Recognition: unknown
Training-inference input alignment outweighs framework choice in longitudinal retinal image prediction
Pith reviewed 2026-05-10 06:41 UTC · model grok-4.3
The pith
Training-inference input alignment produces larger gains in longitudinal retinal image prediction than the choice between stochastic and deterministic frameworks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
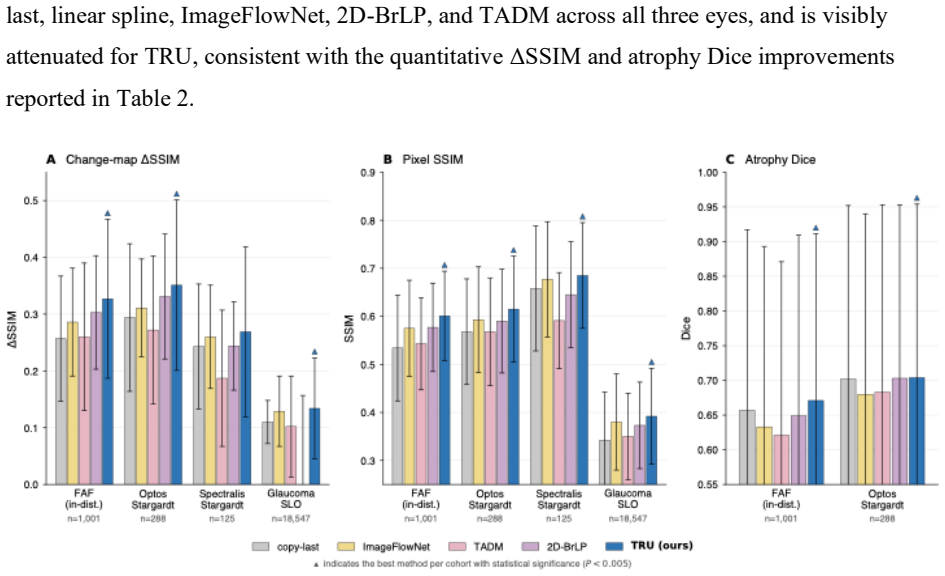
In longitudinal retinal imaging, training-inference input alignment produces large gains measured by delta-SSIM of +0.082 and SSIM of +0.086 (both p < 0.001), whereas the choice among aligned frameworks such as conditional diffusion, inference-aligned stochastic training, and deterministic regression produces no clinically meaningful differences. This equivalence occurs because inter-visit change in the FAF dataset is dominated by time-invariant acquisition variability rather than disease progression, causing stochastic model posteriors to collapse to effective points. A deterministic Temporal Retinal U-Net trained under aligned conditions matches or exceeds published baselines on delta-SSIM
What carries the argument
Training-inference input alignment, the practice of using identical conditioning configurations for past images in both training and inference phases so that the model learns consistent mappings from observed to future scans.
If this is right
- When disease progression is slow relative to acquisition variability, deterministic regression suffices and matches complex stochastic alternatives.
- Task-entropy analysis on image pairs and posterior-concentration analysis on stochastic models can indicate the complexity a prediction task warrants before model selection.
- A deterministic Temporal Retinal U-Net generalizes across three manufacturers, two modalities, and zero-shot to independent cohorts.
- Alignment yields consistent gains on SSIM, delta-SSIM, and PSNR independent of the underlying generative framework.
Where Pith is reading between the lines
- The same alignment principle could reduce computational cost in other longitudinal medical imaging tasks where technical variability masks slow biological change.
- Pre-deployment checks for posterior collapse could become routine to avoid unnecessary use of stochastic models.
- Datasets with faster disease progression would provide a natural test of the boundary at which generative complexity begins to add value.
Load-bearing premise
Inter-visit changes in the retinal dataset are driven mainly by consistent acquisition variability rather than actual disease progression.
What would settle it
A longitudinal retinal dataset in which measured disease progression produces larger image variation than acquisition artifacts, with stochastic models then showing statistically significant superiority over aligned deterministic regression on the same metrics.
