Recognition: unknown
Alignment Imprint: Zero-Shot AI-Generated Text Detection via Provable Preference Discrepancy
Pith reviewed 2026-05-10 07:21 UTC · model grok-4.3
The pith
The alignment process in LLMs creates a detectable imprint that enables a new zero-shot method to identify AI-generated text with statistical guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
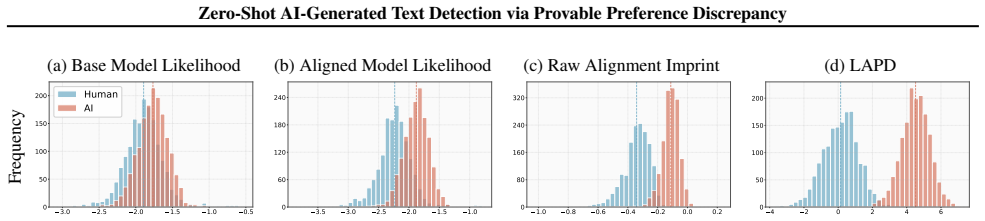
The paper's core claim is that by abstracting alignment as a sequence of constrained optimization steps, the log-likelihood ratio between aligned and base models decomposes into implicit instructional biases and preference rewards, termed the Alignment Imprint. This imprint forms the basis for LAPD, a standardized information-weighted statistic that offers statistical guarantees of better performance than Fast-DetectGPT and strictly improves on unweighted versions when models are distributionally close, with experiments confirming substantial detection accuracy increases.
What carries the argument
The Alignment Imprint, the decomposed log-likelihood ratio capturing preference discrepancies from alignment, which serves as the signal for zero-shot detection in the LAPD statistic.
If this is right
- Alignment-based statistics provably dominate Fast-DetectGPT in detection performance.
- LAPD strictly improves detection scores over unweighted alignment when aligned and base models are close in distribution.
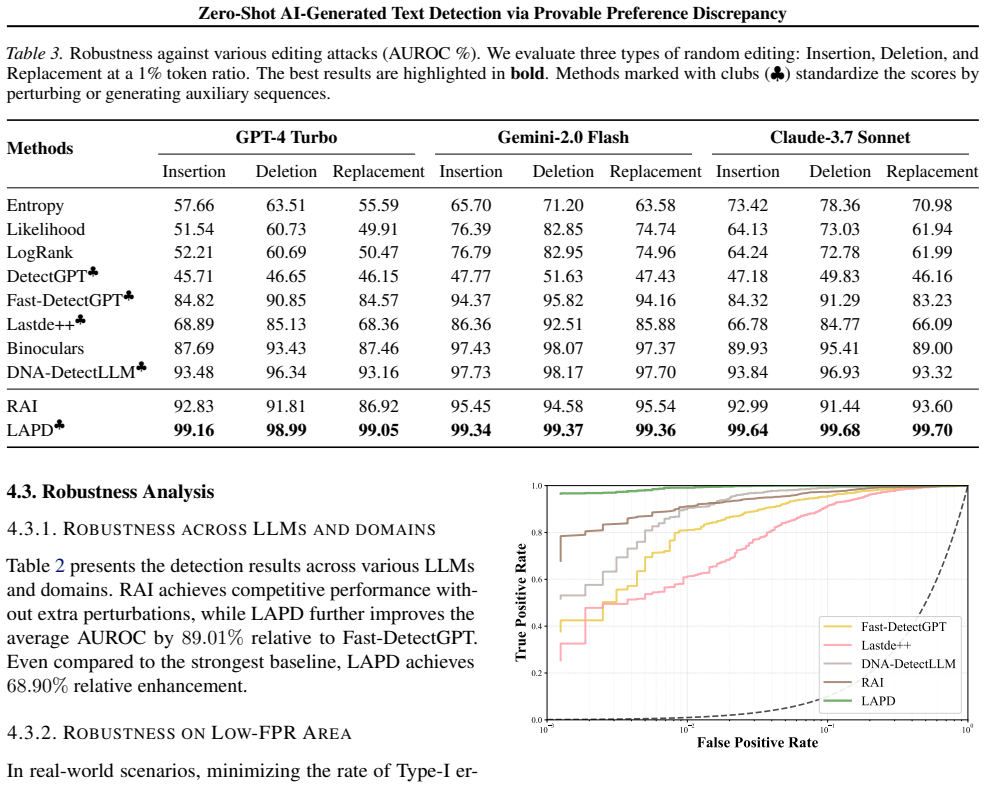
- The method yields consistent improvements of 45.82% relative to strongest baselines across diverse experimental settings.
