Recognition: unknown
TriTS: Time Series Forecasting from a Multimodal Perspective
Pith reviewed 2026-05-10 07:57 UTC · model grok-4.3
The pith
TriTS improves long-term time series forecasting by fusing projections from time, frequency, and visual spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TriTS projects 1D time series into orthogonal time, frequency, and 2D-vision spaces. A Period-Aware Reshaping strategy and Visual Mamba model cross-period dependencies as global visual textures with linear complexity. The Multi-Resolution Wavelet Mixing module decouples non-stationary signals into trend and noise components. A streaming linear branch anchors the time domain. Dynamic fusion of the three complementary representations adapts to diverse data contexts and delivers superior forecasting performance.
What carries the argument
TriTS cross-modal disentanglement framework projecting into time, frequency, and 2D-vision spaces with Period-Aware Reshaping, Multi-Resolution Wavelet Mixing, and Visual Mamba for efficient fusion.
Load-bearing premise
The assumption that orthogonal projections into time, frequency, and 2D-vision spaces with the added reshaping and mixing techniques can disentangle highly entangled temporal dynamics without introducing artifacts or losing critical information.
What would settle it
An experiment where TriTS is applied to a dataset with highly entangled non-stationary dynamics and shows no improvement in forecast accuracy over a standard 1D model would falsify the core benefit of the multimodal approach.
Figures

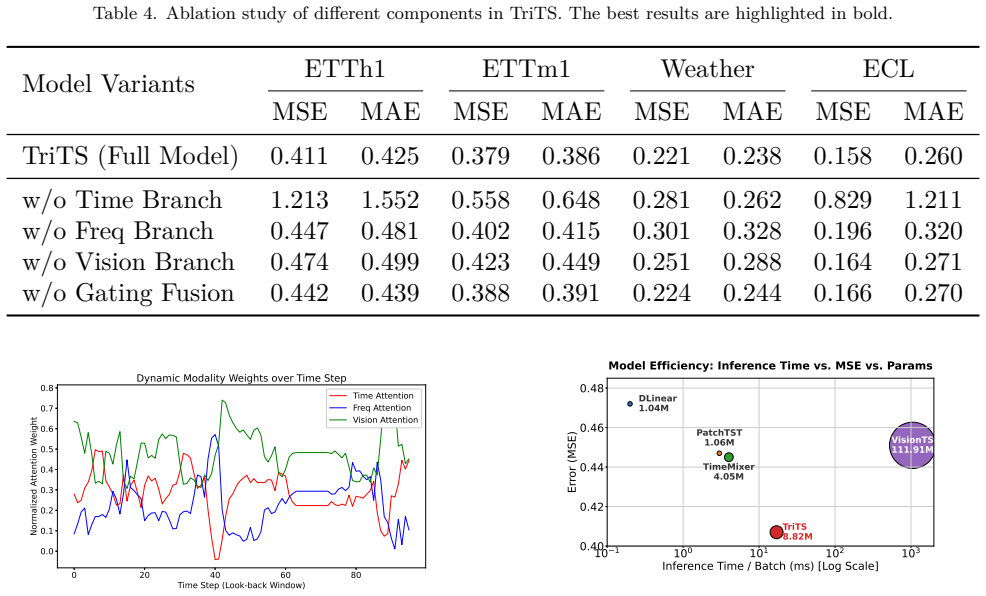

read the original abstract
Time series forecasting plays a pivotal role in critical sectors such as finance, energy, transportation, and meteorology. However, Long-term Time Series Forecasting (LTSF) remains a significant challenge because real-world signals contain highly entangled temporal dynamics that are difficult to fully capture from a purely 1D perspective. To break this representation bottleneck, we propose TriTS, a novel cross-modal disentanglement framework that projects 1D time series into orthogonal time, frequency, and 2D-vision spaces.To seamlessly bridge the 1D-to-2D modality gap without the prohibitive $O(N^2)$ computational overhead of Vision Transformers (ViTs), we introduce a Period-Aware Reshaping strategy and incorporate Visual Mamba (Vim). This approach efficiently models cross-period dependencies as global visual textures while maintaining linear computational complexity. Complementing this, we design a Multi-Resolution Wavelet Mixing (MR-WM) module for the frequency modality, which explicitly decouples non-stationary signals into trend and noise components to achieve fine-grained time-frequency localization. Finally, a streaming linear branch is retained in the time domain to anchor numerical stability. By dynamically fusing these three complementary representations, TriTS effectively adapts to diverse data contexts. Extensive experiments across multiple benchmark datasets demonstrate that TriTS achieves state-of-the-art (SOTA) performance, fundamentally outperforming existing vision-based forecasters by drastically reducing both parameter count and inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TriTS, a cross-modal disentanglement framework for long-term time series forecasting (LTSF). It projects 1D time series into orthogonal time, frequency, and 2D-vision spaces; the vision branch uses Period-Aware Reshaping plus Visual Mamba (Vim) to model cross-period dependencies as global textures with linear complexity, the frequency branch uses a Multi-Resolution Wavelet Mixing (MR-WM) module to decouple non-stationary signals into trend and noise, and a streaming linear branch anchors the time domain. These representations are dynamically fused to adapt to diverse contexts, with the abstract claiming SOTA performance and drastic reductions in parameter count and inference latency relative to prior vision-based forecasters.
