Recognition: unknown
RLM-on-KG: Heuristics First, LLMs When Needed: Adaptive Retrieval Control over Mention Graphs for Scattered Evidence
Pith reviewed 2026-05-10 06:22 UTC · model grok-4.3
The pith
LLM control for graph retrieval outperforms heuristics mainly when evidence is scattered across chunks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
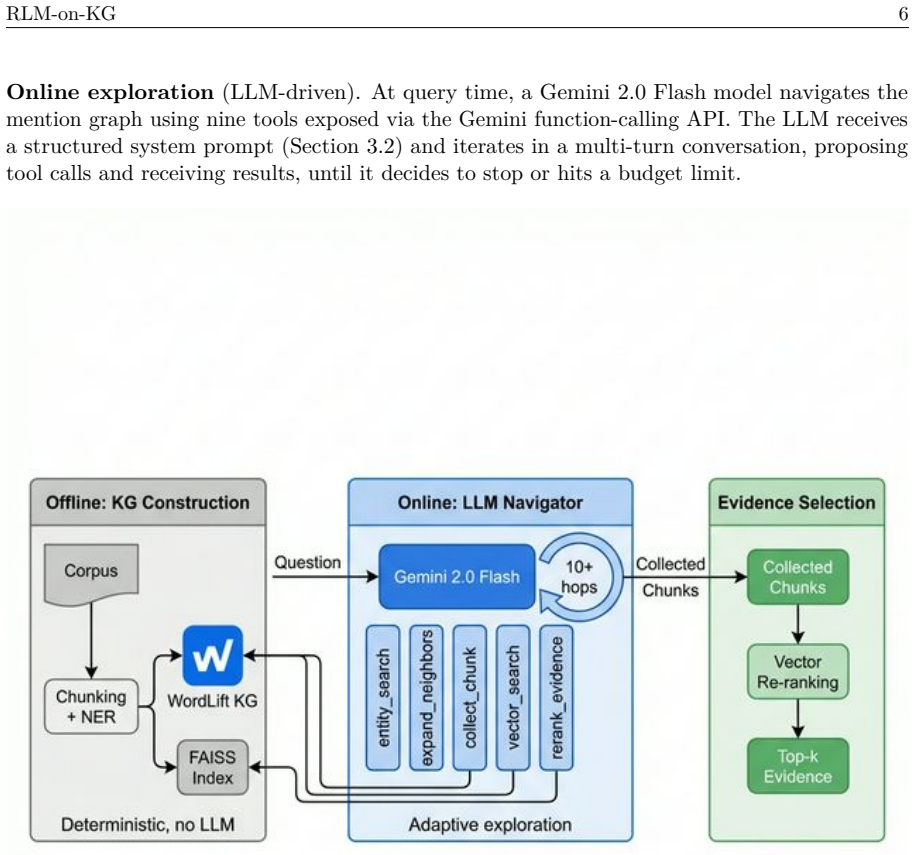
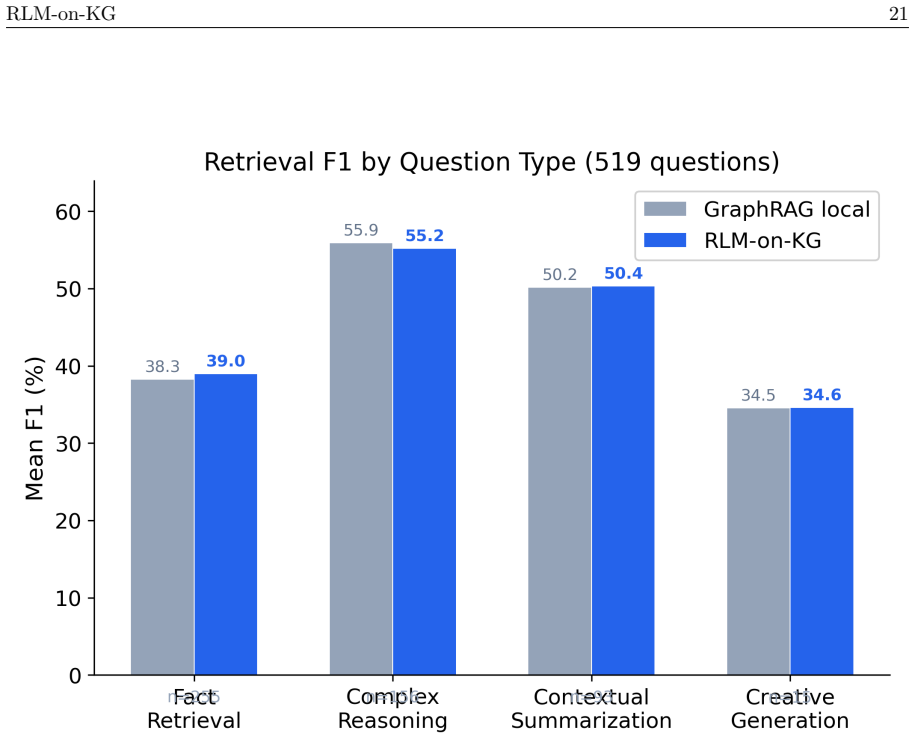
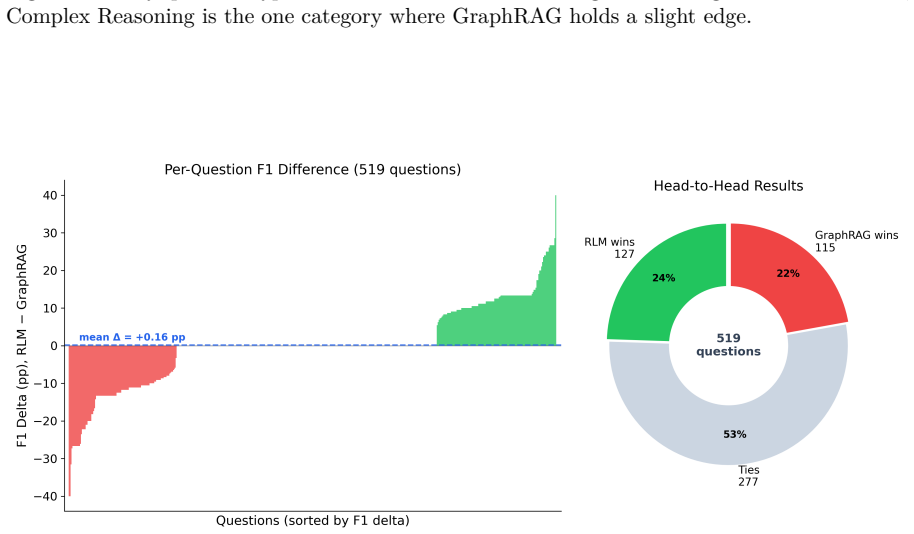
RLM-on-KG performs entity-first multi-hop exploration at query time over a deterministically built RDF mention graph using a fixed tool set and an LLM controller. On 519 questions from GraphRAG-Bench Novel, Gemini 2.0 Flash raises F1 by 2.47 points over a rule-based heuristic baseline but shows no meaningful gain over a GraphRAG-local variant; Claude Haiku 4.5 widens the heuristic gap to 4.37 points and the GraphRAG-local gap to 2.42 points. Largest improvements occur when gold evidence spans 6-10 chunks; the pattern transfers to MuSiQue with expected attenuation on smaller graphs. The architecture separates LLM-driven breadth in discovery from vector re-ranking for selection, and the traces
What carries the argument
RLM-on-KG, a query-time system that lets an LLM autonomously navigate an RDF-encoded mention graph via a fixed tool set while separating candidate discovery from final vector re-ranking.
If this is right
- The largest gains appear for questions whose gold evidence spans 6-10 chunks.
- Stronger controllers widen the advantage to statistically significant levels against both heuristics and GraphRAG-local variants.
- The LLM-over-heuristic edge transfers to MuSiQue though the absolute lift shrinks with smaller per-question graphs.
- Exploration traces can diagnose coverage, connectivity, provenance, and queryability of the underlying structured data.
- Final evidence selection is best left to vector re-ranking after LLM-guided discovery.
Where Pith is reading between the lines
- Retrieval systems could predict scatter level in advance and route queries to LLM control or pure heuristics accordingly.
- For low-scatter queries, investing in richer graph construction may close performance gaps more effectively than upgrading the controller.
- The conditional-control pattern could be tested on other structured-data retrieval tasks beyond mention graphs.
- Varying the size or quality of the fixed tool set would reveal whether more tools amplify or reduce the LLM advantage.
Load-bearing premise
The chosen rule-based heuristic and GraphRAG-local baselines represent fair non-LLM performance without hidden advantages from prompt engineering or graph construction quality.
What would settle it
Running the same 519-question benchmark with an improved adaptive heuristic or on a new collection where evidence scatter is controlled and finding no statistically significant F1 difference would falsify the conditional advantage.
