Recognition: unknown
AI Observability for Developer Productivity Tools: Bridging Cost Awareness and Code Quality
Pith reviewed 2026-05-10 06:04 UTC · model grok-4.3
The pith
A unified dashboard tracks real token usage from multiple LLM providers in developer workflows to deliver accurate costs and rapid insights into AI-assisted code reviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
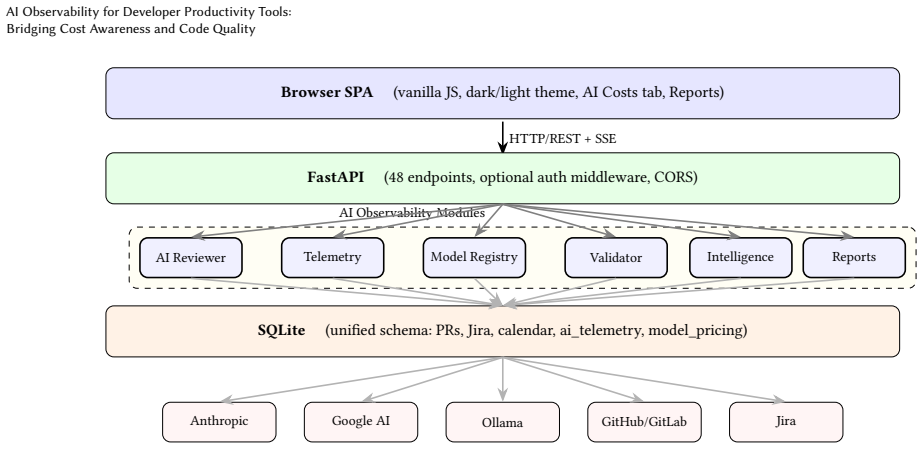
By combining a centralized developer productivity interface with an observability layer that pulls live token counts from provider APIs, applies a configurable pricing registry, runs response validation, and surfaces cost and quality metrics, the approach produces reliable per-review cost figures and order-of-magnitude faster pattern detection than manual tracking.
What carries the argument
Real-time token tracking from provider APIs paired with a multi-model pricing registry that computes exact costs and feeds them into unified analytics and reports.
If this is right
- Developers receive per-review cost numbers that align closely with actual provider invoices.
- Teams spend far less time manually piecing together AI usage patterns.
- A single view links task and review activity with cost and quality signals.
- Validated AI responses support consistent code quality checks.
- Exportable reports allow sharing and deeper analysis across projects.
Where Pith is reading between the lines
- Widespread use could push AI coding assistants to expose cost signals directly to users.
- Collected data might later reveal correlations between specific usage patterns and project velocity or defect rates.
- The same tracking layer could apply to non-coding AI tools such as documentation generators or test writers.
- Open implementations would let smaller teams adopt accurate cost awareness without building custom gateways.
Load-bearing premise
The six-month internal workflow represents how most developers use AI tools and that live token data can be gathered from providers without added delays or access problems.
What would settle it
Running the system on an external team's workflow for several months and finding cost figures more than 2 percent off provider bills or noticeable added latency in tracking would disprove the accuracy and practicality claims.
Figures

read the original abstract
As AI-assisted development tools proliferate, developers face a growing challenge: understanding the cost, quality, and behavioral patterns of AI interactions across their workflow. We present a unified approach to AI observability for developer productivity tools, combining real-time token tracking, configurable model pricing registries, response validation, and cost analytics into a single-pane dashboard. Our work synthesizes two complementary systems -- Workstream, a developer productivity dashboard that centralizes pull requests, Jira tasks, and AI code reviews; and an AI observability summarizer that monitors inference workloads with Prometheus-backed metrics and multi-provider LLM gateways. We describe the architectural patterns adopted, the implementation of real token tracking from provider APIs (replacing heuristic estimation), a 24-model pricing registry, response validation pipelines, LLM-powered review intelligence, and exportable reports. Our evaluation on a six-month development workflow shows the system captures per-review cost with less than 2% variance from provider billing and reduces time-to-insight for AI usage patterns by an order of magnitude compared to manual tracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a unified AI observability framework for developer productivity tools by integrating Workstream, which centralizes pull requests, Jira tasks, and AI code reviews, with an AI observability summarizer that uses Prometheus-backed metrics and multi-provider LLM gateways. Key features include real-time token tracking from provider APIs (replacing heuristics), a 24-model pricing registry, response validation pipelines, LLM-powered review intelligence, and exportable reports. The central empirical claim is that evaluation on a six-month internal development workflow shows per-review cost capture with less than 2% variance from provider billing and an order-of-magnitude reduction in time-to-insight for AI usage patterns versus manual tracking.
