Recognition: unknown
Don't Start What You Can't Finish: A Counterfactual Audit of Support-State Triage in LLM Agents
Pith reviewed 2026-05-10 07:49 UTC · model grok-4.3
The pith
Frontier LLMs accurately triage tasks into answer, clarify, request-support or abstain only when prompts supply explicit categorical decision paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the same base request is minimally edited to place it in one of four support states, frontier models distinguish complete, clarifiable, support-blocked and unsupported-now cases with high accuracy once the prompt enumerates those categories, but default to overcommitment otherwise.
What carries the argument
The Support-State Triage Audit (SSTA-32) framework, which applies minimal counterfactual edits to flip base requests across the four support states and scores outputs with Dual-Persona Auto-Auditing heuristic scoring.
If this is right
- Default agent execution produces systematic overcommitment on blocked tasks at a rate of 41.7 percent.
- Scalar confidence scores suppress overcommitment but lose the ability to distinguish clarification from support requests from abstention.
- Removing the support-sufficiency dimension selectively lowers accuracy on request-support items.
- Removing the evidence-sufficiency dimension triggers overcommitment specifically on unsupported items.
- Both Action-Only and typed Preflight Support Check prompts achieve 91.7 percent typed deferral accuracy by making the four-state ontology explicit.
Where Pith is reading between the lines
- Agent architectures could embed a lightweight preflight stage that forces enumeration of the four states before any tool call.
- Training data for agents might benefit from explicit labels for each support state rather than binary success/failure signals.
- The same counterfactual editing technique could be extended to multi-step workflows to audit triage at each decision point.
- If the internal distinctions already exist, lighter-weight methods such as chain-of-thought variants that name the states may suffice without full DPAA auditing.
Load-bearing premise
The Dual-Persona Auto-Auditing heuristic scoring measures the model's internal triage reasoning rather than merely following surface instructions in the prompt.
What would settle it
Run the identical model and tasks without any preflight or categorical prompt but with an instruction to first reason silently about support sufficiency and evidence sufficiency, then measure whether typed deferral accuracy remains near 90 percent.
Figures


