Recognition: unknown
MambaKick: Early Penalty Direction Prediction from HAR Embeddings
Pith reviewed 2026-05-10 09:04 UTC · model grok-4.3
The pith
Pretrained human action recognition embeddings combined with Mamba temporal models predict soccer penalty kick directions from short contact-centered video segments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
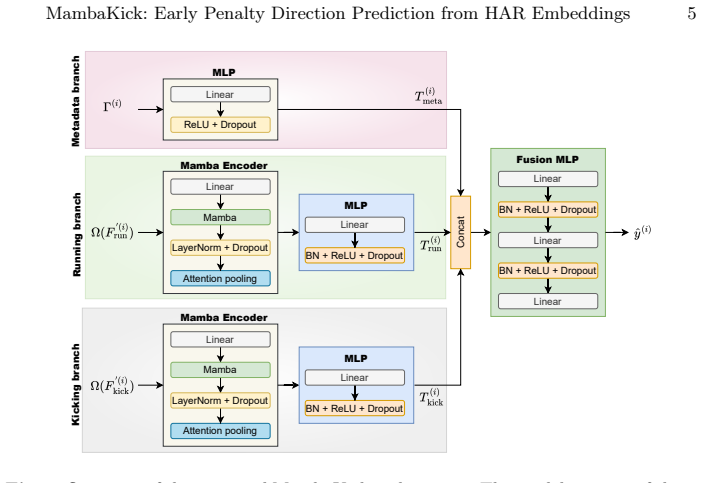
MambaKick is a learning-based framework for penalty direction prediction that leverages pretrained human action recognition (HAR) embeddings extracted from contact-centered short video segments and combines them with a lightweight temporal predictor using selective state-space models (Mamba) for efficient sequence aggregation, along with simple contextual metadata. Across a range of HAR backbones, it consistently improves or matches strong embedding baselines, achieving up to 53.1% accuracy for three classes and 64.5% for two classes.
What carries the argument
MambaKick framework reusing pretrained HAR embeddings with Mamba state-space models for temporal aggregation on contact-centered clips.
If this is right
- The method works across multiple different pretrained HAR backbones without any fine-tuning.
- It reaches 53.1 percent three-class accuracy and 64.5 percent two-class accuracy while remaining computationally light.
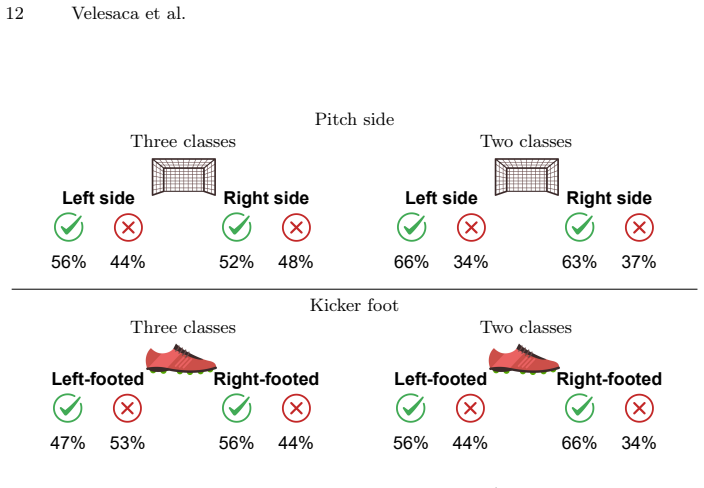
- Contextual cues such as field side and footedness further reduce directional ambiguity in real footage.
- The approach offers a practical alternative to explicit kinematic or biomechanical feature engineering for early intention prediction.
- Results indicate that combining HAR representations with efficient state-space temporal modeling supports low-latency use in sports video.
Where Pith is reading between the lines
- The same embedding-reuse pattern could be tested on intention prediction tasks in other team sports such as basketball shot selection or tennis serve direction.
- Deployment on live camera feeds might enable real-time decision support for coaches or broadcast graphics without heavy compute.
- Extending the temporal window beyond the contact-centered clip could show whether longer context adds value or introduces noise.
- Efficiency gains from Mamba may allow the pipeline to run on edge hardware for on-pitch analysis tools.
Load-bearing premise
Pretrained HAR embeddings from contact-centered short video segments already contain the motion cues needed to predict kick direction, so that no domain-specific fine-tuning or explicit biomechanical reconstruction is required.
What would settle it
Running the same pipeline on penalty-kick videos whose segments are deliberately shifted away from contact time and measuring whether accuracy falls to near-chance levels of 33 percent for three classes.
