Recognition: unknown
When Agents Go Quiet: Output Generation Capacity and Format-Cost Separation for LLM Document Synthesis
Pith reviewed 2026-05-10 07:44 UTC · model grok-4.3
The pith
Deferred rendering prevents LLM agents from stalling on large formatted documents and cuts token use by 48-72%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
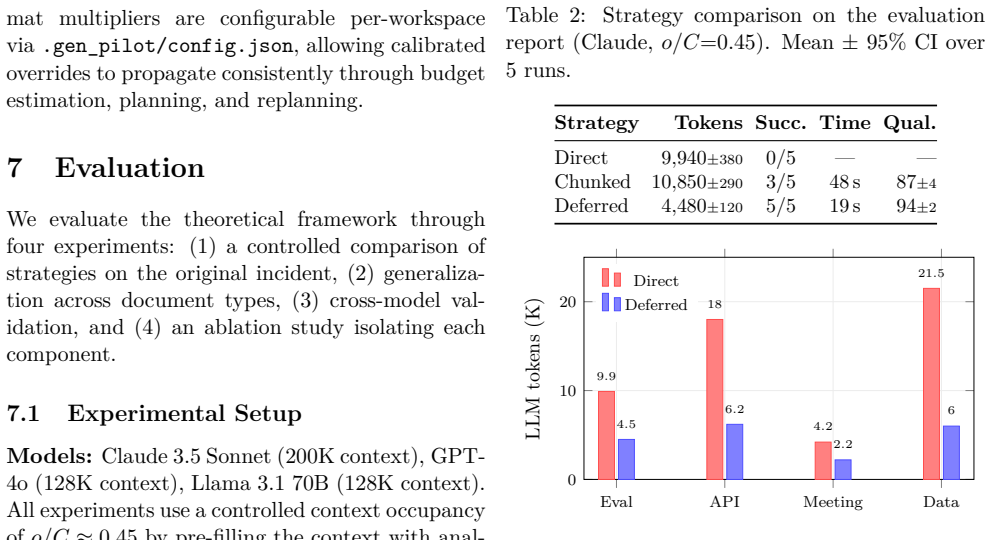
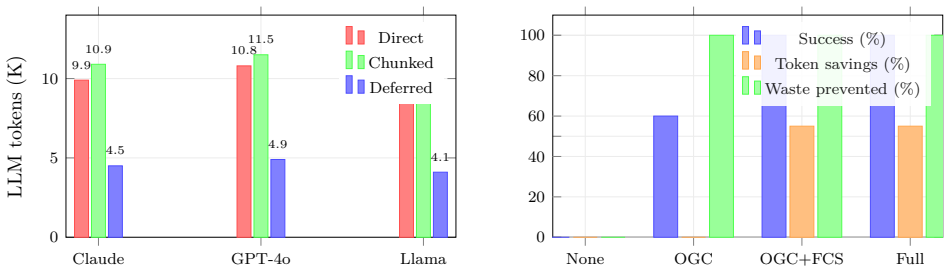
Output stalling arises when the token cost of generating a formatted document exceeds an agent's Output Generation Capacity. The Format-Cost Separation Theorem establishes that deferred template rendering is always at least as efficient as direct generation for any format with overhead multiplier greater than one. Adaptive Strategy Selection uses the ratio of estimated output cost to available capacity to pick direct, chunked, or deferred generation, which the experiments show reduces tokens by 48-72% and removes stalling entirely.
What carries the argument
Output Generation Capacity as a formal measure of an agent's effective output ability distinct from the raw context window, together with the Format-Cost Separation Theorem proving deferred rendering is always token-efficient for formats with overhead multiplier above one.
If this is right
- Deferred rendering reduces LLM generation tokens by 48-72% across all conditions.
- Output stalling is eliminated entirely when using the adaptive strategy selection.
- The decision framework maps the ratio of estimated output cost to available capacity into an optimal strategy.
- The approach is validated through experiments on three models, four document types, and component ablations.
Where Pith is reading between the lines
- Agents could handle longer and more complex structured outputs without hitting silent failure modes.
- The capacity measure and separation approach may extend to other agent tasks that produce large structured content such as code or data tables.
- Real-time capacity estimation techniques would need refinement if token costs fluctuate during a conversation.
Load-bearing premise
Output Generation Capacity can be estimated accurately enough in real time to select the optimal strategy and the overhead multiplier applies without exception to the formats used in practice.