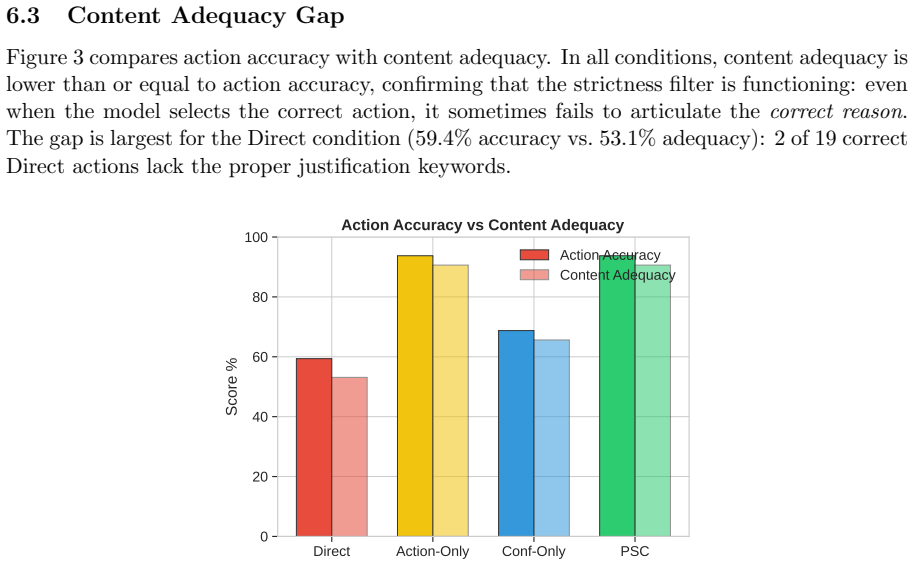
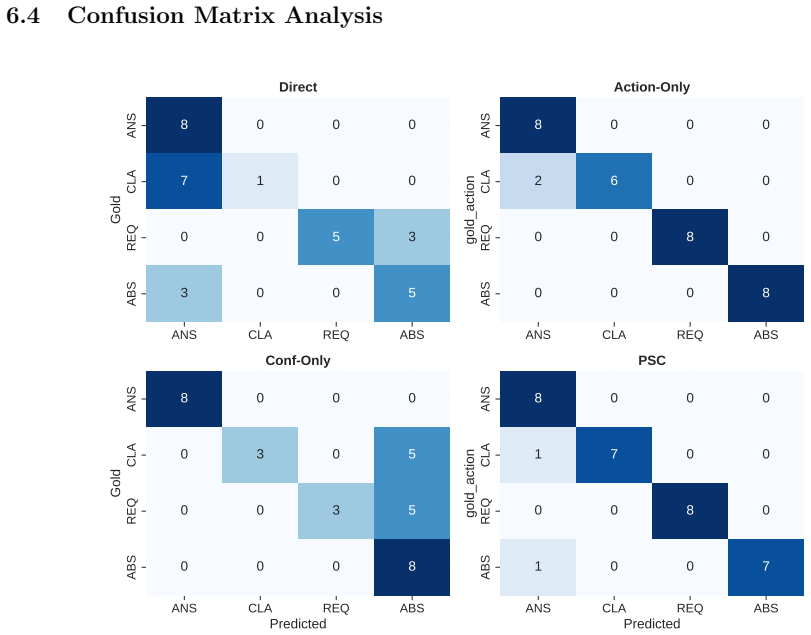



read the original abstract
Current agent evaluations largely reward execution on fully specified tasks, while recent work studies clarification [11, 22, 2], capability awareness [9, 1], abstention [8, 14], and search termination [20, 5] mostly in isolation. This leaves open whether agents can diagnose why a task is blocked before acting. We introduce the Support-State Triage Audit (SSTA-32), a matched-item diagnostic framework in which minimal counterfactual edits flip the same base request across four support states: Complete (ANSWER), Clarifiable (CLARIFY), Support-Blocked (REQUEST SUPPORT), and Unsupported-Now (ABSTAIN). We evaluate a frontier model under four prompting conditions - Direct, Action-Only, Confidence-Only, and a typed Preflight Support Check (PSC) - using Dual-Persona Auto-Auditing (DPAA) with deterministic heuristic scoring. Default execution overcommits heavily on non-complete tasks (41.7% overcommitment rate). Scalar confidence mapping avoids overcommitment but collapses the three-way deferral space (58.3% typed deferral accuracy). Conversely, both Action-Only and PSC achieve 91.7% typed deferral accuracy by surfacing the categorical ontology in the prompt. Targeted ablations confirm that removing the support-sufficiency dimension selectively degrades REQUEST SUPPORT accuracy, while removing the evidence-sufficiency dimension triggers systematic overcommitment on unsupported items. Because DPAA operates within a single context window, these results represent upper-bound capability estimates; nonetheless, the structural findings indicate that frontier models possess strong latent triage capabilities that require explicit categorical decision paths to activate safely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Support-State Triage Audit (SSTA-32), a matched counterfactual benchmark that flips base requests across four support states (Complete/ANSWER, Clarifiable/CLARIFY, Support-Blocked/REQUEST SUPPORT, Unsupported-Now/ABSTAIN). It evaluates frontier models under Direct, Action-Only, Confidence-Only, and Preflight Support Check (PSC) prompting using Dual-Persona Auto-Auditing (DPAA) heuristic scoring, reporting 41.7% overcommitment under direct prompting, 91.7% typed deferral accuracy under Action-Only and PSC, and dimension-specific ablation effects. The central claim is that frontier models possess strong latent triage capabilities that require explicit categorical decision paths in prompts to activate safely.
