Recognition: unknown
Freshness-Aware Prioritized Experience Replay for LLM/VLM Reinforcement Learning
Pith reviewed 2026-05-10 07:23 UTC · model grok-4.3
The pith
Freshness-Aware PER adds exponential age decay to experience priorities to overcome staleness in fast-evolving LLM policies and achieve major gains over on-policy RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that augmenting prioritized experience replay with a multiplicative exponential age decay term, derived from effective sample size analysis, resolves the priority staleness issue caused by rapid policy updates in large models, allowing successful off-policy learning that significantly exceeds on-policy baselines.
What carries the argument
The age decay factor, a multiplicative term applied to priorities that exponentially reduces the weight of older trajectories as the policy evolves.
If this is right
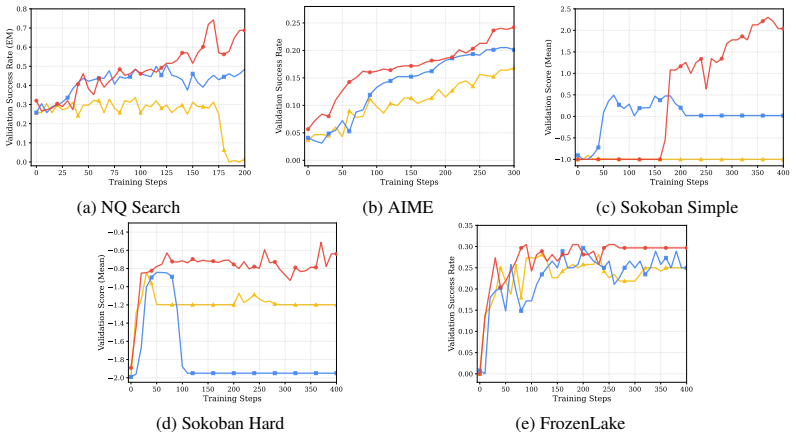
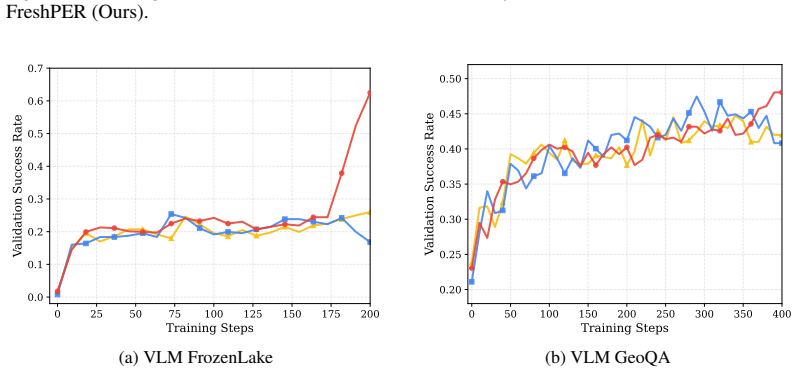
- Large performance improvements on tasks such as natural language search, Sokoban, and vision-language navigation.
- Consistent degradation when using standard PER without age decay.
- Effective across model sizes of 0.5B, 3B, and 7B parameters.
- Applicable to a range of multi-step reasoning and agentic environments.
Where Pith is reading between the lines
- Age decay mechanisms like this may extend to other off-policy RL methods when applied to non-stationary policies in large models.
- Reducing the discard rate of trajectories could lower the overall compute needed for post-training LLMs.
- Further work might explore adaptive decay rates that depend on measured policy change speed.
Load-bearing premise
The specific form of multiplicative exponential age decay will accurately counteract staleness from policy changes without introducing harmful sampling biases or requiring extensive tuning.
What would settle it
If an ablation study removing the age decay or using a fixed decay rate results in performance no better than or worse than on-policy methods, the mechanism's effectiveness would be called into question.