Figures






read the original abstract
When does an LLM controller outperform rule-based traversal for knowledge graph exploration? We study this question through RLM-on-KG, a retrieval system that treats an LLM as an autonomous navigator over an RDF-encoded mention graph for grounded question answering. Unlike GraphRAG pipelines that rely on offline LLM indexing, RLM-on-KG performs entity-first, multi-hop exploration at query time using deterministic graph construction and a fixed tool set. Our central finding is a conditional advantage: the value of LLM control depends on evidence scatter and tool-calling sophistication. The paper's core claim is LLM control versus heuristic traversal, not a generic win over GraphRAG. On GraphRAG-Bench Novel (519 questions), Gemini 2.0 Flash achieves +2.47 pp F1 over a rule-based heuristic baseline (p < 0.0001), but only +0.16 pp over a GraphRAG-local variant (not significant). With a stronger controller, Claude Haiku 4.5, the gain over heuristic grows to +4.37 pp (p < 0.001) and extends to a +2.42 pp significant improvement over GraphRAG-local (p < 0.001). The gain is largest when gold evidence is scattered across 6-10 chunks (+3.21 pp) and smallest for concentrated evidence (+1.85 pp). Cross-scale validation on MuSiQue confirms that the LLM-over-heuristic advantage transfers, with expected attenuation on smaller per-question graphs. The core architectural insight is the separation of candidate discovery from ranking: the LLM adds value through exploration breadth, while final evidence selection is best handled by pure vector re-ranking. Beyond retrieval, exploration traces provide a proposed stress-test harness for structured data quality, yielding diagnostics for coverage, connectivity, provenance, and queryability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RLM-on-KG, a retrieval system that uses an LLM as an autonomous navigator over an RDF-encoded mention graph for grounded QA. It performs entity-first, multi-hop exploration at query time with deterministic graph construction and a fixed tool set, contrasting this against rule-based heuristics and GraphRAG-local variants. The central claim is a conditional advantage: LLM control yields statistically significant F1 gains (e.g., +2.47 pp for Gemini 2.0 Flash on 519 GraphRAG-Bench Novel questions, p<0.0001; larger +4.37 pp for Claude) that are most pronounced for scattered evidence (6-10 chunks) and transfer to MuSiQue, while final ranking is best left to vector methods. Exploration traces are proposed as a diagnostic harness for graph quality.
Significance. If the empirical comparisons hold under matched baselines, the work provides concrete evidence that adaptive LLM navigation adds exploration value primarily under high evidence scatter, supporting hybrid 'heuristics-first' designs rather than blanket LLM use. The cross-scale validation and stress-test harness for coverage/connectivity are useful contributions to KGQA and IR retrieval literature.
major comments (2)
- [Results / GraphRAG-Bench Novel experiments] The post-hoc stratification of performance by gold-label evidence scatter (6-10 chunks) does not demonstrate that the LLM controller can detect or act on scatter at inference time. This is load-bearing for the conditional-advantage claim in the abstract and results; without an oracle-free scatter estimator or runtime adaptation test, the +3.21 pp gain cannot be attributed to LLM control rather than post-selection.
- [Baselines and experimental setup] The rule-based heuristic baseline's exact traversal policy, stopping criteria, state representation, and tool-invocation logic are insufficiently specified to confirm equivalence with the LLM controller's access. The reported +2.47 pp F1 (and +4.37 pp with Claude) over this baseline could reflect differences in prompting richness or adaptive depth rather than architectural superiority; the GraphRAG-local variant must also be shown to use identical mention-graph construction, entity linking, and edge weighting.
minor comments (3)
- [Experimental details] Provide full details on data splits, exact graph construction procedure, prompt templates, and statistical test implementation (including multiple-comparison correction) to support the reported p-values.
- [Methods] Clarify whether the deterministic graph construction and fixed tool set are identical across all compared systems; any divergence would confound the attribution of gains to LLM control.
- [Results] The abstract states gains are 'largest when gold evidence is scattered across 6-10 chunks'; include the per-bin sample sizes and confidence intervals to allow readers to assess effect stability.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below with the strongest honest defense of the manuscript, proposing revisions to clarify claims and improve reproducibility where needed.
read point-by-point responses
-
Referee: [Results / GraphRAG-Bench Novel experiments] The post-hoc stratification of performance by gold-label evidence scatter (6-10 chunks) does not demonstrate that the LLM controller can detect or act on scatter at inference time. This is load-bearing for the conditional-advantage claim in the abstract and results; without an oracle-free scatter estimator or runtime adaptation test, the +3.21 pp gain cannot be attributed to LLM control rather than post-selection.