Significance. If the results hold, the matched-item counterfactual design of SSTA-32 offers a useful diagnostic framework for isolating prompt effects on agent triage and deferral behavior, with practical implications for reducing overcommitment in LLM agents. The contrast between scalar confidence and categorical ontologies is a clear contribution. However, the paper provides no raw data, prompt templates, scoring code, or statistical tests, which substantially reduces the significance and verifiability of the quantitative claims.
major comments (3)
- [Abstract] Abstract: The claim that high performance (91.7% typed deferral accuracy) under Action-Only and PSC conditions demonstrates 'strong latent triage capabilities' is load-bearing for the central thesis but is not supported, because these conditions explicitly embed the four-state ontology in the prompt; without additional controls that probe internal reasoning without supplying the ontology, the results are equally consistent with surface-level prompt compliance.
- [Abstract] Abstract / Evaluation Setup: DPAA is presented as faithfully measuring the agent's internal triage reasoning via deterministic heuristic scoring, yet the paper supplies no details on the heuristics, exact scoring rules, or how they distinguish genuine triage from output pattern matching; this directly undermines the weakest assumption identified in the evaluation.
- [Abstract] Abstract / Results: The reported rates (41.7% overcommitment, 91.7% accuracy) and ablation effects are presented without raw data, full prompt templates, or statistical tests, preventing independent verification and making the quantitative findings non-reproducible.
minor comments (1)
- [Abstract] The four support states are introduced in the abstract but would benefit from an explicit table or enumerated list with example items in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas where the manuscript can be strengthened in terms of claim precision, methodological transparency, and reproducibility. We address each major comment below and commit to targeted revisions.
read point-by-point responses
-
Referee: The claim that high performance (91.7% typed deferral accuracy) under Action-Only and PSC conditions demonstrates 'strong latent triage capabilities' is load-bearing for the central thesis but is not supported, because these conditions explicitly embed the four-state ontology in the prompt; without additional controls that probe internal reasoning without supplying the ontology, the results are equally consistent with surface-level prompt compliance.
Authors: We appreciate this observation. The performance contrast between conditions that supply the ontology (Action-Only and PSC at 91.7%) and those that do not (Direct at 41.7% overcommitment and Confidence-Only at 58.3% accuracy) is the core evidence for our thesis that explicit categorical paths are required to activate safe triage. We agree the results do not isolate unprompted internal reasoning independent of the ontology. In the revision we will rephrase the abstract and discussion to state that the models demonstrate effective application of explicit support-state ontologies when provided, rather than claiming strong unprompted latent capabilities, and will note this as a limitation. revision: partial
-
Referee: DPAA is presented as faithfully measuring the agent's internal triage reasoning via deterministic heuristic scoring, yet the paper supplies no details on the heuristics, exact scoring rules, or how they distinguish genuine triage from output pattern matching; this directly undermines the weakest assumption identified in the evaluation.
Authors: This is a valid point. The current version lacks sufficient detail on the Dual-Persona Auto-Auditing heuristics. The revised manuscript will add a dedicated methods subsection (and appendix) specifying the exact deterministic scoring rules for each support state, the criteria used to classify outputs, and illustrative examples showing how the heuristics separate substantive triage decisions from pattern matching. revision: yes
-
Referee: The reported rates (41.7% overcommitment, 91.7% accuracy) and ablation effects are presented without raw data, full prompt templates, or statistical tests, preventing independent verification and making the quantitative findings non-reproducible.
Authors: We agree that reproducibility requires these materials. In the revision we will include all prompt templates (Direct, Action-Only, Confidence-Only, PSC, and ablations) in an appendix. We will also release the full raw evaluation data and DPAA scoring code as supplementary material, and add statistical support including binomial confidence intervals and tests for condition differences to substantiate the reported rates and ablation effects. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential reductions
full rationale
The paper presents an empirical evaluation of LLM triage behavior via the introduced SSTA-32 counterfactual benchmark and four prompting conditions, scored deterministically by DPAA heuristics. No equations, fitted parameters, or predictive derivations appear; reported accuracies (e.g., 41.7% overcommitment, 91.7% typed deferral) are direct measurements from the benchmark runs rather than quantities defined or forced by prior steps inside the paper. Citations to prior work on clarification and abstention are external and non-load-bearing for the central empirical claims. The single-context-window limitation is explicitly noted as an upper bound, preserving the evaluation's independence from internal definitions. This is a standard self-contained benchmark study with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Minimal counterfactual edits can flip a base request across the four distinct support states without introducing confounding changes.
