Recognition: unknown
Frozen Vision Transformers for Dense Prediction on Small Datasets: A Case Study in Arrow Localization
Pith reviewed 2026-05-10 08:01 UTC · model grok-4.3
The pith
A frozen self-supervised vision transformer localizes arrow punctures on archery targets to 1.41 mm accuracy using only 48 training images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
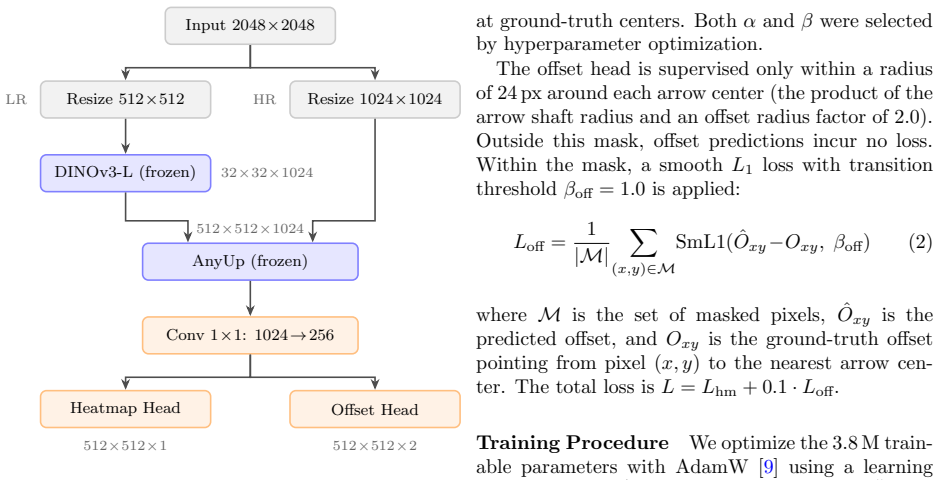
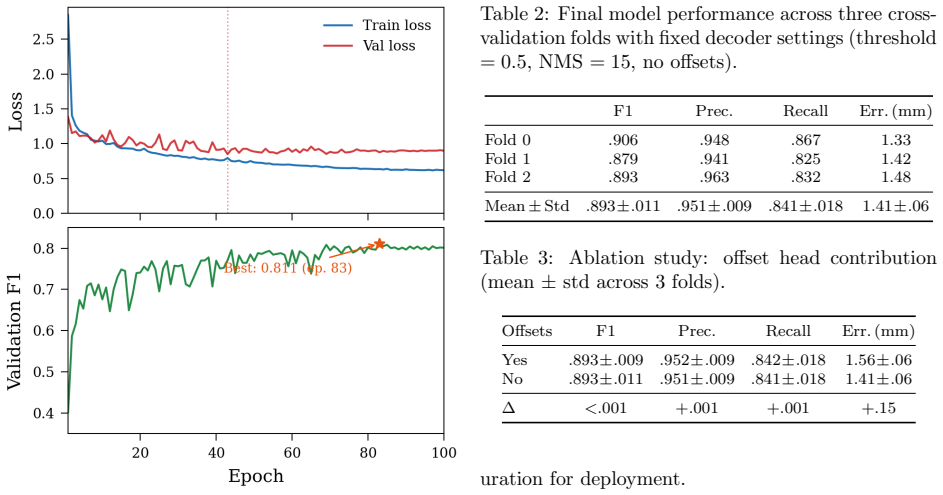
A pipeline that freezes a DINOv3 ViT-L/16 backbone, adds AnyUp guided upsampling to restore spatial resolution from 32 by 32 patch tokens, and attaches lightweight CenterNet-style heads can detect and localize arrow punctures on 40 cm targets after training on only 48 photographs containing 5,084 punctures. With 3.8 M trainable parameters out of 308 M total, the method yields a mean F1 of 0.893 plus or minus 0.011 and mean localization error of 1.41 plus or minus 0.06 mm across three cross-validation folds, while recovering average arrow scores to a median error of 1.8 percent and group centroids to a median of 4.00 mm.
What carries the argument
Frozen DINOv3 ViT-L/16 backbone combined with AnyUp guided feature upsampling to recover sub-millimeter precision from patch tokens, plus color-based canonical rectification that standardizes perspective views for physical measurement.
If this is right
- Guided feature upsampling already supplies the spatial precision that an offset regression head normally provides, so the extra head can be omitted.
