Nov. 2025), 48 pages. doi:10.1145/3768153
-
[48]
Zheng Liu, Chaofan Li, Shitao Xiao, Yingxia Shao, and Defu Lian. 2024. Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Lingui...
-
[49]
Meixiu Long, DuoLin Sun, Dan Yang, Junjie Wang, Yue Shen, Jian Wang, Peng Wei, Jinjie Gu, and Jiahai Wang. 2025. DIVER: A Multi-Stage Approach for Reasoning-intensive Information Retrieval.CoRRabs/2508.07995 (2025). arXiv:2508.07995 doi:10.48550/ARXIV.2508.07995
-
[50]
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. 2024. Fine-Tuning LLaMA for Multi-Stage Text Retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, Grace Hui Yang, Hongning Wang, Sam Han, Claudia Hauff, Guido Zuccon, and Yi ...
-
[51]
Gabriel de Souza P Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, and Even Oldridge. 2024. NV-Retriever: Improving text embedding models with effective hard-negative mining.arXiv preprint arXiv:2407.15831(2024). https://arxiv.org/abs/2407.15831 Manuscript submitted to ACM 32 Yongkang Li, Panagiotis Eustratiadis, Yixing Fan, and Evange...
-
[52]
Gustavo Penha, Arthur Câmara, and Claudia Hauff. 2022. Evaluating the Robustness of Retrieval Pipelines with Query Variation Generators. In Advances in Information Retrieval - 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, April 10-14, 2022, Proceedings, Part I (Lecture Notes in Computer Science, Vol. 13185), Matthias Hagen, Suzan ...
-
[53]
Improving retrieval of short texts through document expansion
Stephen E. Robertson and Evangelos Kanoulas. 2012. On per-topic variance in IR evaluation. InThe 35th International ACM SIGIR conference on research and development in Information Retrieval, SIGIR ’12, Portland, OR, USA, August 12-16, 2012, William R. Hersh, Jamie Callan, Yoelle Maarek, and Mark Sanderson (Eds.). ACM, 891–900. doi:10.1145/2348283.2348402
-
[54]
The probabilistic relevance framework: Bm25 and beyond
Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (2009), 333–389. doi:10.1561/1500000019
-
[55]
William Rudman and Carsten Eickhoff. 2024. Stable Anisotropic Regularization. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=dbQH9AOVd5
2024
-
[56]
William Rudman, Nate Gillman, Taylor Rayne, and Carsten Eickhoff. 2022. IsoScore: Measuring the Uniformity of Embedding Space Utilization. In Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022, Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, 3325...
-
[57]
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. 2022. PLAID: An Efficient Engine for Late Interaction Retrieval. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, October 17-21, 2022, Mohammad Al Hasan and Li Xiong (Eds.). ACM, 1747–1756. doi:10.1145/3511808.3557325
-
[58]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, W A, United States...
-
[59]
Rulin Shao, Rui Qiao, Varsha Kishore, Niklas Muennighoff, Xi Victoria Lin, Daniela Rus, Bryan Kian Hsiang Low, Sewon Min, Wen tau Yih, Pang Wei Koh, and Luke Zettlemoyer. 2025. ReasonIR: Training Retrievers for Reasoning Tasks. InSecond Conference on Language Modeling. https://openreview.net/forum?id=kkBCNLMbGj
2025
-
[60]
Zico Kolter, and Cho-Jui Hsieh
Zhouxing Shi, Yihan Wang, Huan Zhang, J. Zico Kolter, and Cho-Jui Hsieh. 2022. Efficiently Computing Local Lipschitz Constants of Neural Networks via Bound Propagation. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022,...
2022
-
[61]
Georgios Sidiropoulos and Evangelos Kanoulas. 2022. Analysing the Robustness of Dual Encoders for Dense Retrieval Against Misspellings. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 2132–2136. doi:10.1145/3477495.3531818
-
[62]
Georgios Sidiropoulos and Evangelos Kanoulas. 2024. Improving the Robustness of Dense Retrievers Against Typos via Multi-Positive Contrastive Learning. InAdvances in Information Retrieval - 46th European Conference on Information Retrieval, ECIR 2024, Glasgow, UK, March 24-28, 2024, Proceedings, Part III (Lecture Notes in Computer Science, Vol. 14610), Na...
