Recognition: unknown
ReconVLA: An Uncertainty-Guided and Failure-Aware Vision-Language-Action Framework for Robotic Control
Pith reviewed 2026-05-10 07:56 UTC · model grok-4.3
The pith
Applying conformal prediction to the action outputs of pretrained vision-language-action models produces calibrated uncertainty that anticipates failures and cuts errors without retraining the base controller.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
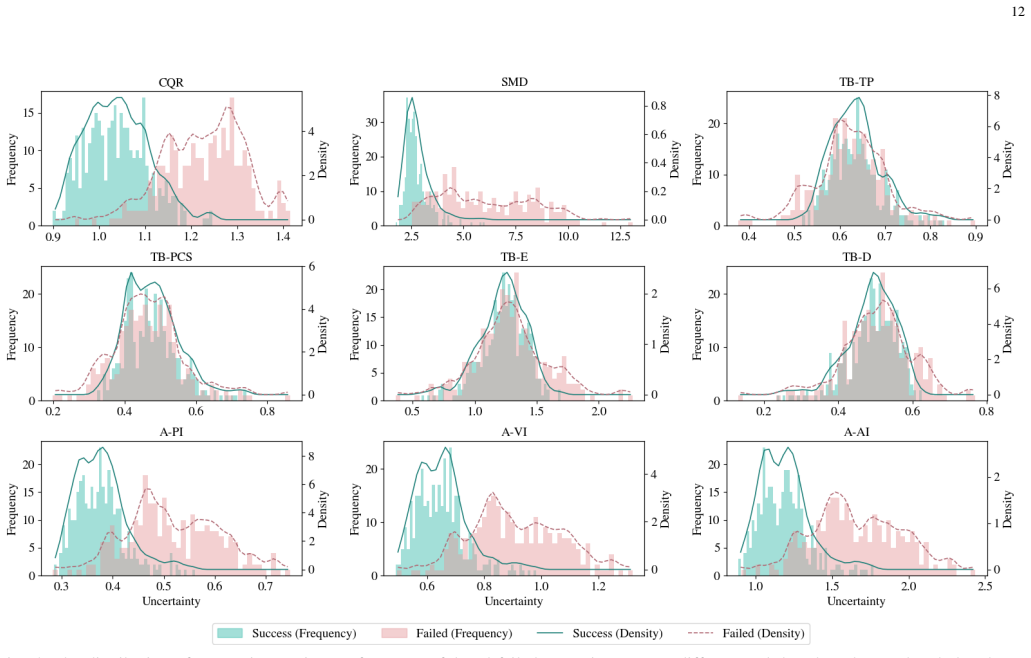
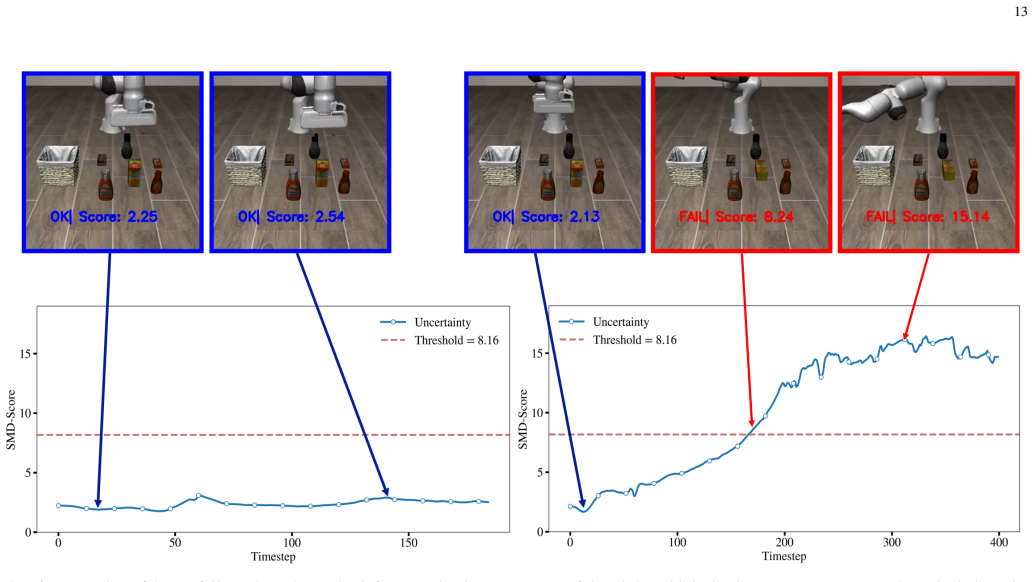
ReconVLA applies conformal prediction directly to the action token outputs of pretrained VLA policies, yielding calibrated uncertainty estimates that correlate with execution quality and task success. It further extends conformal prediction to the robot state space to detect outliers or unsafe states before failures occur, providing a failure detection mechanism that complements action-level uncertainty.
