Recognition: unknown
BIASEDTALES-ML: A Multilingual Dataset for Analyzing Narrative Attribute Distributions in LLM-Generated Stories
Pith reviewed 2026-05-10 06:49 UTC · model grok-4.3
The pith
LLM-generated children's stories show different narrative attribute distributions across languages, and English patterns do not generalize.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
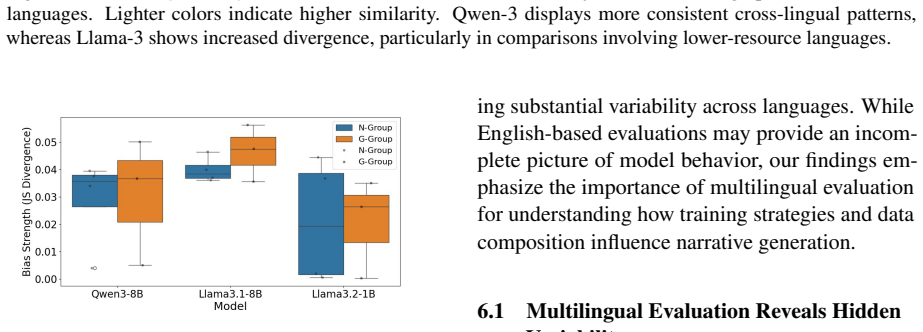
We present BiasedTales-ML, a large-scale parallel corpus of approximately 350,000 children's stories generated across eight typologically and culturally diverse languages using a full-permutation prompting design. We propose a structured generator-extractor pipeline and a multi-dimensional distributional analysis framework to examine how narrative attributes vary across languages, models, and social conditions. Our analysis reveals substantial cross-lingual variability in narrative generation patterns, indicating that distributions observed in English do not always exhibit similar characteristics in other languages, particularly in lower-resource settings. At the narrative level, we identify
What carries the argument
The full-permutation prompting design paired with a generator-extractor pipeline that produces and analyzes the multilingual story corpus for attribute distributions.
If this is right
- Distributions of narrative attributes in English do not match those in other languages.
- Lower-resource languages display distinct characteristics in generated stories.
- Recurring structural patterns in character roles, settings, and themes manifest differently by linguistic context.
- English-centric evaluation is insufficient for characterizing socially grounded narrative generation.
Where Pith is reading between the lines
- Alignment methods tuned on English data may leave language-specific biases unaddressed in non-English outputs.
- The released dataset allows direct tests of whether particular models or prompt strategies reduce cross-language differences.
- The approach could extend to measuring how cultural context beyond language affects LLM story generation.
Load-bearing premise
The full-permutation prompting design combined with the generator-extractor pipeline produces comparable and unbiased attribute extractions across typologically diverse languages without language-specific artifacts or model training data influences.
What would settle it
A replication using the same dataset but alternative extraction methods or different LLMs that finds identical attribute distributions across all eight languages would falsify the claim of substantial cross-lingual variability.
Figures











read the original abstract
Large Language Models (LLMs) are increasingly used to generate narrative content, including children's stories, which play an important role in social and cultural learning. Despite growing interest in AI safety and alignment, most existing evaluations focus primarily on English, leaving the cross-lingual generalization of aligned behavior underexplored. In this work, we introduce BiasedTales-ML, a large-scale parallel corpus of approximately 350,000 children's stories generated across eight typologically and culturally diverse languages using a full-permutation prompting design. We propose a structured generator-extractor pipeline and a multi-dimensional distributional analysis framework to examine how narrative attributes vary across languages, models, and social conditions. Our analysis reveals substantial cross-lingual variability in narrative generation patterns, indicating that distributions observed in English do not always exhibit similar characteristics in other languages, particularly in lower-resource settings. At the narrative level, we identify recurring structural patterns involving character roles, settings, and thematic emphasis, which manifest differently across linguistic contexts. These findings highlight the limitations of English-centric evaluation for characterizing socially grounded narrative generation in multilingual settings. We release the dataset, code, and an interactive visualization tool to support future research on multilingual narrative analysis and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BiasedTales-ML, a parallel corpus of approximately 350,000 LLM-generated children's stories across eight typologically diverse languages, constructed via a full-permutation prompting design. It describes a generator-extractor pipeline to extract narrative attributes (character roles, settings, themes) and applies a multi-dimensional distributional analysis framework, revealing substantial cross-lingual variability in generation patterns and arguing that English-centric distributions do not generalize, especially in lower-resource languages. The manuscript releases the dataset, code, and an interactive visualization tool.