Figures




read the original abstract
Predicting disease progression from longitudinal imaging is useful for clinical decision making and trial design. Recent methods have moved toward increasing generative complexity, but the conditions under which this complexity is necessary remain unclear. We propose that generative complexity should match the entropy of the predictable component of a task's conditional posterior, with training-inference input alignment required in all regimes. Two model-light measurements, a task-entropy analysis on raw image pairs and a posterior-concentration analysis on a stochastic model, let practitioners assess the complexity a task warrants before committing to a modeling framework. We validated this framework on a fundus autofluorescence (FAF) dataset by contrasting five conditioning configurations, sharing one architecture and training set, spanning standard conditional diffusion, inference-aligned stochastic training, and deterministic regression. Training-inference alignment produced large gains (delta-SSIM +0.082, SSIM +0.086, both p < 0.001), while the choice among aligned frameworks produced no clinically meaningful difference across evaluated metrics. Across two FAF platforms, inter-visit change was dominated by time-invariant acquisition variability rather than disease progression, and the stochastic models' posteriors collapsed to an effective point, explaining the framework equivalence. We trained a deterministic Temporal Retinal U-Net (TRU) and evaluated it on 28,899 eyes across three manufacturers and two modalities (two FAF platforms and en-face SLO), with three independent cohorts evaluated zero-shot. TRU matched or exceeded three published baselines on delta-SSIM, SSIM, and PSNR. These findings show that when disease progression is slow compared with acquisition variability, a deterministic regression model matches or outperforms more complex stochastic alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training-inference input alignment outweighs the choice of modeling framework (stochastic vs. deterministic) for longitudinal retinal image prediction. On a fundus autofluorescence (FAF) dataset, alignment yields large gains (delta-SSIM +0.082, SSIM +0.086, both p<0.001) while aligned frameworks show no clinically meaningful differences; this is attributed to inter-visit change being dominated by time-invariant acquisition variability rather than progression, as shown by posterior collapse and task-entropy analysis on raw pairs. A deterministic Temporal Retinal U-Net (TRU) matches or exceeds published baselines on delta-SSIM, SSIM, and PSNR across 28,899 eyes from three manufacturers and two modalities, with zero-shot evaluation on three independent cohorts.
Significance. If the central empirical findings hold, the work offers a practical, model-light heuristic (task-entropy and posterior-concentration checks) for deciding when deterministic regression suffices in medical imaging, which could simplify deployment in clinical decision support and trial design. The large multi-cohort scale and zero-shot testing provide strong empirical grounding; the explicit comparison of five conditioning configurations sharing architecture and training data is a clear strength.
major comments (2)
- [FAF dataset validation and posterior-concentration analysis] The claim that inter-visit change in the FAF dataset is dominated by time-invariant acquisition variability (rather than disease progression) is load-bearing for the conclusion that deterministic regression matches stochastic alternatives, yet it rests solely on internal observations of posterior collapse and task-entropy analysis without an external anchor such as clinical progression labels, longer time baselines, or a comparator modality with known faster progression.
- [Abstract and experimental evaluation] The reported metric improvements (delta-SSIM +0.082, SSIM +0.086, p<0.001) and framework equivalence are presented without details on data splits, exclusion criteria, or potential post-hoc configuration choices; this undermines confidence in the deltas and the cross-framework claim given the multi-cohort setup.
minor comments (2)
- [Methods] Clarify the precise computation of the task-entropy analysis on raw image pairs, including any preprocessing or distance metric used, to support reproducibility.
- [Evaluation] Add a brief description of the three independent cohorts (patient demographics, visit intervals, acquisition parameters) used for zero-shot evaluation.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the work's significance and for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [FAF dataset validation and posterior-concentration analysis] The claim that inter-visit change in the FAF dataset is dominated by time-invariant acquisition variability (rather than disease progression) is load-bearing for the conclusion that deterministic regression matches stochastic alternatives, yet it rests solely on internal observations of posterior collapse and task-entropy analysis without an external anchor such as clinical progression labels, longer time baselines, or a comparator modality with known faster progression.