-
[63]
Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan Ö
Hongjin Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han-yu Wang, Haisu Liu, Quan Shi, Zachary S. Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan Ö. Arik, Danqi Chen, and Tao Yu. 2025. BRIGHT: A Realistic and Challenging Benchmark for Reasoning- Intensive Retrieval. InThe Thirteenth International Conference on Learning Representatio...
2025
-
[64]
Jinyan Su, Preslav Nakov, and Claire Cardie. 2025. Corpus Poisoning via Approximate Greedy Gradient Descent. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, 4274–42...
2025
-
[65]
Manveer Singh Tamber and Jimmy Lin. 2025. Illusions of Relevance: Using Content Injection Attacks to Deceive Retrievers, Rerankers, and LLM Judges.CoRRabs/2501.18536 (2025). arXiv:2501.18536 doi:10.48550/ARXIV.2501.18536
-
[66]
Panuthep Tasawong, Wuttikorn Ponwitayarat, Peerat Limkonchotiwat, Can Udomcharoenchaikit, Ekapol Chuangsuwanich, and Sarana Nutanong
-
[67]
Typo-Robust Representation Learning for Dense Retrieval. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 1106–1115. doi:10.18653/v1/2023.acl-short.95
-
[68]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). https://openreview.net/forum?id=wCu6T5xFjeJ
2021
-
[69]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models.CoRRabs/2302.13971 (2023). arXiv:2302.13971 doi:10.48550/ARXIV.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[70]
Aladin Virmaux and Kevin Scaman. 2018. Lipschitz regularity of deep neural networks: analysis and efficient estimation. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Manuscript submitted to ACM On the Robustness of LLM-Based Dense Retriev...
2018
- [71]
-
[72]
Chen Wu, Ruqing Zhang, Jiafeng Guo, Maarten De Rijke, Yixing Fan, and Xueqi Cheng. 2023. PRADA: Practical Black-box Adversarial Attacks against Neural Ranking Models.ACM Trans. Inf. Syst.41, 4, Article 89 (apr 2023), 27 pages. doi:10.1145/3576923
-
[73]
Chen Wu, Ruqing Zhang, Jiafeng Guo, Yixing Fan, and Xueqi Cheng. 2023. Are Neural Ranking Models Robust?ACM Trans. Inf. Syst.41, 2 (2023), 29:1–29:36. doi:10.1145/3534928
-
[74]
Chenghao Xiao, Yang Long, and Noura Al Moubayed. 2023. On Isotropy, Contextualization and Learning Dynamics of Contrastive-based Sentence Representation Learning. InFindings of the Association for Computational Linguistics: ACL 2023, Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 122...
-
[75]
Shitao Xiao, Zheng Liu, Yingxia Shao, and Zhao Cao. 2022. RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto- Encoder. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Ass...
-
[76]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.CoRRabs/2506.05176 (2025). arXiv:2506.05176 doi:10.48550/ARXIV.2506.05176
work page internal anchor Pith review doi:10.48550/arxiv.2506.05176 2025
-
[77]
Zhong Zhang, Chongming Gao, Cong Xu, Rui Miao, Qinli Yang, and Junming Shao. 2020. Revisiting Representation Degeneration Problem in Language Modeling. InFindings of the Association for Computational Linguistics: EMNLP 2020, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 518–527. doi:10.18653/v1/2020.finding...
-
[78]
Zexuan Zhong, Ziqing Huang, Alexander Wettig, and Danqi Chen. 2023. Poisoning Retrieval Corpora by Injecting Adversarial Passages. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics...
-
[79]
Shengyao Zhuang and Guido Zuccon. 2021. Dealing with Typos for BERT-based Passage Retrieval and Ranking. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.)....
-
[80]
Shengyao Zhuang and Guido Zuccon. 2022. CharacterBERT and Self-Teaching for Improving the Robustness of Dense Retrievers on Queries with Typos. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 1444–1454. doi:1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.