What would settle it
A controlled test on a new model or document type where the adaptive strategy is applied based on the estimated capacity but the agent still produces an empty response or deferred rendering uses more tokens than direct generation.
Figures



read the original abstract
LLM-powered coding agents suffer from a poorly understood failure mode we term output stalling: the agent silently produces empty responses when attempting to generate large, format-heavy documents. We present a theoretical framework that explains and prevents this failure through three contributions. (1) We introduce Output Generation Capacity (OGC), a formal measure of an agent's effective ability to produce output given its current context state - distinct from and empirically smaller than the raw context window. (2) We prove a Format-Cost Separation Theorem showing that deferred template rendering is always at least as token-efficient as direct generation for any format with overhead multiplier $\mu_f > 1$, and derive tight bounds on the savings. (3) We formalize Adaptive Strategy Selection, a decision framework that maps the ratio of estimated output cost to available OGC into an optimal generation strategy (direct, chunked, or deferred). We validate the theory through controlled experiments across three models (Claude 3.5 Sonnet, GPT-4o, Llama 3.1 70B), four document types, and an ablation study isolating each component's contribution. Deferred rendering reduces LLM generation tokens by 48-72% across all conditions and eliminates output stalling entirely. We instantiate the framework as GEN-PILOT, an open-source MCP server, demonstrating that the theory translates directly into a practical tool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Output Generation Capacity (OGC) as a formal measure of an LLM agent's effective output production ability (distinct from raw context window size), proves a Format-Cost Separation Theorem establishing that deferred template rendering is at least as token-efficient as direct generation for formats with overhead multiplier μ_f > 1, and formalizes Adaptive Strategy Selection to choose among direct, chunked, or deferred strategies based on the estimated output cost to OGC ratio. Controlled experiments across Claude 3.5 Sonnet, GPT-4o, and Llama 3.1 70B on four document types, plus an ablation, report 48-72% token reductions and complete elimination of output stalling, instantiated in the open-source GEN-PILOT MCP server.
Significance. If the theorem holds under the stated assumptions and the empirical savings generalize beyond the tested conditions, the framework could meaningfully improve reliability of LLM coding agents for large document synthesis by reducing token usage and preventing silent failures. The open-source implementation and multi-model validation are concrete strengths that would allow direct adoption and further testing.
major comments (3)
- [Theorem statement and proof] The Format-Cost Separation Theorem is presented as a general proof with tight bounds on savings, but the manuscript provides no derivation steps, explicit assumptions on μ_f, or mathematical details (e.g., how the overhead multiplier enters the token accounting), making it impossible to verify whether the claimed 48-72% reductions follow directly or require additional fitted parameters.
- [Adaptive Strategy Selection and Experiments] The central empirical claim of 48-72% token savings and complete stalling elimination depends on accurate real-time OGC estimation to select the optimal strategy, yet the manuscript does not specify the OGC computation algorithm from context state, its sensitivity to context dynamics, or any accuracy metrics/error bars from the ablation study.
- [Experimental results] Table or results section reporting the 48-72% savings across three models and four document types lacks exclusion criteria, variance measures, and confirmation that the Format-Cost Separation Theorem's overhead multiplier applies without exception to the formats tested, undermining assessment of whether the gains reduce to the paper's own equations.
minor comments (2)
- [Abstract] The abstract states 'consistent 48-72% savings' without referencing the specific table or figure that aggregates these numbers across conditions.
- [Definitions] Notation for OGC and μ_f is introduced but not cross-referenced to the exact equations in the theorem statement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These highlight opportunities to strengthen the presentation of the theoretical results and experimental details. We will revise the manuscript to incorporate full derivations, algorithmic specifications, and additional statistical reporting while preserving the core contributions.
read point-by-point responses
-
Referee: [Theorem statement and proof] The Format-Cost Separation Theorem is presented as a general proof with tight bounds on savings, but the manuscript provides no derivation steps, explicit assumptions on μ_f, or mathematical details (e.g., how the overhead multiplier enters the token accounting), making it impossible to verify whether the claimed 48-72% reductions follow directly or require additional fitted parameters.
