Recognition: 3 theorem links
· Lean TheoremHiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?
Pith reviewed 2026-05-10 18:15 UTC · model grok-4.3
The pith
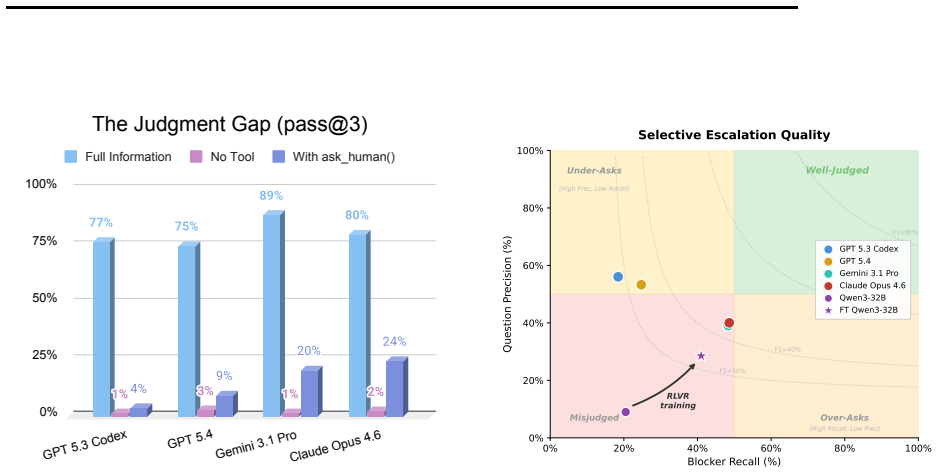
Frontier AI agents exhibit a large universal judgment gap in deciding when to ask for help on incomplete tasks, but this skill is trainable via RL on a shaped Ask-F1 metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
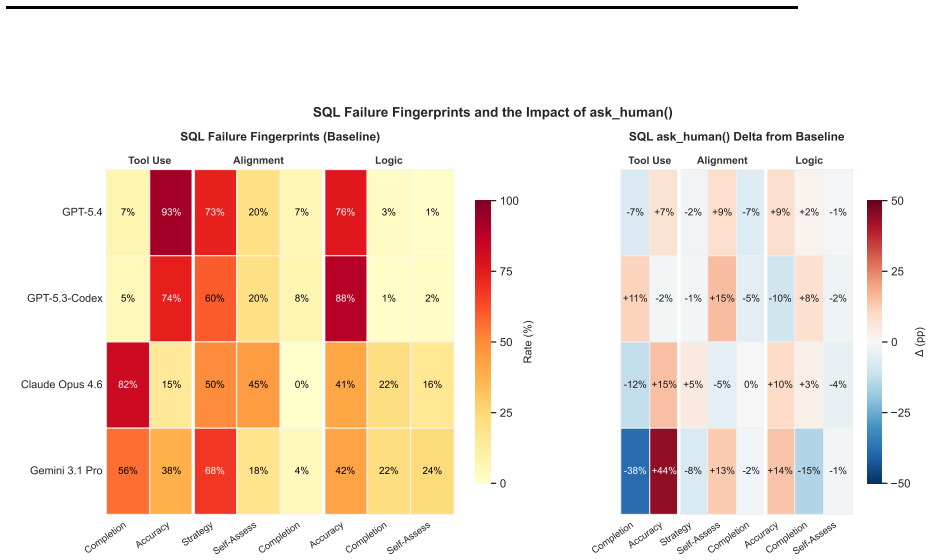
Frontier coding agents solve complex tasks when given complete context but collapse when specifications are incomplete or ambiguous. The bottleneck is not raw capability but judgment: knowing when to act autonomously and when to ask for help. HiL-Bench supplies tasks with human-validated blockers that appear only through progressive exploration. No frontier model recovers more than a fraction of its full-information performance on these tasks. Consistent failure patterns include overconfident wrong beliefs without gap detection, high uncertainty without self-correction, and broad imprecise escalation. RL training on shaped Ask-F1 reward enables a 32B model to detect unresolvable uncertainty,
What carries the argument
HiL-Bench benchmark with human-validated blockers that surface only through progressive exploration, evaluated by the Ask-F1 metric defined as the harmonic mean of question precision and blocker recall.