Figures



read the original abstract
Penalty kicks in soccer are decided under extreme time constraints, where goalkeepers benefit from anticipating shot direction from the kickers motion before or around ball contact. In this paper, MambaKick is presented as a learning-based framework for penalty direction prediction that leverages pretrained human action recognition (HAR) embeddings extracted from contact-centered short video segments and combines them with a lightweight temporal predictor. Rather than relying on explicit kinematic reconstruction or handcrafted biomechanical features, the approach reuses transferable spatiotemporal representations and utilizes selective state-spare models (Mamba) for efficient sequence aggregation. Simple contextual metadata (e.g., field side and footedness) are also considered as complementary cues that may reduce ambiguity in real-world footage. Across a range of HAR backbones, MambaKick consistently improves or matches strong embedding baselines, achieving up to 53.1% accuracy for three classes and 64.5% for two classes under the proposed methodology. Overall, the results indicate that combining pretrained HAR representations with efficient state-space temporal modeling is a practical direction for low-latency intention prediction in real-world sports video. The code will be available at GitHub: https://github.com/hvelesaca/MambaKick/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MambaKick, a framework for early prediction of soccer penalty kick directions (2- or 3-class) that extracts embeddings from pretrained HAR models on contact-centered short video segments and aggregates them with a lightweight Mamba-based temporal predictor, optionally augmented by contextual metadata such as field side and footedness. It reports that the approach consistently improves or matches strong embedding baselines across multiple HAR backbones, reaching up to 53.1% accuracy for three classes and 64.5% for two classes.
Significance. If the empirical results hold under proper validation, the work demonstrates a practical, low-latency method for reusing general-purpose HAR representations in sports intention prediction without explicit biomechanical reconstruction or domain-specific fine-tuning, highlighting the transferability of spatiotemporal embeddings to real-world video analytics tasks. The commitment to public code release supports reproducibility and potential adoption.
major comments (1)
- Abstract: The central performance claims (accuracy improvements over baselines, specific figures of 53.1% and 64.5%) are presented without any accompanying information on dataset size, class balance, number of trials, cross-validation procedure, statistical significance tests, or ablation isolating the Mamba aggregator, so the soundness of the headline empirical result cannot be assessed from the manuscript text.
minor comments (2)
- Abstract: The phrase 'under the proposed methodology' is vague and should explicitly reference the experimental protocol, tables, or figures that contain the quantitative results.
- Abstract: The GitHub link is welcome but the manuscript should state the expected contents (e.g., pretrained weights, evaluation scripts, dataset splits) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our empirical claims. We address the single major comment below and will revise the manuscript accordingly to improve accessibility of the results.
read point-by-point responses
-
Referee: Abstract: The central performance claims (accuracy improvements over baselines, specific figures of 53.1% and 64.5%) are presented without any accompanying information on dataset size, class balance, number of trials, cross-validation procedure, statistical significance tests, or ablation isolating the Mamba aggregator, so the soundness of the headline empirical result cannot be assessed from the manuscript text.
Authors: We agree that the abstract's conciseness limits immediate assessment of the headline numbers. The full manuscript provides these details in Section 3 (dataset: contact-centered penalty kick videos with subject counts, class distributions for 2- and 3-class settings, and trial numbers) and Section 4 (subject-independent cross-validation, statistical significance via paired tests, and ablations comparing Mamba against LSTM/Transformer/mean-pooling aggregators on the same HAR embeddings, shown in Tables 2 and 3). To address the concern directly, we will revise the abstract to include a short clause on dataset scale and evaluation protocol while preserving length constraints. This change will make the claims more self-contained without altering the reported accuracies. revision: yes
Circularity Check
No significant circularity; empirical comparison only
full rationale
The paper describes an empirical pipeline that extracts frozen pretrained HAR embeddings from short video clips, feeds them into a lightweight Mamba-based aggregator, optionally augments with metadata, and reports classification accuracies on 2- and 3-class kick-direction tasks. No equations, uniqueness theorems, or self-referential derivations appear in the provided text; the headline accuracies (53.1 % / 64.5 %) are presented strictly as measured outcomes of this architecture versus external baselines. Because the central claim is an experimental statement rather than a mathematical reduction, no step reduces by construction to a fitted quantity or self-citation chain defined inside the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained HAR models produce spatiotemporal embeddings that are transferable to soccer kick direction without task-specific retraining
Reference graph
Works this paper leans on
-
[1]
Journal of Economic Psychology28, 606–621 (2007)
Bar-Eli, M., Azar, O.H., Ritov, I.: Action bias among elite soccer goalkeepers: The case of penalty kicks. Journal of Economic Psychology28, 606–621 (2007). https://doi.org/10.1016/j.joep.2006.12.001
-
[2]
Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: Proceedings of the International Conference on Machine Learning (ICML) (2021)
2021
-
[3]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Cao,Z.,Simon,T.,Wei,S.E.,Sheikh,Y.:Realtimemulti-person2dposeestimation using part affinity fields. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
2017
-
[4]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
2017
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Cioppa, A., Deliège, A., Giancola, S., Ghanem, B., Van Droogenbroeck, M., Gade, R., Moeslund, T.B.: A context-aware loss function for action spotting in soccer videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
2020
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Fan, H., Xiong, B., Mangalam, K., Li, Y., Yan, Z., Malik, J., Feichtenhofer, C.: Multiscale vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6824–6835 (2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Feichtenhofer, C.: X3d: Expanding architectures for efficient video recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 203–213 (2020)
2020
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2019)
Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recog- nition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2019)
2019
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Feichtenhofer, C., Fan, H., Xiong, B., Girshick, R., He, K.: A large-scale study on unsupervised spatiotemporal representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3299–3309 (2021) MambaKick: Early Penalty Direction Prediction from HAR Embeddings 15
2021
-
[10]
In: International Congress on Sport Sciences Research and Technology Support (2025)
Freire-Obregón, D., Santana, O.J., Lorenzo-Navarro, J., Hernández-Sosa, D., Castrillón-Santana, M.: Gait-based prediction of penalty kick direction in soccer. In: International Congress on Sport Sciences Research and Technology Support (2025)
2025
-
[11]
In: 2025 23rd International Conference on Image Analysis and Processing (ICIAP) (2025)
Freire-Obregón, D., Santana, O.J., Lorenzo-Navarro, J., Hernández-Sosa, D., Castrillón-Santana, M.: Predicting Soccer Penalty Kick Direction Using Human Action Recognition. In: 2025 23rd International Conference on Image Analysis and Processing (ICIAP) (2025)
2025
-
[12]
Giancola, S., Amine, M., Dghaily, T., Ghanem, B.: Soccernet: A scalable dataset for action spotting in soccer videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2018).https: //doi.org/10.1109/CVPRW.2018.00223
-
[13]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023).https://doi.org/10.48550/ arXiv.2312.00752,https://arxiv.org/abs/2312.00752
work page Pith review arXiv 2023
-
[14]
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Computation 9(8), 1735–1780 (1997).https://doi.org/10.1162/neco.1997.9.8.1735
-
[15]
Journal of Sports Sciences24(5), 467–477 (2006).https://doi.org/10
van der Kamp, J.: A field simulation study of the effectiveness of penalty kick strategies in soccer: Late alterations of kick direction increase errors and reduce accuracy. Journal of Sports Sciences24(5), 467–477 (2006).https://doi.org/10. 1080/02640410500190841
2006
-
[16]
Sports Biomechanics10(2), 125–134 (2011).https://doi.org/10.1080/ 14763141.2011.569565
Lees, A., Owens, L.: Early visual cues associated with a directional place kick in soccer. Sports Biomechanics10(2), 125–134 (2011).https://doi.org/10.1080/ 14763141.2011.569565
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Y., Wu, C.Y., Fan, H., Mangalam, K., Xiong, B., Malik, J., Feichtenhofer, C.: Mvitv2: Improved multiscale vision transformers for classification and detec- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4804–4814 (2022)
2022
-
[18]
Li, Y., Alexander, M.J.L., Glazebrook, C.M., Leiter, J.R.S.: Prediction of kick di- rection from kinematics during the soccer penalty kick. International Journal of Ki- nesiology and Sports Science3(4), 1–7 (2015).https://doi.org/10.7575/aiac. ijkss.v.3n.4p.1,https://journals.aiac.org.au/index.php/IJKSS/article/ view/1903
-
[19]
Advances in neural information processing systems27(2014)
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recog- nition in videos. Advances in neural information processing systems27(2014)
2014
-
[20]
In: International Conference on Pattern Recognition Applications and Meth- ods (2023)
Torón-Artiles, J., Hernández-Sosa, D., Santana, O.J., Lorenzo-Navarro, J., Freire- Obregón, D.: Classifying soccer ball-on-goal position through kicker shooting ac- tion. In: International Conference on Pattern Recognition Applications and Meth- ods (2023)
2023
-
[21]
In: International Conference on Pattern Recog- nition Applications and Methods (2024)
Torón-Artiles, J., Hernández-Sosa, D., Santana, O.J., Lorenzo-Navarro, J., Freire- Obregón, D.: Heterogeneous transfer learning in sports: Human action recognition for gender and outcome prediction. In: International Conference on Pattern Recog- nition Applications and Methods (2024)
2024
-
[22]
In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
2017
-
[23]
Velesaca, H., Gomez-Cantos, A., Reyes-Angulo, A., Araujo, S.: S-amba: A multi- view foul recognition in soccer through a mamba-based approach. In: Proceedings of the 13th International Conference on Sport Sciences Research and Technology Support - Volume 1: icSPORTS. pp. 57–68. INSTICC, SciTePress (2025).https: //doi.org/10.5220/0013682500003988 16 Velesaca et al
-
[24]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 7794–7803 (2018)
2018
-
[25]
In: Proceedings of the AAAI Conference on Ar- tificial Intelligence (AAAI) (2018)
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI Conference on Ar- tificial Intelligence (AAAI) (2018)
2018
-
[26]
In: European Conference on Computer Vision (2021)
Zhang, Y., Sun, P., Jiang, Y., Yu, D., Yuan, Z., Luo, P., Liu, W., Wang, X.: Byte- Track: Multi-Object Tracking by Associating Every Detection Box. In: European Conference on Computer Vision (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.