What carries the argument
Conformal prediction wrapped around action token outputs and robot states, which generates prediction sets and nonconformity scores that bound uncertainty without changing the underlying VLA policy.
If this is right
- Failure anticipation improves because uncertainty bounds on actions flag risky sequences before they are executed.
- Catastrophic errors drop when the controller uses uncertainty to trigger conservative or recovery behaviors.
- Calibrated confidence is available for any pretrained VLA without additional training or architecture changes.
- State-space outlier detection supplies an early warning layer that operates alongside action uncertainty.
Where Pith is reading between the lines
- These uncertainty signals could be fed into higher-level planners so robots decide whether to attempt a task or request human assistance.
- The same wrapping technique might apply to other sequence-generating policies in robotics that currently lack confidence measures.
- Combining the method with online adaptation could allow robots to improve their own uncertainty calibration during deployment.
Load-bearing premise
That the uncertainty scores produced by conformal prediction on action tokens will meaningfully track whether the robot will succeed or fail on a given task.
What would settle it
A set of manipulation trials in which high-uncertainty predictions still complete tasks at the same success rate as low-uncertainty predictions, or in which flagged state outliers do not precede actual execution failures.
Figures







read the original abstract
Vision-language-action (VLA) models have emerged as generalist robotic controllers capable of mapping visual observations and natural language instructions to continuous action sequences. However, VLAs provide no calibrated measure of confidence in their action predictions, thus limiting their reliability in real-world settings where uncertainty and failures must be anticipated. To address this problem we introduce ReconVLA, a reliable conformal model that produces uncertainty-guided and failure-aware control signals. Concretely, our approach applies conformal prediction directly to the action token outputs of pretrained VLA policies, yielding calibrated uncertainty estimates that correlate with execution quality and task success. Furthermore, we extend conformal prediction to the robot state space to detect outliers or unsafe states before failures occur, providing a simple yet effective failure detection mechanism that complements the action-level uncertainty. We evaluate ReconVLA in both simulation and real robot experiments across diverse manipulation tasks. Our results show that conformalized action predictions consistently improve failure anticipation, reduce catastrophic errors, and provide a calibrated measure of confidence without retraining or modifying the underlying VLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReconVLA, which applies conformal prediction directly to the action token outputs of pretrained vision-language-action (VLA) models to generate calibrated uncertainty estimates claimed to correlate with execution quality and task success. It extends the same technique to the robot state space for outlier detection and failure anticipation. The framework requires no retraining or modification of the base VLA and is evaluated in both simulation and real-robot experiments across diverse manipulation tasks, with results purportedly showing improved failure anticipation and reduced catastrophic errors.
Significance. If the central claims hold after addressing the exchangeability concern, the work offers a practical, training-free method to add calibrated uncertainty and failure awareness to existing generalist VLA controllers. This is significant for real-world robotic deployment, where anticipating failures is essential. A strength is the direct, parameter-free application to both action tokens and states without altering the underlying policy.
major comments (2)
- [Abstract] Abstract: The claim that conformalized action predictions yield 'calibrated uncertainty estimates that correlate with execution quality and task success' and 'consistently improve failure anticipation' is load-bearing for the contribution. Standard conformal prediction provides marginal coverage only under exchangeability of calibration and test points, but VLA action tokens are generated autoregressively and are temporally dependent within trajectories (and share environment dynamics across episodes). The manuscript applies vanilla conformal prediction without time-series adjustments such as blocking, episode-level exchangeability, or conformalized quantile regression for dependent data; this risks invalid coverage guarantees under distribution shift or online control.
- [§4] §4 (Evaluation): The reported correlation between uncertainty and task success, as well as the failure-detection performance in state space, must be re-evaluated with explicit checks for the exchangeability assumption (e.g., coverage rates on held-out trajectories under temporal blocking). Without such validation, the empirical improvements cannot be attributed to calibrated uncertainty rather than dataset-specific artifacts.
minor comments (2)
- [Abstract] The abstract would benefit from a one-sentence quantitative summary (e.g., average coverage rate or correlation coefficient) to support the 'consistently improve' claim.