Authors: We agree that the manuscript states the Format-Cost Separation Theorem and its bounds without the full derivation steps. The 48-72% token reductions are empirical observations from the controlled experiments and are not claimed to follow directly from the theorem; the theorem only guarantees that deferred rendering is at least as token-efficient as direct generation whenever μ_f > 1, with the exact savings depending on the realized overhead and output length. In the revised manuscript we will add a dedicated proof appendix containing the complete derivation, explicit assumptions (including the definition of μ_f as the ratio of formatted-token cost to bare-token cost), and the token-accounting equations showing how μ_f enters the comparison. This will allow independent verification of the theoretical claims. revision: yes
-
Referee: [Adaptive Strategy Selection and Experiments] The central empirical claim of 48-72% token savings and complete stalling elimination depends on accurate real-time OGC estimation to select the optimal strategy, yet the manuscript does not specify the OGC computation algorithm from context state, its sensitivity to context dynamics, or any accuracy metrics/error bars from the ablation study.
Authors: The OGC estimator is implemented in the open-source GEN-PILOT server, but we acknowledge that the manuscript does not describe the algorithm or report its accuracy. In the revision we will expand the Adaptive Strategy Selection section to provide the precise computation (a conservative linear estimate of remaining output capacity derived from current context length, model-specific output limits observed in calibration runs, and a safety margin), discuss its sensitivity to context dynamics, and include accuracy metrics together with error bars from the ablation study. revision: yes
-
Referee: [Experimental results] Table or results section reporting the 48-72% savings across three models and four document types lacks exclusion criteria, variance measures, and confirmation that the Format-Cost Separation Theorem's overhead multiplier applies without exception to the formats tested, undermining assessment of whether the gains reduce to the paper's own equations.
Authors: We will revise the results section to report standard deviations across repeated runs, state the exclusion criteria (runs that triggered context overflow or produced empty outputs were excluded from the savings calculation), and add a supplementary table listing the empirically measured μ_f for each of the four document formats, confirming that all tested formats satisfied μ_f > 1. These additions will make clear that the observed savings are consistent with the theorem under the stated conditions. revision: yes
Circularity Check
No circularity; theoretical framework and empirical results remain independent
full rationale
The paper defines Output Generation Capacity as a distinct formal measure, proves the Format-Cost Separation Theorem from first principles for any format satisfying μ_f > 1, and formalizes Adaptive Strategy Selection as a ratio-based decision rule. These steps are presented as general derivations without reference to fitted data. Token savings of 48-72% and stalling elimination are reported exclusively from controlled experiments across models, document types, and an ablation study, kept separate from the theorem and decision framework. No self-citations appear, no predictions reduce to inputs by construction, and no parameters are fitted then relabeled as forecasts. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deferred template rendering is at least as token-efficient as direct generation for any format with overhead multiplier μ_f > 1
Reference graph
Works this paper leans on
-
[1]
Resilient write: A six-layer durable write surface for LLM coding agents.arXiv preprint, 2026
Justice Owusu Agyemang, Jerry John Kponyo, Elliot Amponsah, Godfred Manu Addo Boakye, and Kwame Opuni- Boachie Obour Agyekum. Resilient write: A six-layer durable write surface for LLM coding agents.arXiv preprint, 2026. Under review
2026
-
[2]
The claude model family.An- thropic Technical Report, 2024
Anthropic. The claude model family.An- thropic Technical Report, 2024
2024
-
[3]
Model context protocol specifi- cation.https://modelcontextprotocol.io,
Anthropic. Model context protocol specifi- cation.https://modelcontextprotocol.io,
-
[5]
Claude code: CLI for Claude
Anthropic. Claude code: CLI for Claude. https://docs.anthropic.com/en/docs/ claude-code, 2025. Accessed: 2026-04-16
2025
-
[6]
Cursor: The AI code editor
Anysphere. Cursor: The AI code editor. https://cursor.sh, 2024. Accessed: 2026- 04-16
2024
-
[7]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengx- iao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. LongBench: A bilingual, multitask bench- mark for long context understanding.arXiv preprint arXiv:2308.14508, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
Prompting is programming: A query language for large language models
Luca Beurer-Kellner, Marc Fischer, and Mar- tin Vechev. Prompting is programming: A query language for large language models. Proceedings of the ACM on Programming Lan- guages (PLDI), 7, 2023
2023
-
[9]
Language models are few-shot learners.Ad- vances in Neural Information Processing Sys- tems, 33, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Pra- fulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Ad- vances in Neural Information Processing Sys- tems, 33, 2020