- Detection becomes more stable in high-entropy content regions due to information weighting.
Where Pith is reading between the lines
- If alignment imprints are universal across tuning methods, this could inform the design of future LLMs to either enhance or obscure such signals for detection purposes.
- The approach might extend to detecting text from models fine-tuned on other tasks beyond alignment, such as domain-specific adaptations.
- A practical test would involve applying LAPD to emerging open-source models to verify if the performance gains hold as base and aligned distributions evolve.
Load-bearing premise
That the effects of alignment can be isolated as a clean decomposition of log-likelihood ratios into biases and rewards without other confounding factors in the training process.
What would settle it
Running LAPD and Fast-DetectGPT on a new set of LLMs and finding no consistent statistical superiority or relative improvement in detection accuracy would falsify the performance dominance claims.
Figures



read the original abstract
Detecting AI-generated text is an important but challenging problem. Existing likelihood-based detection methods are often sensitive to content complexity and may exhibit unstable performance. In this paper, our key insight is that modern Large Language Models (LLMs) undergo alignment (including fine-tuning and preference tuning), leaving a measurable distributional imprint. We theoretically derive this imprint by abstracting the alignment process as a sequence of constrained optimization steps, showing that the log-likelihood ratio can naturally decompose into implicit instructional biases and preference rewards. We refer to this quantity as the Alignment Imprint. Furthermore, to mitigate the instability in high-entropy regions, we introduce Log-likelihood Alignment Preference Discrepancy (LAPD), a standardized information-weighted statistic based on alignment imprint. We provide statistical guarantee that alignment-based statistics dominate Fast-DetectGPT in performance. We also theoretically show that LAPD strictly improves the unweighted alignment scores when the aligned and base models are close in distribution. Extensive experiments show that LAPD achieves an improvement 45.82% relative to the strongest existing baselines, yielding large and consistent gains across all settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modern LLMs leave a measurable 'Alignment Imprint' from alignment processes (fine-tuning and preference tuning). By abstracting alignment as a sequence of constrained optimization steps, the log-likelihood ratio is shown to decompose into instructional biases and preference rewards. The authors introduce LAPD, an information-weighted statistic based on this imprint, prove that alignment-based statistics dominate Fast-DetectGPT, prove that LAPD strictly improves unweighted scores when aligned and base models are close in distribution, and report a 45.82% empirical improvement over the strongest baselines across experiments.
Significance. If the decomposition and dominance theorems hold under standard alignment procedures, the work supplies a theoretically grounded alternative to purely empirical detectors, with the potential for more stable performance in high-entropy regions. The explicit attempt to derive performance guarantees from the alignment process itself is a positive step beyond ad-hoc likelihood ratios, and the reported relative gains are large enough to warrant follow-up if the modeling assumptions are validated.
major comments (2)
- [Alignment Imprint derivation (Section 3)] The central derivation abstracts alignment as constrained optimization steps whose solution yields an additive decomposition of the log-likelihood ratio into instructional biases and preference rewards. Standard RLHF (PPO) and DPO optimize a joint objective that includes KL regularization or pairwise preference losses; without an explicit reduction showing that the paper's bias and reward terms recover the same quantities under these objectives, the statistical dominance claim over Fast-DetectGPT and the strict-improvement theorem for LAPD lack grounding.
- [Theoretical analysis of LAPD (Section 4)] The strict-improvement theorem for LAPD over unweighted alignment scores is stated to hold when the aligned and base models are close in distribution. The paper should supply a quantitative bound on distributional distance (e.g., total variation or KL) together with an empirical verification that the models used in the experiments satisfy the bound; otherwise the theorem's applicability to real aligned LLMs remains unclear.
minor comments (3)
- [Abstract] The abstract states a 45.82% relative improvement but does not name the metric (AUROC, TPR@FPR, etc.) or the exact set of baselines; this information should appear in the abstract or be cross-referenced to the experimental table.
