Recognition: unknown
Why Training-Free Token Reduction Collapses: The Inherent Instability of Pairwise Scoring Signals
Pith reviewed 2026-05-10 07:55 UTC · model grok-4.3
The pith
Training-free token reduction collapses at high compression because pairwise similarity signals lose ranking consistency in deeper layers of Vision Transformers, creating a signal-agnostic error amplifier in layer-wise reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
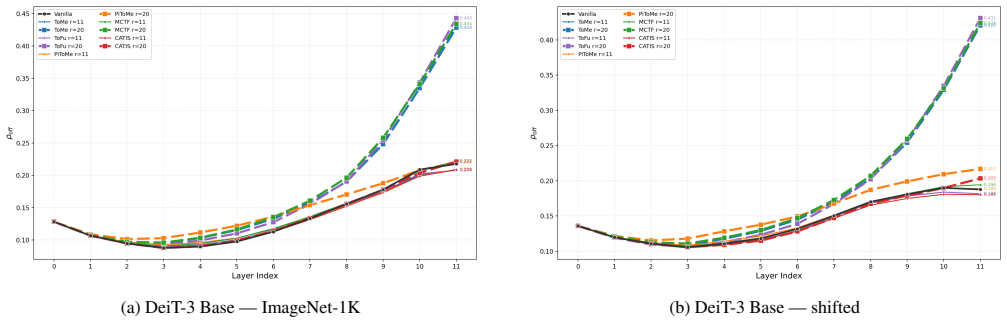
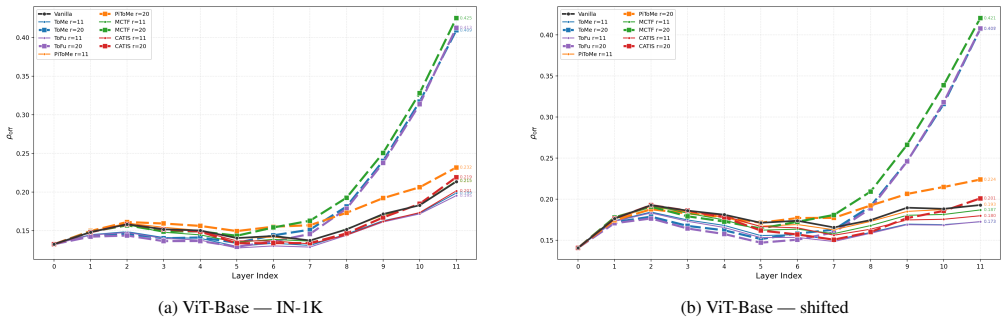
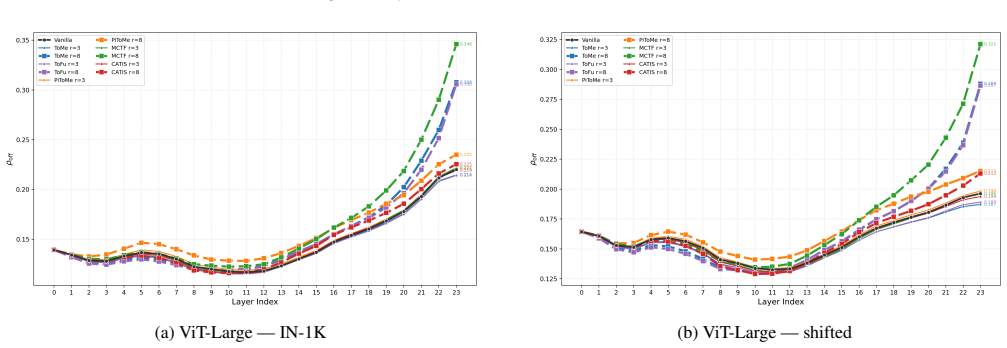
The central claim is that the observed collapse arises from the combination of a signal-agnostic error amplifier inherent to sequential layer-wise token reduction, which predicts convex Pareto curves and a critical reduction ratio proportional to one over model depth, and the shared use of pairwise similarity signals whose ranking consistency degrades sharply from 0.88 to 0.27 across layers. Pairwise rankings are unstable due to O(N_p squared) joint perturbations, while unary signals enjoy greater stability under O(N_p) perturbations and the central limit theorem. This diagnosis directly yields three design principles that are validated by constructing an alternative method using unary cues.