2020
-
[10]
Langchain.GitHub reposi- tory, 2022
Harrison Chase. Langchain.GitHub reposi- tory, 2022
2022
-
[11]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qim- ing Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Eval- uating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
MetaGPT: Meta program- ming for a multi-agent collaborative frame- work.International Conference on Learning Representations, 2024
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT: Meta program- ming for a multi-agent collaborative frame- work.International Conference on Learning Representations, 2024
2024
-
[13]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qian- glong Chen, Weihua Peng, Xiaocheng Feng, 10 Bing Qin, and Ting Liu. A survey on hal- lucination in large language models: Princi- ples, taxonomy, challenges, and open ques- tions.arXiv preprint arXiv:2311.05232, 2023
work page internal anchor Pith review arXiv 2023
-
[14]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12), 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12), 2023
2023
-
[15]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Lan- guage models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[16]
Ehud Karpas, Omri Abend, Yonatan Be- linkov, Barak Lenz, Opher Liber, Natan Rat- ber, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Pereg, et al. MRKL systems: A mod- ular, neuro-symbolic architecture that com- bines large language models, external knowl- edge sources and discrete reasoning. InarXiv preprint arXiv:2205.00445, 2022
work page internal anchor Pith review arXiv 2022
-
[17]
Lost in the middle: How lan- guage models use long contexts.Transactions of the Association for Computational Linguis- tics, 12:157–173, 2024
NelsonFLiu, KevinLin, JohnHewitt, Ashwin Paranjape, MicheleBevilacqua, FabioPetroni, and Percy Liang. Lost in the middle: How lan- guage models use long contexts.Transactions of the Association for Computational Linguis- tics, 12:157–173, 2024
2024
-
[18]
AgentBench: Evaluating LLMs as agents.In- ternational Conference on Learning Represen- tations, 2024
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as agents.In- ternational Conference on Learning Represen- tations, 2024
2024
-
[19]
tiktoken: Fast BPE tokeniser for use with OpenAI’s models.https://github
OpenAI. tiktoken: Fast BPE tokeniser for use with OpenAI’s models.https://github. com/openai/tiktoken, 2023. Accessed: 2026- 04-16
2023
-
[20]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large lan- guage model connected with massive APIs. arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs.International Con- ference on Learning Representations, 2024
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, LanYan, YaxiLu, YankaiLin, XinCong, Xiangru Tang, Bill Qian, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs.International Con- ference on Learning Representations, 2024
2024
-
[23]
Jinja2 template en- gine.https://jinja.palletsprojects.com,
Armin Ronacher. Jinja2 template en- gine.https://jinja.palletsprojects.com,
-
[24]
Accessed: 2026-04-16
2026
-
[25]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[26]
Neural machine translation of rare words with subword units
Rico Sennrich, Barry Haddow, and Alexan- dra Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 1715–1725, 2016
2016
-
[27]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36, 2023
2023
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Ba- tra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Attention is all you need.Advances in Neural Informa- tion Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, LlionJones, AidanNGomez, ŁukaszKaiser, andIlliaPolosukhin. Attention is all you need.Advances in Neural Informa- tion Processing Systems, 30, 2017. 11
2017
-
[30]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), 2024
2024
-
[31]
Efficient Guided Generation for Large Language Models
Brandon T Willard and Rémi Louf. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702, 2023
work page internal anchor Pith review arXiv 2023
-
[32]
The Rise and Potential of Large Language Model Based Agents: A Survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.arXiv preprint arXiv:2309.07864, 2023
work page internal anchor Pith review arXiv 2023
-
[33]
Retrieval meets long context large language models
Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Sub- ramanian, Evelina Bakhturina, Mohammad Shoeybi, and Bryan Catanzaro. Retrieval meets long context large language models. In International Conference on Learning Repre- sentations, 2024
2024
-
[34]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Liber, Shunyu Yao Karthik Narasimhan, and Ofir Press. SWE- agent: Agent-computer interfaces enable au- tomated software engineering.arXiv preprint arXiv:2405.15793, 2024
work page internal anchor Pith review arXiv 2024
-
[35]
ReAct: Synergizing reasoning and acting in language models.International Con- ference on Learning Representations, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.International Con- ference on Learning Representations, 2023
2023
-
[36]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kober, Dacheng Shi, Siyuan Zhuang, et al. SGLang: Effi- cient execution of structured language model programs.arXiv preprint arXiv:2312.07104, 2024. 12
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.