Significance. If the variability findings are robust, the work would be significant for multilingual NLP and AI safety research by providing evidence against assuming English narrative distributions generalize and by supplying a large-scale resource for studying cultural and linguistic biases in generated stories. The public release of the dataset, code, and visualization tool is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- The headline claim of substantial cross-lingual variability in narrative attribute distributions (abstract and analysis framework) rests on the generator-extractor pipeline producing comparable, unbiased extractions across all eight languages. No per-language validation metrics, human evaluation, inter-annotator agreement, or error analysis for the extractor is described, leaving open the possibility that observed shifts in lower-resource languages reflect LLM extractor artifacts rather than generation differences.
- The abstract states that the analysis 'reveals substantial cross-lingual variability' and identifies 'recurring structural patterns' but provides no quantitative results, statistical tests, effect sizes, or tables summarizing the distributional differences. This weakens support for the central claim that English observations 'do not always exhibit similar characteristics' in other languages.
minor comments (1)
- The abstract refers to 'approximately 350,000' stories but does not break down the count by language, model, or condition; adding this detail would clarify the balance and scale of the parallel corpus.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript introducing BiasedTales-ML. We address each major comment below in detail, indicating planned revisions to strengthen the work while maintaining fidelity to our original contributions and resource constraints.
read point-by-point responses
-
Referee: The headline claim of substantial cross-lingual variability in narrative attribute distributions (abstract and analysis framework) rests on the generator-extractor pipeline producing comparable, unbiased extractions across all eight languages. No per-language validation metrics, human evaluation, inter-annotator agreement, or error analysis for the extractor is described, leaving open the possibility that observed shifts in lower-resource languages reflect LLM extractor artifacts rather than generation differences.
Authors: We appreciate the referee's emphasis on methodological rigor for the extractor. The manuscript describes a structured generator-extractor pipeline using consistent prompting across languages to promote comparability, but we acknowledge that it does not report per-language validation metrics, human evaluation, or inter-annotator agreement. In the revision, we will add a dedicated error analysis subsection that samples stories from each of the eight languages, reports extraction consistency metrics where feasible, and discusses potential artifacts. This will provide additional evidence that the observed distributional shifts reflect generation patterns rather than extractor issues. Full-scale human annotation across the entire corpus remains impractical given the scale (approximately 350,000 stories), but the added analysis will address the core concern. revision: partial
-
Referee: The abstract states that the analysis 'reveals substantial cross-lingual variability' and identifies 'recurring structural patterns' but provides no quantitative results, statistical tests, effect sizes, or tables summarizing the distributional differences. This weakens support for the central claim that English observations 'do not always exhibit similar characteristics' in other languages.