- [§3] Notation for the conformal score and quantile in the methods section should be introduced with an explicit equation for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments on our manuscript. The points raised regarding the exchangeability assumption in conformal prediction are important for strengthening the theoretical grounding of ReconVLA. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that conformalized action predictions yield 'calibrated uncertainty estimates that correlate with execution quality and task success' and 'consistently improve failure anticipation' is load-bearing for the contribution. Standard conformal prediction provides marginal coverage only under exchangeability of calibration and test points, but VLA action tokens are generated autoregressively and are temporally dependent within trajectories (and share environment dynamics across episodes). The manuscript applies vanilla conformal prediction without time-series adjustments such as blocking, episode-level exchangeability, or conformalized quantile regression for dependent data; this risks invalid coverage guarantees under distribution shift or online control.
Authors: We acknowledge that the autoregressive generation of action tokens in VLA models introduces temporal dependencies that can violate the strict exchangeability assumption required for finite-sample marginal coverage guarantees in standard conformal prediction. Our approach applies conformal prediction marginally to the action token outputs (as detailed in Section 3) using a held-out calibration set drawn from the same distribution as the test trajectories, which is a common practical choice in robotics applications. While this does not provide distribution-free guarantees under arbitrary shifts, the resulting uncertainty scores empirically correlate with execution failures in both simulation and real-robot settings. In the revised manuscript we will (1) qualify the abstract claims to emphasize practical calibration and correlation rather than strict coverage, (2) add a paragraph in the discussion section referencing time-series conformal methods (e.g., block-based or adaptive conformal prediction) and explaining why vanilla CP was chosen for its training-free simplicity, and (3) include a brief analysis of coverage sensitivity to different calibration splits. revision: partial
-
Referee: [§4] §4 (Evaluation): The reported correlation between uncertainty and task success, as well as the failure-detection performance in state space, must be re-evaluated with explicit checks for the exchangeability assumption (e.g., coverage rates on held-out trajectories under temporal blocking). Without such validation, the empirical improvements cannot be attributed to calibrated uncertainty rather than dataset-specific artifacts.
Authors: We agree that additional validation would increase confidence that the observed correlations stem from the conformal uncertainty rather than dataset artifacts. In the revised Section 4 we will add explicit checks: coverage rates computed on temporally blocked held-out trajectories (grouping consecutive timesteps within episodes) versus standard random splits, as well as coverage plots stratified by task and environment. We will also report failure-detection metrics under these splits for the state-space conformal detector. If the blocked coverage deviates substantially, we will qualify the claims and discuss the practical implications for online deployment. revision: yes
Circularity Check
Direct application of standard conformal prediction with no self-referential derivations
full rationale
The paper's core contribution is the direct application of existing conformal prediction techniques to the action token outputs and state space of pretrained VLA policies, without introducing new equations, fitted parameters renamed as predictions, or derivations that reduce to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the method; the approach is presented as a straightforward extension of standard conformal prediction. The claimed improvements in failure anticipation and calibrated confidence are supported by empirical results on simulation and real-robot tasks rather than any load-bearing self-referential step. This is a normal, self-contained application of an external statistical tool.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Action token outputs from VLA policies satisfy the exchangeability assumption required for conformal prediction coverage guarantees
Reference graph
Works this paper leans on
-
[1]
Vision- language-action models for robotics: A review towards real-world ap- plications,
K. Kawaharazuka, J. Oh, J. Yamada, I. Posner, and Y . Zhu, “Vision- language-action models for robotics: A review towards real-world ap- plications,”IEEE Access, pp. 162 467–162 504, 2025
2025
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choroman- ski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. Gonza- lez Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Morda...
2023
-
[3]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burch- fiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” inProceedings of the Conference on Robot Learning, vol. 270. PMLR, 2024, pp. 2679– 2713
2024
-
[4]
π 0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π 0: A vision-language-action flow model for general robot control,” in Proceedings of Roboti...