- [Experiments section] Experimental results should report standard deviations or confidence intervals across random seeds and multiple datasets to allow assessment of the consistency of the reported gains.
- [LAPD definition] Notation for the information-weighting term inside LAPD should be defined on first use and related explicitly to the entropy or variance of the token-level log-likelihoods.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which have helped us identify areas to strengthen the theoretical foundations of our work. We provide point-by-point responses below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Alignment Imprint derivation (Section 3)] The central derivation abstracts alignment as constrained optimization steps whose solution yields an additive decomposition of the log-likelihood ratio into instructional biases and preference rewards. Standard RLHF (PPO) and DPO optimize a joint objective that includes KL regularization or pairwise preference losses; without an explicit reduction showing that the paper's bias and reward terms recover the same quantities under these objectives, the statistical dominance claim over Fast-DetectGPT and the strict-improvement theorem for LAPD lack grounding.
Authors: We agree that explicitly connecting our general abstraction to the specific objectives in PPO and DPO would provide stronger grounding for the claims. In the revised manuscript, we will add a new subsection in Section 3 that derives the decomposition under the PPO objective (with KL regularization) and the DPO loss, demonstrating that the instructional bias and preference reward terms correspond to the key components of these standard alignment procedures, up to the regularization parameters. This will directly support the dominance and improvement theorems. revision: yes
-
Referee: [Theoretical analysis of LAPD (Section 4)] The strict-improvement theorem for LAPD over unweighted alignment scores is stated to hold when the aligned and base models are close in distribution. The paper should supply a quantitative bound on distributional distance (e.g., total variation or KL) together with an empirical verification that the models used in the experiments satisfy the bound; otherwise the theorem's applicability to real aligned LLMs remains unclear.
Authors: The strict-improvement result is indeed conditional on the aligned and base models being sufficiently close in distribution, as stated in the theorem. To make this more concrete, we will include a quantitative bound on the distributional distance (in terms of KL divergence) under which the improvement holds, derived from the proof technique. Furthermore, we will add an empirical analysis in the experiments section measuring the KL divergence or total variation between the base and aligned models for the LLMs used (e.g., Llama-2 base vs. aligned), confirming that the condition is satisfied in our experimental setup. This will validate the theorem's applicability. revision: yes
Circularity Check
No circularity; derivation proceeds from explicit modeling assumptions without self-referential reduction
full rationale
The paper's core chain abstracts alignment as constrained optimization steps to derive the log-likelihood decomposition into biases and rewards (Alignment Imprint), then defines LAPD and proves dominance/strict improvement under a stated closeness-in-distribution condition. These steps are conditional on the abstraction and assumptions rather than tautological; no equation reduces to a fitted parameter renamed as prediction, no self-citation chain bears the central claim, and no uniqueness theorem is imported from prior author work. The statistical guarantees follow directly from the modeled decomposition without looping back to the input data or outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Alignment process can be abstracted as a sequence of constrained optimization steps
- domain assumption Aligned and base models are close in distribution
invented entities (2)
-
Alignment Imprint
no independent evidence
-
LAPD
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Your language model can secretly write like humans: Contrastive paraphrase attacks on llm-generated text detectors
Fang, H., Kong, J., Zhuang, T., Qiu, Y ., Gao, K., Chen, B., Xia, S.-T., Wang, Y ., and Zhang, M. Your language model can secretly write like humans: Contrastive paraphrase attacks on llm-generated text detectors. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 8596–8613,
2025
-
[4]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
B., and Lapata, M
Narayan, S., Cohen, S. B., and Lapata, M. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. InProceed- ings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 1797–1807,
2018
-
[7]
