Recognition: unknown
DOSE: Data Selection for Multi-Modal LLMs via Off-the-Shelf Models
Pith reviewed 2026-05-10 06:14 UTC · model grok-4.3
The pith
Off-the-shelf pretrained models can filter multimodal data so that training on the selection matches or beats the full dataset on VQA and math tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Without any task-specific training, off-the-shelf pretrained models can assess text quality and image-text alignment to build a joint quality-alignment distribution. Adaptive weighted sampling from this distribution then selects informative samples while preserving long-tail diversity. Models trained on the resulting DOSE-filtered data match or surpass those trained on the complete dataset across standard VQA and math benchmarks.
What carries the argument
The joint quality-alignment distribution built from off-the-shelf model assessments, paired with adaptive weighted sampling to select informative yet diverse samples.
If this is right
- Models trained on DOSE-selected data match or surpass full-dataset performance on VQA and math benchmarks.
- The selection process maintains long-tail diversity in the data.
- No task-specific training of filtering models is required, reducing computational cost.
- The approach scales efficiently to large multimodal datasets.
Where Pith is reading between the lines
- General pretrained models appear to capture transferable signals for assessing data quality on new distributions.
- The method could extend to data selection in text-only or other multimodal settings.
- Using fewer but better samples may lower the environmental cost of training large models.
- Combining assessments from multiple off-the-shelf models could refine the selection further.
Load-bearing premise
Off-the-shelf pretrained models never exposed to the target data can reliably judge text quality and image-text alignment.
What would settle it
Training on the DOSE-filtered data and finding that VQA and math benchmark scores fall well below those from the full dataset would disprove the value of this selection.
Figures




read the original abstract
High-quality and diverse multimodal data are essential for improving vision-language models (VLMs), yet existing datasets often contain noisy, redundant, and poorly aligned samples. To address these problems, data filtering is commonly used to enhance the efficiency and performance of multimodal learning, but it introduces extra computational cost because filtering models are usually trained on the same data they are meant to screen. To reduce this cost, we study DOSE, which explores whether off-the-shelf pretrained models that have never seen the target data can be used to select training samples for larger and stronger multimodal models without any task-specific training. Even without fine-tuning, these models can effectively assess text quality and image-text alignment to guide data selection. Based on this, we build a joint quality-alignment distribution and apply adaptive weighted sampling to select informative samples while maintaining long-tail diversity. This approach enhances data diversity, enabling models trained on DOSE-filtered data to match or surpass those trained on the full dataset on standard VQA and math benchmarks. Extensive experiments demonstrate its effectiveness, efficiency, and scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DOSE, a data selection framework for training vision-language models (VLMs) that uses off-the-shelf pretrained models (never exposed to the target dataset) to compute zero-shot text-quality and image-text alignment scores. These scores form a joint distribution from which adaptive weighted sampling draws a subset intended to preserve diversity while removing noisy or misaligned samples. The central empirical claim is that VLMs trained on the DOSE-selected subset match or exceed the performance of models trained on the full original dataset on standard VQA and mathematical reasoning benchmarks.
Significance. If the results hold under rigorous controls, the approach would eliminate the need to train task-specific filtering models on the target data, lowering the computational barrier to high-quality multimodal data curation and offering a scalable way to handle redundancy and long-tail distributions in existing datasets.
major comments (2)
- [Experiments / Ablation studies] The headline claim—that off-the-shelf zero-shot scores can be used for adaptive sampling to produce a subset whose training utility equals or exceeds the full set—rests on the untested premise that these scores are sufficiently calibrated to downstream VQA/math utility. The manuscript should add a direct correlation analysis (e.g., between per-sample quality/alignment scores and either per-sample loss reduction or influence on final benchmark scores) in the experiments section to demonstrate that the selection criterion is predictive rather than merely correlated with generic data quality.
- [§4 (Results) and associated tables/figures] To isolate the benefit of the joint quality-alignment distribution and weighted sampling from simple data reduction, the paper must report performance of random subsampling at the exact same cardinality as the DOSE subset, together with multiple random seeds and error bars. Without these controls, it is impossible to rule out that any observed parity or improvement is an artifact of reduced dataset size or variance in training.
minor comments (2)
- [Abstract] The abstract states that 'extensive experiments demonstrate effectiveness' yet contains no numerical results, baseline names, or effect sizes; adding at least one key performance delta (with dataset size) would improve readability.
- [Method section] Clarify the precise functional form of the adaptive weighted sampling (including any temperature or normalization constants) and provide the explicit formula for the joint quality-alignment density.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comments point-by-point below and will update the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: The headline claim—that off-the-shelf zero-shot scores can be used for adaptive sampling to produce a subset whose training utility equals or exceeds the full set—rests on the untested premise that these scores are sufficiently calibrated to downstream VQA/math utility. The manuscript should add a direct correlation analysis (e.g., between per-sample quality/alignment scores and either per-sample loss reduction or influence on final benchmark scores) in the experiments section to demonstrate that the selection criterion is predictive rather than merely correlated with generic data quality.
Authors: We agree that a direct correlation analysis would strengthen the evidence that our zero-shot scores are predictive of downstream utility rather than merely reflecting generic data quality. While the end-to-end results in the current manuscript demonstrate the effectiveness of DOSE subsets, we have not reported per-sample correlations. In the revised version, we will add this analysis in the experiments section, including Pearson correlations between the quality/alignment scores and per-sample loss reductions on a held-out set, plus feasible approximations to influence where computationally tractable. revision: yes
-
Referee: To isolate the benefit of the joint quality-alignment distribution and weighted sampling from simple data reduction, the paper must report performance of random subsampling at the exact same cardinality as the DOSE subset, together with multiple random seeds and error bars. Without these controls, it is impossible to rule out that any observed parity or improvement is an artifact of reduced dataset size or variance in training.