Figures







read the original abstract
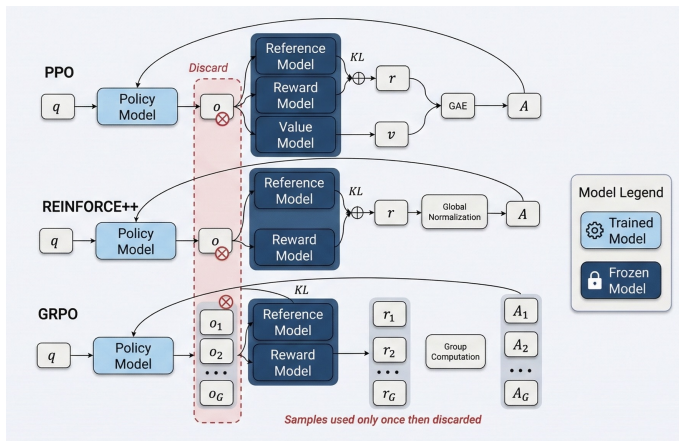
Reinforcement Learning (RL) has achieved impressive success in post-training Large Language Models (LLMs) and Vision-Language Models (VLMs), with on-policy algorithms such as PPO, GRPO, and REINFORCE++ serving as the dominant paradigm. However, these methods discard all collected trajectories after a single gradient update, resulting in poor sample efficiency, particularly wasteful for agentic tasks where multi-turn environment interactions are expensive. While Experience Replay drives sample efficiency in classic RL by allowing agents to reuse past trajectories and prioritize informative ones, directly applying Prioritized Experience Replay (PER) to LLMs fails. The rapid policy evolution of billion-parameter models renders stored priorities stale, causing old high-priority trajectories to dominate sampling long after they have become uninformative. We propose Freshness-Aware PER, which addresses this priority staleness problem by augmenting any PER-based priority with a multiplicative exponential age decay grounded in effective sample size analysis. To the best of our knowledge, Freshness-Aware PER is the first work to successfully apply PER to LLM/VLM reinforcement learning. We evaluate on eight multi-step agentic, reasoning, and math competition tasks with 0.5B, 3B, and 7B models. Freshness-Aware PER significantly outperforms on-policy baselines, achieving +46% on NQ Search, +367% on Sokoban, and +133% on VLM FrozenLake, while standard PER without age decay consistently degrades performance. Our code is publicly available at https://github.com/Vision-CAIR/Freshness-Aware-PER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Freshness-Aware Prioritized Experience Replay (PER) to improve sample efficiency in LLM and VLM reinforcement learning. Standard on-policy methods like PPO discard trajectories after one update, while direct application of PER fails due to rapid policy evolution making stored priorities stale. The method augments PER priorities with a multiplicative exponential age decay derived from effective sample size analysis. Evaluations across eight agentic, reasoning, and math tasks using 0.5B–7B models report large gains over on-policy baselines (+46% on NQ Search, +367% on Sokoban, +133% on VLM FrozenLake) and consistent degradation when using vanilla PER without the decay. Code is released publicly.
Significance. If the central result holds, the work would provide a practical route to off-policy reuse in LLM/VLM post-training, where environment interactions are costly. The consistent degradation of standard PER and the public code release are notable strengths that would support adoption if the age-decay mechanism proves robust across tasks and model scales.
major comments (2)
- [Method (age decay derivation)] The grounding of the multiplicative exponential age decay in effective sample size analysis (described in the method) assumes priority distributions evolve on timescales comparable to classic RL. For billion-parameter models, a single gradient step can induce abrupt policy shifts; the manuscript must demonstrate that the chosen decay rate remains effective without per-task retuning or introducing new sampling bias under these conditions, as the reported gains (+46% NQ Search, etc.) could otherwise hinge on hyperparameter selection.
- [Experiments (main results table and ablation)] Table reporting main results and the PER ablation: the manuscript shows standard PER degrades performance, but does not report per-seed variance, statistical significance tests, or the exact replay-buffer size and priority normalization used. Without these, it is unclear whether the Freshness-Aware variant’s advantage is robust or sensitive to implementation details that interact with the decay term.
minor comments (2)
- [Related Work] The abstract states 'to the best of our knowledge' Freshness-Aware PER is the first successful application of PER to LLM/VLM RL; the related-work section should explicitly cite and differentiate from any prior attempts at experience replay in language-model RL to strengthen this claim.