What carries the argument
The diagnostic framework consisting of ranking consistency rho_s and off-diagonal correlation rho_off, which decomposes the collapse into error amplification and pairwise signal instability; the contrast between pairwise similarity signals and unary signals as carriers of ranking information.
If this is right
- All methods that rely on pairwise similarity signals will display similar cliff-like accuracy drops once compression exceeds the critical ratio.
- The critical compression ratio scales inversely with the number of layers in the model.
- Switching to unary signals raises the compression threshold at which collapse begins.
- A triage step that limits error propagation allows higher compression while preserving most of the original accuracy.
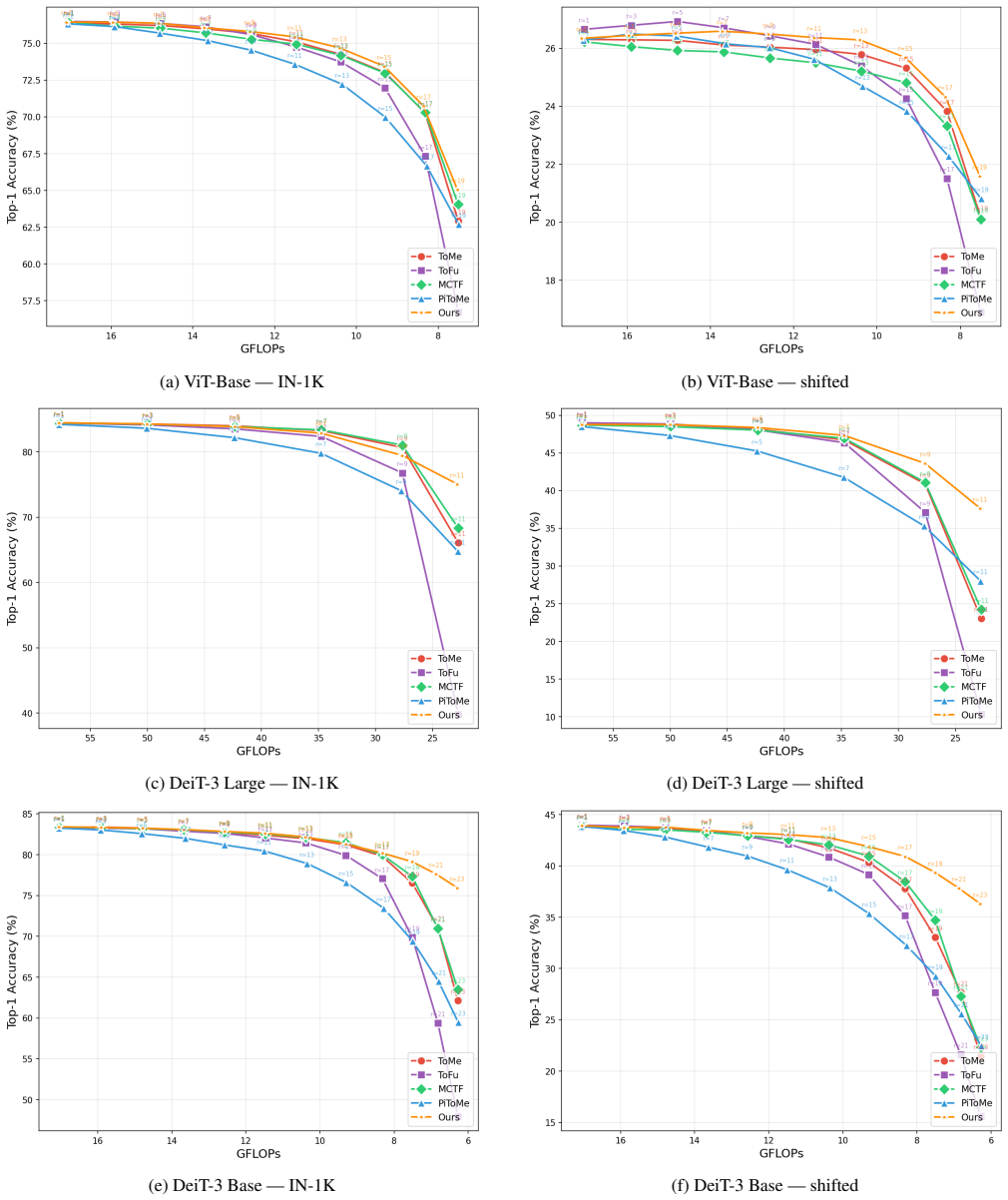
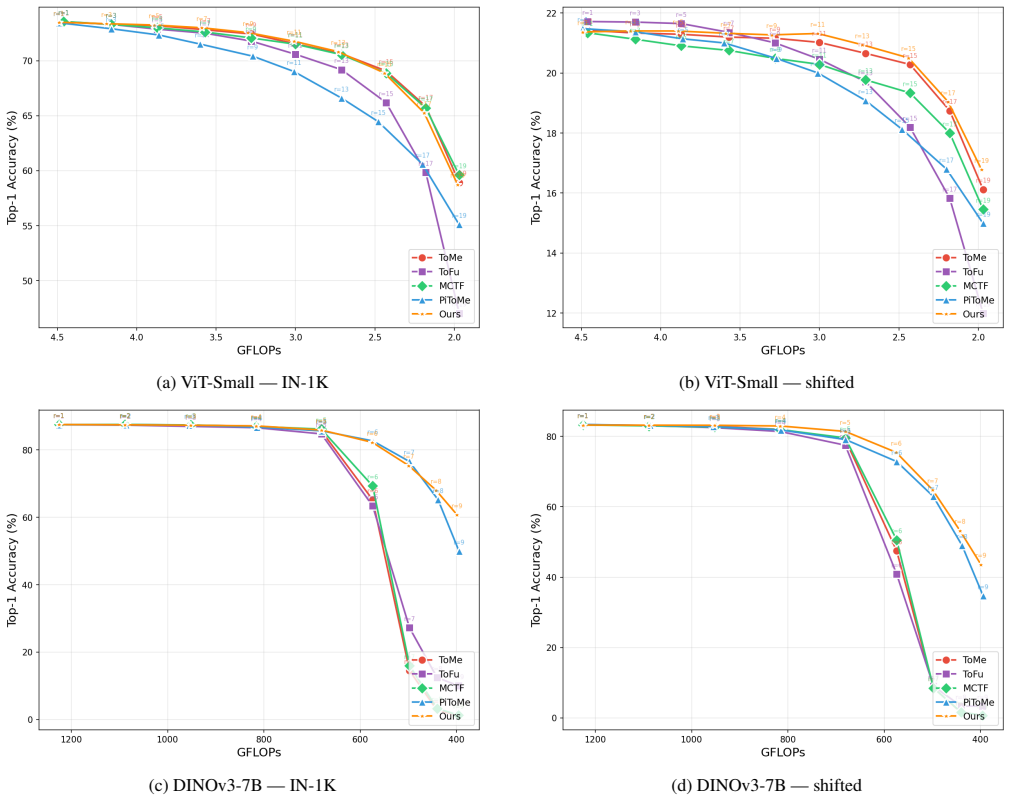
- The alternative method built from these principles retains 96.9 percent of original accuracy at 63 percent FLOPs reduction.
Where Pith is reading between the lines
- The same layer-wise instability may appear in sequence reduction tasks outside image classification whenever reductions are applied sequentially through transformer blocks.