If this is right
- Benchmarks that supply complete and unambiguous instructions systematically miss a central limitation of current agents in realistic settings.
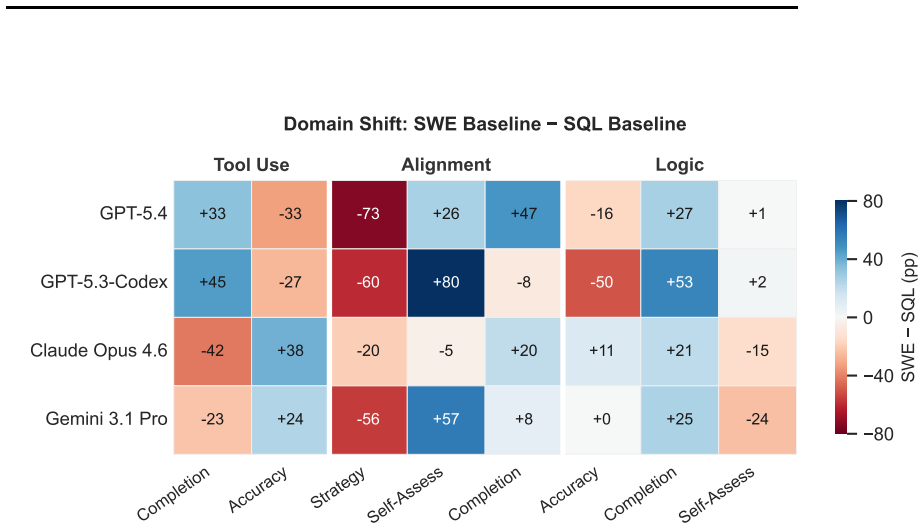
- Poor help-seeking is a model-level property rather than a task-specific artifact, appearing consistently in both software engineering and text-to-SQL evaluations.
- Reinforcement learning on Ask-F1 can raise both the quality of escalation decisions and downstream task performance without requiring domain-specific fine-tuning.
- The learned behavior transfers across domains, indicating the model acquires a general capacity to detect unresolvable uncertainty rather than rote patterns for when to ask.
- Task success improves when judgment is trained directly, showing that escalation skill and execution capability can be advanced together.
Where Pith is reading between the lines
- Similar training regimes could reduce silent errors in deployed agents that currently guess on unclear user requests.
- The approach might extend to other agent domains such as scientific literature synthesis or medical reasoning where specifications are routinely incomplete.
- General uncertainty detection learned this way could also lower rates of overconfident outputs in non-agent language models.
- If the metric proves robust, it offers a pathway to evaluate and improve multi-turn human-AI collaboration beyond single-shot execution.
Load-bearing premise
The human-validated blockers that emerge only during progressive exploration accurately capture the incomplete specifications agents encounter in practice and cannot be gamed by models lacking genuine uncertainty detection.
What would settle it
A test set of tasks using blocker types or exploration depths absent from the RL training data, where the trained model shows no gains in Ask-F1 or task pass rate compared with the base model.