Authors: We acknowledge that external anchors would provide additional support. Our evidence consists of direct measurements on the data: task-entropy computed on raw inter-visit image pairs quantifies the high variability present, while posterior-concentration analysis on the stochastic models shows collapse to near-point estimates. This is corroborated by the empirical equivalence of aligned deterministic and stochastic frameworks across metrics. We agree this interpretation would be strengthened by clinical labels or a faster-progression comparator, which are unavailable in the current multi-cohort datasets. We have added a limitations paragraph explicitly discussing reliance on these internal analyses. revision: partial
-
Referee: [Abstract and experimental evaluation] The reported metric improvements (delta-SSIM +0.082, SSIM +0.086, p<0.001) and framework equivalence are presented without details on data splits, exclusion criteria, or potential post-hoc configuration choices; this undermines confidence in the deltas and the cross-framework claim given the multi-cohort setup.
Authors: We thank the referee for noting this omission. Patient-level splits were used throughout to avoid leakage (approximately 70/15/15 train/validation/test), with exclusion criteria applied for image quality (e.g., low SNR or artifacts) and incomplete metadata; final cohort sizes are now tabulated. All five conditioning configurations shared the identical architecture, training procedure, and hyperparameter set, which were fixed before evaluation. We have expanded the Methods section with full split statistics, exclusion counts, and details of the paired statistical tests used for the reported deltas and p-values. revision: yes
Circularity Check
No circularity; central claims rest on direct empirical comparisons across held-out configurations
full rationale
The paper's derivation proceeds by proposing that generative complexity should match task-entropy of the conditional posterior, introducing two internal measurements (task-entropy on raw pairs, posterior-concentration on stochastic models), then validating via controlled experiments on five conditioning configurations that share architecture and training data. Key quantitative results (delta-SSIM +0.082, SSIM +0.086, p<0.001 for alignment; no meaningful difference among aligned frameworks) are obtained from held-out test metrics and statistical tests, not by algebraic reduction to fitted parameters or by renaming quantities defined during training. The interpretive claim that inter-visit change is dominated by time-invariant acquisition variability is supported by the same internal analyses plus observed posterior collapse, but this does not create a self-definitional loop or turn predictions into fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the provided text. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inter-visit change is dominated by time-invariant acquisition variability rather than disease progression
Reference graph
Works this paper leans on
-
[1]
R.W. Strauss, X. Kong, A. Ho, A. Jha, S. West, M. Ip, P.S. Bernstein, D.G. Birch, A.V. Cideciyan, M. Michaelides, J.-A. Sahel, J.S. Sunness, E.I. Traboulsi, E. Zrenner, S. Pitetta, D. Jenkins, A.H. Hariri, S. Sadda, H.P.N. Scholl, ProgStar Study Group, Progression of Stargardt Disease as Determined by Fundus Autofluorescence Over a 12-Month Period: ProgSt...
-
[2]
F.G. Holz, A. Bindewald-Wittich, M. Fleckenstein, J. Dreyhaupt, H.P.N. Scholl, S. Schmitz-Valckenberg, FAM-Study Group, Progression of geographic atrophy and impact of fundus autofluorescence patterns in age-related macular degeneration, Am J Ophthalmol 143 (2007) 463–472. https://doi.org/10.1016/j.ajo.2006.11.041
-
[3]
L. Dai, B. Sheng, T. Chen, Q. Wu, R. Liu, C. Cai, L. Wu, D. Yang, H. Hamzah, Y. Liu, X. Wang, Z. Guan, S. Yu, T. Li, Z. Tang, A. Ran, H. Che, H. Chen, Y. Zheng, J. Shu, S. Huang, C. Wu, S. Lin, D. Liu, J. Li, Z. Wang, Z. Meng, J. Shen, X. Hou, C. Deng, L. Ruan, F. Lu, M. Chee, T.C. Quek, R. Srinivasan, R. Raman, X. Sun, Y.X. Wang, J. Wu, H. Jin, R. Dai, D...