Significance. If the evaluation results hold after additional methodological detail, this work offers a timely practical contribution to software engineering by providing developers with integrated visibility into AI tool costs, quality, and behavioral patterns. The architectural synthesis of productivity dashboards with real-time observability infrastructure, emphasis on actual token tracking over estimation, and multi-provider support represent reusable patterns that address a growing need as AI-assisted coding proliferates. The implementation of configurable registries and validation pipelines is a concrete strength.
major comments (1)
- [Evaluation] Evaluation section: The claims of <2% variance from provider billing and order-of-magnitude reduction in time-to-insight rest on a single six-month internal workflow, yet the manuscript supplies no details on sample size (number of reviews/users/models), provider mix, data collection/exclusion criteria, operational definition of time-to-insight (e.g., controlled timing, log analysis, or self-report), baseline manual process, or statistical reconciliation procedure for billing variance. This under-specification is load-bearing for the central empirical contribution and prevents assessment of robustness or generalizability.
minor comments (2)
- [Abstract] The abstract and system description refer to a '24-model pricing registry' and 'configurable model pricing registries' without specifying maintenance procedures, update frequency, or handling of provider pricing changes.
- Consider adding a summary table comparing Workstream components with the AI observability summarizer features to clarify the integration points described in the architectural patterns section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the major comment below and will perform a major revision to strengthen the evaluation section.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The claims of <2% variance from provider billing and order-of-magnitude reduction in time-to-insight rest on a single six-month internal workflow, yet the manuscript supplies no details on sample size (number of reviews/users/models), provider mix, data collection/exclusion criteria, operational definition of time-to-insight (e.g., controlled timing, log analysis, or self-report), baseline manual process, or statistical reconciliation procedure for billing variance. This under-specification is load-bearing for the central empirical contribution and prevents assessment of robustness or generalizability.
Authors: We agree that the Evaluation section currently lacks sufficient methodological detail, which limits assessment of the empirical claims. In the revised manuscript we will expand this section to include the sample size (number of reviews, users, and models), provider mix, data collection and exclusion criteria, the operational definition and measurement approach for time-to-insight, the baseline manual process used for comparison, and the statistical procedure for reconciling tracked costs against provider billing. These additions will improve transparency and allow better evaluation of robustness without changing the reported results. revision: yes
Circularity Check
No circularity detected; empirical evaluation without fitted predictions or self-referential derivations
full rationale
The manuscript describes an architectural implementation of AI observability combining real-time token tracking from provider APIs, configurable pricing registries, response validation, and cost analytics dashboards. Its central claims consist of direct empirical measurements (per-review cost variance <2% and order-of-magnitude reduction in time-to-insight) reported from a six-month internal workflow. No equations, parameter fittings, predictions derived from fitted inputs, self-citations, uniqueness theorems, or ansatzes appear in the text. The evaluation metrics are presented as observed outcomes of the implemented system rather than quantities that reduce by construction to prior definitions or fits. This is a standard descriptive systems paper whose reasoning chain is self-contained and independent of the circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Bhati. 2025. Workstream: An Open-Source Developer Productivity Dashboard. GitHub. https://github.com/happybhati/workstream
2025
-
[2]
Sisodia et al
T. Sisodia et al. 2025. AI Observability Summarizer: OpenShift AI Metrics Analysis with LLM-Powered Insights. GitHub. https://github.com/rh-ai-quickstart/ai- observability-summarizer
2025
-
[3]
Large Language Models for Software Engineering: A Systematic Literature Review,
A. Fan et al. 2023. Large Language Models for Software Engineering: A Systematic Literature Review.arXiv:2308.10620
-
[4]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
S. Peng et al. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.arXiv:2302.06590
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
GitHub. 2024. GitHub Copilot Research Recitation. https://github.blog/2023-06- 27-the-economic-potential-of-generative-ai/
2024
-
[6]
Kwon et al
W. Kwon et al. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of SOSP ’23
2023
-
[7]
OpenTelemetry. 2024. Semantic Conventions for Generative AI Systems. https: //opentelemetry.io/docs/specs/semconv/gen-ai/
2024
-
[8]
Forsgren, J
N. Forsgren, J. Humble, and G. Kim. 2018.Accelerate: The Science of Lean Software and DevOps. IT Revolution Press
2018
-
[9]
Forsgren et al
N. Forsgren et al. 2021. The SPACE of Developer Productivity.ACM Queue19, 1
2021
-
[10]
S. Ramírez. 2018. FastAPI: Modern Python Web Framework. https://fastapi. tiangolo.com
2018
-
[11]
Anthropic. 2024. Model Context Protocol Specification. https: //modelcontextprotocol.io
2024
-
[12]
Prometheus Authors. 2024. Prometheus Monitoring System. https://prometheus. io
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.