- Layer-depth-adaptive choice between pairwise and unary signals could be tested as a general strategy for other efficiency techniques.
- The diagnostic metrics could be applied to quantify robustness in related compression settings such as attention head pruning.
- Models with fewer layers would be expected to tolerate higher per-layer reduction ratios before the error amplifier dominates.
Load-bearing premise
The measured drop in pairwise ranking consistency together with the layer-wise error amplification are the dominant drivers of collapse rather than other unmeasured factors such as particular attention patterns or dataset properties.
What would settle it
A controlled replacement of pairwise similarity scoring with unary signals in an existing reduction pipeline, followed by measurement of whether accuracy remains above 80 percent at the 63 percent FLOPs reduction point where pairwise methods drop to the 43-65 percent range on the same Vision Transformer and dataset.
Figures











read the original abstract
Training-free token reduction methods for Vision Transformers (ToMe, ToFu, PiToMe, and MCTF) employ different scoring mechanisms, yet they share a closely matched cliff-like collapse at high compression. This paper explains \emph{why}. We develop a diagnostic framework with two tools, ranking consistency $\rho_s$ and off-diagonal correlation $\rho_\text{off}$, that decomposes the collapse into (1)a signal-agnostic error amplifier inherent to layer-wise reduction, predicting convex Pareto curves and $r_{\text{crit}} \propto 1/L$; and (2)shared reliance on \emph{pairwise} similarity signals whose ranking consistency degrades from $\rho_s{=}0.88$ to $0.27$ in deep layers. Pairwise rankings are inherently unstable ($O(N_p^2)$ joint perturbations) while unary signals enjoy greater stability ($O(N_p)$ perturbations, CLT). From three design principles derived from this diagnosis, we construct CATIS as a constructive validation: unary signals raise the trigger threshold, triage suppresses the gain. On ViT-Large at 63% FLOPs reduction, CATIS retains 96.9% of vanilla accuracy (81.0%) on ImageNet-1K where all baselines collapse to 43--65%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that training-free token reduction methods (ToMe, ToFu, PiToMe, MCTF) for Vision Transformers exhibit closely matched cliff-like collapse at high compression because of two factors: (1) a signal-agnostic error amplifier inherent to layer-wise reduction that predicts convex Pareto curves and r_crit ∝ 1/L, and (2) shared reliance on pairwise similarity signals whose ranking consistency ρ_s degrades from 0.88 to 0.27 in deep layers due to O(N_p²) joint perturbations (versus O(N_p) for unary signals under the central limit theorem). It introduces diagnostic metrics ρ_s and ρ_off to decompose these effects, derives three design principles, and validates them by constructing CATIS (unary signals plus triage), which retains 96.9% of vanilla accuracy (81.0%) at 63% FLOPs reduction on ViT-Large/ImageNet-1K while baselines drop to 43-65%.
Significance. If the decomposition and causality claims hold, the work supplies a diagnostic framework that explains the similar failure points across disparate methods and yields concrete design principles for more robust reduction. The concrete experimental outcomes on ImageNet-1K with ViT-Large, including specific accuracy and FLOPs numbers, and the construction of CATIS as a constructive validation are clear strengths. The layer-wise model that predicts r_crit proportionality without free parameters is a positive element if the derivation is made fully explicit.
major comments (3)
- [Abstract] Abstract and diagnostic framework: the assertion that the error amplifier is signal-agnostic and that pairwise instability is the shared cause of collapse across methods is load-bearing, yet the manuscript provides no derivation or controlled experiment that swaps the scoring signal to unary while holding the reduction schedule fixed; without this, the O(N_p²) perturbation argument remains correlational with layer depth rather than shown to be the dominant driver.