2025
-
[5]
Foundation models in robotics: Applications, challenges, and the future,
R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y . Zhu, S. Song, A. Kapoor, K. Hausman, B. Ichter, D. Driess, J. Wu, C. Lu, and M. Schwager, “Foundation models in robotics: Applications, challenges, and the future,”The International Journal of Robotics Research, vol. 44, no. 5, pp. 701–739, 2025
2025
-
[6]
Towards out-of-distribution generalization: A survey.arXiv preprint arXiv:2108.13624, 2021
J. Liu, Z. Shen, Y . He, X. Zhang, R. Xu, H. Yu, and P. Cui, “Towards out-of-distribution generalization: A survey,”arXiv preprint arXiv:2108.13624, 2021
-
[7]
Real-time out-of-distribution failure prevention via multi-modal rea- soning,
M. Ganai, R. Sinha, C. Agia, D. Morton, L. Di Lillo, and M. Pavone, “Real-time out-of-distribution failure prevention via multi-modal rea- soning,” inProceedings of the Conference on Robot Learning, vol. 305. PMLR, 2025, pp. 283–308
2025
-
[8]
Uncertainty-aware data aggregation for deep imitation learning,
Y . Cui, D. Isele, S. Niekum, and K. Fujimura, “Uncertainty-aware data aggregation for deep imitation learning,” inProceedings of the IEEE International Conference on Robotics and Automation, 2019, pp. 761– 767
2019
-
[9]
Pablo Valle, Chengjie Lu, Shaukat Ali, and Aitor Arri- eta
P. Valle, C. Lu, S. Ali, and A. Arrieta, “Evaluating uncertainty and quality of visual language action-enabled robots,”arXiv preprint arXiv:2507.17049, 2025
-
[10]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” inProceedings of the International Conference on Machine Learning, vol. 48. PMLR, 2016, pp. 1050–1059
2016
-
[11]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” inProceedings of the Advances in Neural Information Processing Systems, vol. 30, 2017, pp. 6402–6413
2017
-
[12]
A tutorial on conformal prediction
G. Shafer and V . V ovk, “A tutorial on conformal prediction.”Journal of Machine Learning Research, vol. 9, no. 3, pp. 371–421, 2008
2008
-
[13]
Dropout sam- pling for robust object detection in open-set conditions,
D. Miller, L. Nicholson, F. Dayoub, and N. S ¨underhauf, “Dropout sam- pling for robust object detection in open-set conditions,” inProceedings of the IEEE International Conference on Robotics and Automation, 2018, pp. 3243–3249
2018
-
[14]
Probabilistic object detection via deep ensembles,
Z. Lyu, N. Gutierrez, A. Rajguru, and W. J. Beksi, “Probabilistic object detection via deep ensembles,” inProceedings of the European Conference on Computer Vision, 2020, pp. 67–75
2020
-
[15]
Uncertainty quantification and deep ensembles,
R. Rahaman and A. H. Thiery, “Uncertainty quantification and deep ensembles,” inProceedings of the Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 20 063–20 075
2021
-
[16]
Conformal prediction for ensem- bles: Improving efficiency via score-based aggregation,
Y . Patel, E. O. Rivera, and A. Tewari, “Conformal prediction for ensem- bles: Improving efficiency via score-based aggregation,” inProceedings of the Advances in Neural Information Processing Systems, 2025
2025
-
[17]
How certain is your transformer?
A. Shelmanov, E. Tsymbalov, D. Puzyrev, K. Fedyanin, A. Panchenko, and M. Panov, “How certain is your transformer?” inProceedings of the Conference of the European Chapter of the Association for Computational Linguistics, 2021, pp. 1833–1840
2021
-
[18]
Exploring predictive uncer- tainty and calibration in nlp: A study on the impact of method & data scarcity,
D. Ulmer, J. Frellsen, and C. Hardmeier, “Exploring predictive uncer- tainty and calibration in nlp: A study on the impact of method & data scarcity,” inProceedings of the Conference on Empirical Methods in Natural Language Processing, 2022, pp. 2707–2735
2022
-
[19]
Conformal prediction for natural language processing: A survey,
M. Campos, A. Farinhas, C. Zerva, M. A. Figueiredo, and A. F. Martins, “Conformal prediction for natural language processing: A survey,” Transactions of the Association for Computational Linguistics, vol. 12, pp. 1497–1516, 2024
2024
-
[20]
Robots that ask for help: Uncertainty alignment for large language model planners,
A. Z. Ren, A. Dixit, A. Bodrova, S. Singh, S. Tu, N. Brown, P. Xu, L. Takayama, F. Xia, J. Varley, Z. Xu, D. Sadigh, A. Zeng, and A. Majumdar, “Robots that ask for help: Uncertainty alignment for large language model planners,” inProceedings of the Conference on Robot Learning, vol. 229. PMLR, 2023, pp. 661–682
2023
-
[21]