-
[4]
A. Salvi, J. Cluceru, S.S. Gao, C. Rabe, C. Schiffman, Q. Yang, A.Y. Lee, P.A. Keane, S.R. Sadda, F.G. Holz, D. Ferrara, N. Anegondi, Deep Learning to Predict the Future Growth of Geographic Atrophy from Fundus Autofluorescence, Ophthalmol Sci 5 (2025) 100635. https://doi.org/10.1016/j.xops.2024.100635
-
[5]
J. Yim, R. Chopra, T. Spitz, J. Winkens, A. Obika, C. Kelly, H. Askham, M. Lukic, J. Huemer, K. Fasler, G. Moraes, C. Meyer, M. Wilson, J. Dixon, C. Hughes, G. Rees, P.T. Khaw, A. Karthikesalingam, D. King, D. Hassabis, M. Suleyman, T. Back, J.R. Ledsam, P.A. Keane, J. De Fauw, Predicting conversion to wet age-related macular degeneration using deep learn...
-
[6]
B. Liefers, P. Taylor, A. Alsaedi, C. Bailey, K. Balaskas, N. Dhingra, C.A. Egan, F.G. Rodrigues, C.G. Gonzalo, T.F.C. Heeren, A. Lotery, P.L. Müller, A. Olvera-Barrios, B. Paul, R. Schwartz, D.S. Thomas, A.N. Warwick, A. Tufail, C.I. Sánchez, Quantification of Key Retinal Features in Early and Late Age-Related Macular Degeneration Using Deep Learning, Am...
-
[7]
J. Cluceru, N. Anegondi, S.S. Gao, A.Y. Lee, E.M. Lad, U. Chakravarthy, Q. Yang, V. Steffen, M. Friesenhahn, C. Rabe, D. Ferrara, Topographic Clinical Insights From Deep Learning-Based Geographic Atrophy Progression Prediction, Transl Vis Sci Technol 13 (2024) 6. https://doi.org/10.1167/tvst.13.8.6
-
[8]
Z. Mishra, Z. Wang, E. Xu, S. Xu, I. Majid, S.R. Sadda, Z.J. Hu, Recurrent and Concurrent Prediction of Longitudinal Progression of Stargardt Atrophy and Geographic Atrophy, (2024). https://doi.org/10.1101/2024.02.11.24302670
-
[9]
C. Liu, K. Xu, L.L. Shen, G. Huguet, Z. Wang, A. Tong, D. Bzdok, J. Stewart, J.C. Wang, L.V. Del Priore, S. Krishnaswamy, ImageFlowNet: Forecasting Multiscale Image-Level Trajectories of Disease Progression with Irregularly-Sampled Longitudinal Medical Images, in: ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing ...
-
[10]
D. Lachinov, A. Chakravarty, C. Grechenig, U. Schmidt-Erfurth, H. Bogunovic, Learning Spatio-Temporal Model of Disease Progression With NeuralODEs From Longitudinal Volumetric Data, IEEE Trans Med Imaging 43 (2024) 1165–1179. https://doi.org/10.1109/TMI.2023.3330576
-
[11]
M. Litrico, F. Guarnera, M.V. Giuffrida, D. Ravì, S. Battiato, TADM: Temporally-Aware Diffusion Model for Neurodegenerative Progression on Brain MRI, in: M.G. Linguraru, Q. Dou, A. Feragen, S. Giannarou, B. Glocker, K. Lekadir, J.A. Schnabel (Eds.), Medical Image Computing and Computer Assisted Intervention – MICCAI 2024, Springer Nature Switzerland, Cham...