URL https://www.kaggle.com/datasets/ spsayakpaul/arxiv-paper-abstracts. Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cap- pelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., and Launay, J. The refinedweb dataset for falcon llm: out- performing curated corpora with web data, and web data only.arXiv preprint arXiv:2306.01116,
work page internal anchor Pith review arXiv
-
[8]
Qing, C., Wu, J., Liu, Z., Qiu, Y ., Yu, H., Chen, B., Wu, H., and Xia, S.-T. C-red: A comprehensive chinese bench- mark for ai-generated text detection derived from real- world prompts.arXiv preprint arXiv:2604.11796,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Emma Strubell, Ananya Ganesh, and Andrew McCallum
Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert- V oss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., et al. Release strategies and the social impacts of language models.arXiv preprint arXiv:1908.09203,
-
[11]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Ghost- buster: Detecting text ghostwritten by large language models
Verma, V ., Fleisig, E., Tomlin, N., and Klein, D. Ghost- buster: Detecting text ghostwritten by large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 1702–1717,
2024
-
[13]
Moses: Uncertainty-aware ai-generated text detection via mixture of stylistics experts with conditional thresholds
Wu, J., Wang, J., Liu, Z., Chen, B., Hu, D., Wu, H., and Xia, S.-T. Moses: Uncertainty-aware ai-generated text detection via mixture of stylistics experts with conditional thresholds. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 5797–5816,
2025
-
[14]
A Survey of Large Language Models
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y ., Min, Y ., Zhang, B., Zhang, J., Dong, Z., et al. A survey of large language models.arXiv preprint arXiv:2303.18223,
-
[15]
Zhou, H., Zhu, J., Su, P., Ye, K., Yang, Y ., Gavioli-Akilagun, S. A., and Shi, C. Adadetectgpt: Adaptive detection of llm-generated text with statistical guarantees.arXiv preprint arXiv:2510.01268,
-
[16]
Zhu, X., Ren, Y ., Cao, Y ., Lin, X., Fang, F., and Li, Y . Reliably bounding false positives: A zero-shot machine- generated text detection framework via multiscaled con- formal prediction.arXiv preprint arXiv:2505.05084, 2025a. Zhu, X., Ren, Y ., Fang, F., Tan, Q., Wang, S., and Cao, Y . DNA-DetectLLM: Unveiling AI-generated text via a DNA-inspired muta...
-
[17]
Proofs To begin, we first present two technical assumptions, which is analogous to the setting introduced in (Zhou et al., 2025)
From this equation, we can write the optimal policyP ϕ∗(x)as: Pϕ∗(x) = 1 Z2 Pref(x) exp R(x) β .(20) Summing over allx ′: 1 = X x′ P ∗ ϕ(x′) = 1 Z2 X x′ Pref(x′) exp R(x′) β .(21) Then we obtain the constant Z2 = X x′ Pref(x′) exp R(x′) β .(22) B. Proofs To begin, we first present two technical assumptions, which is analogous to the setting introduced in ...
2025
-
[18]
However, this may not hold in real-world scenarios since human-written text tends to exhibit higher variance due to lexical and semantic diversity
basically requires the conditional variance of logits be asymptotically equivalent for human-written text and AI-generated text. However, this may not hold in real-world scenarios since human-written text tends to exhibit higher variance due to lexical and semantic diversity. In contrast, our Assumption 4 only requires the ratio of the sentence-level vari...
2025
-
[19]
as the scoring (reference) model for all baselines. For the perturbation (observer) model, Fast-DetectGPT, Lastde++, Binoculars, and DNA-DetectLLM utilize Falcon-7B (Penedo et al., 2023), while DetectGPT employs T5-3B (Raffel et al.,
2023
-
[20]
We primarily select models with approximately 7B parameters
All these models are open-sourced and can be downloaded from HuggingFace. We primarily select models with approximately 7B parameters. This consistency in model scale ensures that the observed performance variations are attributable to the detection methods themselves rather than differences in model capacity. Table 8.Details of the LLMs used. Model Model...
2023
-
[21]
The Multi-generator, Multi-domain, and Multi-lingual dataset is a large-scale benchmark for AI-generated text detection in black-box scenarios
M4(Wang et al., 2024). The Multi-generator, Multi-domain, and Multi-lingual dataset is a large-scale benchmark for AI-generated text detection in black-box scenarios. It contains human and AI texts across 7 domains and 7 languages. AI texts are generated by 6 model families, including GPT-4, ChatGPT and BLOOMz. DetectRL(Wu et al., 2024). This benchmark da...
2024
-
[22]
Existing methods generally exhibit poor performance under this strict metric: Fast-DetectGPT, Binoculars, and DNA- DetectLLM achieve average TPRs of51.79%,66.67%, and59.56%, respectively. On the contrary, RAI demonstrates performance comparable to the best baseline, while LAPD attains an average TPR of 92.27%, obtaining a substantial relative improvement ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.