Authors: The abstract is intentionally concise to summarize the contribution and cannot accommodate full quantitative details. The main manuscript presents the multi-dimensional distributional analysis with figures, comparative tables, and descriptions of variability across languages, models, and conditions. To directly address this point, we will revise the abstract to include a brief mention of key quantitative highlights (e.g., specific percentage differences in character role distributions between English and lower-resource languages, along with reference to statistical comparisons). This will better foreground the evidence for the central claim without exceeding typical abstract length limits. revision: yes
Circularity Check
No significant circularity: empirical distributions from new multilingual corpus
full rationale
The paper constructs a new parallel corpus of ~350k LLM-generated children's stories across eight languages via full-permutation prompting, applies an LLM-based generator-extractor pipeline to label narrative attributes (roles, settings, themes), and reports observed distributional differences. All central claims about cross-lingual variability rest on direct computation of empirical frequencies and patterns in this freshly generated data rather than any parameter fitting, self-citation chains, uniqueness theorems, or renamings that would reduce the reported results to the inputs by construction. No equations, ansatzes, or load-bearing citations to prior author work appear in the derivation; the analysis framework simply tabulates and compares attribute counts across language/model conditions on the released dataset.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Systematic prompting of LLMs can surface stable narrative attribute distributions that reflect model behavior across languages
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
BedtimeStory.ai. 2023. https://bedtimestory.ai AI Powered Story Creator Bedtimestory .ai
2023
-
[3]
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610--623
2021
-
[4]
Su Lin Blodgett, Solon Barocas, Hal Daum \'e III, and Hanna Wallach. 2020. https://doi.org/10.18653/v1/2020.acl-main.485 Language (technology) is power: A critical survey of `` bias '' in NLP . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5454--5476, Online. Association for Computational Linguistics
-
[5]
Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183--186
2017
-
[6]
Victoria Cooper. 2014. Children’s developing identity. A critical companion to early childhood, pages 281--296
2014
- [7]
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
-
[10]
Nicole Kobie. 2023. https://www.wired.com/story/bluey-gpts-bedtime-stories-artificial-intelligence-copyright/ AI Is Telling Bedtime Stories to Your Kids Now . Wired. Section: tags
2023
-
[11]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data. biometrics, pages 159--174
1977
-
[12]
Jianhua Lin. 2002. Divergence measures based on the shannon entropy. IEEE Transactions on Information theory, 37(1):145--151
2002
-
[13]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634
work page internal anchor Pith review arXiv 2023
-
[14]
Li Lucy and David Bamman. 2021. Gender and representation bias in gpt-3 generated stories. In Proceedings of the third workshop on narrative understanding, pages 48--55
2021
-
[15]
Kristian Lum, Jacy Reese Anthis, Kevin Robinson, Chirag Nagpal, and Alexander Nicholas D'Amour. 2025. https://aclanthology.org/2025.acl-long.7/ Bias in language models: Beyond trick tests and towards ruted evaluation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Aust...
2025
-
[16]
Yingfeng Luo, Ziqiang Xu, Yuxuan Ouyang, Murun Yang, Dingyang Lin, Kaiyan Chang, Tong Zheng, Bei Li, Peinan Feng, Quan Du, Tong Xiao, and Jingbo Zhu. 2025. https://doi.org/10.48550/ARXIV.2511.07003 Beyond english: Toward inclusive and scalable multilingual machine translation with llms . CoRR, abs/2511.07003
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.07003 2025
-
[17]
Burt L Monroe, Michael P Colaresi, and Kevin M Quinn. 2008. Fightin'words: Lexical feature selection and evaluation for identifying the content of political conflict. Political Analysis, 16(4):372--403
2008
- [18]
-
[19]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
- [20]
- [21]
-
[22]
Donya Rooein, Vil \' e m Zouhar, Debora Nozza, and Dirk Hovy. 2025. https://doi.org/10.48550/ARXIV.2509.07908 Biased tales: Cultural and topic bias in generating children's stories . CoRR, abs/2509.07908
- [23]
-
[24]
Spriha Srivastava. 2023. https://www.businessinsider.com/i-use-chatgpt-write-bedtime-stories-my-5-year-old-2023-4 I use ChatGPT to write stories for my 5-year-old. It 's fun, innovative, and makes bedtime less stressful
2023
-
[25]
Qwen Team. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems, 36:80079--80110
2023
-
[27]
Zheng-Xin Yong, Beyza Ermis, Marzieh Fadaee, Stephen Bach, and Julia Kreutzer. 2025. The state of multilingual llm safety research: From measuring the language gap to mitigating it. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15856--15871
2025
-
[28]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595--46623
2023
-
[29]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[30]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.