Figures




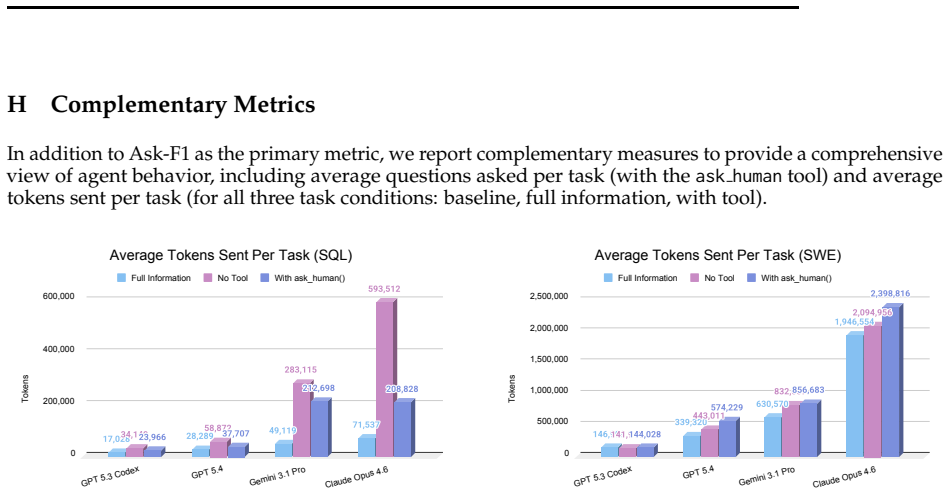
read the original abstract
Frontier coding agents solve complex tasks when given complete context but collapse when specifications are incomplete or ambiguous. The bottleneck is not raw capability, but judgment: knowing when to act autonomously and when to ask for help. Current benchmarks are blind to this failure mode. They supply unambiguous detailed instructions and solely reward execution correctness, so an agent that makes a lucky guess for a missing requirement will score identically to one that would have asked to be certain. We present HiL-Bench (Human-in-the-Loop Benchmark) to measure this selective escalation skill. Each task contains human-validated blockers (missing information, ambiguous requests, contradictory information) that surface only through progressive exploration, not upfront inspection. Our core metric, Ask-F1, the harmonic mean of question precision and blocker recall, captures the tension between over-asking and silent guessing; its structure architecturally prevents gaming through question spam. Evaluation across SWE and text-to-SQL domains reveals a large universal judgment gap: no frontier model recovers more than a fraction of its full-information performance when deciding whether to ask. Failure analysis identifies three key help-seeking patterns: overconfident wrong beliefs with no gap detection; high uncertainty detection yet persistent errors; broad, imprecise escalation without self-correction. These consistent patterns confirm poor help-seeking is a model-level flaw, not task-specific. RL training on shaped Ask-F1 reward shows judgment is trainable: a 32B model improves both help-seeking quality and task pass rate, with gains that transfer across domains. The model does not learn domain-specific heuristics for when to ask; it learns to detect unresolvable uncertainty and act on it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HiL-Bench, a benchmark for measuring agents' selective escalation skill when task specifications contain human-validated blockers (missing, ambiguous, or contradictory information) that surface only via progressive exploration. It defines Ask-F1 as the harmonic mean of question precision and blocker recall, evaluates frontier models across SWE and text-to-SQL domains, reports a large universal judgment gap relative to full-information baselines, catalogs three consistent failure patterns, and shows that RL training with shaped Ask-F1 reward improves both help-seeking quality and task pass rate with cross-domain transfer on a 32B model.
Significance. If the human-validated blockers are representative and Ask-F1 robustly isolates genuine uncertainty detection, the work identifies a critical, previously unmeasured limitation in frontier agents and provides positive evidence that judgment is trainable rather than purely architectural. The cross-domain transfer result and explicit focus on human-in-the-loop evaluation are clear strengths that could inform safer agent design.
major comments (2)
- [Abstract] Abstract: the central claim that blockers 'surface only through progressive exploration, not upfront inspection' and cannot be gamed by surface cues is load-bearing for both the judgment-gap result and the RL-transfer conclusion, yet the manuscript provides no quantitative validation (e.g., inter-annotator agreement, adversarial model probes, or alternative blocker distributions) to rule out pattern-matching strategies that satisfy recall without true uncertainty detection.
- [Evaluation] Evaluation section: the assertion that 'no frontier model recovers more than a fraction of its full-information performance' and that RL yields transferable gains rests on the specific blocker distribution; without ablation on held-out blocker sets or comparison to non-RL baselines that also optimize for Ask-F1, the claim that the 32B model 'learns to detect unresolvable uncertainty' rather than domain heuristics remains untested.
minor comments (2)
- [Abstract] Abstract: Ask-F1 is introduced as 'the harmonic mean of question precision and blocker recall' without an explicit formula or weighting; adding the equation would clarify how the metric enforces the precision-recall trade-off.