- Only 3.8 million parameters need to be trained, leaving the remaining 304 million frozen.
- Per-image average arrow scores are recovered with a median error of 1.8 percent.
- Group centroid positions are recovered to a median error of 4.00 mm.
- The approach matches fully supervised methods that require substantially larger training sets.
Where Pith is reading between the lines
- The same frozen-plus-light-adaptation pattern could be tested on other small-data dense prediction tasks such as defect detection on manufactured parts or tracking in sports video.
- Performance may depend on having a reliable domain-specific rectification step; without it the model would need to learn perspective correction from the limited labels.
- Alternative self-supervised backbones or different upsampling operators could be swapped in to test whether DINOv3 and AnyUp are uniquely effective here.
- The low parameter count suggests the pipeline could run on modest hardware for real-time coaching feedback during archery sessions.
Load-bearing premise
The color-based canonical rectification stage reliably maps perspective-distorted photographs into a standardized coordinate system where pixel distances correspond to known physical measurements.
What would settle it
Retraining and testing the same frozen backbone on a new collection of target photographs captured under changed lighting or with non-standard color patterns, then measuring whether localization error rises above 2 mm without the rectification step, would show whether the frozen model alone suffices.
Figures





read the original abstract
We present a system for automated detection, localization, and scoring of arrow punctures on 40\,cm indoor archery target faces, trained on only 48 annotated photographs (5{,}084 punctures). Our pipeline combines three components: a color-based canonical rectification stage that maps perspective-distorted photographs into a standardized coordinate system where pixel distances correspond to known physical measurements; a frozen self-supervised vision transformer (DINOv3 ViT-L/16) paired with AnyUp guided feature upsampling to recover sub-millimeter spatial precision from $32 \times 32$ patch tokens; and lightweight CenterNet-style detection heads for arrow-center heatmap prediction. Only 3.8\,M of 308\,M total parameters are trainable. Across three cross-validation folds, we achieve a mean F1 score of $0.893 \pm 0.011$ and a mean localization error of $1.41 \pm 0.06$\,mm, comparable to or better than prior fully-supervised approaches that require substantially more training data. An ablation study shows that the CenterNet offset regression head, typically essential for sub-pixel refinement, provides negligible detection improvement while degrading localization in our setting. This suggests that guided feature upsampling already resolves the spatial precision lost through patch tokenization. On downstream archery metrics, the system recovers per-image average arrow scores with a median error of 1.8\% and group centroid positions to within a median of 4.00\,mm. These results demonstrate that frozen foundation models with minimal task-specific adaptation offer a practical paradigm for dense prediction in small-data regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a pipeline for automated detection, localization, and scoring of arrow punctures on 40 cm archery targets using only 48 annotated images (5,084 punctures). It combines a color-based canonical rectification stage, a frozen DINOv3 ViT-L/16 backbone with AnyUp guided upsampling, and lightweight CenterNet-style heads, training just 3.8M of 308M parameters. Cross-validation yields mean F1 of 0.893 ± 0.011 and localization error of 1.41 ± 0.06 mm, with downstream median errors of 1.8% on scores and 4 mm on centroids; an ablation indicates the offset head adds little value.
Significance. If the rectification is reliable, the work would demonstrate that frozen foundation models with minimal adaptation can deliver competitive dense-prediction performance in small-data regimes, supported by cross-validation metrics with standard deviations and an ablation study. This offers a practical alternative to fully supervised training on large datasets for specialized applications.
major comments (1)
- [Abstract] Abstract (and methods description of the color-based canonical rectification stage): all headline metrics are reported in physical units (1.41 mm localization error, 4 mm centroid, 1.8% score error), yet no quantitative validation, accuracy metrics, failure-case analysis, or comparison against ground-truth physical measurements is provided for the rectification. If rectification error is comparable to or larger than 1.41 mm, the physical-unit claims lose empirical grounding and the small-data performance argument cannot be evaluated.
minor comments (2)
- The ablation study is summarized but lacks a table or explicit numerical comparison (F1 and localization error with vs. without the offset head) that would allow readers to assess the claim that guided upsampling already resolves spatial precision.