Significance. If the performance and efficiency claims hold, the work could meaningfully advance LTSF by addressing representation bottlenecks through complementary multimodal projections while mitigating the quadratic cost of ViTs. The Period-Aware Reshaping + Vim combination and the MR-WM module represent concrete engineering contributions for handling multi-scale and non-stationary dynamics; explicit credit is due for targeting linear complexity and for retaining a numerical-stability anchor in the time domain.
major comments (3)
- [Abstract] Abstract: the assertion that 'TriTS achieves state-of-the-art (SOTA) performance' and 'fundamentally outperforming existing vision-based forecasters by drastically reducing both parameter count and inference latency' is unsupported by any quantitative metrics, ablation tables, error bars, dataset specifications, or baseline comparisons. This evidentiary gap is load-bearing for the central claim.
- [Method (Period-Aware Reshaping)] Method description of Period-Aware Reshaping: the strategy is presented as converting 1D series into 2D grids to exploit visual textures, yet no analysis or experiment addresses whether imprecise period detection or multi-scale/non-stationary signals introduce spurious cross-period correlations or distort sequential dependencies. This directly affects the claim that the three projections yield artifact-free complementary representations.
- [Method (MR-WM)] Method description of MR-WM: the module is said to 'explicitly decouple non-stationary signals into trend and noise components to achieve fine-grained time-frequency localization,' but the manuscript supplies neither the precise wavelet formulation nor any verification that separation is complete and alias-free. Failure here would invalidate the premise that fusion receives truly complementary information.
minor comments (2)
- [Abstract] The abstract refers to 'Extensive experiments across multiple benchmark datasets' without naming the datasets or providing even summary statistics; this should be expanded for clarity.
- [Abstract] The abbreviation 'Vim' for Visual Mamba is introduced without an explicit definition or citation on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help improve the clarity and rigor of our work. We address each major comment point by point below, proposing specific revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'TriTS achieves state-of-the-art (SOTA) performance' and 'fundamentally outperforming existing vision-based forecasters by drastically reducing both parameter count and inference latency' is unsupported by any quantitative metrics, ablation tables, error bars, dataset specifications, or baseline comparisons. This evidentiary gap is load-bearing for the central claim.
Authors: We agree that the abstract would benefit from greater specificity to make the central claims self-contained. Although the full manuscript (Section 4) provides extensive quantitative results, ablation studies, error bars, dataset details, and baseline comparisons demonstrating SOTA performance and efficiency gains, we will revise the abstract to incorporate key numerical highlights (e.g., average MSE/MAE improvements and reductions in parameters/latency) with direct references to the relevant tables and figures. revision: yes
-
Referee: [Method (Period-Aware Reshaping)] Method description of Period-Aware Reshaping: the strategy is presented as converting 1D series into 2D grids to exploit visual textures, yet no analysis or experiment addresses whether imprecise period detection or multi-scale/non-stationary signals introduce spurious cross-period correlations or distort sequential dependencies. This directly affects the claim that the three projections yield artifact-free complementary representations.
Authors: This is a fair point on potential robustness issues. The current manuscript does not contain a dedicated sensitivity analysis for period detection inaccuracies or multi-scale effects. In the revision, we will add an ablation study and discussion section that evaluates the impact of perturbed period estimates on cross-period correlations, sequential dependency preservation, and overall forecasting performance across non-stationary datasets, thereby supporting the complementarity of the projections. revision: yes
-
Referee: [Method (MR-WM)] Method description of MR-WM: the module is said to 'explicitly decouple non-stationary signals into trend and noise components to achieve fine-grained time-frequency localization,' but the manuscript supplies neither the precise wavelet formulation nor any verification that separation is complete and alias-free. Failure here would invalidate the premise that fusion receives truly complementary information.