-
[12]
L. Puglisi, D.C. Alexander, D. Ravì, Brain Latent Progression: Individual-based spatiotemporal disease progression on 3D Brain MRIs via latent diffusion, Medical Image Analysis 106 (2025) 103734. https://doi.org/10.1016/j.media.2025.103734
-
[13]
N.A. Disch, Y. Kirchhoff, R. Peretzke, M. Rokuss, S. Roy, C. Ulrich, D. Zimmerer, K. Maier-Hein, Temporal Flow Matching for Learning Spatio-Temporal Trajectories in 4D Longitudinal Medical Imaging, (2025). https://doi.org/10.48550/arXiv.2508.21580
-
[14]
H. Chen, R. Yin, Y. Chen, Q. Chen, C. Li, Learning Patient-Specific Disease Dynamics with Latent Flow Matching for Longitudinal Imaging Generation, (2025). https://doi.org/10.48550/ARXIV.2512.09185
-
[15]
J. Ho, A. Jain, P. Abbeel, Denoising Diffusion Probabilistic Models, Proceedings of the 34th International Conference on Neural Information Processing Systems, 574, Pages 6840 - 6851, (2020)
2020
-
[16]
M. Ning, M. Li, J. Su, A.A. Salah, I.O. Ertugrul, ELUCIDATING THE EXPOSURE BIAS IN DIFFUSION MODELS, (2024)
2024
-
[17]
G.-H. Liu, A. Vahdat, D.-A. Huang, E.A. Theodorou, W. Nie, A. Anandkumar, I2SB: Image-to-Image Schro¨dinger Bridge, Proceedings of the 40th International Conference on Machine Learning, 915, Pages 22042 - 22062, (2023)
2023
-
[18]
Bansal, E
A. Bansal, E. Borgnia, H.-M. Chu, J.S. Li, H. Kazemi, F. Huang, M. Goldblum, J. Geiping, T. Goldstein, Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise, Proceedings of the 37th International Conference on Neural Information Processing Systems, 1789, pages 41259–41282, (2023)
2023
-
[19]
arXiv preprint arXiv:2303.11435 , year=
M. Delbracio, P. Milanfar, Inversion by Direct Iteration: An Alternative to Denoising Diffusion for Image Restoration, (2024). https://doi.org/10.48550/arXiv.2303.11435
-
[20]
In: Medical Image Compu ting and Computer-Assisted Intervention – MICCAI 2015
O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional Networks for Biomedical Image Segmentation, in: N. Navab, J. Hornegger, W.M. Wells, A.F. Frangi (Eds.), Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Springer International Publishing, Cham, 2015: pp. 234–241. https://doi.org/10.1007/978-3-319-24574-4_28
-
[21]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is All you Need, Proceedings of the 31th International Conference on Neural Information Processing Systems, Pages 6000 - 6010, (2017)
2017
-
[22]
In: ECCV (2020).https://doi.org/10.1007/978-3-030-58452-8_24
B. Mildenhall, P.P. Srinivasan, M. Tancik, J.T. Barron, R. Ramamoorthi, R. Ng, NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12346. Springer, Cham. https://doi.org/10.1007/978-3-030-58452-8_24
-
[23]
S. Elfwing, E. Uchibe, K. Doya, Sigmoid-weighted linear units for neural network function approximation in reinforcement learning, Neural Networks 107 (2018) 3–11. https://doi.org/10.1016/j.neunet.2017.12.012
-
[24]
K. He, X. Zhang, S. Ren, J. Sun, Deep Residual Learning for Image Recognition, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Las Vegas, NV, USA, 2016: pp. 770–778. https://doi.org/10.1109/CVPR.2016.90
-
[25]
Progressive Distillation for Fast Sampling of Diffusion Models
T. Salimans, J. Ho, Progressive Distillation for Fast Sampling of Diffusion Models, (2022). https://doi.org/10.48550/arXiv.2202.00512
work page internal anchor Pith review doi:10.48550/arxiv.2202.00512 2022
-
[26]