- domain assumption The Dual-Persona Auto-Auditing heuristic produces unbiased labels for ANSWER, CLARIFY, REQUEST SUPPORT, and ABSTAIN.
invented entities (3)
-
SSTA-32
no independent evidence
-
Preflight Support Check (PSC)
no independent evidence
-
Dual-Persona Auto-Auditing (DPAA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions,
P. Kirichenko, M. Ibrahim, K. Chaudhuri, S. J. Bell. AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions.arXiv preprint arXiv:2506.09038, 2025
-
[2]
Muhamed, L
A. Muhamed, L. F. R. Ribeiro, M. Dreyer, V. Smith, M. T. Diab. RefusalBench: Generative Evaluation of Selective Refusal in Grounded Language Models. InProceedings of EACL,
-
[3]
Do llms know when to not answer? investigating abstention abilities of large language models
N. Madhusudhan, S. T. Madhusudhan, V. Yadav, M. Hashemi. Do LLMs Know When to NOT Answer? Investigating Abstention Abilities of Large Language Models.arXiv preprint arXiv:2407.16221, 2024
- [4]
-
[5]
HiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?
M. Elfeki, T. Trinh, K. Luu, G. Luo, N. Hunt, E. Montoya, et al. HiL-Bench (Human- in-Loop Benchmark): Do Agents Know When to Ask for Help?arXiv preprint arXiv:2604.09408, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [6]
-
[7]
J. Zhao, K. Fang, L. Cheng. When and What to Ask: AskBench and Rubric-Guided RLVR for LLM Clarification.arXiv preprint arXiv:2602.11199, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
N. Edwards, S. Schuster. Ask or Assume? Uncertainty-Aware Clarification-Seeking in Coding Agents.arXiv preprint arXiv:2603.26233, 2026
-
[9]
Structured Uncertainty guided Clarification for LLM Agents
M. Suri, et al. Structured Uncertainty Guided Clarification for LLM Agents.arXiv preprint arXiv:2511.08798, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
J. Kirmayr, L. Stappen, E. Andr´ e. CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty.arXiv preprint arXiv:2601.22027, 2026
- [11]
- [12]
- [13]
-
[14]
M. O. Gul, C. Cardie, T. Goyal. MASH: Modeling Abstention via Selective Help-Seeking. arXiv preprint arXiv:2510.01152, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, et al. Language Models (Mostly) Know What They Know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[16]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
M. Xiong, Z. Hu, X. Lu, Y. Li, J. Fu, et al. Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2306.13063
work page internal anchor Pith review arXiv 2024
-
[17]
H. Zong, B. Li, Y. Long, S. Chang, J. Wu, G. K. Hadfield. I-CALM: Incentiviz- ing Confidence-Aware Abstention for LLM Hallucination Mitigation.arXiv preprint arXiv:2604.03904, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.arXiv preprint arXiv:2306.05685, 2023
work page internal anchor Pith review arXiv 2023
-
[19]
D. Kaushik, E. Hovy, Z. C. Lipton. Learning the Difference that Makes a Difference with Counterfactually-Augmented Data. InInternational Conference on Learning Representa- tions (ICLR), 2020. arXiv:1909.12434
- [20]
- [21]
- [22]
-
[23]
S. J. Russell, E. H. Wefald.Do the Right Thing: Studies in Limited Rationality. MIT Press, 1991
1991
-
[24]
R. Vasudev, M. Russak, D. Bikel, W. Alshikh. Accurate Failure Prediction in Agents Does Not Imply Effective Failure Prevention.arXiv preprint arXiv:2602.03338, 2026. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.