Authors: We acknowledge the need for greater technical detail here. While the manuscript describes the high-level intent of MR-WM, it does not provide the full mathematical formulation or empirical verification of decoupling quality. We will revise the method section to include the exact wavelet equations, multi-resolution mixing details, and add verification experiments (e.g., reconstruction error and aliasing metrics on synthetic non-stationary signals) to confirm that the components are complementary and alias-free. revision: yes
Circularity Check
No circularity: TriTS is a constructive multimodal architecture validated empirically
full rationale
The paper introduces TriTS as a novel framework that projects 1D series into time/frequency/2D-vision spaces using Period-Aware Reshaping, Visual Mamba, MR-WM wavelet mixing, and dynamic fusion. No equations or steps reduce by construction to fitted inputs, self-citations, or prior ansatzes. Claims rest on new modules and benchmark experiments rather than renaming known results or importing uniqueness from self-citations. This matches the default non-circular case for an architectural proposal.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Period-Aware Reshaping strategy
no independent evidence
-
Multi-Resolution Wavelet Mixing (MR-WM) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Research on the stock price prediction model based on large-scale transactions
Xiang Ao. Research on the stock price prediction model based on large-scale transactions. In Proceed- ings of the 2025 8th International Conference on Com- puter Information Science and Artificial Intelligence, page 392–396, New York, NY, USA, 2025. Association for Computing Machinery. 1
2025
-
[2]
VisionTS: Visual masked autoencoders are free-lunch zero-shot time series forecasters, 2025
Mouxiang Chen, Lefei Shen, Zhuo Li, Xiaoyun Joy Wang, Jianling Sun, and Chenghao Liu. VisionTS: Visual masked autoencoders are free-lunch zero-shot time series forecasters, 2025. 1, 3, 5, 6
2025
-
[3]
An image is worth 16x16 words: Trans- formers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Trans- formers for image recognition at scale. In International Conference on Learning Representations, 2021. 2, 3, 5
2021
-
[4]
Forecastable component analysis
Georg Goerg. Forecastable component analysis. In Proceedings of the 30th International Conference on Machine Learning, pages 64–72, Atlanta, Georgia, USA, 2013. PMLR. 6
2013
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time se- quence modeling with selective state spaces. ArXiv, abs/2312.00752, 2023. 1, 3
work page Pith review arXiv 2023
-
[6]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 770–778, 2016. 2
2016
-
[7]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021. 3
2021
-
[8]
Long short- term memory
Sepp Hochreiter and Jürgen Schmidhuber. Long short- term memory. Neural Comput., 9(8):1735–1780, 1997. 1, 2
1997
-
[9]
Fdnet: High-frequency disentanglement network with information-theoretic guidance for mul- tivariate time series forecasting
Ao Hu, Liangjian Wen, Jiang Duan, Yong Dai, Dongkai Wang, Shudong Huang, Jun Wang, and Zenglin Xu. Fdnet: High-frequency disentanglement network with information-theoretic guidance for mul- tivariate time series forecasting. Pattern Recognition, 173:112810, 2026. 2, 6
2026
-
[10]
A multiview spatial-temporal adaptive transformer-gru framework for traffic flow prediction
Yang Hu, Shaobo Li, Dawen Xia, Wenyong Zhang, Panliang Yuan, Fengbin Wu, and Huaqing Li. A multiview spatial-temporal adaptive transformer-gru framework for traffic flow prediction. IEEE Internet of Things Journal, 12(6):7114–7132, 2025. 1
2025
-
[11]
Modeling long- and short-term tempo- ral patterns with deep neural networks
Guokun Lai, Wei-Cheng Chang, Yiming Yang, and Hanxiao Liu. Modeling long- and short-term tempo- ral patterns with deep neural networks. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, page 95–104, New York, NY, USA, 2018. Association for Comput- ing Machinery. 6
2018
-
[12]
itrans- former: Inverted transformers are effective for time series forecasting, 2024
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itrans- former: Inverted transformers are effective for time series forecasting, 2024. 2, 6
2024
-
[13]
Wpmixer: efficient multi-resolution mixing for long-term time series forecasting
Md Mahmuddun Nabi Murad, Mehmet Aktukmak, and Yasin Yilmaz. Wpmixer: efficient multi-resolution mixing for long-term time series forecasting. In Pro- ceedings of the Thirty-Ninth AAAI Conference on Ar- tificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in...