J. Song, C. Meng, S. Ermon, DENOISING DIFFUSION IMPLICIT MODELS, (2021)
2021
-
[27]
Loshchilov, F
I. Loshchilov, F. Hutter, DECOUPLED WEIGHT DECAY REGULARIZATION, (2019)
2019
-
[28]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov, F. Hutter, SGDR: Stochastic Gradient Descent with Warm Restarts, (2017). https://doi.org/10.48550/arXiv.1608.03983
-
[29]
P. Tanna, R.W. Strauss, K. Fujinami, M. Michaelides, Stargardt disease: clinical features, molecular genetics, animal models and therapeutic options, Br J Ophthalmol 101 (2017) 25–30. https://doi.org/10.1136/bjophthalmol-2016-308823
-
[30]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Z. Wang, A.C. Bovik, H.R. Sheikh, E.P. Simoncelli, Image quality assessment: from error visibility to structural similarity, IEEE Trans Image Process 13 (2004) 600–612. https://doi.org/10.1109/tip.2003.819861
-
[31]
W.R. Crum, O. Camara, D.L.G. Hill, Generalized overlap measures for evaluation and validation in medical image analysis, IEEE Trans Med Imaging 25 (2006) 1451–1461. https://doi.org/10.1109/TMI.2006.880587
-
[32]
A.A. Taha, A. Hanbury, Metrics for evaluating 3D medical image segmentation: analysis, selection, and tool, BMC Med Imaging 15 (2015) 29. https://doi.org/10.1186/s12880-015- 0068-x
-
[33]
In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
R. Zhang, P. Isola, A.A. Efros, E. Shechtman, O. Wang, The Unreasonable Effectiveness of Deep Features as a Perceptual Metric, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, Salt Lake City, UT, 2018: pp. 586–595. https://doi.org/10.1109/CVPR.2018.00068
-
[34]
Y. Blau, T. Michaeli, The Perception-Distortion Tradeoff, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, Salt Lake City, UT, USA, 2018: pp. 6228–6237. https://doi.org/10.1109/CVPR.2018.00652
-
[35]
Auto-Encoding Variational Bayes
D.P. Kingma, M. Welling, Auto-Encoding Variational Bayes, (2022). https://doi.org/10.48550/arXiv.1312.6114
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.6114 2022
-
[36]
L. Zhang, A. Rao, M. Agrawala, Adding Conditional Control to Text-to-Image Diffusion Models, in: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Paris, France, 2023: pp. 3813–3824. https://doi.org/10.1109/ICCV51070.2023.00355
-
[37]
Available: https://dx.doi.org/10.1162/neco.1992.4.1.1
S. Geman, E. Bienenstock, R. Doursat, Neural Networks and the Bias/Variance Dilemma, Neural Computation 4 (1992) 1–58. https://doi.org/10.1162/neco.1992.4.1.1
-
[38]
J. Liu, X. Li, Q. Wei, J. Xu, D. Ding, Semi-Supervised Keypoint Detector and Descriptor for Retinal Image Matching, (2022). https://doi.org/10.48550/arXiv.2207.07932
-
[39]
D.G. Lowe, Distinctive Image Features from Scale-Invariant Keypoints, International Journal of Computer Vision 60 (2004) 91–110. https://doi.org/10.1023/B:VISI.0000029664.99615.94
-
[40]
Fischler, R.C
M.A. Fischler, R.C. Bolles, Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography, Commun. ACM 24 (1981) 381–
1981
-
[41]
https://doi.org/10.1145/358669.358692
-
[42]
L. Chen, Y. Zhao, M. Moradi, M. Eslami, M. Wang, T. Elze, N. Zebardast, Spatial Decomposition of Longitudinal RNFL Maps Reveals Distinct Modes of Glaucomatous Progression with Structure–Function and Genetic Signatures, (2026). https://doi.org/10.64898/2026.04.09.26350387. Figures Figure 1. Architecture of Temporal Retinal U-Net (TRU). (A) Registered longi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.