Authors: We acknowledge that the stratification by gold evidence scatter is post-hoc and does not include an explicit oracle-free scatter estimator or a dedicated runtime adaptation test. The LLM controller makes decisions adaptively at inference time using only the query and the evolving graph state (no gold labels). The larger observed gains in high-scatter regimes indicate that the adaptive policy yields greater benefit precisely when more exploration is required, compared to fixed heuristics. To strengthen attribution without overclaiming, we will revise the abstract and results to frame the conditional advantage as an observed property of the LLM policy under varying evidence distributions (rather than proven runtime detection of scatter). We will also add an analysis correlating the controller's exploration depth, hop count, and stopping decisions with inference-time proxies for scatter (e.g., initial entity set size and graph connectivity metrics). This is a partial revision focused on enhanced diagnostics. revision: partial
-
Referee: [Baselines and experimental setup] The rule-based heuristic baseline's exact traversal policy, stopping criteria, state representation, and tool-invocation logic are insufficiently specified to confirm equivalence with the LLM controller's access. The reported +2.47 pp F1 (and +4.37 pp with Claude) over this baseline could reflect differences in prompting richness or adaptive depth rather than architectural superiority; the GraphRAG-local variant must also be shown to use identical mention-graph construction, entity linking, and edge weighting.
Authors: We agree that insufficient specification of the heuristic baseline risks confounding the comparison. In the revised manuscript we will expand the baseline description (Section 4) to detail the exact traversal policy (e.g., priority ordering by relation type and entity degree), stopping criteria (maximum hops or exhaustion of new entities), state representation (current visited entity set plus accumulated relations), and tool-invocation logic, confirming identical tool access and graph interface as the LLM controller. We will also explicitly document and verify that the GraphRAG-local variant uses the identical deterministic mention-graph construction, entity linking, and edge-weighting pipeline as RLM-on-KG. These additions will ensure matched conditions and support the architectural claims. revision: yes
Circularity Check
No circularity: empirical performance deltas measured against fixed external baselines
full rationale
The manuscript reports measured F1 differences (+2.47 pp Gemini, +4.37 pp Claude) between an LLM controller and two fixed baselines (rule-based heuristic, GraphRAG-local) on GraphRAG-Bench Novel (519 questions) and MuSiQue. No equations, fitted parameters, or derivations appear; the central claim is a direct empirical comparison whose inputs (deterministic graph construction, fixed tool set, gold-evidence scatter bins) are stated independently of the output deltas. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the architecture or results. The reported conditional advantage is therefore a measured outcome rather than a reduction to the paper's own definitions or prior outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Statistical significance testing (p-values) is appropriate and correctly applied to the F1 comparisons
Reference graph
Works this paper leans on
-
[1]
• Buehler, M. J. (2024). Accelerating Scientific Discovery with Generative Knowledge Extraction, Graph-Based Representation, and Multimodal Intelligent Graph Reasoning. arXiv:2403.11996. • Carbonell, J. and Goldberg, J. (1998). The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries. SIGIR
-
[2]
• Edge, D. et al. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130. • GraphWalks (2025). GraphWalks: A Benchmark for Long-Context Graph Reasoning. OpenAI, github.com/openai/graphwalks. Released alongside GPT-4.1, April
work page internal anchor Pith review arXiv 2024
-
[3]
• Guo, Z. et al. (2025). LightRAG: Simple and Fast Retrieval-Augmented Generation. Findings of EMNLP 2025, pp. 10746–10761. • Gutierrez, B. J. et al. (2024). HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. NeurIPS
2025
-
[4]
and Grave, E
• Izacard, G. and Grave, E. (2021). Leveraging Passage Retrieval with Generative Models RLM-on-KG 32 for Open Domain Question Answering. EACL
2021
-
[5]
• Kontonis, V. et al. (2026). Memento: Teaching LLMs to Manage Their Own Context. Microsoft Research. • Lewis, P. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS
2026
-
[6]
• Ma, X. et al. (2023). Query Rewriting for Retrieval-Augmented Large Language Models. EMNLP
2023
-
[7]
• Trivedi, H. et al. (2022). MuSiQue: Multihop Questions via Single-hop Question Composi- tion. TACL
2022
-
[8]
• Trivedi, H. et al. (2023). Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. ACL
2023
- [9]
-
[10]
• Zhang, S., Kraska, T., and Khattab, O. (2025). Recursive Language Models. arXiv:2512.24601. • Zhu, R.-J. et al. (2025). Scaling Latent Reasoning via Looped Language Models (Ouro). arXiv:2510.25741. Acknowledgments The authors used Antigravity to assist with the research and the writing to improve clarity and readability. All content was carefully review...
work page Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.