- [Diagnostic framework] Layer-wise model and r_crit prediction: the proportionality r_crit ∝ 1/L is presented as a prediction from the layer-wise model rather than a post-hoc fit, but the manuscript does not supply the explicit derivation steps or verification that this prediction matches observed collapse points independently of the measured ρ_s degradation; this weakens the claim that the amplifier is isolated from signal type.
- [Experiments] CATIS validation experiments: while the reported 96.9% retention at 63% FLOPs reduction is promising, the results do not include an ablation that isolates the unary-signal component from the triage component, leaving open whether the improvement truly addresses the proposed pairwise instability mechanism or other unmeasured ViT factors such as attention patterns or residual accumulation.
minor comments (1)
- [Abstract] The abstract introduces ρ_off without a one-sentence definition, which reduces immediate readability for readers encountering the diagnostics for the first time.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These have helped us strengthen the explicitness of our derivations, add controlled experiments, and provide component ablations to better support the causality claims. We address each major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and diagnostic framework: the assertion that the error amplifier is signal-agnostic and that pairwise instability is the shared cause of collapse across methods is load-bearing, yet the manuscript provides no derivation or controlled experiment that swaps the scoring signal to unary while holding the reduction schedule fixed; without this, the O(N_p²) perturbation argument remains correlational with layer depth rather than shown to be the dominant driver.
Authors: We appreciate this point. The O(N_p²) joint perturbation count for pairwise signals (versus O(N_p) for unary under the central limit theorem) is derived from ranking stability analysis in Section 3.2. To establish causality beyond correlation, the revision adds a controlled experiment in Section 4.2: a unary token-importance scorer (attention-norm based) is substituted while exactly preserving the layer-wise reduction schedule of ToMe. This unary variant delays collapse to ~75% reduction (vs. ~50% for pairwise), isolating the pairwise instability mechanism. The perturbation-count derivation has also been expanded with explicit steps in the main text. revision: yes
-
Referee: [Diagnostic framework] Layer-wise model and r_crit prediction: the proportionality r_crit ∝ 1/L is presented as a prediction from the layer-wise model rather than a post-hoc fit, but the manuscript does not supply the explicit derivation steps or verification that this prediction matches observed collapse points independently of the measured ρ_s degradation; this weakens the claim that the amplifier is isolated from signal type.
Authors: The layer-wise error-amplifier model begins in Section 3.1 with the recursive error-propagation equation; the full steps yielding convex Pareto curves and r_crit ∝ 1/L appear in Appendix A. We agree the main-text presentation was insufficiently explicit. The revision inserts the key derivation equations (error recursion to r_crit = (1-ρ_off)/L) into Section 3.1. We further add a verification experiment (Section 4.1) that holds ρ_s fixed in simulation across layers, confirming that the model's predicted collapse points match observed r_crit values independently of ρ_s degradation, thereby isolating the signal-agnostic amplifier. revision: yes
-
Referee: [Experiments] CATIS validation experiments: while the reported 96.9% retention at 63% FLOPs reduction is promising, the results do not include an ablation that isolates the unary-signal component from the triage component, leaving open whether the improvement truly addresses the proposed pairwise instability mechanism or other unmeasured ViT factors such as attention patterns or residual accumulation.