AHA: A vision- language-model for detecting and reasoning over failures in robotic ma- nipulation,
J. Duan, W. Pumacay, N. Kumar, Y . R. Wang, S. Tian, W. Yuan, R. Krishna, D. Fox, A. Mandlekar, and Y . Guo, “AHA: A vision- language-model for detecting and reasoning over failures in robotic ma- nipulation,” inProceedings of the International Conference on Learning Representations, 2025
2025
-
[22]
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective,
Y . Zhong, F. Bai, S. Cai, X. Huang, Z. Chen, X. Zhang, Y . Wang, S. Guo, T. Guan, K. N. Lui, Z. Qi, Y . Liang, Y . Chen, and Y . Yang, “A survey on vision-language-action models: An action tokenization perspective,” arXiv preprint arXiv:2507.01925, 2025
-
[23]
Conformal decision theory: Safe autonomous decisions from imperfect 17 predictions,
J. Lekeufack, A. N. Angelopoulos, A. Bajcsy, M. I. Jordan, and J. Malik, “Conformal decision theory: Safe autonomous decisions from imperfect 17 predictions,” inProceedings of the IEEE International Conference on Robotics and Automation, 2024, pp. 11 668–11 675
2024
-
[24]
Conformalized quantile regression,
Y . Romano, E. Patterson, and E. Candes, “Conformalized quantile regression,” inProceedings of the Advances in Neural Information Processing Systems, vol. 32, 2019, pp. 3543–3553
2019
-
[25]
A generalist agent,
S. Reed, K. ˙Zołna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-Maron, M. Gim ´enez, Y . Sulsky, J. Kay, J. T. Springenberg, T. Eccles, J. Bruce, A. Razavi, A. Edwards, N. Heess, Y . Chen, R. Hadsell, O. Vinyals, M. Bordbar, and N. de Freitas, “A generalist agent,”Transactions on Machine Learning Research, 2022
2022
-
[26]
Do as i can, not as i say: Grounding language in robotic affordances,
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. J. Ruano, K. Jeffrey, S. Jesmonth, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Rettinghou...
2022
-
[27]
Palm: Scaling language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y . Tay, N. Shazeer, V . Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghe- mawat, S. De...
2023
-
[28]
Palm- e: An embodied multimodal language model,
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence, “Palm- e: An embodied multimodal language model,” inProceedings of the International Conferenc...
2023
-
[29]
R. M. Neal,Bayesian learning for neural networks. Springer Science & Business Media, 2012, vol. 118
2012
-
[30]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A. N. Angelopoulos and S. Bates, “A gentle introduction to confor- mal prediction and distribution-free uncertainty quantification,”arXiv preprint arXiv:2107.07511, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
An uncertainty estimation framework for probabilistic object detection,
Z. Lyu, N. B. Gutierrez, and W. J. Beksi, “An uncertainty estimation framework for probabilistic object detection,” inProceedings of the IEEE International Conference on Automation Science and Engineering, 2021, pp. 1441–1446
2021
-
[32]
Conformal prediction for uncertainty-aware planning with diffusion dynamics model,
J. Sun, Y . Jiang, J. Qiu, P. Nobel, M. J. Kochenderfer, and M. Schwager, “Conformal prediction for uncertainty-aware planning with diffusion dynamics model,” inProceedings of the Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 80 324–80 337
2023
-
[33]
Conformalized teleoperation: Confidently mapping human inputs to high-dimensional robot actions,
M. D. Zhao, R. Simmons, H. Admoni, and A. Bajcsy, “Conformalized teleoperation: Confidently mapping human inputs to high-dimensional robot actions,” inProceedings of Robotics: Science and Systems, 2024
2024
-
[34]
Uncertainty and exploration,
S. J. Gershman, “Uncertainty and exploration,”Decision, vol. 6, no. 3, pp. 277–286, 2019
2019
-
[35]
Racer: Epistemic risk-sensitive rl enables fast driving with fewer crashes,
K. Stachowicz and S. Levine, “Racer: Epistemic risk-sensitive rl enables fast driving with fewer crashes,” inProceedings of Robotics: Science and Systems, 2024
2024
-
[36]
Estimating uncer- tainty in multimodal foundation models using public internet data,
S. Dutta, H. Wei, L. van der Laan, and A. Alaa, “Estimating uncer- tainty in multimodal foundation models using public internet data,” in Proceedings of the Advances in Neural Information Processing Systems Workshops, 2023
2023
-
[37]
Know where you’re uncertain when planning with multimodal foundation models: A formal framework,