- [Method] Notation for the age-decay factor and its integration into the priority formula should be introduced with a single equation early in the method section rather than scattered across paragraphs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing clarifications and committing to revisions that strengthen the presentation of robustness without altering the core claims.
read point-by-point responses
-
Referee: [Method (age decay derivation)] The grounding of the multiplicative exponential age decay in effective sample size analysis (described in the method) assumes priority distributions evolve on timescales comparable to classic RL. For billion-parameter models, a single gradient step can induce abrupt policy shifts; the manuscript must demonstrate that the chosen decay rate remains effective without per-task retuning or introducing new sampling bias under these conditions, as the reported gains (+46% NQ Search, etc.) could otherwise hinge on hyperparameter selection.
Authors: We thank the referee for this important observation. The effective sample size derivation yields a general exponential decay factor that depends on the observed rate of policy evolution (via KL divergence between consecutive policies), rather than assuming classic RL timescales. In the original experiments, a single decay hyperparameter was used uniformly across all eight tasks and model scales (0.5B–7B) with no per-task retuning, and the consistent gains plus vanilla PER degradation support that the rate is not overly sensitive. In the revised manuscript we add (i) per-step policy shift measurements confirming the decay remains effective under abrupt LLM updates and (ii) a sensitivity plot over a range of decay rates showing stable performance without new sampling bias (the multiplicative term is renormalized after application). These additions directly address the concern while preserving the reported gains. revision: yes
-
Referee: [Experiments (main results table and ablation)] Table reporting main results and the PER ablation: the manuscript shows standard PER degrades performance, but does not report per-seed variance, statistical significance tests, or the exact replay-buffer size and priority normalization used. Without these, it is unclear whether the Freshness-Aware variant’s advantage is robust or sensitive to implementation details that interact with the decay term.
Authors: We agree these reporting details are essential. The replay buffer size (10,000 trajectories) and priority normalization (sum-tree with freshness decay applied prior to normalization) are specified in Section 4.1 and the publicly released code. In the revised manuscript we expand the main results table to report mean ± standard deviation over five random seeds and include paired t-test p-values establishing statistical significance of the improvements over baselines. We also add a short paragraph clarifying that the decay term is applied before normalization, preventing stale-sample dominance and ensuring the observed advantage is not an artifact of implementation choices. revision: yes
Circularity Check
No circularity: age decay presented as derived from effective sample size analysis with independent empirical validation
full rationale
The paper's central proposal augments PER priorities with a multiplicative exponential age decay explicitly grounded in effective sample size analysis, rather than by fitting to the target performance metrics or by self-referential definition. No equations, claims, or citations in the provided text reduce this decay (or the overall Freshness-Aware PER method) to its inputs by construction, invoke load-bearing self-citations for uniqueness, or rename known results as novel derivations. Performance gains are reported as separate empirical evaluations across multiple tasks and model sizes, without the 'predictions' being statistically forced by the derivation itself. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- exponential decay rate
axioms (1)
- domain assumption Effective sample size analysis provides a valid grounding for determining trajectory freshness in the context of fast policy updates.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
11 DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learn- ing.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Rlhf workflow: From reward modeling to online rlhf
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. RLHF workflow: From reward modeling to online RLHF.arXiv preprint arXiv:2405.07863,
-
[4]
Prioritized replay for RL post-training.arXiv preprint arXiv:2601.02648,
Mehdi Fatemi, Banafsheh Rafiee, Kavosh Asadi, Yaqiao Li, Yunhao Tang, Yongchao Zhou, and Dzmitry Bahdanau. Prioritized replay for RL post-training.arXiv preprint arXiv:2601.02648,
-
[5]
Revisiting fundamentals of experience replay.arXiv preprint arXiv:2007.06700,
William Fedus, Prajit Ramachandran, Aravind Rajeswaran, Charles Blundell, Timothy Lillicrap, et al. Revisiting fundamentals of experience replay.arXiv preprint arXiv:2007.06700,
-
[6]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Siheng Li, Wanpeng Zhang, Yue Wu, Tianbao Xie, Yongfeng Zhang, Tao Yu, Zhiwei Jia, and Zhaoran Wang. AReaL: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298,
-
[7]
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, et al. OpenRLHF: An easy-to-use, scalable and high-performance RLHF framework.arXiv preprint arXiv:2405.11143,
-
[8]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. REINFORCE++: Stabilizing critic-free policy optimization with global advantage normalization.arXiv preprint arXiv:2501.03262,
work page internal anchor Pith review arXiv
-
[9]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, et al. Vision-R1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review arXiv
-
[10]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
-
[11]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025a. Zichuan Liu, Jinyu Wang, Lei Song, and Jiang Bian. Sample-efficient LLM optimization with reset replay.arXiv preprint arXiv:2508.06412, 2025b. Yu Luo, Shuo Han,...