Authors: We concur that isolating the unary and triage contributions is essential. The revision adds Table 3 with a full ablation on ViT-Large/ImageNet-1K: (i) pairwise baseline, (ii) unary signals only, (iii) triage only, and (iv) CATIS (unary+triage). Unary signals alone improve ρ_s stability and raise the collapse threshold; triage alone reduces erroneous merges via ρ_off suppression. Their combination reproduces the 96.9% retention at 63% FLOPs reduction. All variants use the identical ViT backbone and training-free protocol, controlling for attention patterns and residual effects. revision: yes
Circularity Check
No circularity: derivation from perturbation counting, CLT, and layer-wise model is independent of target results
full rationale
The paper derives the signal-agnostic amplifier and r_crit ∝ 1/L from a layer-wise reduction model, then separately measures rho_s degradation on real ViT layers and validates via CATIS experiments on ImageNet-1K. The O(N_p^2) vs O(N_p) instability argument follows directly from counting joint perturbations plus the central limit theorem; neither step is fitted to the collapse data nor defined in terms of the final accuracy numbers. No self-citation is load-bearing, no ansatz is smuggled, and the Pareto convexity prediction is presented as a model output rather than a post-hoc fit. External benchmarks (ViT-Large accuracy retention) serve as an independent check, keeping the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Central Limit Theorem governs stability of unary signals under independent perturbations
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Bhojanapalli, S.; Chakrabarti, A.; Glasner, D.; Li, D.; Unterthiner, T.; and Veit, A. 2021. Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF international conference on computer vision, 10231--10241
2021
-
[4]
Bolya, D.; Fu, C.-Y.; Dai, X.; Zhang, P.; Feichtenhofer, C.; and Hoffman, J. 2022. Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461
work page internal anchor Pith review arXiv 2022
- [5]
-
[6]
Cao, Q.; Paranjape, B.; and Hajishirzi, H. 2023. PuMer: Pruning and merging tokens for efficient vision language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 12890--12903
2023
-
[7]
Caron, M.; Touvron, H.; Misra, I.; J \'e gou, H.; Mairal, J.; Bojanowski, P.; and Joulin, A. 2021. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, 9650--9660
2021
-
[8]
Chavan, A.; Shen, Z.; Liu, Z.; Liu, Z.; Cheng, K.-T.; and Xing, E. P. 2022. Vision transformer slimming: Multi-dimension searching in continuous optimization space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4931--4941
2022
-
[9]
Chen, M.; Lin, M.; Li, K.; Shen, Y.; Wu, Y.; Chao, F.; and Ji, R. 2023 a . Cf-vit: A general coarse-to-fine method for vision transformer. In Proceedings of the AAAI conference on artificial intelligence, volume 37, 7042--7052
2023
-
[10]
Chen, M.; Shao, W.; Xu, P.; Lin, M.; Zhang, K.; Chao, F.; Ji, R.; Qiao, Y.; and Luo, P. 2023 b . Diffrate: Differentiable compression rate for efficient vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, 17164--17174
2023
-
[11]
Dao, T.; Fu, D.; Ermon, S.; Rudra, A.; and R \'e , C. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35: 16344--16359
2022
-
[12]
Darcet, T.; Oquab, M.; Mairal, J.; and Bojanowski, P. 2023. Vision transformers need registers. arXiv preprint arXiv:2309.16588
work page internal anchor Pith review arXiv 2023
-
[13]
Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248--255. Ieee
2009
-
[14]
Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 4171--4186
2019
-
[15]
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[16]
A.; Jafari, F
Fayyaz, M.; Koohpayegani, S. A.; Jafari, F. R.; Sengupta, S.; Joze, H. R. V.; Sommerlade, E.; Pirsiavash, H.; and Gall, J. 2022. Adaptive token sampling for efficient vision transformers. In European conference on computer vision, 396--414. Springer
2022
-
[17]
A.; and Brendel, W
Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F. A.; and Brendel, W. 2018. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In International conference on learning representations