2025
-
[14]
Logtrans: Provid- ing efficient local-global fusion with transformer and cnn parallel network for biomedical image segmenta- tion
Xingqing Nie, Xiaogen Zhou, Zhiqiang Li, Luoyan Wang, Xingtao Lin, and Tong Tong. Logtrans: Provid- ing efficient local-global fusion with transformer and cnn parallel network for biomedical image segmenta- tion. In 2022 IEEE 24th Int Conf on High Performance Computing, pages 769–776, 2022. 2
2022
-
[15]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers, 2023. 1, 2, 6
2023
-
[16]
Real-time deep anomaly detection framework for multivariate time-series data in indus- trial iot
Hussain Nizam, Samra Zafar, Zefeng Lv, Fan Wang, and Xiaopeng Hu. Real-time deep anomaly detection framework for multivariate time-series data in indus- trial iot. IEEE Sensors Journal, 22(23):22836–22849,
-
[17]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In 2016 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 779–788, 2016. 2
2016
-
[18]
Rumelhart, Geoffrey E
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back- propagating errors. Nature, 323(6088):533–536, 1986. 1, 2
1986
-
[19]
Vi- sionts++: Cross-modal time series foundation model with continual pre-trained vision backbones, 2025
Lefei Shen, Mouxiang Chen, Xu Liu, Han Fu, Xiaoxue Ren, Jianling Sun, Zhuo Li, and Chenghao Liu. Vi- sionts++: Cross-modal time series foundation model with continual pre-trained vision backbones, 2025. 1, 3, 6
2025
-
[20]
Stitsyuk and J
A. Stitsyuk and J. Choi. xpatch: Dual-stream time series forecasting with exponential seasonal-trend de- composition. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 20601–20609, 2025. 2, 3
2025
-
[21]
Short-term multivariate load fore- casting for integrated energy systems based on bigru- am and multi-task learning
Qianxiang Sun, Hongyuan Ma, Guangdi Li, Ziwen Li, and Yining Wang. Short-term multivariate load fore- casting for integrated energy systems based on bigru- am and multi-task learning. In 2022 First International Conference on Cyber-Energy Systems and Intelligent Energy (ICCSIE), pages 1–6, 2023. 1
2022
-
[22]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Sys- tems. Curran Associates, Inc., 2017. 1
2017
-
[23]
Timemixer: Decomposable multiscale mixing for time series forecasting
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Zhang, and JUN ZHOU. Timemixer: Decomposable multiscale mixing for time series forecasting. In International Conference on Representation Learning, pages 38626–38652, 2024. 2, 6
2024
-
[24]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting, 2022
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting, 2022. 1, 2, 6
2022
-
[25]
Timesnet: Temporal 2d-variation modeling for general time series analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jian- min Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis. In The Eleventh International Conference on Learning Representations, 2023. 3
2023
-
[26]
Interpretable weather forecasting for worldwide stations with a unified deep model
Haixu Wu, Hang Zhou, Mingsheng Long, and Jianmin Wang. Interpretable weather forecasting for worldwide stations with a unified deep model. Nature Machine Intelligence, 5(6):602–611, 2023. 1
2023
-
[27]
Filternet: Harnessing fre- quency filters for time series forecasting, 2024
Kun Yi, Jingru Fei, Qi Zhang, Hui He, Shufeng Hao, Defu Lian, and Wei Fan. Filternet: Harnessing fre- quency filters for time series forecasting, 2024. 1, 2
2024
-
[28]
Are transformers effective for time series forecasting?,
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting?,
-
[29]
In- former: Beyond efficient transformer for long sequence time-series forecasting, 2021
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. In- former: Beyond efficient transformer for long sequence time-series forecasting, 2021. 5
2021
-
[30]
Fedformer: Frequency en- hanced decomposed transformer for long-term series forecasting, 2022
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. Fedformer: Frequency en- hanced decomposed transformer for long-term series forecasting, 2022. 1, 2
2022
-
[31]
Vision mamba: efficient visual representation learning with bidirectional state space model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: efficient visual representation learning with bidirectional state space model. In Proceedings of the 41st International Conference on Machine Learning. JMLR.org, 2024. 2, 3, 5
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.