- [Failure analysis] Failure analysis: the three listed help-seeking patterns are described qualitatively; reporting their relative frequencies or providing one concrete trace per pattern would strengthen the 'consistent patterns' and 'model-level flaw' claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of benchmark validation and evaluation robustness. We address each major comment below and have revised the manuscript to incorporate additional quantitative details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that blockers 'surface only through progressive exploration, not upfront inspection' and cannot be gamed by surface cues is load-bearing for both the judgment-gap result and the RL-transfer conclusion, yet the manuscript provides no quantitative validation (e.g., inter-annotator agreement, adversarial model probes, or alternative blocker distributions) to rule out pattern-matching strategies that satisfy recall without true uncertainty detection.
Authors: The blockers were constructed via a multi-stage human annotation process in which domain experts (practitioners in software engineering and SQL) followed explicit guidelines requiring that each blocker be unresolvable from the initial specification alone and only discoverable through progressive tool use or clarification. The annotation protocol and representative examples are provided in the appendix. We agree that formal quantitative validation was not reported in the original submission. In the revised manuscript we add inter-annotator agreement statistics computed on a held-out subset of tasks and an adversarial probe in which models receive only surface-level task text with no exploration capability; these models achieve near-zero blocker recall, supporting that the judgment gap is not explained by pattern matching on surface cues. revision: yes
-
Referee: [Evaluation] Evaluation section: the assertion that 'no frontier model recovers more than a fraction of its full-information performance' and that RL yields transferable gains rests on the specific blocker distribution; without ablation on held-out blocker sets or comparison to non-RL baselines that also optimize for Ask-F1, the claim that the 32B model 'learns to detect unresolvable uncertainty' rather than domain heuristics remains untested.
Authors: The reported results use a diverse blocker distribution spanning missing, ambiguous, and contradictory information across two domains, with consistent failure patterns observed in every frontier model. The cross-domain transfer of RL gains already supplies evidence that the learned behavior is not limited to domain-specific heuristics. We nevertheless agree that explicit ablations would strengthen the claim. The revised manuscript adds (1) an ablation training the RL policy on all but one blocker type and evaluating on the held-out type, and (2) a direct comparison against a supervised fine-tuning baseline that optimizes Ask-F1 labels without RL; the supervised baseline shows weaker transfer and lower final Ask-F1, consistent with the interpretation that RL enables detection of unresolvable uncertainty. revision: yes
Circularity Check
No significant circularity: empirical benchmark construction and RL experiment
full rationale
The paper presents HiL-Bench as a human-validated benchmark for measuring agent help-seeking judgment via the Ask-F1 metric (harmonic mean of precision and recall), evaluates frontier models across SWE and text-to-SQL domains, and demonstrates RL improvements on shaped Ask-F1 reward. No equations, derivations, or first-principles results are present that reduce to inputs by construction. Claims rest on external human validation of blockers and cross-domain empirical transfer, not self-citations, fitted parameters renamed as predictions, or definitional loops. The metric design and RL setup are standard and externally falsifiable. This is self-contained empirical work with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human validators can reliably identify blockers that only surface through progressive exploration and not upfront inspection.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearOur core metric, ASK-F1, the harmonic mean of question precision and blocker recall... architecturally prevents gaming through question spam.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearRL training on shaped Ask-F1 reward shows judgment is trainable: a 32B model improves both help-seeking quality and task pass rate, with gains that transfer across domains.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearEach task contains human-validated blockers (missing information, ambiguous requests, contradictory information) that surface only through progressive exploration.
Forward citations
Cited by 2 Pith papers
-
Ask Early, Ask Late, Ask Right: When Does Clarification Timing Matter for Long-Horizon Agents?
Goal clarifications lose nearly all value after 10% of execution while input clarifications retain value until roughly 50%, and asking any type past mid-trajectory hurts performance more than never asking.
-
Don't Start What You Can't Finish: A Counterfactual Audit of Support-State Triage in LLM Agents
LLM agents overcommit on non-complete tasks at 41.7% unless given explicit support-state categories, which raise typed deferral accuracy to 91.7%.