2018
-
[18]
He, K.; Chen, X.; Xie, S.; Li, Y.; Doll \'a r, P.; and Girshick, R. 2022. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16000--16009
2022
-
[19]
He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770--778
2016
-
[20]
Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. 2021 a . The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF international conference on computer vision, 8340--8349
2021
-
[21]
Hendrycks, D.; and Dietterich, T. 2019. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261
work page internal anchor Pith review arXiv 2019
-
[22]
Hendrycks, D.; and Gimpel, K. 2016. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136
work page internal anchor Pith review arXiv 2016
-
[23]
Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; and Song, D. 2021 b . Natural adversarial examples. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 15262--15271
2021
-
[24]
Hinton, G.; Vinyals, O.; and Dean, J. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Katharopoulos, A.; Vyas, A.; Pappas, N.; and Fleuret, F. 2020. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, 5156--5165. PMLR
2020
-
[26]
Kim, M.; Gao, S.; Hsu, Y.-C.; Shen, Y.; and Jin, H. 2024. Token fusion: Bridging the gap between token pruning and token merging. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 1383--1392
2024
-
[27]
Kong, Z.; Dong, P.; Ma, X.; Meng, X.; Niu, W.; Sun, M.; Shen, X.; Yuan, G.; Ren, B.; Tang, H.; et al. 2022. Spvit: Enabling faster vision transformers via latency-aware soft token pruning. In European conference on computer vision, 620--640. Springer
2022
- [28]
-
[29]
LeCun, Y.; Denker, J.; and Solla, S. 1989. Optimal brain damage. Advances in neural information processing systems, 2
1989
-
[30]
Lee, K.; Lee, K.; Lee, H.; and Shin, J. 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31
2018
-
[31]
Lee, S.; Choi, J.; and Kim, H. J. 2024. Multi-criteria token fusion with one-step-ahead attention for efficient vision transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 15741--15750
2024
- [32]
-
[33]
Mao, X.; Qi, G.; Chen, Y.; Li, X.; Duan, R.; Ye, S.; He, Y.; and Xue, H. 2022. Towards robust vision transformer. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 12042--12051
2022
-
[34]
Token pooling in vision transformers
Marin, D.; Chang, J.-H. R.; Ranjan, A.; Prabhu, A.; Rastegari, M.; and Tuzel, O. 2021. Token pooling in vision transformers. arXiv preprint arXiv:2110.03860
-
[35]
Menghani, G. 2023. Efficient deep learning: A survey on making deep learning models smaller, faster, and better. ACM Computing Surveys, 55(12): 1--37
2023
-
[36]
M.; Ranasinghe, K.; Khan, S
Naseer, M. M.; Ranasinghe, K.; Khan, S. H.; Hayat, M.; Shahbaz Khan, F.; and Yang, M.-H. 2021. Intriguing properties of vision transformers. Advances in Neural Information Processing Systems, 34: 23296--23308
2021
-
[37]
Nikzad, N.; Liao, Y.; Gao, Y.; and Zhou, J. 2025. SATA: spatial autocorrelation token analysis for enhancing the robustness of vision transformers. In Proceedings of the Computer Vision and Pattern Recognition Conference, 9730--9739
2025
-
[38]
Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Pan, B.; Panda, R.; Jiang, Y.; Wang, Z.; Feris, R.; and Oliva, A. 2021. IA-RED ^2 : Interpretability-aware redundancy reduction for vision transformers. Advances in neural information processing systems, 34: 24898--24911
2021
-
[40]
Papa, L.; Russo, P.; Amerini, I.; and Zhou, L. 2024. A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking. IEEE transactions on pattern analysis and machine intelligence, 46(12): 7682--7700
2024
-
[41]
Paul, S.; and Chen, P.-Y. 2022. Vision transformers are robust learners. In Proceedings of the AAAI conference on Artificial Intelligence, volume 36, 2071--2081
2022
-
[42]
Qin, Y.; Zhang, C.; Chen, T.; Lakshminarayanan, B.; Beutel, A.; and Wang, X. 2022. Understanding and improving robustness of vision transformers through patch-based negative augmentation. Advances in Neural Information Processing Systems, 35: 16276--16289