- Implementation details for AnyUp integration, the exact form of the CenterNet heads, and the rectification algorithm (e.g., color calibration procedure) are referenced but not fully specified, limiting reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback. The primary concern is the lack of quantitative validation for the color-based canonical rectification stage underlying the physical-unit metrics. We address this point below and commit to revisions that strengthen the empirical support without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract (and methods description of the color-based canonical rectification stage): all headline metrics are reported in physical units (1.41 mm localization error, 4 mm centroid, 1.8% score error), yet no quantitative validation, accuracy metrics, failure-case analysis, or comparison against ground-truth physical measurements is provided for the rectification. If rectification error is comparable to or larger than 1.41 mm, the physical-unit claims lose empirical grounding and the small-data performance argument cannot be evaluated.
Authors: We agree that explicit quantitative validation of the rectification would strengthen the grounding of the physical-unit claims. The rectification applies color-based segmentation to detect the target's outer boundary and rings, followed by a homography that maps each image to a canonical coordinate frame in which the 40 cm target diameter is fixed, enabling direct pixel-to-mm conversion. All reported localization and scoring errors are computed in this rectified frame against human annotations. The low cross-validation standard deviation on localization error (0.06 mm) provides indirect evidence of rectification consistency, as inconsistent rectification would inflate variance. Nevertheless, we acknowledge the referee's point is valid and will revise the manuscript to add: (i) a precise algorithmic description of the color segmentation and homography steps, (ii) quantitative metrics such as the mean and standard deviation of the estimated target diameter (in pixels) across the 48 images and the average corner reprojection error of the fitted homography, and (iii) a short failure-case analysis (e.g., images with extreme lighting or partial occlusion) together with their frequency and impact on downstream metrics. These additions will be placed in a new subsection of Methods and will demonstrate that rectification error is well below the 1.41 mm localization figure, thereby preserving the validity of the physical-unit results. revision: yes
Circularity Check
No circularity in empirical pipeline
full rationale
The paper presents an empirical system for arrow localization using a frozen DINOv3 ViT with AnyUp upsampling and lightweight detection heads, trained on 48 images and evaluated via cross-validation folds against external annotations. No mathematical derivations, equations, or predictions are claimed that reduce to fitted parameters or inputs by construction. The color-based rectification is described as a preprocessing stage but is not derived from or equivalent to the model outputs; all reported metrics (F1, mm errors) are measured directly on held-out data. This matches the reader's assessment of no self-referential reductions, making the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. Zhou, D. Wang, and P. Kr¨ ahenb¨ uhl, “Objects as points,”arXiv preprint arXiv:1904.07850, 2019
-
[2]
DINOv2: Learning robust vi- sual features without supervision,
M. Oquabet al., “DINOv2: Learning robust vi- sual features without supervision,”Trans. Mach. Learn. Res., 2024
2024
-
[3]
O. Sim´ eoniet al., “DINOv3,”arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
AnyUp: Universal feature up- sampling,
T. Wimmer, P. Truong, M.-J. Rakotosaona, M. Oechsle, F. Tombari, B. Schiele, and J. E. Lenssen, “AnyUp: Universal feature up- sampling,” inProc. Int. Conf. Learn. Represent. (ICLR), 2026
2026
-
[5]
Archery score analysis system for outdoor environments,
S. Kim, J. Moon, and E. C. Lee, “Archery score analysis system for outdoor environments,” Proc. Inst. Mech. Eng., Part P: J. Sports Eng. Technol., 2025
2025
-
[6]
Rulebook, Book 3: Target Archery,
World Archery, “Rulebook, Book 3: Target Archery,” World Archery Federation, 2025. [On- line]. Available:https://www.worldarchery. sport/rulebook/article/13
2025
-
[7]
Optuna: A next-generation hy- perparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hy- perparameter optimization framework,” inProc. ACM SIGKDD Int. Conf. Knowl. Disc. Data Mining, 2019, pp. 2623–2631
2019
-
[8]
Albumentations: Fast and flexible image aug- mentations,
A. Buslaev, V. I. Iglovikov, E. Khvedchenya, A. Parinov, M. Druzhinin, and A. A. Kalinin, “Albumentations: Fast and flexible image aug- mentations,”Information, vol. 11, no. 2, p. 125, 2020
2020
-
[9]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. Int. Conf. Learn. Represent. (ICLR), 2019
2019
-
[10]
The Hungarian method for the assignment problem,
H. W. Kuhn, “The Hungarian method for the assignment problem,”Naval Research Logistics Quarterly, vol. 2, no. 1–2, pp. 83–97, 1955. 9
1955
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.