Authors: We concur that random subsampling controls at identical cardinality are necessary to isolate the contribution of the joint distribution and adaptive weighting. The revised manuscript will include these baselines in §4 and associated tables/figures, reporting results averaged over multiple random seeds (e.g., 5) with standard error bars to quantify training variance and confirm that observed performance is not an artifact of dataset size. revision: yes
Circularity Check
No circularity: purely empirical selection via external off-the-shelf models
full rationale
The paper describes DOSE as an empirical data-filtering pipeline that applies zero-shot quality and alignment scoring from pretrained models never exposed to the target dataset, followed by adaptive weighted sampling. No equations, parameter fitting, self-definitional loops, or load-bearing self-citations appear in the derivation. Claims of matching or surpassing full-dataset performance rest on downstream benchmark experiments rather than reducing to the input scores by construction. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Instructblip: Towards general-purpose vision- language models with instruction tuning.CoRR, abs/2305.06500. Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev, and Vaishaal Shankar
work page internal anchor Pith review arXiv
-
[2]
arXiv preprint arXiv:2309.17425 (2023) 3, 4, 9, 11, 20, 21, 22
Data filtering networks.arXiv preprint arXiv:2309.17425. Meng Fang, Yuan Li, and Trevor Cohn. 2017. Learning how to active learn: A deep reinforcement learning approach. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 595–605, Copenhagen, Denmark. Association for Computational Linguistics. Vitaly Feldman and...
-
[3]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Mme: A comprehensive evaluation benchmark for multimodal large language models.Preprint, arXiv:2306.13394. Jiahui Gao, Renjie Pi, Yong Lin, Hang Xu, Jiacheng Ye, Zhiyong Wu, Weizhong Zhang, Xiaodan Liang, Zhenguo Li, and Lingpeng Kong. 2023. Self-guided noise-free data generation for efficient zero-shot learning. InThe Eleventh International Conference on...
work page internal anchor Pith review arXiv 2023
-
[4]
D2 pruning: Message passing for balancing diversity and difficulty in data pruning
D2 pruning: Message passing for balancing di- versity and difficulty in data pruning.arXiv preprint arXiv:2310.07931. Anas Mahmoud, Mostafa Elhoushi, Amro Abbas, Yu Yang, Newsha Ardalani, Hugh Leather, and Ari Morcos. 2023. Sieve: Multimodal dataset prun- ing using image captioning models.arXiv preprint arXiv:2310.02110. Pratyush Maini, Sachin Goyal, Zach...
-
[5]
Eric Nalisnick, Akihiro Matsukawa, Yee Whye Teh, Dilan Gorur, and Balaji Lakshminarayanan
Scaling data-constrained language models. arXiv preprint arXiv:2305.16264. Thao Nguyen, Samir Yitzhak Gadre, Gabriel Ilharco, Sewoong Oh, and Ludwig Schmidt. 2023. Improv- ing multimodal datasets with image captioning.Ad- vances in Neural Information Processing Systems, 36:22047–22069. OpenAI. 2023. Gpt-4 technical report.Preprint, arXiv:2303.08774. Mansh...
-
[6]
How to train data-efficient llms.arXiv preprint arXiv:2402.09668, 2024
How to train data-efficient llms.arXiv preprint arXiv:2402.09668. Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, and Roy Ka-Wei Lee. 2024. Math-LLaV A: Bootstrapping mathemati- cal reasoning for multimodal large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4663–4680, Mi...
-
[7]
Too large; data reduction for vision-language pre-training.arXiv preprint arXiv:2305.20087. Baode Wang, Biao Wu, Weizhen Li, Meng Fang, Zuming Huang, Jun Huang, Haozhe Wang, Yanjie Liang, Ling Chen, Wei Chu, and 1 others. 2025. Infinity parser: Layout aware reinforcement learn- ing for scanned document parsing.arXiv preprint arXiv:2506.03197. Kai Wei, Ris...
-
[8]
C Time Cost Analysis Figure 3 presents a joint analysis of model perfor- mance and wall-clock cost across different data selection strategies
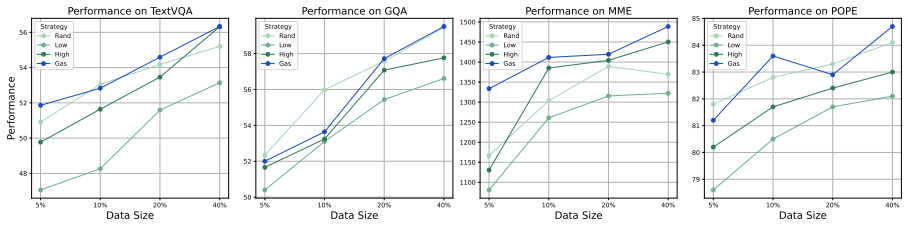
The WRS sampling distribution shows a pro- nounced concentration in regions with higher CLIP and Text-Quality Scores, effectively validating our strategy for assessing data quality and demonstrat- ing the benefits of our sampling approach. C Time Cost Analysis Figure 3 presents a joint analysis of model perfor- mance and wall-clock cost across different d...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.