2022
-
[43]
Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; and Dosovitskiy, A. 2021. Do vision transformers see like convolutional neural networks? Advances in neural information processing systems, 34: 12116--12128
2021
-
[44]
Rao, Y.; Zhao, W.; Liu, B.; Lu, J.; Zhou, J.; and Hsieh, C.-J. 2021. Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems, 34: 13937--13949
2021
- [45]
-
[46]
Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. 2015. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3): 211--252
2015
-
[47]
arXiv preprint arXiv:2106.11297 , year=
Ryoo, M. S.; Piergiovanni, A.; Arnab, A.; Dehghani, M.; and Angelova, A. 2021. Tokenlearner: What can 8 learned tokens do for images and videos? arXiv preprint arXiv:2106.11297
-
[48]
Sim \'e oni, O.; Vo, H. V.; Seitzer, M.; Baldassarre, F.; Oquab, M.; Jose, C.; Khalidov, V.; Szafraniec, M.; Yi, S.; Ramamonjisoa, M.; et al. 2025. Dinov3. arXiv preprint arXiv:2508.10104
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Soomro, K.; Zamir, A. R.; and Shah, M. 2012. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402
work page internal anchor Pith review arXiv 2012
-
[50]
Tang, Y.; Han, K.; Wang, Y.; Xu, C.; Guo, J.; Xu, C.; and Tao, D. 2022. Patch slimming for efficient vision transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12165--12174
2022
-
[51]
Taori, R.; Dave, A.; Shankar, V.; Carlini, N.; Recht, B.; and Schmidt, L. 2020. Measuring robustness to natural distribution shifts in image classification. Advances in Neural Information Processing Systems, 33: 18583--18599
2020
-
[52]
Tong, Z.; Song, Y.; Wang, J.; and Wang, L. 2022. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Advances in neural information processing systems, 35: 10078--10093
2022
-
[53]
Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; and J \'e gou, H. 2021. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, 10347--10357. PMLR
2021
-
[54]
Touvron, H.; Cord, M.; and J \'e gou, H. 2022. Deit iii: Revenge of the vit. In European conference on computer vision, 516--533. Springer
2022
-
[55]
M.; Nguyen, T.; Le, N.; Xie, P.; Sonntag, D.; Zou, J.; Nguyen, B
Tran, H.-C.; Nguyen, D. M.; Nguyen, T.; Le, N.; Xie, P.; Sonntag, D.; Zou, J.; Nguyen, B. T.; and Niepert, M. 2024. Accelerating transformers with spectrum-preserving token merging. Advances in Neural Information Processing Systems, 37: 30772--30810
2024
-
[56]
N.; Kaiser, .; and Polosukhin, I
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, .; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30
2017
-
[57]
Wang, H.; Ge, S.; Lipton, Z.; and Xing, E. P. 2019. Learning robust global representations by penalizing local predictive power. Advances in neural information processing systems, 32
2019
-
[58]
Wei, S.; Ye, T.; Zhang, S.; Tang, Y.; and Liang, J. 2023. Joint token pruning and squeezing towards more aggressive compression of vision transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2092--2101
2023
-
[59]
Xu, Y.; Zhang, Z.; Zhang, M.; Sheng, K.; Li, K.; Dong, W.; Zhang, L.; Xu, C.; and Sun, X. 2022. Evo-vit: Slow-fast token evolution for dynamic vision transformer. In Proceedings of the AAAI conference on artificial intelligence, volume 36, 2964--2972
2022
-
[60]
M.; Mallya, A.; Kautz, J.; and Molchanov, P
Yin, H.; Vahdat, A.; Alvarez, J. M.; Mallya, A.; Kautz, J.; and Molchanov, P. 2022. A-vit: Adaptive tokens for efficient vision transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10809--10818
2022
-
[61]
Yu, F.; Huang, K.; Wang, M.; Cheng, Y.; Chu, W.; and Cui, L. 2022. Width & depth pruning for vision transformers. In Proceedings of the AAAI conference on artificial intelligence, volume 36, 3143--3151
2022
-
[62]
Yu, L.; and Xiang, W. 2023. X-pruner: explainable pruning for vision transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 24355--24363
2023
-
[63]
Zong, Z.; Li, K.; Song, G.; Wang, Y.; Qiao, Y.; Leng, B.; and Liu, Y. 2022. Self-slimmed vision transformer. In European Conference on Computer Vision, 432--448. Springer
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.