N. P. Bhatt, Y . Yang, R. Siva, D. Milan, U. Topcu, and Z. Wang, “Know where you’re uncertain when planning with multimodal foundation models: A formal framework,” inProceedings of the Conference on Machine Learning and Systems, 2025
2025
-
[38]
Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies,
C. Xu, T. K. Nguyen, E. Dixon, C. Rodriguez, P. Miller, R. Lee, P. Shah, R. Ambrus, H. Nishimura, and M. Itkina, “Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies,” inProceedings of Robotics: Science and Systems, 2025
2025
-
[39]
Confidence calibration in vision-language-action models.arXiv preprint arXiv:2507.17383, 2025
T. P. Zollo and R. Zemel, “Confidence calibration in vision-language- action models,”arXiv preprint arXiv:2507.17383, 2025
-
[40]
Ask before you act: Token-level uncertainty for intervention in vision-language-action models,
U. B. Karli, T. Kurumisawa, and T. Fitzgerald, “Ask before you act: Token-level uncertainty for intervention in vision-language-action models,” inWorkshop on Out-of-Distribution Generalization in Robotics at Robotics: Science and Systems, 2025
2025
-
[41]
Rediffuser: Reliable decision- making using a diffuser with confidence estimation,
N. He, S. Li, Z. Li, Y . Liu, and Y . He, “Rediffuser: Reliable decision- making using a diffuser with confidence estimation,” inProceedings of the International Conference on Machine Learning. PMLR, 2024, pp. 17 921–17 933
2024
-
[42]
Safe: Multitask failure detection for vision-language- action models,
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti, “Safe: Multitask failure detection for vision-language- action models,” inProceedings of the Advances in Neural Information Processing Systems, 2025
2025
-
[43]
Robomonkey: Scaling test-time sampling and verification for vision-language-action models,
J. Kwok, C. Agia, R. Sinha, M. Foutter, S. Li, I. Stoica, A. Mirho- seini, and M. Pavone, “Robomonkey: Scaling test-time sampling and verification for vision-language-action models,” inProceedings of the Conference on Robot Learning, vol. 305. PMLR, 2025, pp. 3200– 3217
2025
-
[44]
Run-time observation interventions make vision-language-action models more visually robust,
A. J. Hancock, A. Z. Ren, and A. Majumdar, “Run-time observation interventions make vision-language-action models more visually robust,” inProceedings of the IEEE International Conference on Robotics and Automation, 2025, pp. 9499–9506
2025
-
[45]
Failure prediction at runtime for generative robot policies,
R. R ¨omer, A. Kobras, L. Worbis, and A. P. Schoellig, “Failure prediction at runtime for generative robot policies,” inProceedings of the Advances in Neural Information Processing Systems, 2025
2025
-
[46]
On the generalised distance in statistics,
P. C. Mahalanobis, “On the generalised distance in statistics,” inPro- ceedings of the National Institute of Science of India, vol. 12, 1936, pp. 49–55
1936
-
[47]
Tip-over detection and avoidance algorithms as stabiliza- tion strategy for small-footprint and lightweight mobile manipulators,
A. Toledo Fuentes, F. Kempf, M. Kipfm ¨uller, T. Bergmann, and M. J. Prieto, “Tip-over detection and avoidance algorithms as stabiliza- tion strategy for small-footprint and lightweight mobile manipulators,” Machines, vol. 11, no. 1, p. 44, 2022
2022
-
[48]
Adaptive admittance control for safety-critical physical human robot collaboration,
Y . Sun, M. Van, S. McIlvanna, N. N. Minh, S. McLoone, and D. Ceglarek, “Adaptive admittance control for safety-critical physical human robot collaboration,”IFAC-PapersOnLine, vol. 56, no. 2, pp. 1313–1318, 2023
2023
-
[49]
Fine-tuning vision-language-action models: Optimizing speed and success,
M. J. Kim, C. Finn, and P. Liang, “Fine-tuning vision-language-action models: Optimizing speed and success,” inProceedings of Robotics: Science and Systems, 2025
2025
-
[50]
A critique and improvement of the cl common language effect size statistics of mcgraw and wong,
A. Vargha and H. D. Delaney, “A critique and improvement of the cl common language effect size statistics of mcgraw and wong,”Journal of Educational and Behavioral Statistics, vol. 25, no. 2, pp. 101–132, 2000
2000
-
[51]
Estimation of the youden index and its associated cutoff point,
R. Fluss, D. Faraggi, and B. Reiser, “Estimation of the youden index and its associated cutoff point,”Biometrical Journal: Journal of Math- ematical Methods in Biosciences, vol. 47, no. 4, pp. 458–472, 2005
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.