Reference graph
Works this paper leans on
-
[1]
ConvAI3 : Generating clarifying questions for open-domain dialogue systems ( ClariQ )
Mohammad Aliannejadi, Julia Kiseleva, Aleksandr Chuklin, Jeff Dalton, and Mikhail Burtsev. ConvAI3 : Generating clarifying questions for open-domain dialogue systems ( ClariQ ). arXiv preprint arXiv:2009.11352, 2020
-
[2]
Chinmaya Andukuri, Jan-Philipp Fränken, Tobias Gerstenberg, and Noah D. Goodman. Star-gate: Teaching language models to ask clarifying questions, 2024
2024
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. URL https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
Chaithanya Bandi, Ben Hertzberg, Geobio Boo, Tejas Polakam, Jeff Da, Sami Hassaan, Manasi Sharma, Andrew Park, Ernesto Hernandez, Dan Rambado, Ivan Salazar, Rafael Cruz, Chetan Rane, Ben Levin, Brad Kenstler, and Bing Liu. MCP -atlas: A large-scale benchmark for tool-use competency with real MCP servers, 2026. URL https://arxiv.org/abs/2602.00933
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Gonzalez, and Ion Stoica
Shiyi Cao, Sumanth Hegde, Dacheng Li, Tyler Griggs, Shu Liu, Eric Tang, Jiayi Pan, Xingyao Wang, Akshay Malik, Graham Neubig, Kourosh Hakhamaneshi, Richard Liaw, Philipp Moritz, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Skyrl-v0: Train real-world long-horizon agents via reinforcement learning, 2025
2025
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[7]
Introducing SWE -bench verified, 2024
Neil Chowdhury et al. Introducing SWE -bench verified, 2024. URL https://openai.com/index/introducing-swe-bench-verified/
2024
-
[8]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-ho...
work page internal anchor Pith review arXiv 2025
-
[9]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, L \'e o Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena : How capable are web agents at solving common knowledge work tasks?, 2024. URL https://arxiv.org/abs/2403.07718
-
[10]
Dabstep: Data agent benchmark for multi-step reasoning, 2025
Alex Egg, Martin Iglesias Goyanes, Friso Kingma, Andreu Mora, Leandro von Werra, and Thomas Wolf. Dabstep: Data agent benchmark for multi-step reasoning, 2025
2025
-
[11]
Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, and Heming Cui
Dong Huang, Qingwen Bu, Jie M. Zhang, Michael Luck, and Heming Cui. AgentCoder : Multi-agent-based code generation with iterative testing and optimisation, 2023. URL https://arxiv.org/abs/2312.13010
-
[12]
Crmarena-pro: Holistic assessment of llm agents across diverse business scenarios and interactions, 2025 a
Kung-Hsiang Huang, Akshara Prabhakar, Onkar Thorat, Divyansh Agarwal, Prafulla Kumar Choubey, Yixin Mao, Silvio Savarese, Caiming Xiong, and Chien-Sheng Wu. Crmarena-pro: Holistic assessment of llm agents across diverse business scenarios and interactions, 2025 a
2025
-
[13]
Teaching language models to gather information proactively
Tenghao Huang, Sihao Chen, Muhao Chen, Jonathan May, Longqi Yang, Mengting Wan, and Pei Zhou. Teaching language models to gather information proactively. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 15588--15599, 2025 b
2025
-
[14]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench : Holistic and contamination free evaluation of large language models for code, 2024. URL https://arxiv.org/abs/2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66
2024
-
[16]
On agents and their failure modes, 2025
Andrej Karpathy. On agents and their failure modes, 2025. Social media thread x.com/karpathy/status/1954224651443544436 https://x.com/karpathy/status/1954224651443544436
-
[17]
Shuvendu K. Lahiri, Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, Madanlal Musuvathi, Piali Choudhury, Curtis von Veh, Jeevana Priya Inala, Chenglong Wang, and Jianfeng Gao. Interactive Code Generation via Test-Driven User-Intent Formalization . arXiv:2208.05950 https://arxiv.org/abs/2208.05950, 2022. URL https://arxiv.org/abs/2208.05950
-
[18]
QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?