-
[12]
Michael Noukhovitch, Shengyi Huang, Sophie Xhonneux, Arian Hosseini, Rishabh Agarwal, and Aaron Courville. Asynchronous RLHF: Faster and more efficient off-policy RL for language models.arXiv preprint arXiv:2410.18252,
-
[13]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Qwen Team. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Nicolas Le Roux, Marc G. Bellemare, Jonathan Lebensold, Arnaud Bergeron, Joshua Greaves, et al. Tapered off-policy REINFORCE: Stable and efficient reinforcement learning for LLMs.arXiv preprint arXiv:2503.14286,
-
[16]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prajit Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, et al. VLM-R1: A stable and generalizable R1-style large vision-language model.arXiv preprint arXiv:2504.07615,
work page internal anchor Pith review arXiv
-
[19]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework.arXiv preprint arXiv:2409.19256,
work page internal anchor Pith review arXiv
-
[20]
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, et al. Improving data ef- ficiency for LLM reinforcement fine-tuning through difficulty-targeted online data selection and rollout replay.arXiv preprint arXiv:2506.05316,
-
[21]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, Zichen Liu, Haizhou Zhao, et al. ROLL: Reinforcement learning optimization for large-scale learning: An efficient and user-friendly scaling library.arXiv preprint arXiv:2506.06122, 2025a. 13 Zihan Wang, Kangrui Wang, Qineng Wang, Ping...
-
[22]
arXiv preprint arXiv:2510.18927 , year=
Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, et al. BAPO: Stabilizing off-policy reinforcement learning for LLMs via balanced policy optimization with adaptive clipping.arXiv preprint arXiv:2510.18927,
-
[23]
Part II: ROLL flash - accelerating RLVR and agentic training with asynchrony.CoRR, abs/2510.11345,
Luo Yu, Zhiyuan Zeng, Jiaze Chen, Qiying Yu, Jian Li, Yuchi Zhang, Hang Yan, Bairen Yi, Ao Liu, Tao Ji, Zhipeng Chen, Dahua Lin, Junbo Zhao, and Zhi Zheng. ROLL Flash: Accelerating RLVR and agentic training with asynchrony.arXiv preprint arXiv:2510.11345, 2025a. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohang C...
-
[24]
Haizhong Zheng, Jiawei Zhao, and Beidi Chen. Prosperity before collapse: How far can off-policy RL reach with stale data on LLMs?arXiv preprint arXiv:2510.01161,
-
[25]
Max Actions
between distributionsPandQis defined as: Dα(P∥Q) = 1 α−1 logE Q P(x) Q(x) α .(22) Two standard properties are relevant here: Property 1: Connection toχ 2-divergence.Settingα= 2in Eq. (22): D2(P∥Q) = logE Q ρ2 = log 1 +χ 2(P∥Q) ,(23) where we usedE Q[ρ2] = 1 +χ 2 from Eq. (21). Rearranging: χ2(P∥Q) = exp(D 2(P∥Q))−1.(24) 17 Property 2: Monotonicity inα.Pre...
2014
-
[26]
Con- fig A
This serves as a control: the task is simple enough that on-policy training solves it quickly, and replay is not expected to help. GSM8K.Grade-school math word problems [Cobbe et al., 2021] requiring multi-step arithmetic reasoning. The base Qwen2.5-0.5B model already achieves>93% accuracy on this task, so it serves as a near-saturated control where repla...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.