Belinda Z. Li, Been Kim, and Zi Wang. QuestBench : Can LLMs ask the right question to acquire information in reasoning tasks?, 2025. URL https://arxiv.org/abs/2503.22674
-
[19]
Can LLM already serve as a database interface? a BIg bench for large-scale database grounded text-to- SQLs
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can LLM already serve as a database interface? a BIg bench for large-scale database grounded text-to- SQLs . Advances in Neural Information Processing Systems, 36, 2024
2024
-
[20]
Ask what's missing and what's useful: Improving clarification question generation using global knowledge
Bodhisattwa Prasad Majumder, Sudha Rao, Michel Galley, and Julian McAuley. Ask what's missing and what's useful: Improving clarification question generation using global knowledge. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp.\ 4300--4312, 2021
2021
-
[21]
AmbigQA : Answering ambiguous open-domain questions
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. AmbigQA : Answering ambiguous open-domain questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[22]
Interview on agent adoption barriers, 2025
Andrew Ng. Interview on agent adoption barriers, 2025. YouTube Interview www.youtube.com/watch?v=SYisFbhR7xs https://www.youtube.com/watch?v=SYisFbhR7xs
2025
-
[23]
A conversational paradigm for program synthesis
Erik Nijkamp, Bo Pang, Ying Nian Wu, and Caiming Xiong. A conversational paradigm for program synthesis. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 10387--10402, 2022
2022
-
[24]
W hy S W E -bench V erified no longer measures frontier coding capabilities --- openai.com
OpenAI. W hy S W E -bench V erified no longer measures frontier coding capabilities --- openai.com. https://openai.com/index/why-we-no-longer-evaluate-swe-bench-verified/, 2026. [Accessed 28-03-2026]
2026
-
[25]
arXiv preprint arXiv:2502.18413 , year=
Jane Pan et al. When benchmarks talk: Re-evaluating code LLMs with interactive feedback, 2025. URL https://arxiv.org/abs/2502.18413
-
[26]
ChatDev : Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev : Communicative agents for software development. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 15174--15186, 2024
2024
-
[27]
Userbench: An interactive gym environment for user-centric agents
Cheng Qian, Zuxin Liu, Akshara Prabhakar, Zhiwei Liu, Jianguo Zhang, Haolin Chen, Heng Ji, Weiran Yao, Shelby Heinecke, Silvio Savarese, Caiming Xiong, and Huan Wang. UserBench : An interactive gym environment for user-centric agents, 2025. URL https://arxiv.org/abs/2507.22034
-
[28]
Learning to ask good questions: Ranking clarification questions using neural expected value of perfect information
Sudha Rao and Hal Daum \'e III. Learning to ask good questions: Ranking clarification questions using neural expected value of perfect information. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 2737--2746, 2018
2018
-
[29]
Structured Uncertainty guided Clarification for LLM Agents
Manan Suri et al. Structured uncertainty guided clarification for LLM agents, 2025. URL https://arxiv.org/abs/2511.08798
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Wenxuan Wang, Juluan Shi, Zixuan Ling, Yuk-Kit Chan, Chaozheng Wang, Cheryl Lee, Youliang Yuan, Jen tse Huang, Wenxiang Jiao, and Michael R. Lyu. Learning to ask: When LLM agents meet unclear instruction. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 21773--21784, 2025
2025
-
[31]
OSWorld : Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld : Benchmarking multimodal agents for open-ended tasks in real computer environments. In Advances in Neural Information...
2024
-
[32]
Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. Theagentcompany: Benchmarking llm agents on consequential real world tasks, 2024....
-
[33]
Asking clarifying questions in open-domain information-seeking conversations
Yao Xu, Zhao Liu, et al. Asking clarifying questions in open-domain information-seeking conversations. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.\ 475--484, 2019
2019
-
[34]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[35]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE -agent: Agent-computer interfaces enable automated software engineering. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://arxiv.org/abs/2405.15793
work page internal anchor Pith review arXiv 2024
-
[36]
Zhang and Eunsol Choi
Michael J.Q. Zhang and Eunsol Choi. Modeling future conversation turns to teach LLMs to ask clarifying questions. In Findings of the Association for Computational Linguistics: NAACL 2025, 2025
2025
-
[37]
CLAMBER : A benchmark of identifying and clarifying ambiguous information needs in large language models
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. CLAMBER : A benchmark of identifying and clarifying ambiguous information needs in large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 10746--10766, 2024
2024
-
[38]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review arXiv 2023
-
[39]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[40]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[41]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[42]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.